You might also like
- ANOVADocument82 pagesANOVAlianNo ratings yet
- Compensation and Rewards Management - Session 9-10Document12 pagesCompensation and Rewards Management - Session 9-10Daksh AnejaNo ratings yet
- Chapter 11 Asynchronous AnovaDocument3 pagesChapter 11 Asynchronous AnovaLoren's Acads AccountNo ratings yet
- Quiz Tues and ThursDocument2 pagesQuiz Tues and ThursJohn Rey Enriquez50% (2)
- Problem 5 Limocon, MelendezDocument24 pagesProblem 5 Limocon, MelendezMaria Angela MelendezNo ratings yet
- Qso510 Final Project Case AddendumDocument3 pagesQso510 Final Project Case AddendumVamsiNo ratings yet
- FM Assignment 2Document9 pagesFM Assignment 2Sanskar SharmaNo ratings yet
- ASSIGNMENT 2.1 OM-2.1 TABLE-Moving Average and Simple Expo.Document2 pagesASSIGNMENT 2.1 OM-2.1 TABLE-Moving Average and Simple Expo.rodge macaraegNo ratings yet
- Frequency Ranges: H5: 518.000-542.000 MHZDocument5 pagesFrequency Ranges: H5: 518.000-542.000 MHZJNo ratings yet
- BBRM-300-ME-02 (TAIWAN) - 279kNDocument1 pageBBRM-300-ME-02 (TAIWAN) - 279kNmohd solihin bin mohd hasanNo ratings yet
- BBRM 300 Me 02Document3 pagesBBRM 300 Me 02mohd solihin bin mohd hasanNo ratings yet
- Assignment 1Document3 pagesAssignment 1kawishNo ratings yet
- Assignment 2 Edwin CastilloDocument10 pagesAssignment 2 Edwin CastilloEdwin CastilloNo ratings yet
- Surat Penawaran Harga Service GensetDocument7 pagesSurat Penawaran Harga Service GensetCV. INTI DAYA ELEKTRIKAL100% (1)
- Breakeven-Analysis 2Document1 pageBreakeven-Analysis 2walterNo ratings yet
- DataDocument11 pagesDataLAKSHMI JNo ratings yet
- SPR Crop Prod 12 2018Document3 pagesSPR Crop Prod 12 2018Brittany EtheridgeNo ratings yet
- Exponential Smoothing Example:: Single Years Quarter Period Sales Avg A (T) /avgDocument6 pagesExponential Smoothing Example:: Single Years Quarter Period Sales Avg A (T) /avgchikomborero maranduNo ratings yet
- Forecast and SOPDocument2 pagesForecast and SOPHassan KhanNo ratings yet
- How To Score Practice Test 1Document2 pagesHow To Score Practice Test 1Avtarika KaurNo ratings yet
- Econometrics Class5Document6 pagesEconometrics Class5abdullahNo ratings yet
- BBRM 300 Me 03Document3 pagesBBRM 300 Me 03mohd solihin bin mohd hasanNo ratings yet
- Chapter-12 ANOVA For-HomeworkDocument16 pagesChapter-12 ANOVA For-HomeworkAndrea Marie CalmaNo ratings yet
- IIT Kharagpur GATE 2015 Final CutoffDocument1 pageIIT Kharagpur GATE 2015 Final CutoffRupesh KumarNo ratings yet
- Efficient Markets Hypothesis (Emh) Test of Api Power Company LimitedDocument8 pagesEfficient Markets Hypothesis (Emh) Test of Api Power Company LimitedSaugat SharmaNo ratings yet
- BBRM-300-ME-03 (TAIWAN) - 279kNDocument1 pageBBRM-300-ME-03 (TAIWAN) - 279kNmohd solihin bin mohd hasanNo ratings yet
- Tugas Kelompok StatprobDocument19 pagesTugas Kelompok StatprobAzkha AvicenaNo ratings yet
- Inventory Forecasting and Planning Template V2Document9 pagesInventory Forecasting and Planning Template V2jani.annapanNo ratings yet
- Random Sampling Uji 1Document5 pagesRandom Sampling Uji 1jhonihan_212546800No ratings yet
- Financial Projection Perniagaan Bahulu Syanaz Enterprise - OkDocument1 pageFinancial Projection Perniagaan Bahulu Syanaz Enterprise - OkPassion TSR Trading ILTUNo ratings yet
- Q 10-14 Samad SiddiquiDocument13 pagesQ 10-14 Samad SiddiquiSamad SiddiquiNo ratings yet
