You might also like
- Statistics: Practical Concept of Statistics for Data ScientistsFrom EverandStatistics: Practical Concept of Statistics for Data ScientistsNo ratings yet
- Introduction to Statistics: An Intuitive Guide for Analyzing Data and Unlocking DiscoveriesFrom EverandIntroduction to Statistics: An Intuitive Guide for Analyzing Data and Unlocking DiscoveriesNo ratings yet
- AnalyticsDocument50 pagesAnalyticsIkshit Bhushan0% (1)
- 10 Challenging Problems in Data Mining ResearchDocument8 pages10 Challenging Problems in Data Mining Researchabhi_cool25No ratings yet
- How To Perform and Interpret Factor Analysis Using SPSSDocument9 pagesHow To Perform and Interpret Factor Analysis Using SPSSJyoti Prakash100% (2)
- Stata Absolute BeginnersDocument38 pagesStata Absolute BeginnersFabián Mtz LNo ratings yet
- Personalised MedicineDocument25 pagesPersonalised MedicineRevanti MukherjeeNo ratings yet
- STA780 Wk6 Factor Analysis-SPSSDocument19 pagesSTA780 Wk6 Factor Analysis-SPSSsyaidatul umairahNo ratings yet
- STATISTICS For MGT Summary of ChaptersDocument16 pagesSTATISTICS For MGT Summary of Chaptersramanadk100% (1)
- Statistical InferenceDocument11 pagesStatistical Inferenceanti100% (1)
- Regression AnalysisDocument280 pagesRegression AnalysisA.Benhari100% (1)
- Customer Churn: by Dinesh Nair Adrien Le Doussal Fiona Tait Fatma Ahmadi Fulya PercinDocument20 pagesCustomer Churn: by Dinesh Nair Adrien Le Doussal Fiona Tait Fatma Ahmadi Fulya PercinFati Ahmadi100% (1)
- Analytics at WorkDocument19 pagesAnalytics at WorkRishabh MauryaNo ratings yet
- Global Hepatitis B Virus (HBV) Treatment Market: Opportunities and Forecast (2017-2022)Document30 pagesGlobal Hepatitis B Virus (HBV) Treatment Market: Opportunities and Forecast (2017-2022)Azoth AnalyticsNo ratings yet
- Observe by Forencis Research (FSR) .: Request The Report Sample PDF of Global Market @Document3 pagesObserve by Forencis Research (FSR) .: Request The Report Sample PDF of Global Market @Patrick Olayinka AdedokunNo ratings yet
- Stats Xi All Chapters PptsDocument2,046 pagesStats Xi All Chapters PptsAnadi AgarwalNo ratings yet
- For Full-Screen View, Click On at The Lower Left of Your ScreenDocument24 pagesFor Full-Screen View, Click On at The Lower Left of Your ScreenKhaled Helmi El-Wakil100% (4)
- RegressionDocument19 pagesRegressionShardul PatelNo ratings yet
- Ch7 Continuous Probability Distributions Testbank HandoutDocument8 pagesCh7 Continuous Probability Distributions Testbank Handoutragcajun100% (1)
- RM AssignmentDocument10 pagesRM AssignmentGautam PrakashNo ratings yet
- Managerial Economics - NotesDocument69 pagesManagerial Economics - NotesR.T.IndujiNo ratings yet
- Econometrics PG Presentation - Does Trade Cause GrowthDocument15 pagesEconometrics PG Presentation - Does Trade Cause GrowthOscar ChipokaNo ratings yet
- Stock-Trak Project 2013Document4 pagesStock-Trak Project 2013viettuan91No ratings yet
- Predictive Analytics - Share - V5Document32 pagesPredictive Analytics - Share - V5ravikumar19834853No ratings yet
- Data AnalysisDocument87 pagesData AnalysisSaiful Hadi MastorNo ratings yet
- Time Series Analysis & ForecastDocument36 pagesTime Series Analysis & ForecastHà Nguyễn100% (1)
- RAPIDMINER ASSOCIATION RULES FOR COMMUNITY GROUPSDocument38 pagesRAPIDMINER ASSOCIATION RULES FOR COMMUNITY GROUPSGiani SuhikmatNo ratings yet
- Big Data - The Management RevolutionDocument10 pagesBig Data - The Management Revolutionrbrianr100% (1)
- Predictive AnalyticsDocument14 pagesPredictive AnalyticsArunJaitleyNo ratings yet
- Predictive ModelingDocument8 pagesPredictive ModelingPavithra MaddipetlaNo ratings yet
- Regression With StataDocument108 pagesRegression With Stataapi-373702575% (4)
- 1 Introduction To StatisticsDocument18 pages1 Introduction To StatisticsVahn VillenaNo ratings yet
- PA 765 - Factor AnalysisDocument18 pagesPA 765 - Factor AnalysisAnoop Slathia100% (1)
- COVID-19 Data Analysis - Predicting Patient RecoveryDocument7 pagesCOVID-19 Data Analysis - Predicting Patient RecoveryInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Think Pair Share Team G1 - 7Document8 pagesThink Pair Share Team G1 - 7Akash Kashyap100% (1)
- Systematic Risk and Expected ReturnsDocument37 pagesSystematic Risk and Expected ReturnsPurple AppleNo ratings yet
