Informatica PowerCenter 7 Advance Training
Course Objectives
PowerCenter/PowerMart Architecture PowerCenter Advanced Transformations Informatica Performance Tuning Informatica Templates
�PowerCenter Architecture
�This section will cover Informatica Architecture & Connectivity - 6.x and 7.x Informatica Architecture & Connectivity 5.x
Architectural Differences
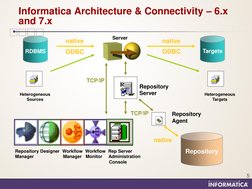
�Informatica Architecture & Connectivity 6.x and 7.x
native
RDBMS
Server
native ODBC
Targets
ODBC
TCP/IP
Heterogeneous Sources
Repository Server
Heterogeneous Targets
TCP/IP
Repository Agent
native
Repository Designer Workflow Workflow Rep Server Manager Manager Monitor Administration Console
Repository
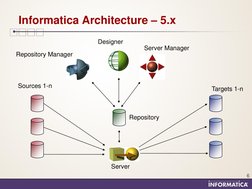
�Informatica Architecture 5.x
Designer Server Manager Repository Manager
Sources 1-n
Targets 1-n
Repository
Server
6
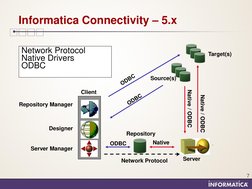
�Informatica Connectivity 5.x
Network Protocol Native Drivers ODBC
Source(s) Target(s)
Native / ODBC
Client Repository Manager
Native / ODBC
Designer Repository Server Manager ODBC Native
Network Protocol
Server
7
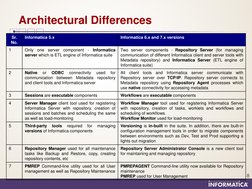
�Architectural Differences
Sr. No. 1 Informatica 5.x Only one server component - Informatica server which is ETL engine of Informatica suite Informatica 6.x and 7.x versions Two server components - Repository Server (for managing communication of different Informatica client and server tools with Metadata repository) and Informatica Server (ETL engine of Informatica suite) All client tools and Informatica server communicate with Repository server over TCP/IP. Repository server connects to Metadata repository using Repository Agent processes which use native connectivity for accessing metadata Workflows are executable components Workflow Manager tool used for registering Informatica Server with repository, creation of tasks, worklets and workflows and scheduling of workflows. Workflow Monitor used for load-monitoring Versioning is in-built in the suite. In addition, there are built-in configuration management tools in order to migrate components between environments such as Dev, Test and Prod supporting a lights out migration Repository Server Administrator Console is a new client tool for maintaining and managing repository PMREPAGENT Command-line utility now available for Repository maintenance 8 PMREP used for User Management
Native or ODBC connectivity used for communication between Metadata repository and client tools and Informatica server Sessions are executable components Server Manager client tool used for registering Informatica Server with repository, creation of sessions and batches and scheduling the same as well as load-monitoring Third-party tools required for versions of Informatica components managing
3 4
Repository Manager used for all maintenance tasks like Backup and Restore, copy, creating repository contents, etc PMREP Command-line utility used for all User management as well as Repository Maintenance
�PowerCenter Advanced Transformations
�This section will cover Transformation Concepts Recap Stored Procedure Transformation (Lab 1)
Filter Aggregator
Pivoting Data (Rows to columns) (Lab 2)
Incremental Aggregation (Lab 3,4) Implementation using mapping variables and Aggregator
Implementation using SP and Aggregator Implementation using Filter and Aggregator
Joiner
Self Join (Lab 5) Joiner to emulate Lookup Contd
10
� Normalizer
Converting Columns to Rows (Lab 6) Sourcing data from VSAM files
Understanding Transaction Control Transaction Control (Lab 7)
Transaction Control to restart sessions
Lookup
Dynamic Lookup Unconnected Lookup
Union Transformation (Lab 8)
11
�What is a transformation?
