100% found this document useful (2 votes)
778 views77 pagesData Science: Chapter 1: Introduction To Big Data
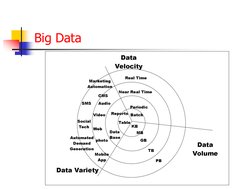
The document discusses the introduction to big data and data science. It defines big data as any data that is expensive to manage and hard to extract value from due to its volume, velocity, and variety. It provides examples of industries that gather and analyze large amounts of data. It also discusses attributes that define big data, types of data that exist, and what can be done with these different data types. Finally, it introduces data science and discusses goals, examples, key roles, and the analytics lifecycle process.
Uploaded by
Hrishikesh DabeerCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
100% found this document useful (2 votes)
778 views77 pagesData Science: Chapter 1: Introduction To Big Data
The document discusses the introduction to big data and data science. It defines big data as any data that is expensive to manage and hard to extract value from due to its volume, velocity, and variety. It provides examples of industries that gather and analyze large amounts of data. It also discusses attributes that define big data, types of data that exist, and what can be done with these different data types. Finally, it introduces data science and discusses goals, examples, key roles, and the analytics lifecycle process.
Uploaded by
Hrishikesh DabeerCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd