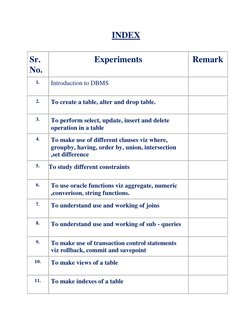
INDEX Sr. No.
1.
Experiments
Introduction to DBMS To create a table, alter and drop table. To perform select, update, insert and delete operation in a table To make use of different clauses viz where, groupby, having, order by, union, intersection ,set difference To study different constraints To use oracle functions viz aggregate, numeric ,converison, string functions. To understand use and working of joins To understand use and working of sub - queries To make use of transaction control statements viz rollback, commit and savepoint To make views of a table To make indexes of a table
Remark
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
��EXPERIMENT NO: 1 AIM: INTRODUCTION TO DBMS THEORY: DBMS
A DBMS (Database Management System) is a software program used to manage a database. These programs enable users to access and modify database A DBMS is a complex set of software programs that controls the organization, storage, management, and retrieval of data in a database. A DBMS includes four main components, which are: Modeling Language, Data Structures, DB Query Language and Report Writer, and Transaction Mechanism.
Each of these components can be further broken down into smaller and more specific pieces, but it is the sum of these parts which are combined to create the management system around the particular database to be utilized.
A database management system, or DBMS, gives the user access to their data and helps them transform the data into information.
Such database management systems include dBase, Paradox, IMS, and Oracle. These systems allow users to create, update, and extract information from their databases. Compared to a manual filing system, the biggest advantages to a computerized database system are speed, accuracy, and accessibility. A database is a structured collection of data. Data refers to the characteristics of people, things, and events.
THE MAIN FOUR COMPONENTS OF DBMS:
MODELING LANGUAGE
A modeling language to define the schema of each database hosted in the DBMS, according to the DBMS data model. The four most common types of organizations are the hierarchical, network, relational and object models.
DATA STRUCTURES
Data structures (fields, records, files and objects) optimized to deal with very large amounts of data stored on a permanent data storage device (which implies relatively slow access compared to volatile main memory).
DB QUERY LANGUAGE AND REPORT WRITER
�A database query language and report writer to allow users to interactively interrogate the database, analyze its data and update it according to the users privileges on data.
TRANSACTION MECHANISM
A transaction mechanism, that ideally would guarantee the ACID properties, in order to ensure data integrity, despite concurrent user accesses (concurrency control), and faults (fault tolerance).
ORACLE
Oracle is one of the powerful RDBMS product that provide efficient solutions for database applications. Oracle is the product of Oracle Corporation which was founded by LAWRENCE ELLISION in 1977. The first commercial product of oracle was delivered in 1970. The first version of oracle 2.0 was written in assembly language. Nowadays commonly used versions of oracle are ORACLE 8, 8i & 9i Oracle 8 and onwards provide tremendous increase in performance, features and functionality.
FEATURES OF ORACLE :
Client/Server Architecture Large database and Space Management Concurrent Processing High transaction processing performance High Availability Many concurrent database users Controlled availability Openness industry standards Manageable security Database enforced integrity Distributed systems Portability Compatibility
ORACLE SERVER TOOL :
Oracle is a company that produces most widely used server based multi-user RDBMS. Oracle server is a program installed on server hard-disk drive. This program must be loaded in RAM to that it can process the user requests. Oracle server takes care of following functions. Oracle server tools are also called as back end. Functions of server tool:
Updates the data
Retrieves the data sharing Manages the data sharing Accepts the query statements PL/SQL and SQL Enforce the transaction consistency
DDL DATA DEFINATION LANGUAGE
The SQL sentences that are used to create these objects are called DDLs or Data Definition Language. The sql provides various commands for defining relation schemas, deleting relations, creating indexes and modify relation schemas. DDL is part of sql which helps a user in defining the data structures into the database. Following are the various DDL commands are
Alter table & Create table & drop table Create index & drop index Create view & drop view
DML DATA MANIPULATION LANGUAGE
The SQL sentences used to manipulate data within these objects are called DMLs or Data Manipulation Language. It is language that enables users to access or manipulate data as organized by appropriate data model. By data manipulation we have
Retrieval of information stored in database. Insertion of new information into database. Deletion of information from database. Modification of data stored in database.
TWO TYPES OF DML ARE:
Procedural DML Non-procedural DML (Declarative )
FOLLOWING ARE DML COMMANDS ARE:
o o o o
Select Update Delete Insert
�DCL DATA CONTROL LANGUAGE
The SQL sentences, which are used to control the behavior of these objects, are called DCLs or Data Control Language. It is language used to control data and access to the database. Following are some DCL commands are
Commit Rollback Save point Set transaction
A Data Control Language (DCL) is a computer language and a subset of SQL, used to control access to data in a database. Examples of DCL commands include:
GRANT to allow specified users to perform specified tasks. REVOKE to cancel previously granted or denied permissions.
The following privileges can be GRANTED TO or REVOKED FROM a user or role:
CONNECT SELECT INSERT UPDATE DELETE EXECUTE USAGE
DATA TYPES OF SQL
CHAR :
This data type is used to store character strings values of fixed length. The size in brackets determines the number of characters the cell can hold. The maximum number of characters (i.e. the size) this data type can hold is 255 characters. Syntax is CHAR(SIZE) Example is CHAR (20)
VARCHAR :
This data type is used to store variable length alphanumeric data. The maximum this data type can hold is 2000 characters. One difference between this data type and the CHAR data type is ORACLE compares VARCHAR values using non-padded comparison semantics i.e. the inserted values will not be padded with spaces. Syntax is VARCHAR(SIZE)
�Example is VARCHAR (20) OR VARCHAR2 (20)
NUMBER :
The NUMBER data type is used to store numbers (fixed or floating point). Numbers of virtually any magnitude maybe stored up to 38 digits of precision. Numbers as large as 9.99 * 10 to the power of 124, i.e. followed by 125 zeros can be stored. The precision, (P), determines the maximum length of the data, whereas the scale, (S), determines the number of places to the right of the decimal. If scale is omitted then the default is zero. If precision is omitted values are stored with their original precision up to the maximum of 38 digits. Syntax is NUMBER (P, S) Example is NUMBER (10, 2)
LONG :
This data type is used to store variable length character strings containing up to 2GB. LONG data can be used to store arrays of binary data in ASCII format. LONG values cannot be indexed, and the normal character functions such as SUBSTR cannot be applied to LONG values. Syntax is LONG (SIZE) Example is LONG (20)
DATE :
This data type is used to represent data and time. The standard format id DD-MM-YY as in 13JUL-85. To enter dates other than the standard format, use the appropriate functions. Date Time stores date in the 24-hour format. By default, the time in a date field is 12:00:00 am, if no time portion is specified. The default date for a date field is the first day of the current month. Syntax is DATE
LONG RAW :
LONG RAW data types are used to store binary data, such as Digitized picture or image. Data loaded into columns of these data types are stored without any further conversion. LONG RAW data type can contain up to 2GB. Values stored in columns having LONG RAW data type cannot be indexed. Syntax is LONGRAW (SIZE)
RAW : It is used to hold strings of byte oriented data. Data type can have a maximum length of 255 bytes. Syntax is RAW(SIZE)
�EXPERIMENT NO: 2 AIM: TO CREATE A TABLE, ALTER AND DROP TABLE THEORY:
CREATE TABLE:
A table is basic unit of storage. It is composed of rows and columns. To create a table we will name the table and the columns of the table. We follow the rules to name tables and columns:-
o o
It must begin with a letter and can be up to 30 characters long. It must not be duplicate and not any reserved word.
SYNTAX to create a table is CREATE TABLE tablename (column_name1 datatype (size), column_name2 datatype (size) ); Example is CREATE TABLE student (rollno number (4), name varchar2 (15));
ALTER TABLE :
After creating a table one may have need to change the table either by add new columns or by modify existing columns. One can do so by using alter table command. SYNTAX to add a column is ALTER TABLE tablename ADD(col1 datatype,col2 datatype); SYNTAX to modify a column is ALTER TABLE tablename MODIFY(col1 datatype,col2 datatype);
�DROP TABLE :
To remove the definition of oracle table, the drop table statement is used.
SYNTAX to drop table is DROP TABLE tablename
�EXPERIMENT NO: 3 AIM: TO PERFORM SELECT, UPDATE, INSERT AND DELETE OPERATION IN A TABLE THEORY: SELECT STATEMENT: SELECTING ALL COLUMNS OF THE TABLE:
A SELECT statement is used as a DATA RETRIVAL statement i.e. It retrieves information from the database. SYNTAX: SQL> SELECT * FROM TABLE NAME;
SELECT identifies WHAT COLUMNS. FROM identifies WHICH TABLE.