A transformation is repository object that generates, modifies and/or passes data to other repository object
12
�Transformation Types
Active Transformation The number of rows that pass through this transformation change, i.e. Number of rows in the transformation may or may not be equal to number of rows out of the transformation Example Number of rows coming in Filter transformation may be 10. But depending on condition, number of rows out of Filter can be anywhere between Zero and 10
Passive Transformation
The number of rows into the transformation is always equal to number of rows out of the transformation Example Number of rows into Expression is always equal to number of rows out of the transformation
13
�Stored Procedure Transformation
A stored procedure is a precompiled collection of Transact-SQL, PL/SQL or other database procedural and flow control statements. To call this from within Informatica, Stored Procedure Transformation is used This passive transformation can be connected or unconnected The stored procedure transformation can be scheduled to run Normal Runs like any other inline transformation Pre-load of the Source Runs before session retrieves data from the Source Post-load of the Source Runs after session retrieves data from the Source Pre-load of the Target Runs before session sends data to the Target Contd
14
�Stored Procedure Transformation
Post-load of the Target Runs after session sends data to the target
Informatica supports following databases for Stored Procedure Transformation:
Oracle Informix Sybase SQL Server Microsoft SQL Server IBM DB2
Teradata
Contd
15
�Stored Procedure Transformation
Stored Procedure Transformation Ports
Input/Output Parameters send and receive input and output parameters using ports, variables or values hard-coded in expression Return Values Status Codes The stored procedure issues a status code that notifies whether or not it completed successfully. PowerCenter server uses these to determine weather to continue running the session or stop it
Stored Procedure Transformation Properties
Stored Procedure Name Name of the procedure/function as in the database Connection Information Database containing the stored procedure. Default value is $Target Call Text This is used only when transformation type is not Normal. Input parameters passed to SP can be included within the call text
16
�Stored Procedure Transformation
17
�Filter - Basics
Filter transformation allows to filter rows in a mapping It is active transformation and is always connected
All ports in Filter transformation are input/output ports
Rows from multiple transformations cannot be concatenated into Filter Transformation. Thus input ports for Filter must come from a single transformation
Any expression that returns Boolean value can be used as a filter condition
Filter condition is case sensitive
18
�Filter Performance Tips
Place the filter as close as possible to the Source to maximize session performance
19
�Aggregator - Basics
Aggregator transformation performs aggregate calculations like sum, max, min, count on groups of data
Aggregate transformation uses Informatica Cache to perform these aggregations
Typically Aggregator has Aggregate expressions in output port
Group By port to create groups. The port can be I, I/O, V or O port
Aggregator is Active transformation and is always connected
20
�Aggregator Cache
21
�Aggregator Performance Tips
Connect only necessary input/output ports to subsequent transformations, reducing the size of data cache
Pass data to Aggregator sorted by Group By ports, in ascending or descending order
Use Incremental Aggregation if changes in Source are less than half the target
22
�Aggregator Pivoting Data (Rows to Columns)
In many scenarios, source data rows need to be converted to columns
Example: Source contains two fields, field_name and field_value. These are to be converted into a target table which has column names as given by list of field_names in Source
Aggregator transformation and FIRST function can be used for converting rows into columns Elaborating above example, target field names are First_Name, Last_Name, Middle_Name and Salutation o_First_Name = FIRST(field_value, field_name = FIRSTNAME)
1
Contd
23
�Aggregator Pivoting Data (Rows to Columns)
24
�Incremental Aggregation
When to use Incremental Aggregation? New source data can be captured Incremental changes do not significantly change the target When aggregation does not contain Percentile or median 2 functions When mapping includes aggregator with Transaction Transformation scope How to capture Incremental Data? Using Filter and Variables
1
Using Stored Procedure
25
�Incremental Aggregation
Session failure scenarios when using Incremental Aggregation When PowerCenter Server data movement mode is changed from ASCII to Unicode or vise-versa When PowerCenter Server code page is changed to incompatible code page When session sort order is changed for PowerCenter server in Unicode mode When Enable High Precision option is changed in a session To avoid session failures for above, reinitialize the cache by deleting the incremental aggregation files
26
�Incremental Aggregation
