You might also like
- Chapter 1:introduction To Design of ExperimentsDocument20 pagesChapter 1:introduction To Design of ExperimentsSachin K KambleNo ratings yet
- Research Trends in Deep Reinforcement LearningDocument6 pagesResearch Trends in Deep Reinforcement LearningNil KosenkoNo ratings yet
- Reinforcement Learning in Robotics A SurveyDocument37 pagesReinforcement Learning in Robotics A Surveyaleong1No ratings yet
- DoeDocument37 pagesDoeSnehasish IsharNo ratings yet
- Industry DOEDocument73 pagesIndustry DOE蘇andrewNo ratings yet
- Deep Gamblers: Learning To Abstain With Portfolio TheoryDocument17 pagesDeep Gamblers: Learning To Abstain With Portfolio TheoryGeorge CheungNo ratings yet
- WHOLE BRAIN LEARNING SYSTEM STATISTICS MODULEDocument16 pagesWHOLE BRAIN LEARNING SYSTEM STATISTICS MODULEleo markNo ratings yet
- Etter To The Editor: Virtual Reality-Based Proficiency Test in Direct OphthalmosDocument2 pagesEtter To The Editor: Virtual Reality-Based Proficiency Test in Direct OphthalmosWalisson BarbosaNo ratings yet
- Unit 2 Experimental Design (Control Group Design and Two Factor Design)Document15 pagesUnit 2 Experimental Design (Control Group Design and Two Factor Design)Manisha BhavsarNo ratings yet
- Organon 2013Document11 pagesOrganon 2013Dominic GondweNo ratings yet
- Cloud Point Extraction-Spectrophotometric Method - A ReviewDocument4 pagesCloud Point Extraction-Spectrophotometric Method - A ReviewIjrei JournalNo ratings yet
- Binomial Test ExplainedDocument10 pagesBinomial Test ExplainedMarben OrogoNo ratings yet
- Reinforcement Learning From Demonstration: Madhur Singal 2015EE10908Document19 pagesReinforcement Learning From Demonstration: Madhur Singal 2015EE10908Madhur SingalNo ratings yet
- Determin Geolog7Document180 pagesDetermin Geolog7nathanael halawaNo ratings yet
- Test-Time Training With Self-Supervision For Generalization Under Distribution ShiftsDocument20 pagesTest-Time Training With Self-Supervision For Generalization Under Distribution ShiftsKowshik ThopalliNo ratings yet
- Design of ExperimentsDocument44 pagesDesign of ExperimentsJYNo ratings yet
- Chapter 1 Introduction to Designed Experiment: 許湘伶 Design and Analysis of Experiments (Douglas C. Montgomery)Document16 pagesChapter 1 Introduction to Designed Experiment: 許湘伶 Design and Analysis of Experiments (Douglas C. Montgomery)Chidambaranathan SubramanianNo ratings yet
- Lab ModuleDocument92 pagesLab ModuleRajan SinnathambyNo ratings yet
- RolfSteilGienger2011 ICDL OnlineGoalBabblingDocument9 pagesRolfSteilGienger2011 ICDL OnlineGoalBabblingArsh UppalNo ratings yet
- Chalearn Lap 2016: First Round Challenge On First Impressions - Dataset and ResultsDocument18 pagesChalearn Lap 2016: First Round Challenge On First Impressions - Dataset and ResultslikufaneleNo ratings yet
- The Using of Computer For Elimination of Misconceptions About PhotosynthesisDocument5 pagesThe Using of Computer For Elimination of Misconceptions About PhotosynthesisNindyaNo ratings yet
- Cap 3Document72 pagesCap 3Jhonatan LeandroNo ratings yet
- Final Mongu Conference Presentation 2023 - 123743Document35 pagesFinal Mongu Conference Presentation 2023 - 123743Tahpehs PhiriNo ratings yet
- 3.3 Difference Between Quasi Experimental Design and True Experimental DesignDocument2 pages3.3 Difference Between Quasi Experimental Design and True Experimental DesignbangorNo ratings yet
- L1Document12 pagesL1jessica magdyNo ratings yet
- R R ? A L M J: Easons To Eject Ligning Anguage Odels With UdgmentsDocument20 pagesR R ? A L M J: Easons To Eject Ligning Anguage Odels With Udgmentsbosheng dingNo ratings yet
- Episodic Memory in Lifelong Language LearningDocument88 pagesEpisodic Memory in Lifelong Language LearningAnderson Wu100% (1)
- Design and Analysis of Experiments: Dr. Tai-Yue WangDocument33 pagesDesign and Analysis of Experiments: Dr. Tai-Yue WangqwertqwertqwertNo ratings yet
- Transfer Learning Reduces Prosthetics Training Time 95Document3 pagesTransfer Learning Reduces Prosthetics Training Time 95nessus joshua aragonés salazarNo ratings yet
- Supervised Learning Using An Active StrategyDocument9 pagesSupervised Learning Using An Active StrategyUmang MahantNo ratings yet
- Ul 2Document39 pagesUl 2kai luNo ratings yet
- Du Pont AnalysisDocument1 pageDu Pont Analysiskaltim.iu.m.ma.h78No ratings yet
- BIGDAS2023 Paper 13Document8 pagesBIGDAS2023 Paper 13Duy-Phuong DaoNo ratings yet
- Lec 9Document22 pagesLec 9Nada ElDeebNo ratings yet
- CS 331: Artificial Intelligence SearchDocument14 pagesCS 331: Artificial Intelligence SearchwardaNo ratings yet
- General Summary: Completely Randomized (Independent Samples) Repeated Measures Mixed DesignDocument17 pagesGeneral Summary: Completely Randomized (Independent Samples) Repeated Measures Mixed DesignHarshal mevadaNo ratings yet
- ModuleDocument22 pagesModulesugiartoNo ratings yet
- Reinforcement Learning in Robotics: A Survey: Jens Kober J. Andrew Bagnell Jan PetersDocument38 pagesReinforcement Learning in Robotics: A Survey: Jens Kober J. Andrew Bagnell Jan PetersLaxmikanth CherukupalliNo ratings yet
- EAPP - Lesson 5Document18 pagesEAPP - Lesson 5Carmen OrtizNo ratings yet
- Note MF-S0.65 Hc-Sq3.29Document11 pagesNote MF-S0.65 Hc-Sq3.29Francisco GalindoNo ratings yet
- Research PaperDocument7 pagesResearch Paperpskvlogs0005No ratings yet
- DocDocument19 pagesDocAngra ArdanaNo ratings yet
- 1 Haycock2010Document10 pages1 Haycock2010Elena IovinelliNo ratings yet
- Effect of Duval Cognitive Model On Geometric Reasioning: Dr. Manju GeraDocument11 pagesEffect of Duval Cognitive Model On Geometric Reasioning: Dr. Manju GeralucaNo ratings yet
- Physics Invention Project PresentationDocument2 pagesPhysics Invention Project PresentationBach DoNo ratings yet
- Factorial Design Experiment PDFDocument2 pagesFactorial Design Experiment PDFChristopherNo ratings yet
- Predicate Invention and Reuse: Andrei Diaconu, Andrew Cropper, Rolf Morel University of Oxford (Emails) @ox - Ac.ukDocument2 pagesPredicate Invention and Reuse: Andrei Diaconu, Andrew Cropper, Rolf Morel University of Oxford (Emails) @ox - Ac.ukAndrei DiaconuNo ratings yet
- Organize Facility Layout Using CRAFTS MethodDocument10 pagesOrganize Facility Layout Using CRAFTS MethodKainat jamilNo ratings yet
- Experiment 9Document10 pagesExperiment 9Kainat jamilNo ratings yet
- Q1-W1-L1 DLP - Factoring Polynomials by Common Monomial FactoringDocument6 pagesQ1-W1-L1 DLP - Factoring Polynomials by Common Monomial FactoringArela Jane TumulakNo ratings yet
- Hybrid Discriminative-Generative Training Via COnstrrastive LeanringDocument14 pagesHybrid Discriminative-Generative Training Via COnstrrastive Leanringbobabeari989No ratings yet
- Deriving CDF of Kolmogorov-Smirnov Test Statistic: Jan VrbikDocument20 pagesDeriving CDF of Kolmogorov-Smirnov Test Statistic: Jan VrbikPelajar JaliNo ratings yet
- Ns ExamDocument9 pagesNs ExamJimmyNo ratings yet
- Agent-Based Simulation: Principles of Simulation and The Multi-Agent ApproachDocument42 pagesAgent-Based Simulation: Principles of Simulation and The Multi-Agent ApproachtuanngthanhNo ratings yet
- DistilBERT: A Distilled Version of BERTDocument5 pagesDistilBERT: A Distilled Version of BERTAakash VermaNo ratings yet
- Understanding Trainable Sparse Coding With Matrix FactorizationDocument45 pagesUnderstanding Trainable Sparse Coding With Matrix FactorizationOscar Julian Perdomo CharryNo ratings yet
- Course Information Sheet: Biomedical Engineering Department Sir Syed University of Engineering & TechnologyDocument9 pagesCourse Information Sheet: Biomedical Engineering Department Sir Syed University of Engineering & TechnologyOraNo ratings yet
- Factorial Design Experiments PDFDocument2 pagesFactorial Design Experiments PDFAshleyNo ratings yet
- Practical Design of Experiments: DoE Made EasyFrom EverandPractical Design of Experiments: DoE Made EasyRating: 4.5 out of 5 stars4.5/5 (7)
- Jack of All Trades ArchetypeDocument2 pagesJack of All Trades ArchetypeGwazi MagnumNo ratings yet
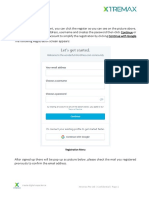
- Register for a WordPress account in 5 easy stepsDocument5 pagesRegister for a WordPress account in 5 easy stepsPutriNo ratings yet
- Project Equipment Load AnalysisDocument54 pagesProject Equipment Load Analysisrajeshmk2002100% (6)
- Organizational Change & Development - VIL2021 - 22Document3 pagesOrganizational Change & Development - VIL2021 - 22Rahul TRIPATHINo ratings yet
- 268US03 Oiltech Technical & Product Catalogue Letter WDocument48 pages268US03 Oiltech Technical & Product Catalogue Letter WMauricio CarestiaNo ratings yet
- Article 680 Swimming Pools, Spas, Hot Tubs, Fountains, and Similar InstallationsDocument13 pagesArticle 680 Swimming Pools, Spas, Hot Tubs, Fountains, and Similar InstallationsDocente 361 UMECITNo ratings yet
- Public Dealing With UrduDocument5 pagesPublic Dealing With UrduTariq Ghayyur86% (7)
- Magazine 55 EnglishPartDocument50 pagesMagazine 55 EnglishPartAli AwamiNo ratings yet
- Planets Classification Malefic and BeneficDocument3 pagesPlanets Classification Malefic and Beneficmadhu77No ratings yet
- CE QB - All Units PDFDocument38 pagesCE QB - All Units PDFkurian georgeNo ratings yet
- Standard 2Document10 pagesStandard 2Bridget GumboNo ratings yet
- 2022 MSK Poster JonDocument1 page2022 MSK Poster Jonjonathan wijayaNo ratings yet
- DX DiagesDocument36 pagesDX DiagesBpbd Kota BengkuluNo ratings yet
- Balino, Shedina D. Beed 2-CDocument5 pagesBalino, Shedina D. Beed 2-CSHEDINA BALINONo ratings yet
- Mahusay Module 4 Acc3110Document2 pagesMahusay Module 4 Acc3110Jeth MahusayNo ratings yet
- NPPD Sri LankaDocument15 pagesNPPD Sri LankaasdasdNo ratings yet
- ADC MethodDocument16 pagesADC MethodPhilip K MathewNo ratings yet
- Universal Chargers and GaugesDocument2 pagesUniversal Chargers and GaugesFaizal JamalNo ratings yet
- Ch05 - Deformation - HamrockDocument14 pagesCh05 - Deformation - HamrockMuhammad Mansor BurhanNo ratings yet
- i-PROTECTOR SPPR Catalogue 1.0Document2 pagesi-PROTECTOR SPPR Catalogue 1.0Sureddi KumarNo ratings yet
- Chapter 3Document12 pagesChapter 3Raymond LeoNo ratings yet
- ECOSYS FS-2100D Ecosys Fs-2100Dn Ecosys Fs-4100Dn Ecosys Fs-4200Dn Ecosys Fs-4300Dn Ecosys Ls-2100Dn Ecosys Ls-4200Dn Ecosys Ls-4300DnDocument33 pagesECOSYS FS-2100D Ecosys Fs-2100Dn Ecosys Fs-4100Dn Ecosys Fs-4200Dn Ecosys Fs-4300Dn Ecosys Ls-2100Dn Ecosys Ls-4200Dn Ecosys Ls-4300DnJosé Bonifácio Marques de AmorimNo ratings yet
- NFA To DFA Conversion: Rabin and Scott (1959)Document14 pagesNFA To DFA Conversion: Rabin and Scott (1959)Rahul SinghNo ratings yet
- Atuador Ip67Document6 pagesAtuador Ip67Wellington SoaresNo ratings yet
- ACP160DDocument14 pagesACP160Dinbox934No ratings yet
- Thandeka, Learning To Be White: Money, Race, and God in America (New York: Continuum International Publishing Group, 1999), 169 PPDocument2 pagesThandeka, Learning To Be White: Money, Race, and God in America (New York: Continuum International Publishing Group, 1999), 169 PPFefa LinsNo ratings yet
- Example4 FatigueTools WS01-SNDocument23 pagesExample4 FatigueTools WS01-SNJosé Luciano Cerqueira CesarNo ratings yet
- PBS CCMD CVMD Administrator GuideDocument40 pagesPBS CCMD CVMD Administrator GuidesharadcsinghNo ratings yet
- Calicut University: B. A PhilosophyDocument6 pagesCalicut University: B. A PhilosophyEjaz KazmiNo ratings yet
- Follow The Directions - GR 1 - 3 PDFDocument80 pagesFollow The Directions - GR 1 - 3 PDFUmmiIndia100% (2)