Professional Documents
Culture Documents
Music Similarity
Uploaded by
sommukhOriginal Description:
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Music Similarity
Uploaded by
sommukhCopyright:
Available Formats
INVESTIGATIONS IN MUSIC SIMILARITY:
ANALYSIS, ORGANIZATION, AND VISUALIZATION USING TONAL
FEATURES
by
Arpi Mardirossian
A Dissertation Presented to the
FACULTY OF THE GRADUATE SCHOOL
UNIVERSITY OF SOUTHERN CALIFORNIA
In Partial Fulllment of the
Requirements for the Degree
DOCTOR OF PHILOSOPHY
(INDUSTRIAL AND SYSTEMS ENGINEERING)
August 2007
Copyright 2007 Arpi Mardirossian
UMI Number: 3283520
3283520
2007
Copyright 2007 by
Mardirossian, Arpi
UMI Microform
Copyright
All rights reserved. This microform edition is protected against
unauthorized copying under Title 17, United States Code.
ProQuest Information and Learning Company
300 North Zeeb Road
P.O. Box 1346
Ann Arbor, MI 48106-1346
All rights reserved.
by ProQuest Information and Learning Company.
Acknowledgments
I would like to thank, rst and foremost, my advisor Prof. Elaine Chew. She has
played a critical role in my pursuits and accomplishments. I have been awed by her
talent, knowledge, dedication, and strong will. I credit her with opening my eyes
to the wonderful world of research and for setting an example of how to set high
standards, be dedicated to achieving goals, and communicate ideas eectively. She
is a true inspiration.
I would also like to thank my committee members for their time, helpful com-
ments and suggestions, and expertise. They have pushed me to explore directions
I otherwise might not have explored.
Lastly, I would like to thank my entire family for their love, encouragement
and support. Also, I thank my husband for his loving and supportive nature, my
father for his sheer joy and enthusiasm for my accomplishments and my mother
for her wisdom and constant guidance.
ii
Contents
Acknowledgments ii
List of Tables vi
List of Figures viii
Abstract xiii
Chapter 1: Introduction 1
Music Similarity 3
Music Visualization 5
Outline 5
Chapter 2: Related Work on Music Similarity Assessment 7
Music Similarity Systems Based on Pitch 8
Melodic Similarity 8
Harmonic Similarity 9
High-Level Pitch Similarity 10
Music Similarity Systems Based on Rhythm 10
Music Similarity Systems Based on Timbre 12
Discussion 13
Chapter 3: Quantifying Music Similarity 14
Pitch Class Distributions Feature 15
Segmentation 16
Key Determination 17
Spiral Array Model 17
Pitch Spelling 19
CEG Key-Finding Algorithm 20
SKeFiS Evaluation 21
Key Distributions Feature 23
Mean-Time-In-Key Distributions Feature 24
Comparing Two Pitch Class Distributions 25
iii
Comparing Two Key Sequences 26
Comparing Two Key Distributions 29
Comparing Pairs of Key and Mean-Time-In-Key Distribution 30
Example 32
Chapter 4: Similarity Experiments 36
Experiment: Dierent Renditions of a Piece 38
Analysis of Results for Method PD 40
Analysis of Results for Method SA 43
Analysis of Results for Method KD 46
Analysis of Results for Method KMD 49
Segmentation Parameter Selection 51
Results Overview 54
Experiment: Theme and Variations 55
Analysis of Results for Method PD 56
Analysis of Results for Method SA 59
Analysis of Results for Method KD 62
Analysis of Results for Method KMD 65
Segmentation Parameter Selection 68
Results Overview 71
Method Performance Analysis 72
Chapter 5: Related Work on Music Visualization 77
Static Visualization of Direct Data 78
Dynamic Visualization of Direct Data 79
Static Visualization of Interpreted Data 81
Dynamic Visualization of Interpreted Data 83
Chapter 6: Dynamic Music Visualization 89
Information Design Qualities of Dynamic Visualization Method 90
Escaping Flatland 90
Small Multiple Design 92
Color and Information 93
System Description 94
Tonal Pitch Space 95
Color Selection 96
Animation 97
User Interface 97
Example 98
Validation 99
Pitch Translation Invariance 99
Octave Translation Invariance 100
iv
Time Scaling Invariance 101
Amplitude Scaling Invariance 101
Time Translation Invariance 101
Demonstrations 102
Classical Music 102
Armenian Music 105
Results Overview and Discussion 107
Chapter 7: Static Aggregate Music Visualization 110
Segmentation 111
Visualization 111
Example 112
Discussion 114
Chapter 8: Conclusion 116
Music Similarity 116
Music Visualization 120
Future Work 121
References 122
v
List of Tables
1 Overview of Features and Similarity Metrics Used for Similarity
Assessment Methods 15
2 Points Allocated to Keys Identied with Key-Finding Algorithms 22
3 Evaluation Results for SKeFiS Key-Finding System 23
4 Mismatch Costs
x
i
y
j
Used for Sequence Alignment Algorithms 28
5 Sequences of Keys Identied for Example Pieces A, B and C 33
6 Summary of Pieces in the Data Set Used for the Experiment with
Dierent Renditions of a Piece 39
7 Segmentation Value for Methods SA, KD and KMD Using the Ren-
ditions Data 54
8 Type I and Type II Errors for Methods PD, SA, KD and KMD
Using the Renditions Data 55
9 Probabilities for Methods PD, SA, KD and KMD Using the Rendi-
tions Data 55
10 Summary of Pieces in the Data Set Used for the Experiment with
Theme and Variations 56
11 Segmentation Value for Methods SA, KD and KMD Using the Vari-
ations Data 70
12 Type I and Type II Errors for Methods PD, SA, KD and KMD
Using the Variations Data 71
13 Probabilities for Methods PD, SA, KD and KMD Using the Varia-
tions Data 72
14 Key Representation on Tonal Pitch Space 96
vi
15 Type I and Type II Errors for Methods PD, SA, KD and KMD
Using the Renditions Data 118
16 Probabilities for Methods PD, SA, KD and KMD Using the Rendi-
tions Data 118
17 Type I and Type II Errors for Methods PD, SA, KD and KMD
Using the Variations Data 119
18 Probabilities for Methods PD, SA, KD and KMD Using the Varia-
tions Data 119
19 Segmentation Parameter Size for Methods SA, KD and KMD 119
vii
List of Figures
1 Levels of Music Similarity 4
2 Pitch Class Representation on the Spiral Array [Chew 2001], [Chew
2000] (Image used with permission of author) 18
3 System Diagram for Method PD 25
4 System Diagram for Method SA 26
5 System Diagram for Method KD 30
6 System Diagram for Method KMD 31
7 Plot of vector E for example Pieces A, B, and C 33
8 Plot of vector F for example Pieces A, B, and C 34
9 Plot of vector A for example Pieces A, B, and C 34
10 Quantile-Quantile Plot Comparing Groups S and D of Rendition
Sets Data Using Method PD 40
11 Distributions of Distance Measure, Obtained Using Method PD,
Divided into Groups S and D for Rendition Sets Data 41
12 Quantile-Quantile Plot Comparing Groups S and D of Rendition
Sets Data Using Method SA 43
13 Distributions of Distance Measure, Obtained Using Method SA,
Divided into Groups S and D for Rendition Sets Data 44
14 Quantile-Quantile Plot Comparing Groups S and D of Rendition
Sets Data Using Method KD 46
15 Distributions of Distance Measure, Obtained Using Method KD,
Divided into Groups S and D for Rendition Sets Data 47
viii
16 Quantile-Quantile Plot Comparing Groups S and D of Rendition
Sets Data Using Method KMD 49
17 Distributions of Distance Measure, Obtained Using Method KMD,
Divided into Groups S and D for Rendition Sets Data 50
18 Plot of Type I, Type II and Total Errors for Method SA of Rendition
Sets Data 52
19 Plot of Type I, Type II and Total Errors for Method KD of Rendition
Sets Data 52
20 Plot of Type I, Type II and Total Errors for Method KMD of Ren-
dition Sets Data 53
21 Quantile-Quantile Plot Comparing Groups S and D of Variation
Sets Data Using Method PD 57
22 Distributions of Distance Measure, Obtained Using Method PD,
Divided into Groups S and D for Variation Sets Data 58
23 Quantile-Quantile Plot Comparing Groups S and D of Variation
Sets Data Using Method SA 60
24 Distributions of Distance Measure, Obtained Using Method SA,
Divided into Groups S and D for Variation Sets Data 61
25 Quantile-Quantile Plot Comparing Groups S and D of Variation
Sets Data Using Method KD 63
26 Distributions of Distance Measure, Obtained Using Method KD,
Divided into Groups S and D for Variation Sets Data 64
27 Quantile-Quantile Plot Comparing Groups S and D of Variation
Sets Data Using Method KMD 66
28 Distributions of Distance Measure, Obtained Using Method KMD,
Divided into Groups S and D for Variation Sets Data 67
29 Plot of Type I, Type II and Total Errors for Method SA of Variation
Sets Data 69
30 Plot of Type I, Type II and Total Errors for Method KD of Variation
Sets Data 69
ix
31 Plot of Type I, Type II and Total Errors for Method KMD of Vari-
ation Sets Data 70
32 Plot of Type I, Type II and Total Errors for Methods PD, SA, KD
and KMD of Rendition Sets Data 73