Configuring Session Set location of cache files. By default index and data files are created in $PMCacheDir Cache filenames can be written to session log by setting tracing level to Verbose Init. In session log, path after TE_7034 gives the location of index file and path after TE_7035 gives the location of data file Incremental Aggregation Session Properties can be set in Session -> Properties -> Performance
27
�Incremental Aggregation Using Mapping Variable
Mapping Variable
28
�Incremental Aggregation Using Filter
29
�Joiner - Basics
Joiner Transformation joins two sources with at least one matching port Joiner requires inputs from two separate pipelines or two branches from one pipeline Joiner is an Active transformation and is always connected Joiner transformation cannot be used in following cases: Either input pipeline contains an Update Strategy A Sequence Generator transformation is directly connected before a Joiner transformation Joiner conditions for string comparison are case sensitive Join types supported are Normal, Master Outer, Detail Outer and Full Outer
30
�Joiner - Cache
31
�Joiner Debugging Common Errors
"Assertion/Unexpected condition at file tengine.cpp line 4221" running session with multiple Joiners Product : PowerMart Problem Description: When running a session with multiple Joiner Transformations, the following error occurs: On NT: MAPPING> CMN_1141 ERROR: Unexpected condition at file:[d:\cheetah\builder\powrmart\server\dmapper\trans\tengine.cpp] line:[4221]. Application terminating. Contact Informatica Technical Support for assistance. On Unix: Session fails with no error and the following assertion appears on the standard output (stdout) of the pmserver machine. Assertion failed: ((m_teFlags) & (0x00000002)), file /export/home1/build50/pm50n/server/dmapper/trans/tengine.cpp, line 4221
32
�Joiner Debugging Common Errors
Solution: This is because of an invalid master/detail relationship for one or more of the Joiner Transformations. Informatica reads all the master rows before it starts reading the detail. So if there are multiple joiners in the mapping, make sure the master/detail relationships are defined in such a way that the server will be able to define the DSQ order.
33
�Self Join
Scenario of self join is encountered when some aggregated information is required along with Transaction data in target table
Using Joiner transformation, this can be achieved in Informatica PowerCenter version 7.x
This feature was not available in earlier Informatica versions
34
�Self Join
Aggregator and sorter outputs combined in Joiner transformation
35
�Joiner to emulate Lookup
A joiner can be used to emulate the lookup, but with certain limitations: - Only equi- conditions are supported. - Duplicate matching is not supported. - Joiner will always cache, Non-Cached is not an option. Here are the settings that need to be made on the Joiner for it to emulated the lookup: 1. The table that is used for the lookup must be brought into the mapping as a source. 2. The "lookup" table should be joined to the other table with an outer join. The outer join must be based on the "lookup" table, i.e. if it is the Detail table then it should be a Detail Outer Join, if it is the Master table then it should be a Master Outer Join.
36
�Joiner to emulate Lookup
3. The Condition must set in the same way that it would have been in the Lookup. Note: Only equi- conditions are allowed. 4. The lookup values must be mapped downstream from the Joiner just as it would be with a Lookup Transformation.
37
�Joiner to emulate Lookup
38
�Normalizer - Basics
Normalizer Transformation is used to organize the data in a mapping COBOL Sources For COBOL sources, Normalizer acts as a Source Qualifier These sources are often stored in normalized form, where OCCUR statement nests multiple records in single record For relational sources, Normalizer can be used to create multiple rows from a single row of data Normalizer is an Active transformation and is always connected
39
�Normalizer Ports
When using normalizer, two keys are generated Generated Key One port for each REDEFINES clause Naming convention - GK_<redefined_field_name> At the end of each session the Power Center updates the GK value to the last value generated for the session plus one Generated Column ID One port for each OCCURS clause Naming convention - GCID_<occurring_field_name>
Note: These are default ports created by Normalizer and cannot be deleted
40
�Normalizer Debugging Common Errors
A mapping that contains a Normalizer transformation fails to initialize with the following error: "TE_11017: Cannot match OFOSid with IFOTid"? Sol: This error will occur when the inputs to the Normalizer and outputs from it do not match. Resolutions: 1. Make sure there are no unconnected input ports to the Normalizer transformation. 2. If the Normalizer has an Occurs in it, make sure number of input ports matches the number of Occurs. Note: Second case is more common in mappings where Normalizer is not a Source Qualifier where definition is somehow changed by hand or damaged. To fix this, drop and then recreate the Normalizer transformation.
