You might also like
- Craftsman Shop Vac ManualDocument16 pagesCraftsman Shop Vac ManualRandy MarmerNo ratings yet
- ADHD Rating Scales and CPT Tools Predict Reading FluencyDocument29 pagesADHD Rating Scales and CPT Tools Predict Reading FluencyRandy MarmerNo ratings yet
- Machine LearningDocument56 pagesMachine LearningMani Vrs100% (3)
- Lab Report Experiment 5Document4 pagesLab Report Experiment 5Czarina mantuano100% (2)
- Cellular Patterns BBDocument3 pagesCellular Patterns BBRandy MarmerNo ratings yet
- Anesthesia Q&A - CPT Exam PrepDocument15 pagesAnesthesia Q&A - CPT Exam PrepRandy Marmer82% (22)
- Ball MillsDocument8 pagesBall MillsBoy Alfredo PangaribuanNo ratings yet
- Machine Learning: Engr. Ejaz AhmadDocument54 pagesMachine Learning: Engr. Ejaz AhmadejazNo ratings yet
- Lick de John ColtraneDocument21 pagesLick de John Coltranebastosgtr86% (7)
- Detect credit card fraud with machine learning modelsDocument20 pagesDetect credit card fraud with machine learning modelsVishal Sharma100% (1)
- Case Study-R12 12Document81 pagesCase Study-R12 12ranjitpandeyNo ratings yet
- Hot Bolting FPSO BrazilDocument1 pageHot Bolting FPSO BrazilKhan Arshi100% (1)
- Assignment R New 1Document26 pagesAssignment R New 1Sohel RanaNo ratings yet
- Reduce Household Emissions by 30Document1,010 pagesReduce Household Emissions by 30James Albert BarreraNo ratings yet
- Insulation Castables Application Procedure - Rev-2 - PDFDocument10 pagesInsulation Castables Application Procedure - Rev-2 - PDFNatarajan MurugesanNo ratings yet
- Nextgen Healthcare Ebook Data Analytics Healthcare Edu35Document28 pagesNextgen Healthcare Ebook Data Analytics Healthcare Edu35Randy Marmer100% (1)
- 4503 Rc158 010d Machinelearning 1Document6 pages4503 Rc158 010d Machinelearning 1AhsanAnisNo ratings yet
- A Short Introduction To The Caret Package: Max Kuhn June 20, 2013Document10 pagesA Short Introduction To The Caret Package: Max Kuhn June 20, 2013Renukha PannalaNo ratings yet
- B Ridge - and - Lasso - RegressionDocument5 pagesB Ridge - and - Lasso - RegressionGabriel GheorgheNo ratings yet
- A Short Introduction To CaretDocument10 pagesA Short Introduction To CaretblacngNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionParth MehtaNo ratings yet
- Diabetes Machine Learning Case StudyDocument10 pagesDiabetes Machine Learning Case StudyAbhising100% (1)
- Procedure GLMDocument37 pagesProcedure GLMMauricio González PalacioNo ratings yet
- Maxbox - Starter67 Machine LearningDocument7 pagesMaxbox - Starter67 Machine LearningMax KleinerNo ratings yet
- Week 7 Laboratory ActivityDocument12 pagesWeek 7 Laboratory ActivityGar NoobNo ratings yet
- Gradient Descent and Regularization for Neural Network OptimizationDocument37 pagesGradient Descent and Regularization for Neural Network OptimizationKamakshi SubramaniamNo ratings yet
- Functions and PackagesDocument7 pagesFunctions and PackagesNur SyazlianaNo ratings yet
- Benchmarking MLDocument9 pagesBenchmarking MLYentl HendrickxNo ratings yet
- R AssignmentDocument8 pagesR AssignmentTunaNo ratings yet
- P05 The Regression Pipeline - Training and Testing AnsDocument13 pagesP05 The Regression Pipeline - Training and Testing AnsYONG LONG KHAWNo ratings yet
- 41 Perusse Alexander Aperusse PDFDocument7 pages41 Perusse Alexander Aperusse PDFAnurita MathurNo ratings yet
- Homework Assignment 3 Homework Assignment 3Document10 pagesHomework Assignment 3 Homework Assignment 3Ido AkovNo ratings yet