33 Plot of Type I, Type II and Total Errors for Methods PD, SA, KD
and KMD of Variation Sets Data 73
34 Plot of Type I, Type II and Total Errors for Rendition and Variation
Sets data of Method PD 74
35 Plot of Type I, Type II and Total Errors for Rendition and Variation
Sets data of Method SA 74
36 Plot of Type I, Type II and Total Errors for Rendition and Variation
Sets data of Method KD 75
37 Plot of Type I, Type II and Total Errors for Rendition and Variation
Sets data of Method KMD 75
38 Screen Shot of sndpeek [Misra et al. 2005] (Image used with permis-
sion of author) 79
39 Screen Shot of Music Animation Machine [Malinowski 2007] Visual-
izing William Byrds A Voluntarie: for my ladye nevell (Image used
with permission of author) 80
40 Screen Shot of Impromptu [Bamberger 2000] (Image used with per-
mission of author) 80
41 Self-similarity Visualization of Bachs BWV 846 [Foote & Cooper
2001] (Image used with permission of author) 81
42 Self-similarity Visualization of Bachs Goldberg Variations [Watten-
berg 2007] (Image used with permission of author) 82
43 Key Visualization of Mozarts K. 439b [Sapp 2001] (Image used with
permission of author) 83
44 Snapshot of Visualization of Listeners Continuous Ratings of Tonal
Context [Toiviainen & Krumhansl 2003] (Image used with permis-
sion of author) 84
45 Snapshot of Key Correlation Visualization [Gomez & Bonada 2005]
(Image used with permission of author) 85
x
46 Snapshot of KeyGram Visualization [Gomez & Bonada 2005] (Image
used with permission of author) 86
47 Snapshot of Tempo-Loudness Visualization [Langer & Goebl 2003]
(Image used with permission of author) 86
48 Snapshot of MuSA.RT Visualization [Chew & Francois 2005] (Image
used with permission of author) 87
49 Kellom Tomlinson, The Art of Dancing, Explained by Reading and
Figures (London, 1735), book I, plate XII (Image used with permis-
sion of publisher) 91
50 Rules and Regulations for the Government of Employees of the Oper-
ating Department of the Hudson and Manhattan Railroad Company,
Eective October 1st, 1923 (New York, 1923) (Image used with per-
mission of publisher) 92
51 Oliver Byrne, The First Six Books of the Elements of Euclid in
Which Coloured Diagrams and Symbols Are Used Instead of Letters
for the Greater Ease of Learners (London, 1847) (Image used with
permission of publisher) 93
52 System Diagram for Dynamic Visualization Method 94
53 Color Assignments for Major and Minor Keys 96
54 Snapshot of Dynamic Visualization Interface 98
55 Frame-by-Frame Dynamic Visualization of Beethovens WoO80 First
Variation 99
56 Last Frame of Dynamic Visualization of Mozarts K265 Theme -
Original Piece and Alterations 100
57 Frame-by-Frame Dynamic Visualization of Bachs BWV 544 103
58 Frame-by-Frame Dynamic Visualization of Beethovens Op. 93 103
59 Frame-by-Frame Dynamic Visualization of Chopins Op. 10 No. 1 104
60 Color Coded Key Progressions for Twenty Five Classical Pieces 105
61 Frame-by-Frame Dynamic Visualization of Armenian dance song
Barer 106
xi
62 Frame-by-Frame Dynamic Visualization of Armenian dance song
Amber Goran 106
63 Frame-by-Frame Dynamic Visualization of Armenian dance song
Apheres Oor Es 107
64 Color Coded Key Progressions for Twenty Five Armenian Songs 108
65 Aerial Visualization of Hierarchical Description Tree Conguration 112
66 Normalized Aerial Visualization of Example Piece A 113
67 Normalized Aerial Visualization of Example Piece B 113
68 Normalized Aerial Visualization of Example Piece C 114
xii
Abstract
This dissertation is in the area of music information retrieval, which is an interdis-
ciplinary science that incorporates knowledge and expertise from articial intelli-
gence, music theory, mathematical modeling, computational analysis, databases,
music perception and music cognition. We are focused on developing computa-
tional ways to accurately assess, quantify, and visualize degrees of musical simi-
larity. This involves the end-to-end development of computational tools, from the
design of the mathematical models, to the implementation and testing of the algo-
rithms on large datasets, to the creation of an intuitive and user-centered interface
for communicating the results. This dissertation has two parts: music similarity
assessment and music visualization.
Music similarity assessment is a complex problem; denitions of similarity can
diverge widely and be highly subjective. Can we build computer models to recog-
nize these dierent degrees of similarity? Our work addresses this question, and
has focused on the development of similarity metrics based on tonal features, which
are obtained from pitch and key information. We have developed four methods of
similarity assessment, each using one of the following features: pitch class distri-
butions, key sequences, key distributions, and mean-time-in-key distributions, and
based on one of the following similarity metrics: L
1
norm, L
2
norm, and sequence
alignment.
xiii
We use the similarity assessment techniques to conduct two sets of experiments:
the rst uses dierent renditions of pieces, while the second uses theme and varia-
tion pieces. For each experiment, all four methods are used to compare the pieces
in each data set one to another. Statistical analyses such as quantile-quantile plots
and the Kolmogorov-Smirnov test conrm that comparison results from within
similar and across dissimilar sets come from dierent underlying distributions for
all the methods. A Mann-Whitney rank sum test conrms that results for sim-
ilar and dissimilar pieces come from distributions with dierent medians for all
the methods. We further compute Type I, Type II and Bayesian probabilities to
analyze each methods performance.
While metrics are a quick and clear way to determine similarity, visualizations
can add a richness and complexity to the analysis. Our goal is to present music
information in a visual form that is intuitive and easy to access. One method of
visualization we have developed is a dynamic visualization that displays the pro-
gression of the tonal content of a music piece on a two-dimensional representation
of keys. The sequence of keys in a music piece is mapped onto a space that con-
tains points representing all possible keys. The distribution of keys of a piece being
visualized is indicated as growing colored discs, where the colors correspond to the
keys detected, and the size of the discs to the key frequency. This visualization
is an improvement over more basic charting methods, such as histograms, and it
maintains standards of information design in the form of added dimensionality,
color, and animation. We show that the visualization is invariant under music
transformations that preserve the pieces identity.
We demonstrate the dynamic visualization system using two music genres. We
consider classical and Armenian music. Classical music tends to follow a pattern
of beginning in the key of the piece, traveling to neighboring keys throughout the
xiv
course of the piece before returning to the key of the piece in the end. In contrast,
Armenian music follows a more sequential pattern where the piece begins in a key,
remains there for a period of time before moving on to other keys. It rarely ends in
the key it rst visited. We use the visualization method to illustrate these patterns
for a set of classical and Armenian pieces.
Another method of visualization we have developed exploits the tonal properties
of music to derive a hierarchical description for each piece that can then be used in
conjunction with the dynamic visualization. The visualization is generated using a
tree of keys in circular formation. This static aggregate visualization is a high-level,
aerial version of the dynamic visualization that allows a user to get a quick-glance
overview of the dynamic visualization of a piece. We illustrate the usefulness of
this visualization through several examples.
xv
Chapter 1: Introduction
Music is a fundamental part of our existence. It touches every person of every
culture. While music transcends time and generations, the format with which
we receive music is ever changing. We are currently experiencing a digitization
of music. This rapid growth of digital music information necessitates the devel-
opment of computational tools for music information retrieval (MIR). MIR is a
multidisciplinary research endeavor that strives to develop innovative content based
searching schemes, novel interfaces, and evolving networked delivery mechanisms
in an eort to make the worlds vast store of music accessible to all [Downie 2003].