41
�Normalizer Debugging Common Errors
A session with a COBOL source crashes with the following error: WRITER_1_*_1> WRT_8167 Start loading table *********** FATAL ERROR : Caught a fatal signal/exception *********** *********** FATAL ERROR : Aborting the DTM process due to fatal signal/exception. *********** *********** FATAL ERROR : Signal Received: SIGSEGV (11) Sol: This error will occur when the normalizer output ports are connected to two downstream transformations. Contd
42
�Normalizer Debugging Common Errors
Resolution:
1. Add an Expression Transformation right after the Normalizer
2. Connect all the ports from the Normalizer to the Expression Transformation 3. Connect this Expression Transformation to the existing downstream transformations as needed
43
�Normalizer Converting Columns to Rows
Set Occurrence Change Level to 2
44
�Normalizer VSAM Sources
Built-in seq
45
�Understanding Transaction Control
A transaction is a set of rows bound by COMMIT or ROLLBACK, i.e. the transaction boundaries
Some rows may not be bound by Transaction boundaries and is an open transaction
Transaction boundaries originate from transaction control points Transaction Control Point is a transformation that defines or 1 redefines the transaction boundary
46
�Transformation Scope
PowerCenter server can be configured on how to apply transformation logic to incoming data with the Transformation Scope transformation property. Following values can be set: Row Applies the transformation logic to one row of data at a time. Examples are expression, external procedure, filter, lookup, normalizer (relational), router, sequence generator, stored procedure, etc.
Transaction Applies the transformation logic to all rows in a transaction. With this scope, PC server preserves incoming transaction boundaries. Examples are aggregator, joiner, Custom transformation, Rank, Sorter, etc.
All Input Applies the transformation logic on all incoming data. With this scope, PC server drops incoming transaction boundaries and outputs all rows from the transformation as an open transaction. For transformations like aggregator, joiner, Rank, Sorter and Custom transformation, this is default scope
47
�Transaction Control Transformation Basic
Transaction Control transformation is used to define conditions to commit or rollback transactions from relational, XML and dynamic IBM MQ series targets. Following built-in variables can be used to create transaction control expression TC_CONTINUE_TRANSACTION This is the default value of the expression TC_COMMIT_BEFORE TC_COMMIT_AFTER TC_ROLLBACK_BEFORE TC_ROLLBACK_AFTER Transaction Control Transformation is an Active transformation and is always connected
48
�Transaction Control Transformation Guidelines
If a mapping includes an XML target, and you choose to append or create a new document on commit, the input groups must receive data from the same transaction control point Transaction Control transformation connected to any target other than relational, XML or dynamic IBM MQSeries targets is ineffective for those targets Each target instance must be connected to Transaction Control transformation in a mapping where multiple targets are present Multiple targets can be connected to single Transaction Control transformation Only one effective Transaction Control transformation can be connected to a target Transaction Control transformation cannot be connected in a pipeline branch that starts with a Sequence Generator transformation Contd
49
�Transaction Control Transformation Guidelines
If Dynamic Lookup transformation and Transaction Control transformation are used in same mapping, a rolled-back transaction might result in unsynchronized target data A Transaction Control transformation may be effective for one target and ineffective for another target. If each target is connected to an effective Transaction Control transformation, mapping is valid Examples of Effective/Ineffective Transaction Control transformation Please refer Advanced training folder on Informatica Repository Transaction Control transformation can be used to Restart Failed sessions
Constraint-based delete of rows with foreign key relations
50
�Transaction Control Transformation
51
�Lookup - Basics
Lookup transformation is created when data is to be looked up Lookup transformation is passive and can be connected or unconnected Lookup is used to perform tasks like Getting a related value (keys from dimension table) Perform a calculation