Simply, SELECT clause specify which column is to be displayed & FROM clause specify the table containing the columns listed in the SELECT clause. Here, * is used to select all columns.
SELECTING SPECIFIC COLUMNS OF THE TABLE:
SYNTAX: SQL> SELECT ENAME,JOB FROM EMP; We can use SELECT statement to display specific columns of the table by specifying the column names separated by commas. As shown above In SELECT clause We specify the column names, in the order in which we want them to appear as output.
INSERT STATEMENT:
SYNTAX: SQL> INSERT into CSE(student,rollno) VALUES ('MONIKA',651);
�For screenshot PLEASE TURN OVER (PTO) INSERT statement is used to ADD NEW ROW TO A TABLE. Using INSERT We can only insert on row at a time. As shown in above example, In above example CSE is the name of the TABLE & STUDENT, ROLLNO are its two ATTRIBUTES. Enclose CHARACTER & DATE values within a SINGLE QUOTATION MARKS.
CREATING A SCRIPT
i.e USE of & substitution in a SQL statement to Prompt For values. & is a PLACEHOLDER for the VARIABLE VALUE.
DELETE STATEMENT:
SYNTAX: SQL> DELETE from CSE where rollno BETWEEN 605 AND 630; i.e. DELETE FROM table [WHERE condition];
If we OMIT WHERE CLAUSE then ALL ROWS OF THE COLUMN ARE DELETED. We can confirm the delete operation by displaying the deleted rows using SELECT statement as shown above
UPDATE STATEMENT:
SYNTAX: SQL> UPDATE cse SET rollno=21 WHERE student='ITIKA'; Here, If we do not use WHERE clause then ALL ROWS OF THE TABLE ARE UPDATED. SPCIFIED ROW or ROWS are modified if we specify the WHERE clause.
�EXPERIMENT NO: 4 AIM: TO MAKE USE OF DIFFERENT CLAUSES VIZ WHERE, GROUPBY, HAVING, ORDER BY, UNION, INTERSECTION ,SET DIFFERENCE THEORY:
The WHERE Clause
The WHERE clause is used to extract only those records that fulfill a specified criterion.
SYNTAX SELECT column_name(s) FROM table_name WHERE column_name operator value
Operators Allowed in the WHERE Clause
With the WHERE clause, the following operators can be used: Operator = <> > < >= <= Equal Not equal Greater than Less than Greater than or equal Less than or equal Description
BETWEEN Between an inclusive range LIKE Search for a pattern IN If you know the exact value you want to return for at least one of the columns
WHERE Clause Example
�The "Persons" table: P_Id 1 2 3 LastName Hansen Svendson Pettersen FirstName Ola Tove Kari Address Timoteivn 10 Borgvn 23 Storgt 20 City Sandnes Sandnes Stavanger
Now we want to select only the persons living in the city "Sandnes" from the table above. We use the following SELECT statement: SELECT * FROM Persons WHERE City='Sandnes' The result-set will look like this: P_Id 1 2 LastName Hansen Svendson FirstName Ola Tove Address Timoteivn 10 Borgvn 23 City Sandnes Sandnes
GROUP BY Statement
The GROUP BY statement is used in conjunction with the aggregate functions to group the result-set by one or more columns.
SYNTAX : SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name
SQL GROUP BY Example
We have the following "Orders" table: O_Id OrderDate OrderPrice Customer
�1 2 3 4 5 6
2008/11/12 2008/10/23 2008/09/02 2008/09/03 2008/08/30 2008/10/04
1000 1600 700 300 2000 100
Hansen Nilsen Hansen Hansen Jensen Nilsen
Now we want to find the total sum (total order) of each customer. We will have to use the GROUP BY statement to group the customers. We use the following SQL statement: SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer The result-set will look like this: Customer Hansen Nilsen Jensen SUM(OrderPrice) 2000 1700 2000
SET UNION
The union clause merges the outputs of multiple queries into a single set of rows and columns. It combines rows returned by two select statements by eliminating duplicate rows.
SYNTAX :
SQL>SELECT UNION SELECT ; EXAMPLE IS SQL>SELECT designation FROM emp_info WHERE deptt=comp
�UNION SELECT designation FROM emp_info WHERE deptt=eco;
INTERSECT
The intersect operator combines two select statements and return only those rows that are returned by both queries.
SYNTAX SQL>SELECT INTERSECT SELECT ; EXAMPLE IS SQL>SELECT designation FROM emp_info WHERE deptt=comp INTERSECT SELECT designation FROM emp_info WHERE deptt=eco;
MINUS
It combines the result of two queries and returns only those values that are selected by first query but not in second query.
SYNTAX SQL>SELECT MINUS SELECT ; EXAMPLE IS SQL>SELECT desgination FROM emp_info WHERE deptt=comp MINUS SELECT desgination FROM emp_info WHERE deptt=eco;
HAVING CLAUSE
�The having clause filters the group values created by group by clause. This clause can precede the group by clause but it is more logical if we place group by first.
SYNTAX SQL>SELECT col1,col2 FROM tablename GROUP BY HAVING ; EXAMPLE SQL>SELECT dept,max(salary) FROM emp_info GROUP BY dept HAVING max(salary) > 12000;
THE ORDER BY CLAUSE
This ORDER BY clause is used to SORT the rows. The order of rows returned in the query result is UNDEFINED. Generally ORDER BY clause is the LAST clause of the SQL statement. In this we can specify an expression, or an alias, or column position as a sort condition.
DEFAULT ORDER OF THE DATA:
The default order of the sorting is ASCENDING. i.e. NEUMERIC values are displayed with the Lowest values first. NULL values appear at the END. CHARACTERS are displayed in ALPHABETICAL ORDER. DATE values displayed with the earliest value first.
Sorting rows with ORDER BY clause use two keywords: ASC: Used for ascending order, by default DESC: Used for descending order.
EXAMPLE: SELECTING DEFAULT ORDER SYNTAX: SQL> SELECT ename, job, sal, hiredate from EMP ORDER BY sal;
SORTING IN DESENDING ORDER:
�SYNTAX: SQL> SELECT student, rollno FROM CSE ORDER BY student DESC;
SORTING BY COLUMN ALIAS:
SYNTAX: SQL> SELECT ename, hiredate, job, sal*12 AnnualSal FROM emp ORDER BY AnnualSal;
SORTING BY MULTIPLE COLUMNS:
SQL> SELECT ename,job,sal, hiredate FROM emp ORDER BY ename, sal DESC; We can sort by a column that s NOT in the SELECT item.
�EXPERIMENT NO: 5 AIM: TO STUDY DIFFERENT CONSTRAINTS THEORY: CONSTRAINTS
CONSTRAINTS enforces RULES at the table level Constraints prevent the deletion of the table if there is DEPENDENCIES from the other table. Basically, Constraints are used to PREVENT INVALID DATA ENTRIES INTO THE TABLES. HOW TO DEFINE A CONSTRAINT: SYNTAX: SQL> CREATE TABLE [table name] (column datatype [Default expr] [column_constraint], .. [table_constraint][,.]); NOT
NULL : THE NOT NULL CONSTRAINT
This constraint ensures that the column contains no null values. As column without the NOT NULL constraint can contain NULL values BY DEFAULT. Here, On table STUDENT NOT NULL constraint is added to the LAST_NAME i.e. now LAST_NAME cant be NULL If we try to add NULL value in this column then following message will be displayed as ERROR. Whereas we can add NULL value to the NAME column as there exist no NOT NULL constraint.
PRIMARY KEY:
A PRIMARY KEY constraint creates a primary key for a table. Only one primary key can be created for each table. A PRIMARY KEY constraint is a column or a set of columns that are uniquely identifies each row in the table.
�This constraint enforces UNIQUENESS of the column or column combination and ensures that no column that is part of the primary key can contain a NULL value. NULL VALUES are NOT ALLOWED & ALREADY existing values are not replaced. In this Department_id is a PRIMARY KEY. i.e. It do not contain DUPLICATE entries & NO NULL values. If we try to add DUPICATE values than following ERROR is encountered. If we try to add NULL value than following ERROR is encountered. PRIMARY KEY constraint can be defined at the COLUMN LEVEL or TABLE LEVEL. A composite PRIMARY KEY is created by using the TABLE-LEVEL definition. A table can have only one PRIMARY KEY constraint but can have several UNIQUE constraints. We can call them ALTERNATE KEYS.
FOREIGN KEY:
The FOREIGN KEY, or refrential integrity constraint, designates a column or combination of columns as a foreign key and establishes a relationship between a primary key or a unique key in the same table or a different table. A FOREIGN KEY value must match an existing value in the parent table or be NULL FOREIGN KEYS are based on data values and are purely logical, not physical, pointers. SYNTAX: SQL> CREATE TABLE table2 ( department_id NUMBER(4) CONSTRAINT emp_deptid_fk REFERENCES table1(department_id), ) The FOREIGN KEY is defined in the child table, and the table containing the referenced column is the Parent table. The FOREIGN KEY is defined using the combination of the following keywords: FOREIGN KEY: is used to define the column in the child table at the table constraint level. REFERENCES: identifies the table and column in the parent table. ON DELETE CASCADE: indicates that when the row in the parent table is deleted, the dependent rows in the chile table will also be deleted.
