You might also like
- ch09 Functional AreaDocument40 pagesch09 Functional AreaArya GunaNo ratings yet
- Big Data AnalyticsDocument5 pagesBig Data AnalyticsDatatools GYE-ECNo ratings yet
- Business Analytics PointersDocument3 pagesBusiness Analytics Pointersconsume cionNo ratings yet
- Quasi Researh DesignDocument6 pagesQuasi Researh Designlily1528No ratings yet
- IP BookDocument96 pagesIP Booknew mediaNo ratings yet
- TW Ycm01265958803Document62 pagesTW Ycm0126595880313239563No ratings yet
- Feasibility StudyDocument5 pagesFeasibility StudyInza NsaNo ratings yet
- Project Portfolio 2022Document18 pagesProject Portfolio 2022dino_birds6113No ratings yet
- Procurement Strategy DevelopmentDocument1 pageProcurement Strategy DevelopmentMarian DinuNo ratings yet
- Practical guidelines for conducting research in line with DCED StandardDocument40 pagesPractical guidelines for conducting research in line with DCED StandardChé rieNo ratings yet
- Stakeholder RegisterDocument7 pagesStakeholder Registerrouzbehk6515No ratings yet
- MGMT311 Knowledge Management Course OutlineDocument12 pagesMGMT311 Knowledge Management Course Outlinehorxeee100% (1)
- GA 33 KV VCB HT Panel - Siddharth Nagar Project. UPDocument17 pagesGA 33 KV VCB HT Panel - Siddharth Nagar Project. UPaayushNo ratings yet
- QNDocument6 pagesQNdoctor andey1No ratings yet
- Building Organizational CapabilityDocument270 pagesBuilding Organizational CapabilityMohamad RamdanNo ratings yet
- Unit 1logistics ManagementDocument13 pagesUnit 1logistics ManagementSidhu boiiNo ratings yet
- Process CapabilityDocument75 pagesProcess CapabilityNzeza CarineNo ratings yet
- Meetings Planner 2023 - 2024 18 04 23Document1 pageMeetings Planner 2023 - 2024 18 04 23Word Gets AroundNo ratings yet
- Business Research MethodsDocument62 pagesBusiness Research MethodsSourav KaranthNo ratings yet
- 01 Introduction To Quantitative AnalysisDocument16 pages01 Introduction To Quantitative AnalysisKevin Dal100% (3)
- Information Systems For Functional AreasDocument5 pagesInformation Systems For Functional AreasShrikant Nichat100% (1)
- Process Analysis WSDDocument28 pagesProcess Analysis WSDAkhilesh ChaudharyNo ratings yet
- Detailed Scheduling Planning Board Technical HelpDocument6 pagesDetailed Scheduling Planning Board Technical Helpmanojnarain100% (1)
- Logistics NotesDocument18 pagesLogistics NotesRadha Raman SharmaNo ratings yet
- ForecastingDocument21 pagesForecastingSyed Umair100% (1)
- Modelling the house building process to improve value chain managementDocument9 pagesModelling the house building process to improve value chain managementrobert_keeNo ratings yet
- Research Methods and TypesDocument9 pagesResearch Methods and TypesAswith R ShenoyNo ratings yet
- Rip Bushing PDFDocument38 pagesRip Bushing PDFTravis Wood100% (1)
- Application of Data Analytics in Business PDFDocument1 pageApplication of Data Analytics in Business PDFmarvinNo ratings yet
- Pps-Probability Proptional SamplingDocument13 pagesPps-Probability Proptional SamplingdranshulitrivediNo ratings yet
- The Malcolm Baldrige National Quality Award Criteria FrameworkDocument32 pagesThe Malcolm Baldrige National Quality Award Criteria FrameworkAgentSkySkyNo ratings yet
- Statistical MethodDocument3 pagesStatistical MethodAlia buttNo ratings yet
- Definition of StatisticsDocument3 pagesDefinition of StatisticsHaseeb WaheedNo ratings yet
- Corporate Governance Syllabus Aug 2012Document9 pagesCorporate Governance Syllabus Aug 2012Dushyant PatadiyaNo ratings yet
- CRM Challenges in OrganisationDocument12 pagesCRM Challenges in OrganisationBhudev Kumar SahuNo ratings yet
- Internal ScanningDocument4 pagesInternal Scanningfikha zahirahNo ratings yet
- Sources of DataDocument6 pagesSources of DataJamion KnightNo ratings yet
- Strategic Management Accounting PDFDocument5 pagesStrategic Management Accounting PDFMuhammad SadiqNo ratings yet
- MIS Management Information SystemsDocument49 pagesMIS Management Information SystemsDakshata GadiyaNo ratings yet
- Statistics - Introduction Arranging DataDocument45 pagesStatistics - Introduction Arranging Datadreamza2z100% (2)
- Introduction To Logistics Management Module 4Document19 pagesIntroduction To Logistics Management Module 4Kyle SikorskyNo ratings yet
- ManagementAccounting (TermPaper)Document11 pagesManagementAccounting (TermPaper)Eshfaque Alam Dastagir100% (1)
- Research DesignDocument8 pagesResearch DesignMohd Shahid ShamsNo ratings yet
- Methods of Data CollectionDocument9 pagesMethods of Data CollectionHarshita MalikNo ratings yet
- Types of Probability SamplingDocument5 pagesTypes of Probability SamplingSylvia NabwireNo ratings yet
- Study On Consumer Behaviour Towards Big Baazar ChennaiDocument7 pagesStudy On Consumer Behaviour Towards Big Baazar Chennaikiran rajNo ratings yet
- INTRODUCTION TO LOGISTICS MANAGEMENT MODULE For UG Students 1Document21 pagesINTRODUCTION TO LOGISTICS MANAGEMENT MODULE For UG Students 1Kyle Sikorsky100% (1)
- Multivariate Statistical Methods with RDocument11 pagesMultivariate Statistical Methods with Rqwety300No ratings yet
- Application of Statistics in Business DecisionsDocument4 pagesApplication of Statistics in Business DecisionsNusrat Riya100% (1)
- Corporate Governance Models and PrinciplesDocument18 pagesCorporate Governance Models and PrinciplesGunjan JainNo ratings yet
- Rhonda Zubas - Assignment 2 HPT Intervention For Abc WirelessDocument10 pagesRhonda Zubas - Assignment 2 HPT Intervention For Abc Wirelessapi-278841534No ratings yet
- Compensation & Benefits AssignmentDocument11 pagesCompensation & Benefits AssignmentWEDAY LIMITEDNo ratings yet
- Module 1 Introduction To Logistics PDFDocument49 pagesModule 1 Introduction To Logistics PDFChispa BoomNo ratings yet
- ISO 9001 Awareness ProgramDocument67 pagesISO 9001 Awareness ProgramSudhaNo ratings yet
- Module 5 INTERPRETATION & REPORT WRITINGDocument15 pagesModule 5 INTERPRETATION & REPORT WRITINGskumar100% (1)
- Chapter Three Purchasing and Materials ManagementDocument15 pagesChapter Three Purchasing and Materials ManagementHorlick~IceNo ratings yet
- Case 2.3 HanauerDocument10 pagesCase 2.3 HanauerAlexa RodriguezNo ratings yet
- Assignment - Research Paper AnalysisDocument3 pagesAssignment - Research Paper AnalysismacarijoeNo ratings yet
- Situation AnalysisDocument38 pagesSituation AnalysisSantosh GhimireNo ratings yet
- Research ApproachDocument1 pageResearch ApproachomairNo ratings yet
- Talent Management Information SystemDocument7 pagesTalent Management Information SystemAnkita BhardwajNo ratings yet
- 1-Introduction-to-StatisticsDocument6 pages1-Introduction-to-StatisticsMD TausifNo ratings yet
- Unit-II Research Design and MeasurementDocument127 pagesUnit-II Research Design and MeasurementSaravanan Shanmugam50% (2)
- Introduction To Logistics Management Module 5Document33 pagesIntroduction To Logistics Management Module 5Kyle SikorskyNo ratings yet
- IUBAT - International University of Business Agriculture and TechnologyDocument4 pagesIUBAT - International University of Business Agriculture and Technologycreative dudeNo ratings yet
- Value Chain Management Capability A Complete Guide - 2020 EditionFrom EverandValue Chain Management Capability A Complete Guide - 2020 EditionNo ratings yet
- 8th Grade GT Science SyllabusDocument2 pages8th Grade GT Science Syllabusapi-420198655No ratings yet
- Advisory Note 11 ASFP Cell Beam RationaleDocument2 pagesAdvisory Note 11 ASFP Cell Beam RationalePavaloaie Marian ConstantinNo ratings yet
- Future Time ClausesDocument7 pagesFuture Time ClausesAmanda RidhaNo ratings yet
- Negative Impacts of Social Media on Society and BehaviorDocument3 pagesNegative Impacts of Social Media on Society and BehaviorConstanza Pavez PugaNo ratings yet
- Introduction Unit Short Test 1B Grammar, Vocabulary, and VerbsDocument1 pageIntroduction Unit Short Test 1B Grammar, Vocabulary, and VerbsDimitar IvanovNo ratings yet
- Nb7040 - Rules For Pipe Connections and Spools: Acc. Building Specification. Rev. 2, November 2016Document4 pagesNb7040 - Rules For Pipe Connections and Spools: Acc. Building Specification. Rev. 2, November 201624142414No ratings yet
- Cable Percussion Rig ChecksDocument2 pagesCable Percussion Rig Checksargon39No ratings yet
- Mobil Dynagear Series Performance ProfileDocument2 pagesMobil Dynagear Series Performance ProfileXavier DiazNo ratings yet
- Writing Theory DraftDocument18 pagesWriting Theory Draftapi-488391657No ratings yet
- Quenching & TemperingDocument4 pagesQuenching & Temperingkgkganesh8116No ratings yet
- Career Development Plan: Career Navigation at UBC WebsiteDocument10 pagesCareer Development Plan: Career Navigation at UBC WebsiteKty Margaritta MartinezNo ratings yet
- Personal Data Form: World English Placement Test Package Photocopiable © 2011 Heinle, Cengage LearningDocument2 pagesPersonal Data Form: World English Placement Test Package Photocopiable © 2011 Heinle, Cengage Learningadri shimizuNo ratings yet
- Residual Stresses of Plate With Holes by ANSYS Analysis - Hani Aziz AmeenDocument14 pagesResidual Stresses of Plate With Holes by ANSYS Analysis - Hani Aziz AmeenHani Aziz AmeenNo ratings yet
- Openroads Designer User ManualDocument112 pagesOpenroads Designer User ManualNilay BhavsarNo ratings yet
- Summary of C: How To Program Sixth Edition by Deitel: Introduction To Computers, The Internet and The WebDocument15 pagesSummary of C: How To Program Sixth Edition by Deitel: Introduction To Computers, The Internet and The WebFrieda NgaharjoNo ratings yet
- Update CV KhanDocument2 pagesUpdate CV KhanqayyukhanNo ratings yet
- British Airways Case Study SolutionDocument2 pagesBritish Airways Case Study SolutionHassan ZafarNo ratings yet
- Ttb-709016-172718-172718de-65f (MTS46) PDFDocument1 pageTtb-709016-172718-172718de-65f (MTS46) PDFAnonymous OM5uU6No ratings yet
- t-030f Spanish p35-48Document4 pagest-030f Spanish p35-48Juan ContrerasNo ratings yet
- INCaDocument47 pagesINCaMehdi SoltaniNo ratings yet
- Alenar R.J (Stem 11 - Heliotrope)Document3 pagesAlenar R.J (Stem 11 - Heliotrope)REN ALEÑARNo ratings yet
- Iso 9712 2012 PDFDocument19 pagesIso 9712 2012 PDFBala KrishnanNo ratings yet
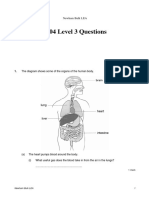
- 2004 Level 3 Questions: Newham Bulk LEADocument18 pages2004 Level 3 Questions: Newham Bulk LEAPatience NgundeNo ratings yet