Update slowly changing dimension tables
Lookup can be configured as Connected or unconnected
Relational or flat file lookup
Cached or un-cached For un-cached lookups, PowerCenter server queries the Lookup table for each input row
52
�Lookup - Cache
The PowerCenter Server builds a cache in memory when it processes the first row of data in a cached Lookup transformation
The PowerCenter Server stores Condition Values in the Index Cache and Output Values in Data Cache
Cache files are created in $PMCacheDir by default. These files are deleted and cache memory is released on completion of session, exception being Persistent Caches Lookup cache can be Persistent Cache Static Cache Dynamic Cache Shared Cache
53
�Lookup - Cache
Persistent Cache With this option, lookup cache files are created by Informatica Server the first time and can be reused the next time Informatica Server processes Lookup transformation, thus eliminating the time required to read the Lookup table. Lookup can be configured to use persistent cache when table does not change between sessions. Static Cache By default, PowerCenter Server creates static or read-only cache for any lookup table. The PowerCenter Server does not update the cache while it processes the Lookup Transformation Dynamic Cache Usual scenario where dynamic cache is used is when Lookup table is also a target table. The PowerCenter Server dynamically inserts or updates data in Lookup cache
Shared Cache Lookup cache can be shared between multiple transformations. Unnamed cache can be shared between transformations of single mapping. Named cache can be shared between transformations of single mapping or across mappings
54
�Lookup - Cache
55
�Unconnected Lookup
An Unconnected Lookup transformation receives input values from the result of :LKP expression in another transformation Unconnected Lookup transformation can be called more than once in a mapping Unconnected Lookup transformation can return only single column as against connected lookup. This single column is designated as Return Port
Unconnected Lookup does not support user-defined default value for return port. By default, return value is NULL
Unconnected Lookup cannot have dynamic cache Unconnected Lookup can be used in scenarios where Slowly changing dimension tables are to be updated Lookup is called multiple times Conditional Lookup
56
�Dynamic Lookup Cache Advantages
When the target table is also the Lookup table, cache is changed dynamically as the target load rows are processed in the mapping New rows to be inserted into the target or for update to the target will affect the dynamic Lookup cache as they are processed Subsequent rows will know the handling of previous rows Dynamic Lookup cache and target load rows remain synchronized throughout the Session run
57
�Update Dynamic Lookup Cache
NewLookupRow port values
0 static lookup, cache is not changed 1 insert row to Lookup cache 2 update row in Lookup cache
Does NOT change row type
Use the Update Strategy transformation before or after Lookup, to flag rows for insert or update to the target
Ignore NULL Property
Per port Ignore NULL values from input row and update the cache only with non-NULL values from input
58
�Example: Dynamic Lookup Configuration
Router Group Filter Condition should be: NewLookupRow = 1
This allows isolation of insert rows from update rows
59
�Dynamic Lookup Cache Common Errors
"Lookup field has no associated port" when validating dynamic Lookup Transformation Sol: This message occurs when the Dynamic Lookup Cache lookup property is selected and one or more lookup/output ports have not been associated with an input port. To resolve this, go to the Ports tab and choose an Associated Port for each output/lookup port. Additional Information When a dynamic lookup cache is used, each lookup/output port must be associated with an appropriate input port or a sequence id. The session inserts or updates rows in the lookup cache based on data in associated ports. When a sequence-id is selected in Associated Port column, Informatica Server generates a key for new records inserted in lookup cache.
60
�Dynamic Lookup Cache Common Errors
"CMN_1650 A duplicate row was inserted into a dynamic lookup cache" running session Sol: This error occurs when the table on which the lookup is built has duplicate rows. Since a dynamic cached lookup cannot be created with duplicate rows, the session fails with this error.