- Whole ML PDF 1614408656Document214 pagesWhole ML PDF 1614408656Kshatrapati Singh100% (1)
- Factor Analysis Source Code AppendixDocument20 pagesFactor Analysis Source Code Appendixpratik zankeNo ratings yet
- Salinan Dari Untitled0.Ipynb - ColaboratoryDocument3 pagesSalinan Dari Untitled0.Ipynb - ColaboratoryDandi Rifa'i TariganNo ratings yet
- Lab 3. Linear Regression 230223Document7 pagesLab 3. Linear Regression 230223ruso100% (1)
- Problem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDocument24 pagesProblem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDarnell LarsenNo ratings yet
- Machine Learning Random Forest Algorithm - JavatpointDocument14 pagesMachine Learning Random Forest Algorithm - JavatpointRAMZI AzeddineNo ratings yet
- Bda AssignDocument15 pagesBda AssignAishwarya BiradarNo ratings yet
- A1Document8 pagesA1DASHPAGALNo ratings yet
- Linear Regression Using RDocument24 pagesLinear Regression Using ROrtodoxieNo ratings yet
- Simple Statistics Functions in RDocument41 pagesSimple Statistics Functions in RTonyNo ratings yet
- Labpractice 2Document29 pagesLabpractice 2Rajashree Das100% (1)
- zerox readyDocument21 pageszerox readygowrishankar nayanaNo ratings yet
- R Unit 4th and 5thDocument17 pagesR Unit 4th and 5thArshad BegNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionChichi Jnr100% (1)
- Machine Learning Lab Manual 06Document8 pagesMachine Learning Lab Manual 06Raheel Aslam100% (1)
- Logistic Regression Implementation in R: The DatasetDocument8 pagesLogistic Regression Implementation in R: The DatasetsuprabhattNo ratings yet
- Jeffrey Williams (20221013) 3Document21 pagesJeffrey Williams (20221013) 3JEFFREY WILLIAMS P M 20221013No ratings yet
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- Multinomial Logit Models in RDocument8 pagesMultinomial Logit Models in RPáblo DiasNo ratings yet
- SC Lab File Fayiz PDFDocument29 pagesSC Lab File Fayiz PDFfayizpNo ratings yet
- Estiven - Hurtado.Santos - Regresión Con Varios AlgoritmosDocument16 pagesEstiven - Hurtado.Santos - Regresión Con Varios AlgoritmosEstiven Hurtado SantosNo ratings yet
- TD2345Document3 pagesTD2345ashitaka667No ratings yet
- 9805 MBAex PredAnalBigDataMar22Document11 pages9805 MBAex PredAnalBigDataMar22harishcoolanandNo ratings yet
- 3 Cluster Customer Analysis Using K-MeansDocument5 pages3 Cluster Customer Analysis Using K-MeansXuanli XiongNo ratings yet
- Charmi Shah 20bcp299 Lab2Document7 pagesCharmi Shah 20bcp299 Lab2Princy100% (1)
- Regresion Logistic - Odt 1Document8 pagesRegresion Logistic - Odt 1Geofrey Julius ZellahNo ratings yet
- Solution 3.1Document4 pagesSolution 3.1Adnan KianiNo ratings yet
- Import As Import As From Import As Import As Import AsDocument3 pagesImport As Import As From Import As Import As Import AsDeepesh YadavNo ratings yet
- KVA Anusha - PGP12021 - BADocument8 pagesKVA Anusha - PGP12021 - BAAditi Pareek100% (1)
- Advanced Statistics-ProjectDocument16 pagesAdvanced Statistics-Projectvivek rNo ratings yet
- Using MaxlikDocument20 pagesUsing MaxlikJames HotnielNo ratings yet
- Chapter - 5 ArrayDocument23 pagesChapter - 5 Arraybeshahashenafe20No ratings yet
- Georglm: A Package For Generalised Linear Spatial Models Introductory SessionDocument10 pagesGeorglm: A Package For Generalised Linear Spatial Models Introductory SessionAlvaro Ernesto Garzon GarzonNo ratings yet
