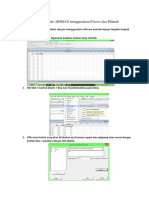
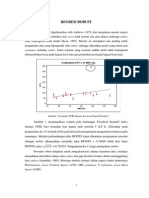
You might also like
- Tutorial ARIMAXDocument15 pagesTutorial ARIMAXHanif Faqot100% (1)
- Analisis Regresi Logistik MultinomialDocument54 pagesAnalisis Regresi Logistik MultinomialDwi Nia WulandariNo ratings yet
- REGRESI LOGIS BINERDocument37 pagesREGRESI LOGIS BINEREdi Kurniawan50% (2)
- Modul Analisis Regresi Dan Korelasi - JarakJauhDocument109 pagesModul Analisis Regresi Dan Korelasi - JarakJauhAbdyazNo ratings yet
- Tabel Kontingensi 3 ArahDocument17 pagesTabel Kontingensi 3 ArahIrianti MuladaniNo ratings yet
- Analisis Perubahan Struktur Ekonomi Jawa Barat Dengan Metode Biproporsional Pada Tabel Input OutputDocument120 pagesAnalisis Perubahan Struktur Ekonomi Jawa Barat Dengan Metode Biproporsional Pada Tabel Input OutputLenny RomauliNo ratings yet
- Regresi Probit Dan TobitDocument10 pagesRegresi Probit Dan TobitTeti Widia0% (1)
- Estimasi ModelDocument24 pagesEstimasi ModelirherNo ratings yet
- Analisis Korelasi Dan Regresi Linier SederhanaDocument41 pagesAnalisis Korelasi Dan Regresi Linier Sederhanajefry holleyNo ratings yet
- REGRESI ROBUSTDocument21 pagesREGRESI ROBUSTPratama Yuly NugrahaNo ratings yet
- Bahan Ajar Ekonometrika 2014Document35 pagesBahan Ajar Ekonometrika 2014dewioktaviani100% (3)
- Uji Kolmogorov SmirnovDocument13 pagesUji Kolmogorov SmirnovChoirul Ridho100% (1)
- 2 - Tutorial Cara Regresi Data Panel Dengan STATADocument17 pages2 - Tutorial Cara Regresi Data Panel Dengan STATAulfathulNo ratings yet
- Regresi LogistikDocument11 pagesRegresi LogistikIdaAyu Dyantari Ari Putri50% (2)
- Latihan Do - File Syntax Stata IFLSDocument11 pagesLatihan Do - File Syntax Stata IFLSmelvia erivaNo ratings yet
- Dasar Analisis BerkalaDocument27 pagesDasar Analisis Berkalakurnia millati100% (1)
- Regresi Ridge Untuk Mengatasi MultikolinieritasDocument12 pagesRegresi Ridge Untuk Mengatasi MultikolinieritasElisabeth Brielin SinuNo ratings yet
- 5 7450 Esa310 102019 Distribusi ProbabilitasDocument26 pages5 7450 Esa310 102019 Distribusi ProbabilitasS Dewi SNo ratings yet
- Buku Analisis Regresi LogistikDocument54 pagesBuku Analisis Regresi LogistikAntòn CahyadhiéNo ratings yet
- Analisis Regresi Berganda Dengan Winbugs Dan MinitabDocument9 pagesAnalisis Regresi Berganda Dengan Winbugs Dan MinitabCanggih ShoffiNo ratings yet
- Ontoh Perhitungan ManualDocument13 pagesOntoh Perhitungan ManualPutu AryaNo ratings yet
- Analisis Regresi Linier BergandaDocument63 pagesAnalisis Regresi Linier BergandaAnies YulindaNo ratings yet
- Laporan Regresi Logistik OrdinalDocument11 pagesLaporan Regresi Logistik OrdinalKlinik RadiologiNo ratings yet
- REGRESI LOGISTIKDocument20 pagesREGRESI LOGISTIKTantry Syam0% (1)
- REGRESI ROBUST METODEDocument9 pagesREGRESI ROBUST METODEfienkamaretaNo ratings yet
- REGRESIDocument8 pagesREGRESIaffanNo ratings yet
- Analisis Regresi LogistikDocument20 pagesAnalisis Regresi LogistikPurwanti RahayuNo ratings yet
- Bahan Ajar Tentang Regresi LogistikDocument19 pagesBahan Ajar Tentang Regresi LogistikmasrohNo ratings yet
- Pengujian Pada Regresi Ganda (13-14)Document39 pagesPengujian Pada Regresi Ganda (13-14)Diani LianitaNo ratings yet
