You might also like
- Cek SubmitDocument40 pagesCek SubmitMulya Nurmansyah ArdisasmitaNo ratings yet
- Basic Probability Theory For Bio Medical Engineers - JohnD. EnderleDocument136 pagesBasic Probability Theory For Bio Medical Engineers - JohnD. Enderlejustwoow100% (1)
- Dosen Pembimbing Yang TersediaDocument187 pagesDosen Pembimbing Yang TersediaMulya Nurmansyah ArdisasmitaNo ratings yet
- UmlDocument120 pagesUmlRudrani SarkarNo ratings yet
- Alamat SikdaDocument1 pageAlamat SikdaMulya Nurmansyah ArdisasmitaNo ratings yet
- 27 1Document213 pages27 1Mulya Nurmansyah ArdisasmitaNo ratings yet
- Advanced Probability Theory For Bio Medical Engineers - John D. EnderleDocument108 pagesAdvanced Probability Theory For Bio Medical Engineers - John D. Enderleatul626100% (2)
- UnixDocument1 pageUnixMulya Nurmansyah ArdisasmitaNo ratings yet
- I Jcs It 2014050540Document5 pagesI Jcs It 2014050540Mulya Nurmansyah ArdisasmitaNo ratings yet
- Schema Integration Between Object-Oriented Databases: Ching-Ming ChaoDocument8 pagesSchema Integration Between Object-Oriented Databases: Ching-Ming ChaoMulya Nurmansyah ArdisasmitaNo ratings yet
- Prototyping Tools and TechniquesDocument41 pagesPrototyping Tools and Techniquesblaze3No ratings yet
- Chart Suggestions - A Thought-StarterDocument1 pageChart Suggestions - A Thought-StarterDoc AllaínNo ratings yet
- Rescuing Data From Decaying and Moribund Clinical Information SystemsDocument6 pagesRescuing Data From Decaying and Moribund Clinical Information SystemsMulya Nurmansyah ArdisasmitaNo ratings yet
- Create DFDs for Lemonade StandDocument20 pagesCreate DFDs for Lemonade Standsharoo501No ratings yet
- Ijcsi 9 5 1 329 338Document10 pagesIjcsi 9 5 1 329 338Mulya Nurmansyah ArdisasmitaNo ratings yet
- Professionalism in Interactions With Other Health ProfessionalsDocument16 pagesProfessionalism in Interactions With Other Health ProfessionalsMulya Nurmansyah ArdisasmitaNo ratings yet
- J Am Med Inform Assoc 2011 Borlawsky Amiajnl 2011 000354Document5 pagesJ Am Med Inform Assoc 2011 Borlawsky Amiajnl 2011 000354Mulya Nurmansyah ArdisasmitaNo ratings yet
- PRISM DescriptionOfToolsDocument38 pagesPRISM DescriptionOfToolsMulya Nurmansyah ArdisasmitaNo ratings yet
- Film Cari Versi RendahDocument1 pageFilm Cari Versi RendahMulya Nurmansyah ArdisasmitaNo ratings yet
- SA HB 137-2013 E Health Interoperability FrameworkDocument72 pagesSA HB 137-2013 E Health Interoperability FrameworkMulya Nurmansyah ArdisasmitaNo ratings yet
- Ehealth in IndonesiaDocument24 pagesEhealth in IndonesiaOemmaemNo ratings yet
- Denah Dasar1Document1 pageDenah Dasar1Mulya Nurmansyah ArdisasmitaNo ratings yet
- ,17 (5 29 (510 (17$/1 ( 27,$7,1 %2' $) &7&,1%,1) '2& 217+ (:+2) 5$0 (:25.&219 (17,21 1ryhpehu 2172%$&&2&21752/ 7klugvhvvlrq 3urylvlrqdodjhqgdlwhpDocument47 pages,17 (5 29 (510 (17$/1 ( 27,$7,1 %2' $) &7&,1%,1) '2& 217+ (:+2) 5$0 (:25.&219 (17,21 1ryhpehu 2172%$&&2&21752/ 7klugvhvvlrq 3urylvlrqdodjhqgdlwhpMulya Nurmansyah ArdisasmitaNo ratings yet
- Patients' Rights in Medical CareDocument17 pagesPatients' Rights in Medical CareMulya Nurmansyah ArdisasmitaNo ratings yet
- Asap CobaDocument1 pageAsap CobaMulya Nurmansyah ArdisasmitaNo ratings yet
- Modeling His 1Document8 pagesModeling His 1Mulya Nurmansyah ArdisasmitaNo ratings yet
- ,17 (5 29 (510 (17$/1 ( 27,$7,1 %2' $) &7&,1%,1) '2& 217+ (:+2) 5$0 (:25.&219 (17,21 1ryhpehu 2172%$&&2&21752/ 7klugvhvvlrq 3urylvlrqdodjhqgdlwhpDocument47 pages,17 (5 29 (510 (17$/1 ( 27,$7,1 %2' $) &7&,1%,1) '2& 217+ (:+2) 5$0 (:25.&219 (17,21 1ryhpehu 2172%$&&2&21752/ 7klugvhvvlrq 3urylvlrqdodjhqgdlwhpMulya Nurmansyah ArdisasmitaNo ratings yet
- File FTPDocument1 pageFile FTPMulya Nurmansyah ArdisasmitaNo ratings yet
- Trollandtoad Heroclix Figures and ComicsDocument8 pagesTrollandtoad Heroclix Figures and ComicsMulya Nurmansyah ArdisasmitaNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- P.3 Comprehension SchemeDocument4 pagesP.3 Comprehension Schemeice200mNo ratings yet