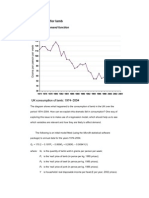
- The Demand For LambDocument11 pagesThe Demand For LambRhanda Williams50% (2)
- Lecture 1.4-Introduction To Biostatistics-DanardonoDocument18 pagesLecture 1.4-Introduction To Biostatistics-DanardonoJohan PadmamukaNo ratings yet
- Statistics Khan AcademyDocument4 pagesStatistics Khan AcademyKumardeep MukhopadhyayNo ratings yet
- Cluster Analysis BRM Session 14Document25 pagesCluster Analysis BRM Session 14akhil107043No ratings yet
- Basics of Research Paper Writing and PublishingDocument18 pagesBasics of Research Paper Writing and Publishingkamau16No ratings yet
- This is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...From EverandThis is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...Rating: 4.5 out of 5 stars4.5/5 (6)
- Chapter 2 - PlanningDocument31 pagesChapter 2 - PlanningAlwiCheIsmailNo ratings yet
- Aerofom - Alu Glass Tape Technical Data SheetDocument1 pageAerofom - Alu Glass Tape Technical Data SheetChris SolonNo ratings yet
- Polytropic Process1Document4 pagesPolytropic Process1Manash SinghaNo ratings yet
- Signed Off - Introduction To Philosophy12 - q1 - m2 - Methods of Philosophizing - v3Document25 pagesSigned Off - Introduction To Philosophy12 - q1 - m2 - Methods of Philosophizing - v3Benjamin Fernandez Jr.No ratings yet
- Winning Without Losing Preorder Gift BookDocument23 pagesWinning Without Losing Preorder Gift Bookcarlos_645331947No ratings yet
- Checklist for Teaching Strategies for Learners with Special NeedsDocument2 pagesChecklist for Teaching Strategies for Learners with Special NeedsJasmin Aldueza100% (6)
- Endurance Test Report MKP 2P Relay PGCILDocument5 pagesEndurance Test Report MKP 2P Relay PGCILTravis WoodNo ratings yet
- Data Sheet 6ES7215-1AG40-0XB0: General InformationDocument10 pagesData Sheet 6ES7215-1AG40-0XB0: General InformationautomaxNo ratings yet
- Daily Site Inspection ReportDocument2 pagesDaily Site Inspection Reportfreanne_0527No ratings yet
- Project ProposalDocument2 pagesProject ProposalTanya Naman SarafNo ratings yet
- Understanding Doctoral Nursing Students' Experiences of Blended LearningDocument8 pagesUnderstanding Doctoral Nursing Students' Experiences of Blended LearningZilbran BerontaxNo ratings yet
- DDL Mapeh 3-10Document8 pagesDDL Mapeh 3-10Reximie D. Dollete Jr.No ratings yet
- Technology and Livelihood Education 7: Home EconomicsDocument6 pagesTechnology and Livelihood Education 7: Home EconomicsJhen Natividad100% (1)
- 2280-Motorola Maxtrac 100-300 User ManualDocument37 pages2280-Motorola Maxtrac 100-300 User ManualKo AzaniNo ratings yet
- Flange Insulation ReducedDocument32 pagesFlange Insulation ReducedVasudev ShanmughanNo ratings yet
- SD ContentsDocument18 pagesSD ContentsAnonymous gUjimJKNo ratings yet
- KrokDocument20 pagesKrokYurii KovalivNo ratings yet
- Assessing ash fouling and slagging in coal-fired boilersDocument10 pagesAssessing ash fouling and slagging in coal-fired boilersDSGNo ratings yet
- Himachal Pradesh PDFDocument17 pagesHimachal Pradesh PDFAbhinav VermaNo ratings yet
- Acopl Todos - MétricoDocument53 pagesAcopl Todos - MétricoDaniela E. Wagner100% (1)
- List of books and standards on vibratory machine foundationsDocument5 pagesList of books and standards on vibratory machine foundationsMiminoRusNo ratings yet
- Chap # 14 (Electromagnetic Induction)Document6 pagesChap # 14 (Electromagnetic Induction)Tariq MahmoodNo ratings yet
- Lab 2 CSSDocument21 pagesLab 2 CSSハンサム アイベックスNo ratings yet
- Rapid Prototyping Question BankDocument2 pagesRapid Prototyping Question BankMeghavi ParmarNo ratings yet
- Outline Medical TerminologyDocument3 pagesOutline Medical TerminologypearlparfaitNo ratings yet
- Thread ID Course - OficialDocument63 pagesThread ID Course - OficialBruno SalasNo ratings yet
- Congratulations: $25 Gift VoucherDocument4 pagesCongratulations: $25 Gift VoucherKeryn LeeNo ratings yet
- Cp12 Pps 3274c Me Ds 001 Data Sheet Hvac Sunyaragi Rev.0Document1 pageCp12 Pps 3274c Me Ds 001 Data Sheet Hvac Sunyaragi Rev.0Triana Rosma Fikriyati DinaNo ratings yet
- Geberit Bathroom Collection BrochureDocument125 pagesGeberit Bathroom Collection BrochureThanhNo ratings yet
- Unit 2 Describing DataDocument21 pagesUnit 2 Describing DataG Ashwinn ReddyNo ratings yet