You might also like
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Rath'S Lectures: Longevity Related Notes On Vimsottari DasaDocument5 pagesRath'S Lectures: Longevity Related Notes On Vimsottari DasasudhinnnNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Chanakya National Law UniversityDocument23 pagesChanakya National Law Universityshubham kumarNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Tuberculosis: Still A Social DiseaseDocument3 pagesTuberculosis: Still A Social DiseaseTercio Estudiantil FamurpNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Carcinoma of PenisDocument13 pagesCarcinoma of Penisalejandro fernandezNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- You Are Loved PDFDocument4 pagesYou Are Loved PDFAbrielle Angeli DeticioNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- 5909 East Kaviland AvenueDocument1 page5909 East Kaviland Avenueapi-309853346No ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Servicenow Rest Cheat SheetDocument3 pagesServicenow Rest Cheat SheetHugh SmithNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Use of ICT in School AdministartionDocument32 pagesUse of ICT in School AdministartionSyed Ali Haider100% (1)
- D78846GC20 sg2Document356 pagesD78846GC20 sg2hilordNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- 600 00149 000 R1 MFD Cmax Dug PDFDocument1 page600 00149 000 R1 MFD Cmax Dug PDFenriqueNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Mark Scheme (Results) Summer 2019: Pearson Edexcel International GCSE in English Language (4EB1) Paper 01RDocument19 pagesMark Scheme (Results) Summer 2019: Pearson Edexcel International GCSE in English Language (4EB1) Paper 01RNairit100% (1)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Decision Making and Problem Solving & Managing - Gashaw PDFDocument69 pagesDecision Making and Problem Solving & Managing - Gashaw PDFKokebu MekonnenNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- He Didnt Die in Vain - Take No GloryDocument2 pagesHe Didnt Die in Vain - Take No GloryDagaerag Law OfficeNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Endless Pursuit of Truth: Subalternity and Marginalization in Post-Neorealist Italian FilmDocument206 pagesThe Endless Pursuit of Truth: Subalternity and Marginalization in Post-Neorealist Italian FilmPaul MathewNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- NHÓM ĐỘNG TỪ BẤT QUY TẮCDocument4 pagesNHÓM ĐỘNG TỪ BẤT QUY TẮCNhựt HàoNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- EmTech TG Acad v5 112316Document87 pagesEmTech TG Acad v5 112316Arvin Barrientos Bernesto67% (3)
- scn615 Classroomgroupactionplan SarahltDocument3 pagesscn615 Classroomgroupactionplan Sarahltapi-644817377No ratings yet
- Grenade FINAL (Esl Song Activities)Document4 pagesGrenade FINAL (Esl Song Activities)Ti LeeNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Aleister Crowley Astrological Chart - A Service For Members of Our GroupDocument22 pagesAleister Crowley Astrological Chart - A Service For Members of Our GroupMysticalgod Uidet100% (3)
- A Research Presented To Alexander T. Adalia Asian College-Dumaguete CampusDocument58 pagesA Research Presented To Alexander T. Adalia Asian College-Dumaguete CampusAnn Michelle PateñoNo ratings yet
- A Complete List of Greek Underworld GodsDocument3 pagesA Complete List of Greek Underworld GodsTimothy James M. Madrid100% (1)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Razom For UkraineDocument16 pagesRazom For UkraineАняNo ratings yet
- BRP 40k Second Edition 2col PDFDocument54 pagesBRP 40k Second Edition 2col PDFColin BrettNo ratings yet
- Unit 4 Place Value Summative RubricDocument1 pageUnit 4 Place Value Summative Rubricapi-169564125No ratings yet
- Tate J. Hedtke SPED 608 Assignment #6 Standard # 8 Cross Categorical Special Education/ Learning Disabilities Artifact SummaryDocument5 pagesTate J. Hedtke SPED 608 Assignment #6 Standard # 8 Cross Categorical Special Education/ Learning Disabilities Artifact Summaryapi-344731850No ratings yet
- MODULE 13 Ethics Through Thick and ThinDocument7 pagesMODULE 13 Ethics Through Thick and ThinCristobal M. CantorNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- MidtermDocument8 pagesMidtermBrian FrenchNo ratings yet
- Presentation of Times of India Newspaper SIPDocument38 pagesPresentation of Times of India Newspaper SIPPrakruti ThakkarNo ratings yet
- Chapter (1) The Accounting EquationDocument46 pagesChapter (1) The Accounting Equationtunlinoo.067433100% (3)
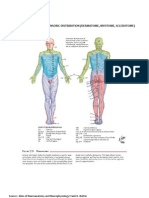
- Dermatome, Myotome, SclerotomeDocument4 pagesDermatome, Myotome, SclerotomeElka Rifqah100% (3)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)