�ON DELETE SET NULL: converts foreign key values to the NULL when parent value is REMOVED. Here, 5 NOT ALLOWED value as 5 doesnt EXIT
CHECK Constraint
The CHECK constraint is used to limit the value range that can be placed in a column. If you define a CHECK constraint on a single column it allows only certain values for this column. If you define a CHECK constraint on a table it can limit the values in certain columns based on values in other columns in the row.
SQL CHECK Constraint on CREATE TABLE
The following SQL creates a CHECK constraint on the "P_Id" column when the "Persons" table is created. The CHECK constraint specifies that the column "P_Id" must only include integers greater than 0. CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), CHECK (P_Id>0) )
SQL CHECK Constraint on ALTER TABLE
To create a CHECK constraint on the "P_Id" column when the table is already created, use the following SQL: MySQL / SQL Server / Oracle / MS Access: ALTER TABLE Persons ADD CHECK (P_Id>0) To allow naming of a CHECK constraint, and for defining a CHECK constraint on multiple columns, use the following SQL syntax:
�ALTER TABLE Persons ADD CONSTRAINT chk_Person CHECK (P_Id>0 AND City='Sandnes')
To DROP a CHECK Constraint
To drop a CHECK constraint, use the following SQL: SQL Server / Oracle / MS Access: ALTER TABLE Persons DROP CONSTRAINT chk_Person
SQL UNIQUE Constraint
The UNIQUE constraint uniquely identifies each record in a database table. The UNIQUE and PRIMARY KEY constraints both provide a guarantee for uniqueness for a column or set of columns. A PRIMARY KEY constraint automatically has a UNIQUE constraint defined on it. Note that you can have many UNIQUE constraints per table, but only one PRIMARY KEY constraint per table.
SQL UNIQUE Constraint on CREATE TABLE
The following SQL creates a UNIQUE constraint on the "P_Id" column when the "Persons" table is created: CREATE TABLE Persons ( P_Id int NOT NULL UNIQUE, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) ) To allow naming of a UNIQUE constraint, and for defining a UNIQUE constraint on multiple columns, use the following SQL syntax: CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL,
�FirstName varchar(255), Address varchar(255), City varchar(255), CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName) )
SQL UNIQUE Constraint on ALTER TABLE
To create a UNIQUE constraint on the "P_Id" column when the table is already created, use the following SQL: ALTER TABLE Persons ADD UNIQUE (P_Id) To allow naming of a UNIQUE constraint, and for defining a UNIQUE constraint on multiple columns, use the following SQL syntax: ALTER TABLE Persons ADD CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName)
To DROP a UNIQUE Constraint
To drop a UNIQUE constraint, use the following SQL: ALTER TABLE Persons DROP CONSTRAINT uc_PersonID
�EXPERIMENT NO: 6 AIM: TO USE ORACLE FUNCTIONS VIZ AGGREGATE, NUMERIC ,CONVERISON, STRING FUNCTIONS. THEORY: Aggregate Functions COUNT : This function returns the number of rows or non-null values for column x.
SYNTAX COUNT([DISTINCT|ALL]COLUMN NAME) EXAMPLE SQL>SELECT COUNT(EMPNO)FROM EMP;
SUM : This function ireturns the sum of values for the column x. This function is applied on
columns having numeric datatype and it returns the numeric value.
SYNTAX SUM([DISTINCT|ALL]COLUMN NAME)
EXAMPLE
SQL>SELECT SUM(SAL) FROM EMP;
AVG : Ths function returns the average of values for the column x. It ignores the null values
in the column x.
SYNTAX AVG([DISTINCT|ALL]COLUMN NAME) EXAMPLE
�SQL>SELECT AVG(SAL),COUNT(SAL) FROM EMP;
MIN : This function returns the minimum of values for the column x for all the rows.
SYNTAX MIN([DISTINCT|ALL]COLUMN NAME) EXAMPLE SQL>SELECT MIN(SAL) FROM EMP;
MAX : This function returns the maximum of values for the column x for all the rows.