- Jaspal - PSCs End TermDocument12 pagesJaspal - PSCs End TermJaspal NarulaNo ratings yet
- Harga Rewinding Electro Motor 2019Document6 pagesHarga Rewinding Electro Motor 2019CV. INTI DAYA ELEKTRIKAL100% (11)
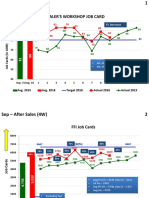
- Dealer'S Workshop Job Card: 7% DecreaseDocument38 pagesDealer'S Workshop Job Card: 7% DecreaseshehrozeNo ratings yet
- 2018 Statistical Highlights PDFDocument7 pages2018 Statistical Highlights PDFBernewsAdminNo ratings yet
- ASSIGNMENT jASPAL 200097Document177 pagesASSIGNMENT jASPAL 200097Jaspal NarulaNo ratings yet
- Actual Demand Forecasted Demand A Forecasted Demand BDocument3 pagesActual Demand Forecasted Demand A Forecasted Demand BRemote IslandNo ratings yet
- Emt770 775Document16 pagesEmt770 775Jaswanth KumarNo ratings yet
- Triumph 6660 Parts ListDocument18 pagesTriumph 6660 Parts ListD_moneyNo ratings yet
- Vaibhav Price 17-03-2024Document1 pageVaibhav Price 17-03-2024Aayat ChoudharyNo ratings yet
- Lampiran 6 Probit Analysis Data InformationDocument4 pagesLampiran 6 Probit Analysis Data InformationBimby NasyaNo ratings yet
- Vehicle Prices 17 TH Aug 2021Document52 pagesVehicle Prices 17 TH Aug 2021AD ADNo ratings yet
- 2008 Sales Complete AnalysisDocument3 pages2008 Sales Complete AnalysisJoni HaryonoNo ratings yet
- Adam - Monthly Cash Flow 2014Document9 pagesAdam - Monthly Cash Flow 2014Ismi RochaniNo ratings yet
- Reliability: Case Processing SummaryDocument21 pagesReliability: Case Processing SummaryRevo Virgoansyah KNo ratings yet
- Forecasting 2 Exponential SmoothingDocument5 pagesForecasting 2 Exponential SmoothingAlberto GaliaNo ratings yet
- 3.4.standard Normal Distribution ExerciseDocument2 pages3.4.standard Normal Distribution ExerciseAmit SemwalNo ratings yet
- Standard Normal Distribution: Background Task 1 Task 2 Task 3Document2 pagesStandard Normal Distribution: Background Task 1 Task 2 Task 3balamurugan SrinivasanNo ratings yet
- 3.4.standard Normal Distribution ExerciseDocument2 pages3.4.standard Normal Distribution ExerciseRahulNo ratings yet
- Scale: Validasi: Case Processing SummaryDocument4 pagesScale: Validasi: Case Processing SummaryAidiniNo ratings yet
- BCA MotorDocument121 pagesBCA Motorari abdul bassyrNo ratings yet
- PP ShahAlam DataDocument8 pagesPP ShahAlam DataHassaan ImranNo ratings yet
- Aggregate Planning NumericalsDocument19 pagesAggregate Planning Numericalsdhruv001100% (1)
- Steel Strucure Database - 19 July 2018Document1 pageSteel Strucure Database - 19 July 2018DeeuNo ratings yet
- PPF CalculatorDocument2 pagesPPF CalculatorshashanamouliNo ratings yet
- SUMMARY Group 5 BSED 3BDocument8 pagesSUMMARY Group 5 BSED 3Bmikeful mirallesNo ratings yet
- Skill DevelopmentDocument9 pagesSkill DevelopmentSAKET MORENo ratings yet
- Cost 900,000 Salvage Value 50,000 Amount To Be Deprecated 850,000 Useful Life (Years) 15 Per Year Deprection 56,667Document3 pagesCost 900,000 Salvage Value 50,000 Amount To Be Deprecated 850,000 Useful Life (Years) 15 Per Year Deprection 56,667AhmedNiazNo ratings yet
- Santu BabaDocument2 pagesSantu Babaamveryhot0950% (2)
- Standard Test Methods For Rheological Properties of Non-Newtonian Materials by Rotational (Brookfield Type) ViscometerDocument8 pagesStandard Test Methods For Rheological Properties of Non-Newtonian Materials by Rotational (Brookfield Type) ViscometerRodrigo LopezNo ratings yet
