You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Uniform Bonding Code (Part 2)Document18 pagesUniform Bonding Code (Part 2)Paschal James BloiseNo ratings yet
- DAP FullTextIntroductionByStuartLichtman PDFDocument21 pagesDAP FullTextIntroductionByStuartLichtman PDFAlejandro CordobaNo ratings yet
- Formal 17 12 04 PDFDocument184 pagesFormal 17 12 04 PDFJose LaraNo ratings yet
- Amended ComplaintDocument38 pagesAmended ComplaintDeadspinNo ratings yet
- Business Advantage Pers Study Book Intermediate PDFDocument98 pagesBusiness Advantage Pers Study Book Intermediate PDFCool Nigga100% (1)
- SHIPPING TERMSDocument1 pageSHIPPING TERMSGung Mayura100% (1)
- Sec of Finance Purisima Vs Philippine Tobacco Institute IncDocument2 pagesSec of Finance Purisima Vs Philippine Tobacco Institute IncCharlotte100% (1)
- Lab 2 ReportDocument9 pagesLab 2 Reportsherub wangdiNo ratings yet
- Exp19 Excel Ch08 HOEAssessment Robert's Flooring InstructionsDocument1 pageExp19 Excel Ch08 HOEAssessment Robert's Flooring InstructionsMuhammad ArslanNo ratings yet
- Request Letter To EDC Used PE PipesDocument1 pageRequest Letter To EDC Used PE PipesBLGU Lake DanaoNo ratings yet
- The Non Technical Part: Sample Interview Questions For Network EngineersDocument5 pagesThe Non Technical Part: Sample Interview Questions For Network EngineersblablaNo ratings yet
- Role Played by Digitalization During Pandemic: A Journey of Digital India Via Digital PaymentDocument11 pagesRole Played by Digitalization During Pandemic: A Journey of Digital India Via Digital PaymentIAEME PublicationNo ratings yet
- CMTD42M FDocument3 pagesCMTD42M FagengfirstyanNo ratings yet
- BILL OF SALE Pre ApproveDocument1 pageBILL OF SALE Pre ApprovedidinurieliaNo ratings yet
- Wordbank Restaurants 15Document2 pagesWordbank Restaurants 15Obed AvelarNo ratings yet
- 01 NumberSystemsDocument49 pages01 NumberSystemsSasankNo ratings yet
- Incident Report Form: RPSG-IMS-F-24 Accident and Investigation Form 5ADocument2 pagesIncident Report Form: RPSG-IMS-F-24 Accident and Investigation Form 5ARocky BisNo ratings yet
- How To Make Pcbat Home PDFDocument15 pagesHow To Make Pcbat Home PDFamareshwarNo ratings yet
- Entrepreneurship and EconomicDocument2 pagesEntrepreneurship and EconomicSukruti BajajNo ratings yet
- Bajaj 100bDocument3 pagesBajaj 100brmlstoreNo ratings yet
- Pass Issuance Receipt: Now You Can Also Buy This Pass On Paytm AppDocument1 pagePass Issuance Receipt: Now You Can Also Buy This Pass On Paytm AppAnoop SharmaNo ratings yet
- Career Guidance Activity Sheet For Grade IiDocument5 pagesCareer Guidance Activity Sheet For Grade IiJayson Escoto100% (1)
- The Study of Accounting Information SystemsDocument44 pagesThe Study of Accounting Information SystemsCelso Jr. AleyaNo ratings yet
- Whats The Average 100 M Time For An Olympics - Google SearchDocument1 pageWhats The Average 100 M Time For An Olympics - Google SearchMalaya KnightonNo ratings yet
- 34 Annual Report 2019 20Document238 pages34 Annual Report 2019 20Rahul N PatelNo ratings yet
- GE Supplier Add Refresh FormDocument1 pageGE Supplier Add Refresh FormromauligouNo ratings yet
- Top Machine Learning ToolsDocument9 pagesTop Machine Learning ToolsMaria LavanyaNo ratings yet
- Wheat as an alternative to reduce corn feed costsDocument4 pagesWheat as an alternative to reduce corn feed costsYuariza Winanda IstyanNo ratings yet
- Perbandingan Sistem Pemerintahan Dalam Hal Pemilihan Kepala Negara Di Indonesia Dan SingapuraDocument9 pagesPerbandingan Sistem Pemerintahan Dalam Hal Pemilihan Kepala Negara Di Indonesia Dan SingapuraRendy SuryaNo ratings yet
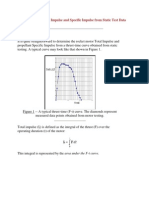
- Determining Total Impulse and Specific Impulse From Static Test DataDocument4 pagesDetermining Total Impulse and Specific Impulse From Static Test Datajai_selvaNo ratings yet