- SURVEI DESAIN SAMPELDocument19 pagesSURVEI DESAIN SAMPELGalih Restu PamelaNo ratings yet
- Proposal Penelitian CeriaDocument30 pagesProposal Penelitian CeriaEnjiNo ratings yet
- (Suhartono) Analisis Data Statistik Dengan RDocument306 pages(Suhartono) Analisis Data Statistik Dengan RSusi Mahanani92% (26)
- Kuliah 6Document124 pagesKuliah 6Lani Dewi AviatningsihNo ratings yet
- Modul 2 Analisis Data KategorikDocument21 pagesModul 2 Analisis Data KategorikNina Fannani100% (1)
- Tabel Kontingensi 2x2Document25 pagesTabel Kontingensi 2x2Puput ArfiantaNo ratings yet
- REGRESI LOGIS MULTINOMIALDocument18 pagesREGRESI LOGIS MULTINOMIALArlene Henny HiarieyNo ratings yet
- Pertemuan 5 Coverage and Nonresponse ErrorDocument47 pagesPertemuan 5 Coverage and Nonresponse ErrorYolandaRizkieApriliaNo ratings yet
- Analisis Statistika NonparametrikDocument68 pagesAnalisis Statistika NonparametrikChevi Kurnia R EdogawaNo ratings yet
- REGRESI BERGANDADocument12 pagesREGRESI BERGANDAIsna AfifahNo ratings yet
- REGRESI BERGANDADocument21 pagesREGRESI BERGANDAdrs.wiranto100% (1)
- Discrete Choice ExperimentDocument5 pagesDiscrete Choice ExperimentSOFI ZUHAIDANo ratings yet
- Metode Maks Likelihood RegresiDocument12 pagesMetode Maks Likelihood RegresinindydyyNo ratings yet
- Makalah Penaksiran Rasio, Regresi & Beda (Fix)Document48 pagesMakalah Penaksiran Rasio, Regresi & Beda (Fix)Aghnia Fauziah SaharNo ratings yet
- Outlier GhozaliDocument12 pagesOutlier Ghozalimoses dicky100% (1)
- Review Jurnal M8 08161032 08161002 08171016 08171072 PDFDocument133 pagesReview Jurnal M8 08161032 08161002 08171016 08171072 PDFIbtisamah Qomala AprilianiNo ratings yet
- Analisis Regresi Linier BergandaDocument9 pagesAnalisis Regresi Linier BergandaJoko Tri WahyudiNo ratings yet
- Estimasi ParameterDocument11 pagesEstimasi ParameterStrong WordNo ratings yet
- Uji HipotesisDocument35 pagesUji HipotesisTrias Suci Helina P50% (2)
- Modul PKS 4Document26 pagesModul PKS 4Muhammad NafisNo ratings yet
- Laporan Praktikum Regresi Logistik BinerDocument21 pagesLaporan Praktikum Regresi Logistik BinerFadhila IsnainiNo ratings yet
- Analisis Runtun Waktu Menggunakan SMA, WMA, dan EMA pada Saham PT. Perdana Bangun Pusaka TbkDocument17 pagesAnalisis Runtun Waktu Menggunakan SMA, WMA, dan EMA pada Saham PT. Perdana Bangun Pusaka TbkHALIMA TUSYAKDIAHNo ratings yet
- ANOVA: Analisis Varian Satu dan Dua ArahDocument10 pagesANOVA: Analisis Varian Satu dan Dua ArahApriyandiNo ratings yet
- Z - Artikel Tentang WarpplsDocument45 pagesZ - Artikel Tentang WarpplsAgus SaefudinNo ratings yet
- Regresi Logistik Menggunakan SPSSDocument19 pagesRegresi Logistik Menggunakan SPSSSiti Rosidah0% (1)
- Missing ValueDocument17 pagesMissing ValueLia Puji Astuti100% (1)
- Panduan Lengkap Menguasai Statistik Dengan SPSS 17 PDFDocument23 pagesPanduan Lengkap Menguasai Statistik Dengan SPSS 17 PDFrajasinga_45No ratings yet
- REGRESI LINEARDocument9 pagesREGRESI LINEARMuhammad SyahNo ratings yet
- Metodologi Penelitian Pertemuan 15Document10 pagesMetodologi Penelitian Pertemuan 15Tati SupartiniNo ratings yet
- Spss SGDDocument38 pagesSpss SGDuddadex100% (1)
- PSAP 07 Akrual 10102014Document13 pagesPSAP 07 Akrual 10102014Hariadi Haezer F SihombingNo ratings yet