MIR incorporates knowledge and expertise from articial intelligence, music the-
ory, mathematical modeling, computational analysis, databases, music perception
and music cognition. Our domain of interest lies in content-based MIR which is the
retrieval of music by content rather than by title, artist, band or composer. Name
That Tune is an example of retrieval by content. Within the broad range of MIR
tasks, we have focused on two main topics: music similarity assessment and music
visualization. Music similarity assessment is a task that must often be performed
as part of bigger MIR projects. Music visualization is a topic related to music
similarity assessment in that it provides a visual component on which to base sim-
ilarity measures. Visualizations often reveal characteristics that would otherwise
be hidden. We have focused on nding computational ways to accurately assess,
1
quantify, and visualize degrees of musical similarity. This involves the end-to-end
development of computational tools, from the design of the mathematical models,
to the implementation and testing of the algorithms on large datasets, to the cre-
ation of an intuitive and user-centered interface for visualizing and communicating
the results.
There are several applications that would benet greatly from a content-based
automated music similarity measure. One major application is query-by-humming
systems which allow users to nd songs by humming them (refer to [Haus &
Pollastri 2001] and [Unal et al. 2005]). An application that could determine the
degree of similarity between a hummed tune and all the pieces in a database would
be a critical component to a query-by-humming system. Another major applica-
tion that would benet from similarity assessment tools is music recommendation
systems [Uitdenbogerd & van Schyndel 2002]. A recommendation system that
could incorporate the similarity between musical content would be a valuable addi-
tion. Music similarity assessment methods may also be used in the organization
of databases where similarity is an intuitive criterion for indexing and classica-
tion [Cli & Freeburn 2000].
The applications of music visualization methods, considered independently of
similarity assessment methods, are more artistic in nature. One possible applica-
tion of music visualization is for use with media player software. Such applications
could present simply aesthetically pleasing imagery. But there is also a potential
to incorporate musically meaningful visualization components. An indirect appli-
cation for music visualizations is for similarity assessment. If a visualization is
successful at showing what a piece of music looks like, then the degree of similarity
may be determined by comparing the visualizations of two pieces.
2
Music Similarity
One of our topics of focus is the assessment of music similarity. Music similarity is
a complex problem; the denition of similarity can be widely divergent and highly
subjective. Music similarity has been viewed from many angles with dierent
assumptions. It is useful to think of similarity as having dierent levels. Consider
the dierent levels outlined in Figure 1. The top of the pyramid represents the
most specic type of similarity while the base represents the most general. The
most specic type of similarity is two exact copies of the same piece. The next level
is dierent renditions of the same piece. An example of this would be two dierent
performances of the same piece. The next level includes pieces from the genre of
theme and variations. The theme is the musical basis upon which a composition
is built. Usually a theme consists of a recognizable melody or a characteristic
rhythmic pattern [Cole 2007]. A variation is a deviation from a theme that uses
the same bass pattern or harmonic progression that the theme used, and usually
having the same number of measures as the theme. Generally, a variation is played
after a theme with the variation being slightly more ornate; in several cases there
are many variations upon a single theme [Cole 2007]. The next level includes
pieces by the same composer. The most general form of similarity is with pieces
from the same genre.
Just as there are dierent levels, the measurement of similarity can be based on
dierent features. Some musical features for assessing similarity include: instru-
mentation, timbre, melody, harmony, rhythm, tempo, mood, lyrics, socio-cultural
backgrounds, structure, and complexity [Pampalk 2006]. Our work focuses on
determining similarity based on tonal features. The methods developed using
these features are successful at determining similarity at the more specic levels
of similarity. In other words, the methods are more successful at the top of the
3
Figure 1: Levels of Music Similarity
pyramid than at the base. Specically, we consider the assessment of similarity at
the top three levels (same piece, dierent renditions of a piece, and variations on
a common piece).
A challenge in music similarity research is the determining of appropriate
ground truth data. Since similarity is subjective and it can take on a variety
of meanings, it is dicult to nd pieces for which there is an agreement about
the degree of similarity. In our work, we have bypassed debates about the true
degree of similarity between pieces through the strategic selection of data sets from
the levels of similarity. We have utilized two unique data sets that have encoded
ground truth. The rst set consists of dierent renditions of the same piece while
the second set consists of pieces from the theme and variations genre. Dierent
renditions of a piece are similar to one another since they are based on the same
underlying musical score. Variations are similar to one another since they were
composed based on the same theme. Since all the variations are similar to the
theme, it follows that they are also similar to one another.