SYNTAX MAX([DISTINCT|ALL]COLUMN NAME) EXAMPLE SQL>SELECT MIN(SAL),MAX(SAL) FROM EMP;
NUMERIC FUNCTIONS:
Numeric functions are used to perform operations on numbers. They accept numeric values as input and return numeric values as output. Few of the Numeric functions are:
Function Name ABS (x) CEIL (x) FLOOR (x)
Return Value Absolute value of the number 'x' Integer value that is Greater than or equal to the number 'x' Integer value that is Less than or equal to the number 'x'
TRUNC (x, y) Truncates value of number 'x' up to 'y' decimal places ROUND (x, y) Rounded off value of the number 'x' up to the number 'y' decimal places
�The following examples explains the usage of the above numeric functions Function Name Examples Return Value ABS (1) 1 ABS (x) ABS (-1) -1 CEIL (2.83) 3 CEIL (x) CEIL (2.49) 3 CEIL (-1.6) -1 FLOOR (2.83) 2 FLOOR (x) FLOOR (2.49) 2 FLOOR (-1.6) -2 ROUND (125.456, 1) 125.4 TRUNC (x, y) ROUND (125.456, 0) 125 ROUND (124.456, -1) 120 TRUNC (140.234, 2) 140.23 TRUNC (-54, 1) 54 ROUND (x, y) TRUNC (5.7) 5 TRUNC (142, -1) 140 These functions can be used on database columns.
ROUND FUNCTION:
SYNTAX: SQL> SELECT ROUND(45.923, 2), ROUND(45.923,0), ROUND(45.923,-1) FROM DUAL;
TRUNC FUNCTION:
SYNTAX: SQL> SELECT TRUNC(45.923, 2), TRUNC(45.923,0), TRUNC(45.923,-1) FROM DUAL;
MOD FUNCTION:
SYNTAX: SQL> SELECT MOD(300,10), MOD(23,9) FROM DUAL; SQL> SELECT ename, MOD(sal,200) FROM emp;
�CONVERSION FUNCTIONS:
These are functions that help us to convert a value in one form to another form. For Ex: a null value into an actual value, or a value from one datatype to another datatype like NVL, TO_CHAR, TO_NUMBER, TO_DATE. Few of the conversion functions available in oracle are: Function Name TO_CHAR (x [,y]) TO_DATE (x [, date_format]) NVL (x, y) DECODE (a, b, c, d, e, default_value) Return Value Converts Numeric and Date values to a character string value. It cannot be used for calculations since it is a string value. Converts a valid Numeric and Character values to a Date value. Date is formatted to the format specified by 'date_format'. If 'x' is NULL, replace it with 'y'. 'x' and 'y' must be of the same datatype. Checks the value of 'a', if a = b, then returns 'c'. If a = d, then returns 'e'. Else, returns default_value.
The below table provides the examples for the above functions Function Name TO_CHAR () TO_DATE () NVL () Examples TO_CHAR (3000, '$9999') TO_CHAR (SYSDATE, 'Day, Month YYYY') TO_DATE ('01-Jun-08') NVL (null, 1) Return Value $3000 Monday, June 2008 01-Jun-08 1
STRING FUNCTIONS UPPER FUNCTION:
SYNTAX: SQL> SELECT UPPER(ename)|| is a || job AS EMPLOYEE DETAILS FROM emp;
LOWER FUNCTION
SYNTAX: SQL> SELECT LOWER(ename) NAME, UPPER(job) JOB FROM emp WHERE sal>2000;
�INITCAP FUNCTION:
SQL> SELECT INITCAP(ename) NAME, UPPER(job) JOB FROM emp WHERE sal>2000;
CONCAT FUNCTION
SYNTAX: SQL> SELECT CONCAT(ename,sal) NAME FROM emp;
LENGTH FUNCTION
SYNTAX: SQL> SELECT LENGTH(ename), sal FROM emp;
LPAD FUNCTION
SYNTAX: SQL> SELECT LPAD(sal,8,*) FROM EMP;
RPAD FUNCTION:
SYNTAX: SQL> SELECT RPAD(sal,8,$) FROM emp WHERE sal>3000;
SUBSTRING FUNCTION:
SYNTAX: SQL> SELECT sal,job FROM emp WHERE SUBSTR(ename,-1,1)=n;
INSTRING FUNCTION:
SYNTAX: SQL> SELECT ename,INSTR(ename,A), job FROM emp WHERE sal>2000;
�EXPERIMENT NO: 7 AIM: TO UNDERSTAND USE AND WORKING OF JOINS THEORY: JOINS
A JOIN can be recognized in sql select statement if its has more than one table after from keyword. This join condition is based on primary keys and foreign keys. There must be n-1 join conditions for n joins to tables. If join condition is omitted then the result is Cartesian product. SYNTAX SQL>SELECT list of columns FROM table1, table2 WHERE condition;
TYPES OF JOINS EQUI JOIN : It returns all rows from tables where there is a match. Tables are joined on
columns that have the same datatype & size in table. It is also known as equality join or simple join or inner join.