- Out of The Classroom and Into The City The Use ofDocument13 pagesOut of The Classroom and Into The City The Use ofLuciaNo ratings yet
- Trauma On Brain DevelopmentDocument29 pagesTrauma On Brain DevelopmentChirra Williams100% (1)
- Executive Forum: Leading in a VUCA WorldDocument6 pagesExecutive Forum: Leading in a VUCA WorldZulkarnainNo ratings yet
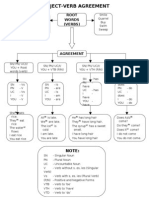
- Subject-Verb Agreement RulesDocument1 pageSubject-Verb Agreement RulesMohd AsyrafNo ratings yet
- Dement and Kleitman Short QuestionsDocument12 pagesDement and Kleitman Short QuestionsUsamaNo ratings yet
- Embodied Affectivity: On Moving and Being Moved: Thomas Fuchs and Sabine C. KochDocument12 pagesEmbodied Affectivity: On Moving and Being Moved: Thomas Fuchs and Sabine C. Kochma ceciNo ratings yet
- Interpretative Sociology and Axiological Neutrality in Max Weber and Werner SombartDocument17 pagesInterpretative Sociology and Axiological Neutrality in Max Weber and Werner Sombartionelam8679No ratings yet
- German Learning Course MaterialDocument66 pagesGerman Learning Course MaterialRobin100% (1)
- Module 25 Introduction To StylisticsDocument31 pagesModule 25 Introduction To Stylisticsshella mae pormento100% (2)
- Module 4-Section 1 GLOBAL CULTURE AND MEDIADocument7 pagesModule 4-Section 1 GLOBAL CULTURE AND MEDIAGIL BARRY ORDONEZNo ratings yet
- Multipurpose Multiplication TablesDocument54 pagesMultipurpose Multiplication Tablesnicksonwong89No ratings yet
- Silviana Rahayu Hersa - 8.3 - Remedial Pas PDFDocument14 pagesSilviana Rahayu Hersa - 8.3 - Remedial Pas PDFDesfi Nurrachma hersaNo ratings yet
- Catch Up Friday Gr10 Mar1Document3 pagesCatch Up Friday Gr10 Mar1milafer dabanNo ratings yet
- Conditionals 2nd BachilleratoDocument2 pagesConditionals 2nd BachilleratoFatima VazquezNo ratings yet
- What New Information Did I Learn From This Activity? DiscussDocument2 pagesWhat New Information Did I Learn From This Activity? DiscussJulius CabinganNo ratings yet
- A Description of Colloquial GuaranDocument125 pagesA Description of Colloquial GuaranBerat GültürkNo ratings yet
- Emotional Intelligence Participant Manual CoulibalyDocument20 pagesEmotional Intelligence Participant Manual Coulibalybrocklyn311No ratings yet
- Cause & Effect: English LessonDocument11 pagesCause & Effect: English LessonAditya DelfiantoNo ratings yet
- DLL - MTB 3 - Q2 - Catch Up ActivityDocument3 pagesDLL - MTB 3 - Q2 - Catch Up ActivityHazel Israel BacnatNo ratings yet
- IntroductionDocument8 pagesIntroductionturdygazyyeva.aigerimNo ratings yet
- Business Communication NotesDocument14 pagesBusiness Communication NotesAnimesh MayankNo ratings yet
- Pedagogical Grammar Dr. Lazgeen Mohammed Raouf Aims, Objectives and OutcomesDocument22 pagesPedagogical Grammar Dr. Lazgeen Mohammed Raouf Aims, Objectives and OutcomesMohammed DoskiNo ratings yet
- Deep Learning: Data Mining: Advanced AspectsDocument131 pagesDeep Learning: Data Mining: Advanced AspectsmakeosNo ratings yet
- Syllabus in Assessment and Evaluation in MathematicsDocument7 pagesSyllabus in Assessment and Evaluation in MathematicsJhielaMaeMacaraigNo ratings yet
- Kenneth E. Bruscia-Defining Music Therapy-Barcelona Pub (2014)Document422 pagesKenneth E. Bruscia-Defining Music Therapy-Barcelona Pub (2014)Cristina Maria Oltean100% (14)
- Ipn-Upiicsa Teacher's Training Course 1 Outline Centro de Idiomas PropedeuticsDocument2 pagesIpn-Upiicsa Teacher's Training Course 1 Outline Centro de Idiomas PropedeuticsLillian LöweNo ratings yet
- 001-Supervision Essentials For Emotion-Focused TherapyDocument181 pages001-Supervision Essentials For Emotion-Focused TherapyJenny Jin100% (1)
- TRỌNG ÂM TỪ 3 ÂM TIẾT 12Document2 pagesTRỌNG ÂM TỪ 3 ÂM TIẾT 12tuannguyen7422No ratings yet
- Fs 5 - Episode 1Document3 pagesFs 5 - Episode 1api-33461747095% (20)