You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Distributed DBMS Reliability - 3 of 3 (Good)Document35 pagesDistributed DBMS Reliability - 3 of 3 (Good)Lakhveer Kaur0% (1)
- PLSQLDocument11 pagesPLSQLAnita AcharyaNo ratings yet
- 3 Tier Architecture (Nice)Document9 pages3 Tier Architecture (Nice)Lakhveer KaurNo ratings yet
- Transaction and SQLDocument35 pagesTransaction and SQLLakhveer KaurNo ratings yet
- PLSQL Lecture 1 (Nice)Document5 pagesPLSQL Lecture 1 (Nice)Lakhveer KaurNo ratings yet
- PL SQLDocument41 pagesPL SQLmeetravi007No ratings yet
- The Buffer Manager of A DBMSDocument7 pagesThe Buffer Manager of A DBMSLakhveer Kaur100% (8)
- Lec - PL - SQL (Nice)Document14 pagesLec - PL - SQL (Nice)Lakhveer KaurNo ratings yet
- A To Z PPT NotesDocument62 pagesA To Z PPT NotesKarthikeyan RamajayamNo ratings yet
- Distributed DBMS (Good)Document58 pagesDistributed DBMS (Good)Lakhveer KaurNo ratings yet
- Indexing and Hashing: B.RamamurthyDocument24 pagesIndexing and Hashing: B.RamamurthyLakhveer KaurNo ratings yet
- 10 1 1 107Document35 pages10 1 1 107Lakhveer KaurNo ratings yet
- 2nd UnitDocument3 pages2nd UnitLakhveer KaurNo ratings yet
- Explain About Distributed SystemsDocument24 pagesExplain About Distributed SystemsLakhveer KaurNo ratings yet
- 1.3 Distributed OsDocument1 page1.3 Distributed OsLakhveer KaurNo ratings yet
- CH 01Document11 pagesCH 01Lakhveer KaurNo ratings yet
- 1.7 Process ConceptsDocument2 pages1.7 Process ConceptsLakhveer KaurNo ratings yet
- 1.9 Scheduling CriteriaDocument7 pages1.9 Scheduling CriteriaLakhveer KaurNo ratings yet
- Lossless DecompositionDocument25 pagesLossless DecompositionLakhveer KaurNo ratings yet
- Lossless DecompositionDocument25 pagesLossless DecompositionLakhveer KaurNo ratings yet
- Basic File Handling in CDocument33 pagesBasic File Handling in CUbaid_Ullah_Fa_1194No ratings yet
- Fundamentals of DBMSS, Elmsari and NavatheDocument33 pagesFundamentals of DBMSS, Elmsari and NavatheLakhveer Kaur100% (1)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Difference Between Distinct and Group byDocument1 pageDifference Between Distinct and Group byPavelStrelkovNo ratings yet
- 12-24VDC Powered Ignition System: N N N N N N NDocument2 pages12-24VDC Powered Ignition System: N N N N N N NLeinner RamirezNo ratings yet
- Cics Tutorial PDFDocument23 pagesCics Tutorial PDFNeelay KumarNo ratings yet
- 110Q Pump Catalog SheetDocument2 pages110Q Pump Catalog SheetJohnNo ratings yet
- Account Statement From 27 Dec 2017 To 27 Jun 2018Document4 pagesAccount Statement From 27 Dec 2017 To 27 Jun 2018mrcopy xeroxNo ratings yet
- Gas Turbine Performance CalculationDocument7 pagesGas Turbine Performance CalculationAtiqur RahmanNo ratings yet
- As 29 Provisions Contingent Liabilities and Contingent AssetsDocument38 pagesAs 29 Provisions Contingent Liabilities and Contingent AssetsAayushi AroraNo ratings yet
- GCE Composite 1306 v4 PDFDocument28 pagesGCE Composite 1306 v4 PDFParapar ShammonNo ratings yet
- Map of The 110 and 220 KV Power Transmission Line and Substation Ulaanbaatar City " Ikh Toirog " ProjectDocument10 pagesMap of The 110 and 220 KV Power Transmission Line and Substation Ulaanbaatar City " Ikh Toirog " ProjectAltanochir AagiiNo ratings yet
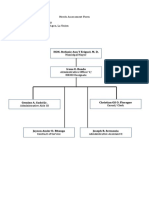
- Needs Assessment Form Company Name: HRMO Address: Sta. Barbara Agoo, La UnionDocument2 pagesNeeds Assessment Form Company Name: HRMO Address: Sta. Barbara Agoo, La UnionAlvin LaroyaNo ratings yet
- Ang AlibangbangDocument29 pagesAng AlibangbangadhrianneNo ratings yet
- " My Heart Will Go On ": Vocal: Celine DionDocument8 pages" My Heart Will Go On ": Vocal: Celine DionLail Nugraha PratamaNo ratings yet
- BUSINESS PROPOSAL-dönüştürüldü-2Document15 pagesBUSINESS PROPOSAL-dönüştürüldü-2Fatah Imdul UmasugiNo ratings yet
- Performance Online - Classic Car Parts CatalogDocument168 pagesPerformance Online - Classic Car Parts CatalogPerformance OnlineNo ratings yet
- Science, Technology and SocietyDocument2 pagesScience, Technology and SocietyHamieWave TVNo ratings yet
- Donor's Tax Post QuizDocument12 pagesDonor's Tax Post QuizMichael Aquino0% (1)
- BS en Iso 11114-4-2005 (2007)Document30 pagesBS en Iso 11114-4-2005 (2007)DanielVegaNeira100% (1)
- Surface Treatments & Coatings Ref: S. KalpakjianDocument22 pagesSurface Treatments & Coatings Ref: S. KalpakjianjojoNo ratings yet
- Galley Steward Knowledge: Free Screening / Interview GuidelineDocument2 pagesGalley Steward Knowledge: Free Screening / Interview GuidelineAgung Mirah Meyliana100% (2)
- DBMS Imp QNDocument24 pagesDBMS Imp QNShivam kumarNo ratings yet
- BookingDocument2 pagesBookingAbhishek Kumar ChaturvediNo ratings yet
- Probate Court Jurisdiction Regarding OwnershipDocument2 pagesProbate Court Jurisdiction Regarding OwnershipBnl NinaNo ratings yet
- Universal Declaration of Human RightsDocument36 pagesUniversal Declaration of Human RightsJanine Regalado100% (4)
- Types of Annuity & Intra Year Compounding: Dr. Anubha GuptaDocument15 pagesTypes of Annuity & Intra Year Compounding: Dr. Anubha GuptarashmipoojaNo ratings yet
- Assessment Form (Indoor)Document14 pagesAssessment Form (Indoor)Mark Tally0% (1)
- Share Purchase Agreement Short FormDocument7 pagesShare Purchase Agreement Short FormGerald HansNo ratings yet
- Roque v. IACDocument3 pagesRoque v. IACBryce KingNo ratings yet
- Queen Elizabeth Olympic Park, Stratford City and Adjacent AreasDocument48 pagesQueen Elizabeth Olympic Park, Stratford City and Adjacent AreasRavi WoodsNo ratings yet
- Labor Relations LawsDocument20 pagesLabor Relations LawsREENA ALEKSSANDRA ACOPNo ratings yet
- DACReq 016Document19 pagesDACReq 016jillianixNo ratings yet