You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Music TheoryDocument277 pagesMusic TheoryPhilip Mingin100% (5)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Scania DC09, DC13, DC16 Industrial Engines - Electrical System - CompressedDocument40 pagesScania DC09, DC13, DC16 Industrial Engines - Electrical System - CompressedMaurice ConnorNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Quarter3 Week4 ClimateDocument11 pagesQuarter3 Week4 ClimateJohn EdselNo ratings yet
- Unit2.SP - Mill.setting and ImbibitionDocument15 pagesUnit2.SP - Mill.setting and ImbibitionHari kantNo ratings yet
- Cookies and Chocolate in Chile 2018Document18 pagesCookies and Chocolate in Chile 2018Daniel Meza BarzenaNo ratings yet
- Chapter2 PDFDocument21 pagesChapter2 PDFDaniel Meza BarzenaNo ratings yet
- Univariate Time Series Analysis: Arnaud AmsellemDocument26 pagesUnivariate Time Series Analysis: Arnaud AmsellemDaniel Meza BarzenaNo ratings yet
- ARIMA Models in R PDFDocument1 pageARIMA Models in R PDFDaniel Meza BarzenaNo ratings yet
- Chapter2 PDFDocument21 pagesChapter2 PDFDaniel Meza BarzenaNo ratings yet
- Forecast Time Series-NotesDocument138 pagesForecast Time Series-NotesflorinNo ratings yet
- Data Science Cert for Python EngineersDocument1 pageData Science Cert for Python EngineersDaniel Meza BarzenaNo ratings yet
- Data Manipulation Certificate EarnedDocument1 pageData Manipulation Certificate EarnedDaniel Meza BarzenaNo ratings yet
- Covid19 Market Report v2Document38 pagesCovid19 Market Report v2Daniel Meza BarzenaNo ratings yet
- The Summarize Verb: David RobinsonDocument21 pagesThe Summarize Verb: David RobinsonDaniel Meza BarzenaNo ratings yet
- Line Plots: David RobinsonDocument27 pagesLine Plots: David RobinsonDaniel Meza BarzenaNo ratings yet
- Creating An RFM Summary Using Excel: Peter S. Fader Bruce G. S. Hardie December 2008Document7 pagesCreating An RFM Summary Using Excel: Peter S. Fader Bruce G. S. Hardie December 2008Daniel Meza BarzenaNo ratings yet
- Chapter1 PDFDocument25 pagesChapter1 PDFDaniel Meza BarzenaNo ratings yet
- Chapter1 PDFDocument25 pagesChapter1 PDFDaniel Meza BarzenaNo ratings yet
- Chapter1 PDFDocument25 pagesChapter1 PDFDaniel Meza BarzenaNo ratings yet
- Revistas JuanaDocument10 pagesRevistas JuanaDaniel Meza BarzenaNo ratings yet
- New Statistical Distributions For Group Counting Bernoulli 2011Document25 pagesNew Statistical Distributions For Group Counting Bernoulli 2011Daniel Meza BarzenaNo ratings yet
- Software Engineering For Data Scientist in PythonDocument1 pageSoftware Engineering For Data Scientist in PythonDaniel Meza BarzenaNo ratings yet
- Poynting OMNI A0098 BrochureDocument2 pagesPoynting OMNI A0098 BrochurekaminareNo ratings yet
- Welding robot aviation plug terminal definitionDocument4 pagesWelding robot aviation plug terminal definitionPhươngNguyễnNo ratings yet
- Maa 2.8 ExponentsDocument12 pagesMaa 2.8 ExponentsMuborakNo ratings yet
- Effort Distribution On Waterfall and AgileDocument12 pagesEffort Distribution On Waterfall and Agileanandapramanik100% (2)
- 5990-3781en Analisis de BiodieselDocument8 pages5990-3781en Analisis de BiodieselAlexis A.González San MartínNo ratings yet
- GR/KWH, KG/HR or Tons/Month.: ScopeDocument5 pagesGR/KWH, KG/HR or Tons/Month.: ScopeThaigroup CementNo ratings yet
- Periodic TableDocument1 pagePeriodic TableChemist MookaNo ratings yet
- Q1 - Answer KeyDocument2 pagesQ1 - Answer KeyJustine AligangaNo ratings yet
- Testing The AdapterDocument8 pagesTesting The AdapterrejnanNo ratings yet
- Surveying - Traverse Surveying - TraverseDocument13 pagesSurveying - Traverse Surveying - Traversebills100% (1)
- Angle Style, Pressure Relief Valves For Steam, Gas, and Liquid ServicesDocument14 pagesAngle Style, Pressure Relief Valves For Steam, Gas, and Liquid ServicesCHRISTIAN ZAVALANo ratings yet
- Custom Objects, Fields, Tabs, Related Lists, List ViewsDocument7 pagesCustom Objects, Fields, Tabs, Related Lists, List ViewsAjay GhugeNo ratings yet
- Think Aloud Strategy Effective for Teaching Narrative Text ComprehensionDocument8 pagesThink Aloud Strategy Effective for Teaching Narrative Text ComprehensionOxtapianus TawarikNo ratings yet
- Shape and angle detective game for kidsDocument21 pagesShape and angle detective game for kidsbemusaNo ratings yet
- 01 - Lesson Plan - Fractions - Decimal - PercentDocument4 pages01 - Lesson Plan - Fractions - Decimal - PercentAnthony MontoyaNo ratings yet
- Recurrent Neural Network-Based Robust NonsingularDocument13 pagesRecurrent Neural Network-Based Robust NonsingularDong HoangNo ratings yet
- Drive Fundamentals and DC Motor CharacteristicsDocument6 pagesDrive Fundamentals and DC Motor CharacteristicsKawooya CharlesNo ratings yet
- Microelectronic Circuit Design 5th Edition Jaeger Blalock Solution ManualDocument21 pagesMicroelectronic Circuit Design 5th Edition Jaeger Blalock Solution Manualruth100% (23)
- Fire ZoneDocument8 pagesFire ZoneKannan NNo ratings yet
- Practice Paper 1 Biology: WWW - Oxfordsecodary.co - UkDocument11 pagesPractice Paper 1 Biology: WWW - Oxfordsecodary.co - UkOHNo ratings yet
- Vesda Arrange Fire Alarm SystemDocument1 pageVesda Arrange Fire Alarm SystemGaurav Kumar SharmaNo ratings yet
- (17417899 - Reproduction) Understanding The Regulation of Pituitary Progesterone Receptor Expression and PhosphorylationDocument9 pages(17417899 - Reproduction) Understanding The Regulation of Pituitary Progesterone Receptor Expression and Phosphorylationتقوى اللهNo ratings yet
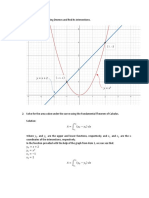
- Area Under The CurveDocument3 pagesArea Under The CurveReyland DumlaoNo ratings yet
- Exercise 1: Pressing Cheeses: Cheese ProductionDocument8 pagesExercise 1: Pressing Cheeses: Cheese ProductionAhmed HusseinNo ratings yet
- Pavan Kumar 1Document8 pagesPavan Kumar 1Anji ChNo ratings yet
- Vikramraju Updated Excel (EXCEL GOODIES)Document40 pagesVikramraju Updated Excel (EXCEL GOODIES)vikramrajuu0% (1)
- Animal and Plant CellDocument3 pagesAnimal and Plant CellElmer Tunggolh, Jr.No ratings yet