Additional Information Following options are available to work around this: Make sure there are no duplicate rows in the table before starting the session Use a static cache instead of dynamic cache Do a SELECT DISTINCT in the lookup cache SQL
61
�Union Transformation - Basics
Union Transformation is a multiple input group transformation that merges data from multiple pipelines or pipeline branches into a single pipeline branch Union transformation is an active transformation and is always connected. This transformation merges data similar to the Union All SQL statement, i.e. the transformation does not remove duplicates. Update Strategy or Sequence Generator transformations cannot be used upstream from a Union transformation. Union transformation is an example of Custom transformation. Editable tabs Transformation, Properties, Groups, Group Ports Non-editable tabs Ports, Initialization Properties, Metadata Extensions, Port Attribute Definitions Designer creates one Output group by default. You cannot edit or delete the output group Input ports can be created by copying ports from upstream transformations. Designer uses the port names specified on the Group Ports tab for each input and output ports, and it appends a number to make each port name in the transformation unique.
62
�Union Transformation Common Errors
New order of group ports in a Union Transformation is not reflected in the links Problem Description: After re-ordering the group ports in a Union Transformation the new order is not reflected in the links from the preceding transformation. Example: Suppose there are two ports A and B in a Source Qualifiers and UA and UB in a Union Transformation with port A connected to port UA and port B connected to port UB. Changing the order of the ports UA and UB in the Union Transformation links A to UB and B to UA.
Solution: This is a known issue (CR 83107) with PowerCenter 7.1.x.
Workaround: Delete the incorrect links and create new links.
63
�Union Transformation Common Errors
Union Transformation and XML Transformations are grayed out in the Designer
Problem Description: While editing a mapping, the following transformations are grayed out and cannot be added to a mapping or created in Transformation Developer Union, Mid-Stream XML Generator, Midstream XML Parser
Solution: The transformations are grayed out because they need to be registered in the PowerCenter repository. These transformation types were introduced in PowerCenter 7.x and are treated as "native" plug-ins to the PowerCenter Repository. Like any plugin, they need to be registered in the repository. In normal operations when the repository is created, they should be registered automatically. If the registration did not occur, these transformations are not available in the Designer. Contd
64
�Union Transformation Common Errors
Resolution: To resolve this issue, you need to manually register these plug-ins. You can do so using pmrepagent commands from the command line. To register the plug-in, you need to locate the XML file for the plug-in. The XML file for a native plug-in is located in PowerCenter Repository Server native subdirectory. First navigate to the directory where the pmrepserver binary is installed. Then, change the command argument for database type to the database used for your repository. The following example shows how to register the Union transformation on Microsoft SQL Server and Oracle: On Windows, enter the following commands:
pmrepagent registerplugin -r RepositoryName -n Administrator -x Administrator -t "Microsoft SQL Server" -u DatabaseUserName -p DatabasePassword -c DatabaseConnectString -i native\pmuniontransform.xml
On UNIX, enter the following commands: pmrepagent registerplugin -r RepositoryName -n Administrator -x Administrator -t "Oracle" -u DatabaseUserName -p DatabasePassword -c DatabaseConnectString -i native/pmuniontransform.xml
65
�Union Transformation
66
�Datatype Sizes for calculating Cache
Datatype Binary Date/Time Decimal, high precision off (all precision) Decimal, high precision on (precision <=18) Decimal, high precision on (precision >18, <=28) Decimal, high precision on (precision >28) Decimal, high precision on (negative scale) Aggregator, Rank precision + 2 18 10 18 22 10 10 Joiner, Lookup
precision + 8 Round to nearest multiple of 8
24 16 24 32 16 16
Double
Real Integer Small integer
10
10 6 6
16
16 16 16 Unicode mode: 2*(precision + 5) ASCII mode: precision + 9
NString, NText, String, Text
Unicode mode: 2*(precision + 2) ASCII mode: precision + 3
67
�Datatype Sizes for calculating Sorter Cache
68
�Cache Sizes
Transformation Name AGGREGATOR Min Index Cache Size Number of Groups * [(Summation( Column size) + 17] 200 * [(Summation of Column size) + 16] Number of input rows * [(Summation of Column size) + 16] (Sum of master column sizes in join condition + 16) X number rows in master table Number OF Groups * [(Sum of Column size) + 17] (Sum of master column sizes NOT in join condition but on output ports + 8) * number of rows in master table Number of Groups * [(number of ranks * ((Sum of Column size) + 10)) + 20] Max Index Cache Size Double Min Index Cache size Number of rows in Lookup table * [(Summation of Column size) + 16] * 2 Data Cache Size Number of Groups * [(Summation( Column size) + 7] Number of rows in Lookup table * [(Summation of Column size) + 8]
LOOKUP
SORTER
JOINER
RANK
69
�Informatica Performance Tuning
70
�This section will cover What is Performance Tuning Measuring Performance
Bottlenecks Mapping Optimization Session Task Optimization Partitioning (Lab 9)
71
�Performance Tuning
There are two general areas to optimize and tune External components to Informatica (OS, memory, etc.) Internal to Informatica (tasks, mapping, workflows, etc.) Getting data through the Informatica engine This involves optimizing at the task and mapping level This involves optimizing the system to make sure Informatica runs well Getting data into and out of the Informatica engine This usually involves optimizing non-Informatica components The engine cant run faster than the source or target
72
�Measuring Performance
For the purpose of identifying bottlenecks we will use:
Wall Clock time as a relative measurement time
Number of rows loaded over the period of time (rows per
second)
Rows per second (rows/sec) will allow performance measurement of a session over a period of time and with changes in our environment. Rows per sec can have a very wide range depending on the size of the row (number of bytes), the type of source/target (flat file or relational) and underlying hardware.
73
�Identifying Bottlenecks
Reader Processes Configure session to read from Flat File target instead of relational target Measure the performance Writer Processes Configure session to read from Flat File target instead of relational target Measure the performance Mapping Generally if the bottleneck is not with the reader or writer process then the next step is to review the mapping Mapping bottlenecks can be created by improper configuration of aggregator, joiner, sorter, rank and lookup caches
74
�Mapping Optimizing
Single-Pass Read Use a single SQL when reading multiple tables from the same database. Data type conversions are expensive Watch out for hidden port to port data type conversions Over use of string and character conversion functions Use filters early and often Filters can be used as SQL overrides (Source Qualifies, Lookups) and as transformations to reduce the amount of data processed
Simplify expressions Factor out common logic Use variables to reduce the number of time a function is used
75
�Mapping Optimizing
Use operators instead of functions when possible
The concatenation operator (||) is faster than the CONCAT
function
Simplify nested IIFs when possible Use proper cache sizing for Aggregators, Rank, Sorter, Joiner and Lookup transformations
Incorrect cache sizing creates additional disk swaps that
can have a large performance degradation Use the performance counters to verify correct sizing
76
�Session Task Optimizing
Run partitioned sessions
Improved performance Better utilization of CPU, I/O and data source/target
bandwidth
Use Incremental Aggregation when possible
Good for rolling average type aggregation
Reduce transformation errors
Put logic in place to reduce bad data such as nulls in a
calculation
Reduce the level of tracing
Tip: See the Velocity Methodology Document for further information
77
�Partitioned Extraction and Load
Key Range Round Robin
Hash Auto Keys
Hash User Keys Pass Through
78
�Partitioned Extraction and Load
Key Range Partition
Data is distributed between partitions according to
pre-defined range values for keys Available in PowerCenter 5, but only for Source Qualifier. Key Range partitioning can be applied to other transformations in 6.x and up Common use for this new functionality:
Apply to Target Definition to align output with physical partition scheme of target table. Apply to Target Definition to write all data to a single file to stream into a database bulk loader that does not support concurrent loads (e.g. Teradata, DB2)
79
�Partitioned Extraction and Load
Key Range Partition (Continued)
You can select input or input/output ports for the keys,
not variable ports and output only ports.
Remember, the partition occurs BEFORE the transformation;
hence variable and output only are not allowed because they have not yet been evaluated
You can select multiple keys to form a Composite Key Range specification is: Start Range and End Range You can specify an Open Range also NULL values will go to the First Partition All unmatched rows will also go into First Partition, user will see the following warning message once in the log file:
80
TRANSF_1_1_2_1> TT_11083 WARNING! A row did not match any of the key ranges specified at transformation [EXPTRANS]. This row and all subsequent unmatched rows will be sent to the first target partition.