SYNTAX: SELECTfield1,field2 FROM table1,table2 WHERE table1.field=table2.field; EXAMPLE SQL>SELECT ename, dname FROM emp, dept WHERE emp.deptno=dept.deptno;
CARTESION JOIN : When the join condition is omitted the result is Cartesian join of
two or more tables in which all the combinations of rows will be displayed. All the rows are joined to all rows of the second table.
SYNTAX SQL>SELECT field1, field2 FROM table1, table2; EXAMPLE
�SQL>SELECT ename, dname FROM emp, dept;
OUTER JOIN : While using equi join we see that if there exists certain rows in one table
which dont have corresponding values in the second table thn those rows will not be selected. We can forcefully select those rows by outer join. The rows for those columns will have NULL values.
SYNTAX SELECT table1.col, table2.col FROM table1, table2 WHERE table1.col (+) = table2.col; EXAMPLE SQL>SELECT empno, ename, emp.deptno, dname FROM emp, dept WHERE emp.deptno (+) = dept.deptno;
SELF JOIN : The self join can be seen as join of two copies of the same table. The table is
not actually copied but sql performs the command as though it were.
EXAMPLE SQL>SELECT e.ename, m.ename FROM emp e, emp m WHERE e.mgr=e.empno;
�EXPERIMENT NO: 8 AIM: TO UNDERSTAND USE AND WORKING OF SUB QUERIES THEORY: SUBQUERIES
A sub query is a form of an SQL statement that appears inside another SQL statement. It is also termed as nested query. The statement containing a sub query is called a parent statement. The parent statement uses the rows returned by the sub query. It can be used by the following commands:
To insert records in a target table. To create tables and insert records in the table created. To update records in a target table. To create views. To provide values for conditions in WHERE, HAVING, IN etc. used with SELECT, UPDATE, and DELETE statements.
TYPES OF SUB QUERIES SINGLE ROW
It returns one row from inner nested query. EXAMPLE IS: SQL>SELECT deptno FROM emp WHERE ename =MILLER;
MULTIPLE ROW
Subqueries that return more than one row called multiple row queries. Operators like IN,ALL,ANY are used.
�EXAMPLE SQL>SELECT ename,sal,deptno FROM emp WHERE sal IN (SELECT min(sal) FROM emp GROUP BY deptno);
�EXPERIMENT NO: 9 AIM: TO MAKE USE OF TRANSACTION CONTROL STATEMENTS VIZ ROLLBACK, COMMIT AND SAVEPOINT THEORY:
SQL-Transaction Statements control transactions in database access. This subset of SQL is also called the Data Control Language for SQL (SQL DCL). A transaction is a sequence of one or more SQL statements that together form a logical unit of work. The SQL statements that form the transaction are typically closely related and perform interdependent actions. Each statement in the transaction performs some part of a task, but all of them are required to complete the task. Grouping the statements as a single transaction tells the DBMS that the entire statement sequence should be executed atomicallyall of the statements must be completed for the database to be in a consistent state. A transaction mechanism, that ideally would guarantee the ACID properties, in order to ensure data integrity, despite concurrent user accesses (concurrency control), and faults (fault tolerance). Transaction control statements are used to either save the modified data or to undo the changes if they were made in error. Until the data has been permanently saved to the table, no other users will be able to view any of the changes you have made. A transaction is a term used to describe a group of DML statements representing data actions that logically should be performed together.
COMMIT and ROLLBACK
SQL supports database transactions through two SQL transaction processing Statements COMMIT and ROLLBACK statement syntax diagrams
The COMMIT statement signals the successful end of a transaction. It tells the DBMS
�that the transaction is now complete; all of the statements that comprise the transaction have been executed, and the database is self-consistent.
The ROLLBACK statement signals the unsuccessful end of a transaction. It tells the DBMS that the user does not want to complete the transaction; instead, the DBMS should back out any changes made to the database during the transaction. In effect, the DBMS restores the database to its state before the transaction began.