- 1 - An Introduction To Machine Learning With Scikit-LearnDocument9 pages1 - An Introduction To Machine Learning With Scikit-Learnyati kumariNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Data Analysis and Evaluation Methods ComparisonDocument11 pagesData Analysis and Evaluation Methods ComparisonJelena NađNo ratings yet
- Jeffrey Williams (20221013) 4Document27 pagesJeffrey Williams (20221013) 4JEFFREY WILLIAMS P M 20221013No ratings yet
- Maxbox Starter60 Machine LearningDocument8 pagesMaxbox Starter60 Machine LearningMax KleinerNo ratings yet
- Efficient Python Tricks and Tools For Data Scientists - by Khuyen TranDocument20 pagesEfficient Python Tricks and Tools For Data Scientists - by Khuyen TranKhagenNo ratings yet
- CPT E&M Level 4 Reference CardDocument2 pagesCPT E&M Level 4 Reference CardRandy MarmerNo ratings yet
- Instructions for Using Vaginal DilatorsDocument2 pagesInstructions for Using Vaginal DilatorsRandy MarmerNo ratings yet
- Top 10 Interview Questions PDFDocument20 pagesTop 10 Interview Questions PDFSaket SinhaNo ratings yet
- E&M Time-Based Coding GuidelinesDocument2 pagesE&M Time-Based Coding GuidelinesRandy MarmerNo ratings yet
- Delay in Treatment Intensification Increases The Risks of Cardiovascular Events in Patients With Type 2 DiabetesDocument17 pagesDelay in Treatment Intensification Increases The Risks of Cardiovascular Events in Patients With Type 2 DiabetesRandy MarmerNo ratings yet
- Analyzing Data Measured by Individual Likert-Type ItemsDocument5 pagesAnalyzing Data Measured by Individual Likert-Type ItemsCheNad NadiaNo ratings yet
- Lister Drug Protocol InstructionsDocument3 pagesLister Drug Protocol InstructionsRandy MarmerNo ratings yet
- The Differences Between Modifiers 51 and 59Document5 pagesThe Differences Between Modifiers 51 and 59Randy MarmerNo ratings yet
- Is That Paper Really Due Today?'': Differences in First-Generation and Traditional College Students' Understandings of Faculty ExpectationsDocument22 pagesIs That Paper Really Due Today?'': Differences in First-Generation and Traditional College Students' Understandings of Faculty ExpectationsRandy MarmerNo ratings yet
- What Is The Patient S RightDocument1 pageWhat Is The Patient S RightRandy MarmerNo ratings yet
- Rails 3 Cheat SheetsDocument6 pagesRails 3 Cheat SheetsdrouchyNo ratings yet
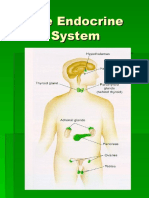
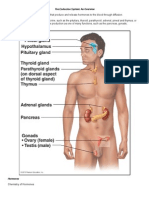
- Hormones Endocrine SystemDocument35 pagesHormones Endocrine SystemRandy MarmerNo ratings yet
- Endocrine SystemDocument24 pagesEndocrine Systemfrowee23No ratings yet
- The Endocrine System: An OverviewDocument27 pagesThe Endocrine System: An OverviewRandy MarmerNo ratings yet
- IO Acronyms and Glossary BasicsDocument6 pagesIO Acronyms and Glossary BasicsRandy MarmerNo ratings yet
- EM StepbyStep 2013 1 PDFDocument9 pagesEM StepbyStep 2013 1 PDFRandy MarmerNo ratings yet
- Picture - Adh Hormone - Photo Gallery SearchDocument8 pagesPicture - Adh Hormone - Photo Gallery SearchRandy MarmerNo ratings yet
- Endocrine Disorder ChartDocument4 pagesEndocrine Disorder ChartRandy MarmerNo ratings yet
- An Evaluation of Holden Arboretum's Shade Tree CollectionDocument3 pagesAn Evaluation of Holden Arboretum's Shade Tree CollectionRandy MarmerNo ratings yet
- Unbiased Review of Digital Diagnostic Images in Practice - Informatics Prototype and Pilot StudyDocument10 pagesUnbiased Review of Digital Diagnostic Images in Practice - Informatics Prototype and Pilot StudyRandy MarmerNo ratings yet
- Case Study Imaging Informatics Pinehurst RadiologyDocument2 pagesCase Study Imaging Informatics Pinehurst RadiologyRick SmithNo ratings yet
- NI Tutorial 4937 enDocument1 pageNI Tutorial 4937 enRandy MarmerNo ratings yet
- CassandraQueryLanguage Quick Reference CardDocument2 pagesCassandraQueryLanguage Quick Reference CardRandy Marmer100% (1)
- Ee09 704 - Electrical Machine Design Model QPDocument2 pagesEe09 704 - Electrical Machine Design Model QPGīřïşh McNo ratings yet
- Final Defence 2078Document43 pagesFinal Defence 2078XxxNo ratings yet
- Agentur H. Willems: Tel.: +49-421-52009-0 List of Manufacturers Fax: +49-421-545858Document5 pagesAgentur H. Willems: Tel.: +49-421-52009-0 List of Manufacturers Fax: +49-421-545858Trần Minh NhậtNo ratings yet
- BPO2-Module 9 PROJECT PLANDocument16 pagesBPO2-Module 9 PROJECT PLANJudame Charo ZozobradoNo ratings yet
- Modified 0-30V - 0-3A Variable Power Supply - Rev.2Document2 pagesModified 0-30V - 0-3A Variable Power Supply - Rev.2Manuel Cereijo NeiraNo ratings yet
- Windmill ABB MachinesDocument6 pagesWindmill ABB MachinesRadu BabauNo ratings yet
- Rectify Binary Plate Efficiency BubblesDocument4 pagesRectify Binary Plate Efficiency BubblesCsaba AndrásNo ratings yet
- Gas Sensors: Jiturvi Chokshi ENPM-808BDocument27 pagesGas Sensors: Jiturvi Chokshi ENPM-808Banon_44955929No ratings yet
- CRCM Manual 2 9 16Document33 pagesCRCM Manual 2 9 16Kamagara Roland AndrewNo ratings yet
- Leg Foot Massager 1026 ManualDocument5 pagesLeg Foot Massager 1026 ManualBhushan BhikeNo ratings yet
- TI Oxydur PTB 206 - en PDFDocument5 pagesTI Oxydur PTB 206 - en PDFgonzalogvargas01100% (1)
- Sooad ManualDocument19 pagesSooad ManualRakhiNo ratings yet
- XXXXXXX XXXXXXX: Pour Exemple: Pour Exemple: ArteorDocument5 pagesXXXXXXX XXXXXXX: Pour Exemple: Pour Exemple: ArteorGilbert MartinezNo ratings yet
- FADesignManual v2 14 SP PDFDocument88 pagesFADesignManual v2 14 SP PDFpandu lambangNo ratings yet
- Section11 Proportional ValvesDocument52 pagesSection11 Proportional ValvesyogitatanavadeNo ratings yet
- FST DFS Ge-EgdDocument5 pagesFST DFS Ge-EgdEric DunnNo ratings yet
- The NT Insider: Writing Filters Is Hard WorkDocument32 pagesThe NT Insider: Writing Filters Is Hard WorkOveja NegraNo ratings yet
- High Build Epoxy Coating for Hulls and Ballast TanksDocument3 pagesHigh Build Epoxy Coating for Hulls and Ballast Tankskasosei0% (1)
- A JIT Lot Splitting Model For Supply Chain Management Enhancing Buyer Supplier Linkage 2003 International Journal of Production EconomicsDocument10 pagesA JIT Lot Splitting Model For Supply Chain Management Enhancing Buyer Supplier Linkage 2003 International Journal of Production EconomicsDaniel Renaldo SimanjuntakNo ratings yet
- Chapter 4.1 Basic Call Procedure (ED01 - 53 - EN)Document53 pagesChapter 4.1 Basic Call Procedure (ED01 - 53 - EN)quaderbtech06No ratings yet
- Flow Charts Option: StartDocument13 pagesFlow Charts Option: StartbalabooksNo ratings yet
- CHM096-Tutorial 1 (Alkanes & Alkenes)Document4 pagesCHM096-Tutorial 1 (Alkanes & Alkenes)Anonymous RD1CrAINo ratings yet
- Custom Validation ExampleDocument4 pagesCustom Validation ExampleAbdul Bais StanikzaiNo ratings yet
- The B-GON Solution: To Mist EliminationDocument20 pagesThe B-GON Solution: To Mist EliminationDimitris Sardis LNo ratings yet
- LMS Adaptive FiltersDocument14 pagesLMS Adaptive FiltersalialibabaNo ratings yet