You might also like
- Investigating FM Signals and DemodulationDocument11 pagesInvestigating FM Signals and DemodulationJosephine LegakNo ratings yet
- MATLAB Project Description - Signal ProcessingDocument6 pagesMATLAB Project Description - Signal Processingsunshine heaven0% (1)
- AssigDocument2 pagesAssignilesh7889No ratings yet
- SVM PRESENTATIONDocument34 pagesSVM PRESENTATIONRavi ChanderNo ratings yet
- Spectrogram Analysis and Audio Filtering in MATLABDocument9 pagesSpectrogram Analysis and Audio Filtering in MATLABsenowmNo ratings yet
- Digital Communications FundamentalsDocument44 pagesDigital Communications FundamentalsKvnsumeshChandraNo ratings yet
- Noise Performance of Analog Communication ReceiversDocument33 pagesNoise Performance of Analog Communication ReceiversNihon MatsoNo ratings yet
- CMOS Mixed Signal Circuit Design by Jacob BakerDocument180 pagesCMOS Mixed Signal Circuit Design by Jacob BakerSharath Sogi0% (1)
- A Self-Steering Digital Microphone Array: At&T NJ, UsaDocument4 pagesA Self-Steering Digital Microphone Array: At&T NJ, UsaMayssa RjaibiaNo ratings yet
- Formatting and Baseband ModulationDocument16 pagesFormatting and Baseband Modulationlongyeuhuong50% (2)
- Analyzing Time-Varying Noise Properties With SpectrerfDocument22 pagesAnalyzing Time-Varying Noise Properties With Spectrerffrostyfoley100% (1)
- Measuring The Modulation Index of An AM Signal Using An FFT 1Document6 pagesMeasuring The Modulation Index of An AM Signal Using An FFT 1tezcatli01No ratings yet
- Noise Removal: Sinusoidal Signals and FrequencyDocument12 pagesNoise Removal: Sinusoidal Signals and Frequencykatrina99No ratings yet
- Real-Time Implementation of A 1/3-Octave Audio Equalizer Simulink Model Using TMS320C6416 DSPDocument6 pagesReal-Time Implementation of A 1/3-Octave Audio Equalizer Simulink Model Using TMS320C6416 DSPBruno Garcia TejadaNo ratings yet
- ProblemsDocument7 pagesProblemsFaraz HumayunNo ratings yet
- Juhan Nam Vesa VälimäkiDocument6 pagesJuhan Nam Vesa VälimäkiHerman HesseNo ratings yet
- Ec332 - Communication Theory and SystemDocument3 pagesEc332 - Communication Theory and SystemsubhazNo ratings yet
- Data Converters1Document30 pagesData Converters1Vidyanand PattarNo ratings yet
- On Using Transmission Overhead Efficiently For Channel Estimation in OFDMDocument6 pagesOn Using Transmission Overhead Efficiently For Channel Estimation in OFDMAnonymous uspYoqENo ratings yet
- AM Demodulation of Speech Spectra for Noise Robust Speech RecognitionDocument4 pagesAM Demodulation of Speech Spectra for Noise Robust Speech RecognitionSsener SSenerNo ratings yet
- Influence of RF Oscillators On An Ofdm SignalDocument12 pagesInfluence of RF Oscillators On An Ofdm SignalLi ChunshuNo ratings yet
- AMDemod Lab Op Amp Part 2Document9 pagesAMDemod Lab Op Amp Part 2shonchoyNo ratings yet
- S A A O N I S C A C: Imulation ND Nalysis F Oise N Witched Apacitor Mplifier IrcuitsDocument4 pagesS A A O N I S C A C: Imulation ND Nalysis F Oise N Witched Apacitor Mplifier IrcuitsSai KrishnaNo ratings yet
- Proyecto 04Document6 pagesProyecto 04Scott Backster Clarck0% (1)
- A4: Short-Time Fourier Transform (STFT) : Audio Signal Processing For Music ApplicationsDocument6 pagesA4: Short-Time Fourier Transform (STFT) : Audio Signal Processing For Music ApplicationsjcvoscribNo ratings yet
- Oscillator Noise Analysis: Cyclostationary NoiseDocument12 pagesOscillator Noise Analysis: Cyclostationary Noisedeepakvaj25No ratings yet
- An Efficient LMMSE Estimator For MIMOOFDM Systems Over Flat Fading ChannelDocument4 pagesAn Efficient LMMSE Estimator For MIMOOFDM Systems Over Flat Fading ChannelseventhsensegroupNo ratings yet
- PadovaniDocument4 pagesPadovaniQiyanNo ratings yet
- VI Lect - Notes#3 Btech Vii Sem Aug Dec2022Document164 pagesVI Lect - Notes#3 Btech Vii Sem Aug Dec2022NAAZNo ratings yet
- Novel WeigtedDocument5 pagesNovel WeigtedLiju TrNo ratings yet
- Performance Analysis of Phase Noise Impaired Ofdm Systeminamultipath Fading ChannelDocument6 pagesPerformance Analysis of Phase Noise Impaired Ofdm Systeminamultipath Fading Channeljagadeesh jagadeNo ratings yet
- BRÜEL & KJAER-Influence of Tripods and Mic ClipsDocument48 pagesBRÜEL & KJAER-Influence of Tripods and Mic ClipsAptaeex Extremadura100% (1)
- Lab 4 Acoustic Direction Finder: Ecen 487 Real-Time Digital Signal Processing LaboratoryDocument6 pagesLab 4 Acoustic Direction Finder: Ecen 487 Real-Time Digital Signal Processing Laboratoryscribd1235207No ratings yet
- Wave-Domain Adaptive Filtering For Acoustic Human-Machine Interfaces Based On Wavefield Analysis and SynthesisDocument4 pagesWave-Domain Adaptive Filtering For Acoustic Human-Machine Interfaces Based On Wavefield Analysis and SynthesisTrần Quang ĐạtNo ratings yet
- UNIT 4 Ofc FinalDocument12 pagesUNIT 4 Ofc FinalnaactitexcellenceNo ratings yet
- Chopper Stabilized Amplifiers: Course - ECE 1352 Analog Integrated Circuits I Professor - K. PhangDocument17 pagesChopper Stabilized Amplifiers: Course - ECE 1352 Analog Integrated Circuits I Professor - K. PhangmhtsoskarNo ratings yet
- FM ModulationDocument8 pagesFM ModulationDelinger TominNo ratings yet
- SpectrogramDocument17 pagesSpectrogramShanmugaraj VskNo ratings yet
- Acoustic Absorption Coefficient MeasurementsDocument8 pagesAcoustic Absorption Coefficient MeasurementsRaphael LemosNo ratings yet
- GFSK Modulation Background for DSP CourseDocument5 pagesGFSK Modulation Background for DSP CourseJ Jesús Villanueva García100% (1)
- Tema 5: Analisis Espectral de Señales Mediante La DFTDocument8 pagesTema 5: Analisis Espectral de Señales Mediante La DFTMiki DiazNo ratings yet
- Experiment No. (5) : Frequency Modulation & Demodulation: - ObjectDocument5 pagesExperiment No. (5) : Frequency Modulation & Demodulation: - ObjectFaez FawwazNo ratings yet
- AN10062 Phase Noise Measurement Guide For OscillatorsDocument16 pagesAN10062 Phase Noise Measurement Guide For Oscillatorspranan100% (1)
- ENGINEERING REPORTS: The Use of Airborne Ultrasonics for Generating Audible Sound BeamsDocument6 pagesENGINEERING REPORTS: The Use of Airborne Ultrasonics for Generating Audible Sound BeamsDaniel Cardona RojasNo ratings yet
- Thapar Institute of Engineering and Technology, PatialaDocument2 pagesThapar Institute of Engineering and Technology, PatialaJagat ChauhanNo ratings yet
- InTech-Analysis and Mitigation of Phase Noise in Centralized de Centralized Mimo SystemsDocument17 pagesInTech-Analysis and Mitigation of Phase Noise in Centralized de Centralized Mimo Systemsdodo gogoNo ratings yet
- Minimum Frequency Spacing For Having Orthogonal Sine Waves: Case 1: For An Arbitrary Value ofDocument8 pagesMinimum Frequency Spacing For Having Orthogonal Sine Waves: Case 1: For An Arbitrary Value ofRazvan IonutNo ratings yet
- Optimal Filter: 'Truncation Time For Matched Array ProcessingDocument4 pagesOptimal Filter: 'Truncation Time For Matched Array ProcessingMayssa RjaibiaNo ratings yet
- 1978 - Passband Timing Recovery in An All-Digital Modem ReceiverDocument7 pages1978 - Passband Timing Recovery in An All-Digital Modem ReceiverqasimilyasscribdNo ratings yet
- Spectrum Analysis and The Frequency DomainDocument16 pagesSpectrum Analysis and The Frequency DomainAhsan AmeenNo ratings yet
- Robust and Efficient Pitch Tracking For Query-by-Humming: Yongwei Zhu, Mohan S KankanhalliDocument5 pagesRobust and Efficient Pitch Tracking For Query-by-Humming: Yongwei Zhu, Mohan S KankanhalliRam Krishna VodnalaNo ratings yet
- Experimental 3D Sound Field Analysis With A Microphone ArrayDocument8 pagesExperimental 3D Sound Field Analysis With A Microphone ArrayLeandro YakoNo ratings yet
- NOTES 99-5 Modulation and Demodulation Modems For Data Transmission Over Analog LinksDocument13 pagesNOTES 99-5 Modulation and Demodulation Modems For Data Transmission Over Analog LinksKwadwo Ntiamoah-sarpongNo ratings yet
- NOTES 99-4 Bandwidth, Frequency Response, and Capacity of Communication LinksDocument13 pagesNOTES 99-4 Bandwidth, Frequency Response, and Capacity of Communication LinksengrkskNo ratings yet
- Blind Estimation of Carrier Frequency Offset in Multicarrier Communication SystemsDocument3 pagesBlind Estimation of Carrier Frequency Offset in Multicarrier Communication SystemsVijay Kumar Raju VippartiNo ratings yet
- Lab Report on Amplitude Modulation MeasurementsDocument11 pagesLab Report on Amplitude Modulation MeasurementsmahinNo ratings yet
- Experiment 2: Waveform Spectrum AnalysisDocument10 pagesExperiment 2: Waveform Spectrum AnalysisVenice Rome RoldanNo ratings yet
- Phase NoiseDocument4 pagesPhase NoisetranthinhamNo ratings yet
- Amateur Radio Electronics on Your MobileFrom EverandAmateur Radio Electronics on Your MobileRating: 5 out of 5 stars5/5 (1)
- MAA Joint MTG Jan2013 San Diego 1.11.13Document39 pagesMAA Joint MTG Jan2013 San Diego 1.11.13Ammelia PinemNo ratings yet
- Example of Perdonal LetterDocument2 pagesExample of Perdonal LetterAmmelia PinemNo ratings yet
- MAA Joint MTG Jan2013 San Diego 1.11.13Document39 pagesMAA Joint MTG Jan2013 San Diego 1.11.13Ammelia PinemNo ratings yet
- Letter Writing Performance Standard 3C.IDocument8 pagesLetter Writing Performance Standard 3C.IAmmelia PinemNo ratings yet
- Konsep Analog Dan DigitalDocument176 pagesKonsep Analog Dan DigitalAmmelia PinemNo ratings yet
- Elementary AlgorithmsDocument630 pagesElementary AlgorithmsKonstantine Mushegiani100% (2)
- EE 301 Notes - Chapter 3 - Part 1Document17 pagesEE 301 Notes - Chapter 3 - Part 1farouq_razzaz2574No ratings yet
- DSP Lab ReportDocument28 pagesDSP Lab ReportKaaviyaNo ratings yet
- Fourier Analysis Explained: Signals, LTI Systems and TransformsDocument46 pagesFourier Analysis Explained: Signals, LTI Systems and TransformsLai Yon PengNo ratings yet
- Optimal Ridge Bias Selection for Linear RegressionDocument6 pagesOptimal Ridge Bias Selection for Linear RegressionAyesha ShahbazNo ratings yet
- COSC 3101A - Design and Analysis of Algorithms 7Document50 pagesCOSC 3101A - Design and Analysis of Algorithms 7Aaqib InamNo ratings yet
- B-Spline Curves: Navsheen Mirakhur 02111604415 Semester 3rdDocument14 pagesB-Spline Curves: Navsheen Mirakhur 02111604415 Semester 3rdYogesh SharmaNo ratings yet
- Unit Test Paper of Digital ElectronicsDocument1 pageUnit Test Paper of Digital Electronicsabhijit_jamdadeNo ratings yet
- Division of Polynomials Long Division LantonDocument2 pagesDivision of Polynomials Long Division LantonJerson YhuwelNo ratings yet
- Generating A Signal:: Types of Function Generators, DAC Considerations, and Other Common TerminologyDocument10 pagesGenerating A Signal:: Types of Function Generators, DAC Considerations, and Other Common Terminologyyogendra.shethNo ratings yet
- Signals and Systems (2nd Edition) - Oppenheim Matlab ProjectDocument2 pagesSignals and Systems (2nd Edition) - Oppenheim Matlab ProjectdavStonerNo ratings yet
- CSC 121 Ass 1Document3 pagesCSC 121 Ass 1Marvellous Johnson-OruNo ratings yet
- Abaqus Topology Optimization Sandeep Urankar ATOM SGL RUM 2011Document41 pagesAbaqus Topology Optimization Sandeep Urankar ATOM SGL RUM 2011matmeanNo ratings yet
- Pre Talk 1Document120 pagesPre Talk 1ab245No ratings yet
- THE SQUARE-ROOT UNSCENTED KALMAN FILTER FOR STATE AND PARAMETER ESTIMATIONDocument4 pagesTHE SQUARE-ROOT UNSCENTED KALMAN FILTER FOR STATE AND PARAMETER ESTIMATIONROHIT SinghNo ratings yet
- Gauss Elimination Method for Solving Linear EquationsDocument31 pagesGauss Elimination Method for Solving Linear EquationsBaja TechinNo ratings yet
- Bairstow Method: PolynomialDocument3 pagesBairstow Method: PolynomialWilson Aponte HuamantincoNo ratings yet
- System Model of TH-UWB Using LDPC Code ImplementationDocument7 pagesSystem Model of TH-UWB Using LDPC Code ImplementationJournal of TelecommunicationsNo ratings yet
- Ai QB 1Document2 pagesAi QB 1Ravi KhimaniNo ratings yet
- Name: Nazim Firdous Ali Bscs 6C Registration# 1612202 Assignment# 1Document11 pagesName: Nazim Firdous Ali Bscs 6C Registration# 1612202 Assignment# 1nazim viraniNo ratings yet
- Difference Formulas for f' (x) ≈ Approx error ξ Difference Formulas for f' (x) ≈ Approx error ξDocument4 pagesDifference Formulas for f' (x) ≈ Approx error ξ Difference Formulas for f' (x) ≈ Approx error ξQuang Huy BùiNo ratings yet
- Linear Programming Sensitivity AnalysisDocument23 pagesLinear Programming Sensitivity AnalysisTheaNo ratings yet
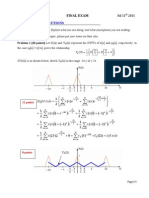
- Y_d(Ω) sketch for problem 1Document4 pagesY_d(Ω) sketch for problem 1Le HuyNo ratings yet
- Naive BayesDocument62 pagesNaive BayessaRIKANo ratings yet
- 2021-22 Copo V Sem Cv2302 Advanced Structural Analysis VNMDocument68 pages2021-22 Copo V Sem Cv2302 Advanced Structural Analysis VNMHAsNo ratings yet
- LeetCode Cheat Sheet - PIRATE KINGDocument18 pagesLeetCode Cheat Sheet - PIRATE KINGJoão Vitor R. BaptistaNo ratings yet
- Bakery Algorithm PropertyDocument2 pagesBakery Algorithm PropertyNijin Vinod0% (1)
- DDA AlgorithmDocument2 pagesDDA Algorithmlakshmi narasimha raoNo ratings yet