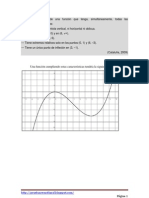
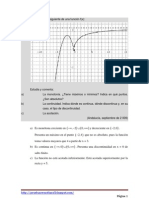
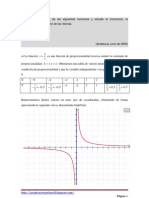
You might also like
- Ej 4Document2 pagesEj 4pedrolopez107No ratings yet
- Cataluña 4Document1 pageCataluña 4pedrolopez107No ratings yet
- Ej 6Document1 pageEj 6pedrolopez107No ratings yet
- Ej 5Document1 pageEj 5pedrolopez107No ratings yet
- Asturias 3Document2 pagesAsturias 3pedrolopez107No ratings yet
- Mad Rid 2Document3 pagesMad Rid 2pedrolopez107No ratings yet
- Ej 1Document1 pageEj 1pedrolopez107No ratings yet
- Ej 3Document1 pageEj 3pedrolopez107No ratings yet
- Ej 2Document1 pageEj 2pedrolopez107No ratings yet
- Cataluña 4Document1 pageCataluña 4pedrolopez107No ratings yet
- Bale Ares 4Document1 pageBale Ares 4pedrolopez107No ratings yet
- And A Lucia 8Document2 pagesAnd A Lucia 8pedrolopez107No ratings yet
- Bale Ares 4Document1 pageBale Ares 4pedrolopez107No ratings yet
- Cataluña 5Document1 pageCataluña 5pedrolopez107No ratings yet
- Cataluña 4Document1 pageCataluña 4pedrolopez107No ratings yet
- Cataluña 4Document1 pageCataluña 4pedrolopez107No ratings yet
- Cataluña 2Document1 pageCataluña 2pedrolopez107No ratings yet
- And A Lucia 7Document1 pageAnd A Lucia 7pedrolopez107No ratings yet
- Soluc B4Document1 pageSoluc B4pedrolopez107No ratings yet
- Mad RidDocument2 pagesMad Ridpedrolopez107No ratings yet
- País Vasco2Document1 pagePaís Vasco2pedrolopez107No ratings yet
- Cataluña 3Document2 pagesCataluña 3pedrolopez107No ratings yet
- Extremadura 3Document1 pageExtremadura 3pedrolopez107No ratings yet
- And A Lucia 6Document1 pageAnd A Lucia 6pedrolopez107No ratings yet
- And A Lucia 5Document3 pagesAnd A Lucia 5pedrolopez107No ratings yet
- Cantabria 2Document1 pageCantabria 2pedrolopez107No ratings yet
- Bale Ares 3Document1 pageBale Ares 3pedrolopez107No ratings yet
- And A Lucia 4Document1 pageAnd A Lucia 4pedrolopez107No ratings yet
- CataluñaçDocument1 pageCataluñaçpedrolopez107No ratings yet
- Comerciantes Mercado Covida - Entrega - 6 - 12Document28 pagesComerciantes Mercado Covida - Entrega - 6 - 12maria alvaNo ratings yet
- Contratos Su Clasificacion en El Codigo Gratuitos y OnerososDocument1 pageContratos Su Clasificacion en El Codigo Gratuitos y Onerososexamendegrado2020No ratings yet
- Las 8 PsDocument19 pagesLas 8 PsPaola ParedesNo ratings yet
- Yoga Taoista FinalDocument180 pagesYoga Taoista FinalPedro ChicoNo ratings yet
- Medida eléctrica 40Document92 pagesMedida eléctrica 40Pepe Perez RuizNo ratings yet
- Laboratorio de MRUVDocument2 pagesLaboratorio de MRUVRonnie Roger Anicama MendozaNo ratings yet
- Teoria Del DelitoDocument33 pagesTeoria Del DelitoStyle Sweet Water PrintNo ratings yet
- Instituto Tecnológico Superior de Las ChoapasDocument4 pagesInstituto Tecnológico Superior de Las Choapasrommel alfonso bolainaNo ratings yet
- Técnicas: EstudioDocument4 pagesTécnicas: EstudioKim Seok jinNo ratings yet
- Análisis Descriptivo de La Aparición Del SERVICIO COMUNITARIO LUIS AGUILERADocument4 pagesAnálisis Descriptivo de La Aparición Del SERVICIO COMUNITARIO LUIS AGUILERAFabianNo ratings yet
- Ciencias 4°Document4 pagesCiencias 4°Keñytha HenríquezNo ratings yet
- Constantes de Prisma LEICADocument4 pagesConstantes de Prisma LEICACristian Abanto LeónNo ratings yet
- La AnemiaDocument4 pagesLa AnemiaNanYeni100% (5)
- Arte y PsicoanalisisDocument111 pagesArte y PsicoanalisisEric FuentesNo ratings yet
- Por Qué Los Niños Franceses Se Portan BienDocument5 pagesPor Qué Los Niños Franceses Se Portan BienJulio César Corvalán100% (1)
- DI TULLIO - El Voseo Argentino en Tiempos Del BicentenarioDocument25 pagesDI TULLIO - El Voseo Argentino en Tiempos Del BicentenarioHado NavarroNo ratings yet
- Clase Examen MentalDocument7 pagesClase Examen MentalPedro Sotomayor SoloagaNo ratings yet
- La Composición en El ArteDocument26 pagesLa Composición en El ArtepeniNo ratings yet
- Historia clínica de paciente con dolor torácicoDocument8 pagesHistoria clínica de paciente con dolor torácicoJose Marco Muñoz BocanegraNo ratings yet
- CBT No. 7 San Juan Tilapa, Toluca Memoria de Trabajo ProfesionalDocument60 pagesCBT No. 7 San Juan Tilapa, Toluca Memoria de Trabajo Profesionalcecilia monserrath reyesNo ratings yet
- Métodos investigación criminologíaDocument1 pageMétodos investigación criminologíaNandy MacedoNo ratings yet
- Ficha - de - Actividad - 11.1. AdministracionDocument2 pagesFicha - de - Actividad - 11.1. AdministracionJuan Antonio Cabanillas perezNo ratings yet
- ExMid MatEco 1Document3 pagesExMid MatEco 1Salomon DominguezNo ratings yet
- Aspecto, tiempo, modalidad y modo en purépechaDocument429 pagesAspecto, tiempo, modalidad y modo en purépechaStephany Gutiérrez VargasNo ratings yet
- Lenguaje 5ºS IVB 2022Document21 pagesLenguaje 5ºS IVB 2022Judith TolentinoNo ratings yet
- Manual de Convivencia Semana de Inducion (1) 2023Document15 pagesManual de Convivencia Semana de Inducion (1) 2023Ruby Margarita Alcala EspinosaNo ratings yet
- Manual PrepartoDocument75 pagesManual PrepartoAndrea TaberneroNo ratings yet
- San Agustin, Libre AlbedrioDocument6 pagesSan Agustin, Libre AlbedrioMarcela SanchezNo ratings yet
- 04 - 25 - IB - REFLEXION y REFRACCION - ConceptosDocument11 pages04 - 25 - IB - REFLEXION y REFRACCION - ConceptosIlan MITMA CHAPANo ratings yet
- Si Dios no existe, la libertad nos condenaDocument6 pagesSi Dios no existe, la libertad nos condenaAnonymous gIdbqLCNo ratings yet