0% found this document useful (0 votes)
425 views72 pagesBig Data Analytics (CS443) IV B.Tech (IT) 2018-19 I Semester
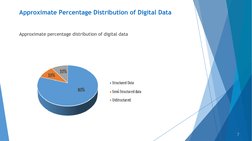
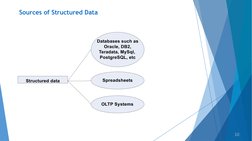
The document discusses different types of digital data: structured, semi-structured, and unstructured. Structured data is organized and stored in databases, spreadsheets, and transaction systems. Semi-structured data includes XML, JSON, and other markup languages that have some structure. Unstructured data makes up 80-90% of organizational data and includes text, images, audio, and video with no predefined structure. The document also outlines methods for dealing with unstructured data such as data mining, natural language processing, and text analytics.
Uploaded by
SivaCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
425 views72 pagesBig Data Analytics (CS443) IV B.Tech (IT) 2018-19 I Semester
The document discusses different types of digital data: structured, semi-structured, and unstructured. Structured data is organized and stored in databases, spreadsheets, and transaction systems. Semi-structured data includes XML, JSON, and other markup languages that have some structure. Unstructured data makes up 80-90% of organizational data and includes text, images, audio, and video with no predefined structure. The document also outlines methods for dealing with unstructured data such as data mining, natural language processing, and text analytics.
Uploaded by
SivaCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
- Types of Digital Data
- Structured Data
- Semi-structured Data
- Unstructured Data
- Introduction to Big Data
- Big Data Analytics