You might also like
- Radial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksFrom EverandRadial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksNo ratings yet
- Pattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkDocument5 pagesPattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkEkin RafiaiNo ratings yet
- Approximate Linear Programming For Network Control: Column Generation and SubproblemsDocument20 pagesApproximate Linear Programming For Network Control: Column Generation and SubproblemsPervez AhmadNo ratings yet
- ProjectReport KanwarpalDocument17 pagesProjectReport KanwarpalKanwarpal SinghNo ratings yet
- NEURAL NETWORKS: Basics using MATLAB Neural Network ToolboxDocument54 pagesNEURAL NETWORKS: Basics using MATLAB Neural Network ToolboxBob AssanNo ratings yet
- Electricity Load Forecasting - IntelligentDocument10 pagesElectricity Load Forecasting - IntelligentkarthikbolluNo ratings yet
- Digital Neural Networks: Tony R. MartinezDocument8 pagesDigital Neural Networks: Tony R. MartinezzaqweasNo ratings yet
- Neural Networks Embed DDocument6 pagesNeural Networks Embed DL S Narasimharao PothanaNo ratings yet
- Nero Solution Litreture From HelpDocument6 pagesNero Solution Litreture From Helpvijay_dhawaleNo ratings yet
- Deep Learning NotesDocument44 pagesDeep Learning NotesAJAY SINGH NEGI100% (1)
- Multi-Layer PerceptronsDocument8 pagesMulti-Layer PerceptronswarrengauciNo ratings yet
- Motor Imagery ClassificationDocument18 pagesMotor Imagery ClassificationAtharva dubeyNo ratings yet
- Character Recognition Using Neural Networks: Rókus Arnold, Póth MiklósDocument4 pagesCharacter Recognition Using Neural Networks: Rókus Arnold, Póth MiklósSharath JagannathanNo ratings yet
- Learning To Learn by Gradient Descent by Gradient DescentDocument10 pagesLearning To Learn by Gradient Descent by Gradient DescentAnkit BiswasNo ratings yet
- Performance Evaluation of Artificial Neural Networks For Spatial Data AnalysisDocument15 pagesPerformance Evaluation of Artificial Neural Networks For Spatial Data AnalysistalktokammeshNo ratings yet
- A Study of Neural Network Algorithms: Namrata AnejaDocument3 pagesA Study of Neural Network Algorithms: Namrata Anejawww.irjes.comNo ratings yet
- Deep Learning Assignment 1 Solution: Name: Vivek Rana Roll No.: 1709113908Document5 pagesDeep Learning Assignment 1 Solution: Name: Vivek Rana Roll No.: 1709113908vikNo ratings yet
- Room Classification Using Machine LearningDocument16 pagesRoom Classification Using Machine LearningVARSHANo ratings yet
- Week - 5 (Deep Learning) Q. 1) Explain The Architecture of Feed Forward Neural Network or Multilayer Perceptron. (12 Marks)Document7 pagesWeek - 5 (Deep Learning) Q. 1) Explain The Architecture of Feed Forward Neural Network or Multilayer Perceptron. (12 Marks)Mrunal BhilareNo ratings yet
- TME - Classification of SUSY Data SetDocument9 pagesTME - Classification of SUSY Data SetAdam Teixidó BonfillNo ratings yet
- Sari WESIC2003 PaperDocument8 pagesSari WESIC2003 PaperSalehNo ratings yet
- Assignment - 4Document24 pagesAssignment - 4Durga prasad TNo ratings yet
- Pattern Recognition System Using MLP Neural Networks: Sarvda Chauhan, Shalini DhingraDocument4 pagesPattern Recognition System Using MLP Neural Networks: Sarvda Chauhan, Shalini DhingraIJERDNo ratings yet
- Module 3.2 Time Series Forecasting LSTM ModelDocument23 pagesModule 3.2 Time Series Forecasting LSTM ModelDuane Eugenio AniNo ratings yet
- Ai-Ml in 5G Challenge ReportDocument11 pagesAi-Ml in 5G Challenge ReportUsha ChandrakalaNo ratings yet
- Batch Normalization SeparateDocument20 pagesBatch Normalization SeparateNeeraj GargNo ratings yet
- Data Mining Project 11Document18 pagesData Mining Project 11Abraham ZelekeNo ratings yet
- Neural Network Toolbox: A Tutorial For The Course Computational IntelligenceDocument8 pagesNeural Network Toolbox: A Tutorial For The Course Computational Intelligencenehabatra14No ratings yet
- A Probabilistic Theory of Deep Learning: Unit 2Document17 pagesA Probabilistic Theory of Deep Learning: Unit 2HarshitNo ratings yet
- DL Mannual For ReferenceDocument58 pagesDL Mannual For ReferenceDevant PajgadeNo ratings yet
- Feed Forward Neural Network ApproximationDocument11 pagesFeed Forward Neural Network ApproximationAshfaque KhowajaNo ratings yet
- Application of Back-Propagation Neural Network in Data ForecastDocument23 pagesApplication of Back-Propagation Neural Network in Data ForecastEngineeringNo ratings yet
- The Research of Camera Distortion Correction Basing On Neural NetworkDocument6 pagesThe Research of Camera Distortion Correction Basing On Neural NetworkSeetha ChinnaNo ratings yet
- DM Assignment.1Document3 pagesDM Assignment.1Muhammad Asfar SiddiqueNo ratings yet
- ANN Model for Water Quality PredictionDocument8 pagesANN Model for Water Quality PredictionEllango ArasarNo ratings yet
- Deep LearningDocument5 pagesDeep LearningTom AmitNo ratings yet
- P-Norm NetworkDocument5 pagesP-Norm NetworkXiaohui ZhangNo ratings yet
- UNIT V Parallel Programming Patterns in CUDA (T2 Chapter 7) - P P With CUDADocument35 pagesUNIT V Parallel Programming Patterns in CUDA (T2 Chapter 7) - P P With CUDAGANESH CINDINo ratings yet
- Electromagnetic Transients Simulation As An Objective Function Evaluator For Optimization of Power System PerformanceDocument6 pagesElectromagnetic Transients Simulation As An Objective Function Evaluator For Optimization of Power System PerformanceAhmed HussainNo ratings yet
- Rule-Base Structure Identification in An Adaptive-Network-Based Fuzzy Inference System PDFDocument10 pagesRule-Base Structure Identification in An Adaptive-Network-Based Fuzzy Inference System PDFOualid LamraouiNo ratings yet
- Evaluate Neural Network For Vehicle Routing ProblemDocument3 pagesEvaluate Neural Network For Vehicle Routing ProblemIDESNo ratings yet
- Principles of Training Multi-Layer Neural Network Using BackpropagationDocument15 pagesPrinciples of Training Multi-Layer Neural Network Using Backpropagationkamalamdharman100% (1)
- Principles of Convolutional Neural NetworksDocument9 pagesPrinciples of Convolutional Neural NetworksAsma AliNo ratings yet
- Prediction of Process Parameters For Optimal Material Removal Rate Using Artificial Neural Network (ANN) TechniqueDocument7 pagesPrediction of Process Parameters For Optimal Material Removal Rate Using Artificial Neural Network (ANN) TechniqueKrishna MurthyNo ratings yet
- Evolving Structure and Function of Neurocontrollers: Stochastic Synthesis) Outlined in Section 2 Is Inspired by A BiDocument6 pagesEvolving Structure and Function of Neurocontrollers: Stochastic Synthesis) Outlined in Section 2 Is Inspired by A BiQaiser AbbasNo ratings yet
- Avoid Local Minima in Neural Nets with Simultaneous LearningDocument10 pagesAvoid Local Minima in Neural Nets with Simultaneous LearningShakeel AhmedNo ratings yet
- SPAM EMAIL DETECTION USING NEURAL NETWORKSDocument7 pagesSPAM EMAIL DETECTION USING NEURAL NETWORKSDiana BeltranNo ratings yet
- Multi Layer Feed-Forward Network LearningDocument5 pagesMulti Layer Feed-Forward Network LearningBidkar Harshal SNo ratings yet
- Solving Ode by Ann PDFDocument14 pagesSolving Ode by Ann PDFDeep SinghaNo ratings yet
- Machine Learning With CaeDocument6 pagesMachine Learning With CaeHarsha KorlapatiNo ratings yet
- ANN & FingerprintDocument26 pagesANN & FingerprintFodelman FidelNo ratings yet
- Chapter 10: Algorithms 10.1. Deterministic and Non-Deterministic AlgorithmDocument5 pagesChapter 10: Algorithms 10.1. Deterministic and Non-Deterministic AlgorithmrowsunmahatoNo ratings yet
- Fast Median Search: An ANSI C Implementation: Nicolas Devillard - Ndevilla AT Free DOT FR July 1998Document14 pagesFast Median Search: An ANSI C Implementation: Nicolas Devillard - Ndevilla AT Free DOT FR July 1998ali alasdyNo ratings yet
- Evolutionary Neural Networks for Product DesignDocument11 pagesEvolutionary Neural Networks for Product DesignjlolazaNo ratings yet
- Design of Efficient MAC Unit for Neural Networks Using Verilog HDLDocument6 pagesDesign of Efficient MAC Unit for Neural Networks Using Verilog HDLJayant SinghNo ratings yet
- E & V - A Chess Opening Repertoire For For Blitz and RapidDocument4 pagesE & V - A Chess Opening Repertoire For For Blitz and Rapidleonilsonsv0% (1)
- Unit Iv DMDocument58 pagesUnit Iv DMSuganthi D PSGRKCWNo ratings yet
- ANN Simulink ExamplesDocument14 pagesANN Simulink ExamplesSantosh NandaNo ratings yet
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- Lecture 38Document33 pagesLecture 38Ahmed KhazalNo ratings yet
- Lab1 VHDL PDFDocument10 pagesLab1 VHDL PDFGustavo Dos Santos LimaNo ratings yet
- Part4 ConfrontingRaceConditionsDocument48 pagesPart4 ConfrontingRaceConditionsAhmed KhazalNo ratings yet
- Shared-Memory Model and Threads: Intel Software CollegeDocument35 pagesShared-Memory Model and Threads: Intel Software CollegeAhmed KhazalNo ratings yet
- Comp Sec IntroDocument16 pagesComp Sec IntroAhmed KhazalNo ratings yet
- Lab1 VHDL PDFDocument10 pagesLab1 VHDL PDFGustavo Dos Santos LimaNo ratings yet
- Part1 RecognizingPotentialParallelismDocument74 pagesPart1 RecognizingPotentialParallelismAhmed KhazalNo ratings yet
- Introduction To Parallel Programming - Student Workbook With Instructor's Notes PDFDocument33 pagesIntroduction To Parallel Programming - Student Workbook With Instructor's Notes PDFAhmed KhazalNo ratings yet
- Reads 51Document71 pagesReads 51Ahmed KhazalNo ratings yet
- English in Common 5-91-102Document7 pagesEnglish in Common 5-91-102Ahmed KhazalNo ratings yet
- New Microsoft Office PowerPoint PresentationDocument1 pageNew Microsoft Office PowerPoint PresentationAhmed KhazalNo ratings yet
- Artificial Neural NetworkDocument20 pagesArtificial Neural NetworkAhmed KhazalNo ratings yet
- Ds Mcu9Document2 pagesDs Mcu9Ahmed KhazalNo ratings yet
- PhysioEx Exercise 5 Activity 1Document3 pagesPhysioEx Exercise 5 Activity 1villanuevaparedesaracely4No ratings yet
- A Tutorial On Combinatorics An Enumeration in Music TheoryDocument22 pagesA Tutorial On Combinatorics An Enumeration in Music TheoryGrandeBoiNo ratings yet
- MAFE208IU-L7 InterpolationDocument35 pagesMAFE208IU-L7 InterpolationThy VũNo ratings yet
- Odd Numbers and SeriesDocument9 pagesOdd Numbers and SeriesOmer Ali100% (1)
- Green FunctionDocument15 pagesGreen Functionjitendra25252No ratings yet
- Checkpoint 2016 - P2Document15 pagesCheckpoint 2016 - P2seetNo ratings yet
- The Traditional Theory of CostsDocument13 pagesThe Traditional Theory of Costsamrendra kumarNo ratings yet
- HBMT 2103 MeiDocument20 pagesHBMT 2103 MeiNick AnsohNo ratings yet
- Voice Based Application As Medicine Spotter For Visually ImpairedDocument5 pagesVoice Based Application As Medicine Spotter For Visually ImpairedCh.pranushaNo ratings yet
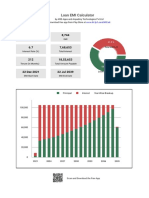
- Loan EMI Calculator: Download Free App From Play Store atDocument9 pagesLoan EMI Calculator: Download Free App From Play Store atkantilal rathodNo ratings yet
- Brownian MotionDocument76 pagesBrownian MotionPraveen KumarNo ratings yet
- CAP1 - Samuel Preston Demography Measuring and Modeling PopulationDocument22 pagesCAP1 - Samuel Preston Demography Measuring and Modeling Populationagathafortunato0% (1)
- GATE Questions On Laplace TransformDocument6 pagesGATE Questions On Laplace Transformgautam100% (1)
- Trig integrals & trig subsDocument6 pagesTrig integrals & trig subsjunaidadilNo ratings yet
- 3 1 Fractions Practice BookDocument23 pages3 1 Fractions Practice Bookapi-260320108No ratings yet
- Breakthrough analysis of SO2 adsorption over zeolitesDocument14 pagesBreakthrough analysis of SO2 adsorption over zeoliteskayeNo ratings yet
- Welcome To CMSC 250 Discrete StructuresDocument13 pagesWelcome To CMSC 250 Discrete StructuresKyle HerockNo ratings yet
- Algebra 1Document38 pagesAlgebra 1Elias RezaNo ratings yet
- Multilinear Algebra - MITDocument141 pagesMultilinear Algebra - MITasdNo ratings yet
- Textbook of Heat Transfer - S. P. Sukhatme PDFDocument122 pagesTextbook of Heat Transfer - S. P. Sukhatme PDFVineet Mathew50% (6)
- Britannica Content EngineeringDocument6 pagesBritannica Content EngineeringMaksudur Rahman SumonNo ratings yet
- Solution Manual For Advanced Engineering Mathematics 7th Edition Peter OneilDocument35 pagesSolution Manual For Advanced Engineering Mathematics 7th Edition Peter Oneilbraidscanty8unib100% (49)
- Sariel Har-Peled - AlgorithmsDocument288 pagesSariel Har-Peled - AlgorithmssomeguyinozNo ratings yet
- ACP WGF25 IP11 Problems With Calculation of Propagation LossDocument18 pagesACP WGF25 IP11 Problems With Calculation of Propagation LossSoXy AngelNo ratings yet
- Rational Numbers on the Number LineDocument4 pagesRational Numbers on the Number LineESTEPHANIE TUMAGANNo ratings yet
- MS Excel Test-Level 2 ModerateDocument3 pagesMS Excel Test-Level 2 Moderatebugarin4870% (1)
- Stacks and QueuesDocument21 pagesStacks and QueuesDhivya NNo ratings yet
- Assignment2 ANNDocument7 pagesAssignment2 ANNaattishNo ratings yet
- LC Filter For Three Phase Inverter ReportDocument19 pagesLC Filter For Three Phase Inverter ReportMuthuRajNo ratings yet