The COMMIT and ROLLBACK statements are executable SQL statements, just like SELECT, INSERT, and UPDATE. A COMMIT statement ends the transaction successfully, making its database changes permanent. A new transaction begins immediately after the COMMIT statement.
A ROLLBACK statement aborts the transaction, backing out its database changes. A new transaction begins immediately after the ROLLBACK statement.
About Oracle SAVEPOINT
A SAVEPOINT is a marker within a transaction that allows for a partial rollback. As changes are made in a transaction, we can create SAVEPOINTs to mark different points within the transaction. If we encounter an error, we can rollback to a SAVEPOINT or all the way back to the beginning of the transaction. SQL> INSERT INTO AUTHOR 2 VALUES ('A11l', 'john', 3 'garmany', '123-345-4567', 4 '1234 here st', 'denver', 5 'CO','90204', '9999');
�1 row created. SQL> savepoint in_author; Savepoint created. SQL> INSERT INTO BOOK_AUTHOR VALUES ('A111', 'B130', .20); 1 row created. SQL> savepoint in_book_author; Savepoint created. SQL> INSERT INTO BOOK 2 VALUES ('B130', 'P002', 'easy oracle sql', 3 'miscellaneous', 9.95, 1000, 15, 0, '', 4 to_date ('02-20-2005','MM-DD-YYYY')); 1 row created. SQL> rollback to in_author; Rollback complete. In the example above, I inserted a row into the AUTHOR table and created a SAVEPOINT called in_author. Next, I inserted a row into the book_author table and created another SAVEPOINT called in_book_author. Finally, I inserted a row in the BOOK table. I then issued a ROLLBACK to in_author.
�EXPERIMENT NO: 10 AIM: TO MAKE VIEWS OF A TABLE THEORY: VIEWS :
A view is very commonly used database object that is derived at runtime. A view contains data of its own. Its contents are derived from another table. The command for creating view is CREATE VIEW command. Editing in the tables are automatically reflected in the views. It is virtual table & does not have any data of its own. SYNTAX TO CREATE A VIEW IS: SQL>CREATE [OR REPLACE] VIEW view name AS sub query [WITH CHECK OPTION] [WITH READ ONLY]; EXAMPLE IS: SQL>CREATE VIEW monika AS SELECT empno, ename, sal, comm FROM emp;
�TYPES OF VIEWS JOIN VIEW
It is defined as view that has more than one table specified in from clause and does not contain following clauses i.e. distinct, aggregation, group by. This type of view allows update, insert and delete command to change data in table.
SYNTAX SQL>CREATE OR REPLACE VIEW monika AS SELECT ename, empno, sal FROM emp, dept WHERE emp.deptno = dept.deptno; The views to be updateable must not include the following are
o o o
Set operators , aggregate functions Distinct operator , rownum pseudo columns Group by clause , having clause
INLINE VIEW
Oracle also offers an inline view that is very handy and inline view is part of SQL statements. It allows you in body of SQL statement to define SQL for view that SQL statement will use to resolve its query.
MATERIALIZED VIEW
Snapshot also called materialized view. It is defined as copy of part of table or entire table. It reflects the current status of table that is being copied. The original status table is also called master table. Two types are Read only and update. Read-only does not allow changes to be made in view. It simply publishes and subscribes the replications. It allows changes in local copy which periodically updates master table.
�EXPERIMENT NO: 11 AIM: TO MAKE INDEXES OF A TABLE THEORY:
SQL CREATE INDEX Statement
The CREATE INDEX statement is used to create indexes in tables. Indexes allow the database application to find data fast; without reading the whole table.
Indexes
An index can be created in a table to find data more quickly and efficiently the users cannot see the indexes, they are just used to speed up searches/queries. Note: Updating a table with indexes takes more time than updating a table without (because the indexes also need an update). So you should only create indexes on columns (and tables) that will be frequently searched against.
Syntax
Creates an index on a table. Duplicate values are allowed: CREATE INDEX index_name ON table_name (column_name)
SQL CREATE UNIQUE INDEX Syntax
Creates a unique index on a table. Duplicate values are not allowed: CREATE UNIQUE INDEX index_name ON table_name (column_name)
CREATE INDEX Example
The SQL statement below creates an index named "PIndex" on the "LastName" column in the "Persons" table: CREATE INDEX PIndex ON Persons (LastName) If you want to create an index on a combination of columns, you can list the column names within the parentheses, separated by commas: