You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Lecture I PDFDocument7 pagesLecture I PDFjegosssNo ratings yet
- 1 204w PDFDocument44 pages1 204w PDFjegosssNo ratings yet
- MIT2 854F10 Inv PDFDocument78 pagesMIT2 854F10 Inv PDFjegosssNo ratings yet
- 9a. Rules in Production SystemsDocument21 pages9a. Rules in Production SystemsjegosssNo ratings yet
- (I K Ev2 Ysi) CO332 PDFDocument5 pages(I K Ev2 Ysi) CO332 PDFjegosssNo ratings yet
- CH 1Document25 pagesCH 1Karthi SanNo ratings yet
- Ijita10 1 p11 PDFDocument8 pagesIjita10 1 p11 PDFjegosssNo ratings yet
- Supply Chain Fundamentals & Segmentation Analysis: Chris Caplice ESD.260/15.770/1.260 Logistics Systems Sept 2006Document27 pagesSupply Chain Fundamentals & Segmentation Analysis: Chris Caplice ESD.260/15.770/1.260 Logistics Systems Sept 2006Jovan ĆetkovićNo ratings yet
- BusinessAdministration1 01 PDFDocument34 pagesBusinessAdministration1 01 PDFjegosssNo ratings yet
- GuidManaLabSC v2 PDFDocument86 pagesGuidManaLabSC v2 PDFjegosssNo ratings yet
- AHP - HunjakT - Cingula Securities Portfolio Modelling For Emerging MarketsDocument9 pagesAHP - HunjakT - Cingula Securities Portfolio Modelling For Emerging MarketsjegosssNo ratings yet
- PDFDocument39 pagesPDFjegosssNo ratings yet
- Chapter1 PDFDocument9 pagesChapter1 PDFjegosssNo ratings yet
- PDFDocument39 pagesPDFjegosssNo ratings yet
- PDFDocument7 pagesPDFjegosssNo ratings yet
- AHP IslamR MBNQA PaperDocument22 pagesAHP IslamR MBNQA PaperjegosssNo ratings yet
- 421read Lab PDFDocument1 page421read Lab PDFjegosssNo ratings yet
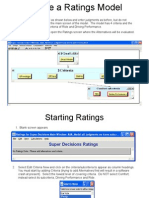
- Tutorial - 3 - Creating An AHP Ratings ModelDocument9 pagesTutorial - 3 - Creating An AHP Ratings ModeljegosssNo ratings yet
- Introduction To The ANP A Single Criterion For Evaluating A DecisionDocument90 pagesIntroduction To The ANP A Single Criterion For Evaluating A DecisionjegosssNo ratings yet
- AHP - MamatN Singular Value Decomposition Vs Duality Approach in AHPDocument9 pagesAHP - MamatN Singular Value Decomposition Vs Duality Approach in AHPjegosssNo ratings yet
- Claudio Garuti, Isabel Spencer: Keywords: ANP, Fractals, System Representation, Parallelisms, HistoryDocument10 pagesClaudio Garuti, Isabel Spencer: Keywords: ANP, Fractals, System Representation, Parallelisms, HistoryjegosssNo ratings yet
- AHP Ismayilova Ozdemir Gasimov Course AssignmentsDocument26 pagesAHP Ismayilova Ozdemir Gasimov Course AssignmentsVidip MathurNo ratings yet
- Tutorial - 2 - Sensitivity in AHP ModelsDocument20 pagesTutorial - 2 - Sensitivity in AHP ModelsjegosssNo ratings yet
- AHP++++++ Course Slides 3 NetworksDocument198 pagesAHP++++++ Course Slides 3 NetworksjegosssNo ratings yet
- Tutorial - 4 - Changing From AHP To ANP ThinkingDocument16 pagesTutorial - 4 - Changing From AHP To ANP ThinkingjegosssNo ratings yet
- Claudio Garuti, Isabel Spencer: Keywords: ANP, Fractals, System Representation, Parallelisms, HistoryDocument10 pagesClaudio Garuti, Isabel Spencer: Keywords: ANP, Fractals, System Representation, Parallelisms, HistoryjegosssNo ratings yet
- AHP - 1 - Rozann - Preface To J of Math ModellingDocument1 pageAHP - 1 - Rozann - Preface To J of Math ModellingjegosssNo ratings yet
- AHP SaatyT Ideal and Distributive Modes RankPreservationDocument16 pagesAHP SaatyT Ideal and Distributive Modes RankPreservationjegosssNo ratings yet