�Partitioned Extraction and Load
Round Robin Partitioning
The Informatica Server evenly distributes the data to
each partition. The user need not specify anything because key values are not interrogated Common use:
Apply to a flat file source qualifier when dealing with unequal
input file sizes Use user hash when there are downstream lookups/joiners Trick: All but one of the input files can be empty you no longer have to physically partition input files Note: There are performance implications with doing this. Sometimes its better, sometimes its worse.
81
�Partitioned Extraction and Load
Hash Partitioning
Data is distributed between partitions according to a hash
function applied to the key values PowerCenter supports Auto Hash Partitioning automatically for aggregator and rank transformations Goal: Evenly distribute data, but make sure that like key values are always processed by the same partition A hash function is applied to a set of ports.
Hash function returns a value between 1 and the number of partitions. A good hash function provides a uniform distribution of return values
Not all 1s or all 2s, but an even mix.
Based on this functions return value, the row is routed to
the corresponding partition (e.g. if 1, send to partition 1, if 2, send to partition 2, etc.)
82
�Partitioned Extraction and Load
Hash Auto Key
No need to specify the keys to hash on. Automatically uses all
key ports (ex, Group By key or Sort key) as a composite key Only valid for Unsorted Aggregation, Rank and Sorter The default partition type for unsorted aggregator and rank NULL values will get converted to zero for hashing.
Hash Key
Just like Auto Hash Key, but the user explicitly specifies the ports
to be used as the key.
Only input and input/output ports allowed
Common use: When dealing with input files of unequal sizes, hash partition (vs. round-robin) data into downstream lookups and joiners to improve locality of reference of caches (hash on ports used in the lookup/join condition) Override the auto hash for performance reasons
Hashing is faster on numeric values vs. strings
83
�Partitioned Extraction and Load
Pass Through Partitioning
Data is passed through to the next stage within the current
partition Since data is not distributed, the user need not specify anything Common use:
Create additional stages (processing threads) within pipeline
to improve performance
84
�Partitioned Extraction and Load
Partition tab appears in Session Task from within the Workflow Manager
85
�Partitioned Extraction and Load
By default, session tasks have the following partition points and partition schemes: Relational Source, Target (Pass Through) File Source, Target (Pass Through) Unsorted Aggregator, Rank (Auto Hash) NOTE: You cannot delete the default partition points for sources and targets.
You can NOT run debug session with number of partition >1
86
�Partitioning Dos
Cache as much as possible in memory Spread cache files across multiple physical devices both within and across partitions Unless the directory is hosted on some kind of disk array, configure disk based caches to use as many disk devices as possible Round Robin or Hash partition a single input file until you determine this is bottleneck Range Partition to align source/target with physical partitioning scheme of source/target tables Pass through partition to apply more CPU resources to a pipeline (when TX is bottleneck)
87
�Partitioning Donts
Dont add partition points if the session is already source or target constrained Tune the source or target to eliminate the bottleneck Dont add partition points if the CPUs are already maxed out (%idle < ~5%) Eliminate unnecessary processing and/or buy more CPUs Dont add partition points if system performance monitor shows regular page out activity Eliminate unnecessary processing and/or buy more memory Dont add multiple partitions until youve tested and tuned a single partition Youll be glad you did
88
�Default Partition Points
Default partitioning points
Reader
Transformation
Transformation
Writer
Default Partition Points
Default Partition Point Default Partition Type Description
Source Qualifier or Normalizer Transformation Rank and unsorted Aggregator Transformation Target Instances
Pass-through
Controls how the Server reads data from the source and passes data into the source qualifier Ensures that the Server group rows before it sends them to the transformation Control how the instances distribute data to the targets
Hash auto-keys
Pass-through
89
�Informatica Templates
90
�This section will cover Template for generating Mapping Specifications Template for generating sessions/workflow specifications Unit Test Plan for Informatica Mapping Standards and Best Practices
91
�Mapping Specifications
92
�Session/Workflow Specifications
93
�94