- Convection Transfer EquationsDocument9 pagesConvection Transfer EquationsA.N.M. Mominul Islam MukutNo ratings yet
- Data Sheet Eldar Void SpinnerDocument1 pageData Sheet Eldar Void SpinnerAlex PolleyNo ratings yet
- Frellwits Swedish Hosts FileDocument10 pagesFrellwits Swedish Hosts FileAnonymous DsGzm0hQf5No ratings yet
- Эквивалентная Схема Мотра Теслы с Thomas2020Document7 pagesЭквивалентная Схема Мотра Теслы с Thomas2020Алексей ЯмаNo ratings yet
- Airport & Harbour Engg-AssignmentDocument3 pagesAirport & Harbour Engg-AssignmentAshok Kumar RajanavarNo ratings yet
- BLP#1 - Assessment of Community Initiative (3 Files Merged)Document10 pagesBLP#1 - Assessment of Community Initiative (3 Files Merged)John Gladhimer CanlasNo ratings yet
- Ecs h61h2-m12 Motherboard ManualDocument70 pagesEcs h61h2-m12 Motherboard ManualsarokihNo ratings yet
- Introduction - Livspace - RenoDocument12 pagesIntroduction - Livspace - RenoMêghnâ BîswâsNo ratings yet
- 1916 South American Championship Squads - WikipediaDocument6 pages1916 South American Championship Squads - WikipediaCristian VillamayorNo ratings yet
- MME 52106 - Optimization in Matlab - NN ToolboxDocument14 pagesMME 52106 - Optimization in Matlab - NN ToolboxAdarshNo ratings yet
- 24 DPC-422 Maintenance ManualDocument26 pages24 DPC-422 Maintenance ManualalternativblueNo ratings yet
- BackgroundsDocument13 pagesBackgroundsRaMinah100% (8)
- Formula:: High Low Method (High - Low) Break-Even PointDocument24 pagesFormula:: High Low Method (High - Low) Break-Even PointRedgie Mark UrsalNo ratings yet
- List of Iconic CPG Projects in SingaporeDocument2 pagesList of Iconic CPG Projects in SingaporeKS LeeNo ratings yet
- 2-1. Drifting & Tunneling Drilling Tools PDFDocument9 pages2-1. Drifting & Tunneling Drilling Tools PDFSubhash KediaNo ratings yet
- Chapter 4 - Basic ProbabilityDocument37 pagesChapter 4 - Basic Probabilitynadya shafirahNo ratings yet
- Lab Report SBK Sem 3 (Priscilla Tuyang)Document6 pagesLab Report SBK Sem 3 (Priscilla Tuyang)Priscilla Tuyang100% (1)
- Statistics and Probability: Quarter 4 - (Week 6)Document8 pagesStatistics and Probability: Quarter 4 - (Week 6)Jessa May MarcosNo ratings yet
- 3 Diversion&CareDocument2 pages3 Diversion&CareRyan EncomiendaNo ratings yet
- Guidelines For Prescription Drug Marketing in India-OPPIDocument23 pagesGuidelines For Prescription Drug Marketing in India-OPPINeelesh Bhandari100% (2)
- COURTESY Reception Good MannersDocument1 pageCOURTESY Reception Good MannersGulzina ZhumashevaNo ratings yet
- Lesson Plan For Implementing NETSDocument5 pagesLesson Plan For Implementing NETSLisa PizzutoNo ratings yet
- CLG418 (Dcec) PM 201409022-EnDocument1,143 pagesCLG418 (Dcec) PM 201409022-EnMauricio WijayaNo ratings yet
- Poetry UnitDocument212 pagesPoetry Unittrovatore48100% (2)
- Genomic Tools For Crop ImprovementDocument41 pagesGenomic Tools For Crop ImprovementNeeru RedhuNo ratings yet
- How To Launch Remix OS For PCDocument2 pagesHow To Launch Remix OS For PCfloapaaNo ratings yet
- Walking in Space - Lyrics and Chord PatternDocument2 pagesWalking in Space - Lyrics and Chord Patternjohn smithNo ratings yet
- Odisha State Museum-1Document26 pagesOdisha State Museum-1ajitkpatnaikNo ratings yet