- The Analytic Hierarchy Process (AHP) For Decision MakingDocument38 pagesThe Analytic Hierarchy Process (AHP) For Decision MakingjegosssNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- DPCA OHE Notice of Appeal 4-11-2018 FinalDocument22 pagesDPCA OHE Notice of Appeal 4-11-2018 Finalbranax2000No ratings yet
- Perceptron Example (Practice Que)Document26 pagesPerceptron Example (Practice Que)uijnNo ratings yet
- 8 DaysDocument337 pages8 Daysprakab100% (1)
- Circle Midpoint Algorithm - Modified As Cartesian CoordinatesDocument10 pagesCircle Midpoint Algorithm - Modified As Cartesian Coordinateskamar100% (1)
- © Call Centre Helper: 171 Factorial #VALUE! This Will Cause Errors in Your CalculationsDocument19 pages© Call Centre Helper: 171 Factorial #VALUE! This Will Cause Errors in Your CalculationswircexdjNo ratings yet
- An Approach To The Aural Analysis of Emergent Musical FormsDocument25 pagesAn Approach To The Aural Analysis of Emergent Musical Formsmykhos0% (1)
- Light Body ActivationsDocument2 pagesLight Body ActivationsNaresh Muttavarapu100% (4)
- MBA Study On Organisational Culture and Its Impact On Employees Behaviour - 237652089Document64 pagesMBA Study On Organisational Culture and Its Impact On Employees Behaviour - 237652089sunitha kada55% (20)
- Investigation of Water Resources Projects - Preparation of DPRDocument148 pagesInvestigation of Water Resources Projects - Preparation of DPRN.J. PatelNo ratings yet
- Develop Your Kuji In Ability in Body and MindDocument7 pagesDevelop Your Kuji In Ability in Body and MindLenjivac100% (3)
- C1 Reading 1Document2 pagesC1 Reading 1Alejandros BrosNo ratings yet
- Nektar Impact LX25 (En)Document32 pagesNektar Impact LX25 (En)Camila Gonzalez PiatNo ratings yet
- STAR Worksheet Interviewing SkillsDocument1 pageSTAR Worksheet Interviewing SkillsCharity WacekeNo ratings yet
- C code snippets with answersDocument14 pagesC code snippets with answersqwerty6327No ratings yet
- 2-Eagan Model of CounsellingDocument23 pages2-Eagan Model of CounsellingVijesh V Kumar100% (4)
- New Microsoft Word DocumentDocument5 pagesNew Microsoft Word DocumentxandercageNo ratings yet
- Gpredict User Manual 1.2Document64 pagesGpredict User Manual 1.2Will JacksonNo ratings yet
- Sprite Graphics For The Commodore 64Document200 pagesSprite Graphics For The Commodore 64scottmac67No ratings yet
- 3D Holographic Projection Technology SeminarDocument28 pages3D Holographic Projection Technology Seminarniteshnks1993No ratings yet
- 62046PSYCHICSDocument1 page62046PSYCHICSs0hpokc310No ratings yet
- Proportions PosterDocument1 pageProportions Posterapi-214764900No ratings yet
- Mosek UserguideDocument81 pagesMosek UserguideadethroNo ratings yet
- Print Application FormDocument4 pagesPrint Application Formarjun guptaNo ratings yet
- Group 7 Scope StatementDocument17 pagesGroup 7 Scope Statementapi-335995226100% (4)
- Fault Tree AnalysisDocument5 pagesFault Tree AnalysisKrishna Kumar0% (1)
- Malla Reddy Engineering College (Autonomous)Document17 pagesMalla Reddy Engineering College (Autonomous)Ranjith KumarNo ratings yet
- Career DevelopmentDocument23 pagesCareer DevelopmentHaris Khan100% (1)
- Tracer Survey of Bsit Automotive GRADUATES BATCH 2015-2016 AT Cebu Technological UniversityDocument8 pagesTracer Survey of Bsit Automotive GRADUATES BATCH 2015-2016 AT Cebu Technological UniversityRichard Somocad JaymeNo ratings yet
- DEMO 2 Critical Reading As ReasoningDocument3 pagesDEMO 2 Critical Reading As ReasoningConnieRoseRamosNo ratings yet