4
Music Visualization
Another topic of focus for us is the development of music visualizations. We strive
to create visualizations that are musically meaningful so that they may also be
used for music analysis and similarity assessment. Music visualization literature
can be broadly grouped into two categories: visualization of individual pieces of
music (our focus), and of collections of pieces. It can be said that the rst form
of music visualization created for individual pieces was music notation itself. An
experienced musician can often look at the score of a piece and see what the
music sounds like. Music notation cannot be used readily as a mainstream form of
visualization because it can take years of training to learn to decipher the subtleties
of the encoded information.
Our goal is to create more intuitive visualizations that reveal important fea-
tures of the music that may not be readily audible to the inexperienced ear. The
challenge with developing such visualizations is that music is complex, consisting
of multiple inter-related features. A successful visualization must strike a balance
between simplicity and comprehensiveness. We aim to create imagery that is both
intuitive and informative. We will present two types of music visualization for
individual pieces. The rst is a dynamic visualization while the second is a static,
aggregate visualization.
Outline
Chapter 2 contains an overview of current music similarity assessment systems.
Chapter 3 develops the methods we have devised for similarity assessment. We
begin this chapter by dening the features we use for similarity assessment: pitch
5
class distributions, key sequences, key distributions, and mean-time-in-key distri-
butions. Next, we introduce four methods of assessment that use the features and
one of the following similarity metrics: L
1
norm, L
2
norm, and sequence alignment.
We conclude the chapter with an example. Chapter 4 contains two sets of experi-
ments we conducted on the similarity assessment methods. Each experiment uses
a dierent data set representing one level of similarity. We test the four methods
of similarity assessment developed in Chapter 3 in each experiment. We provide
statistical analysis of the results including quantile-quantile plots, Kolmogorov-
Smirnov (K-S) tests, and Mann-Whitney (or Wilcoxon) rank sum tests. We also
calculate errors including Type I and Type II errors.
Chapter 5 contains an overview of current music visualization systems. Chapter
6 contains our proposed dynamic music visualization method. We rst introduce
the visualization method and its interface. Next, we demonstrate how this visu-
alization method maintains standards of information design. We then show the
invariance of the visualizations under certain transformations that do not alter our
perception of music. We conclude the chapter by demonstrating the visualization
method using 56 example pieces from two distinct genres. Chapter 7 contains our
proposed static aggregate music visualization that may be used in conjunction with
the dynamic visualization. We rst introduce the visualization method and follow
it with a set of examples that demonstrate how the static aggregate visualizations
provide added information about the tonal content of the music. In Chapter 8 we
summarize our contributions in this work.
6
Chapter 2: Related Work on
Music Similarity Assessment
This chapter reviews a selection of the many music similarity assessment systems
developed so as to put the work presented in Chapters 3 and 4 in perspective and to
illustrate the wide range of approaches that may be utilized in assessing similarity.
Any study of music similarity must rst dene its subject of focus, whether it be
low or high level, melodic or rhythmic, or in linear or vertical time. We present
here some recent work that spans several representative domains of content-based
music similarity. The systems reviewed can be categorized based on their focus:
pitch, time, and timbre. Our work can be loosely categorized as pitch similarity
but diers from other approaches in that several of our methods focus on pitch
structure at a relatively high level, allowing for more general comparisons. Note
that while similarity is strongly tied to the features used for comparison, our main
focus is on comparison. The review presented here will highlight the comparison
methods used.
7
Music Similarity Systems Based on Pitch
Pitch similarity can be further sub-categorized into melody and harmony. Melody
has horizontal structure and can be viewed as a pitch sequence over time while
harmony has a vertical structure and can be viewed as pitch simultaneity in one
time frame.
Melodic Similarity
We rst consider systems developed to assess melodic similarity. These systems
use a melody feature to compare pieces. The melody is often the main focus of
a piece. It is what we often remember about a song. One approach to melodic
similarity assessment is to use sequence matching techniques including: dynamic
programming algorithms for approximate string matching, algorithms associated
with Markov Models and Hidden Markov Models. Sequence matching techniques
are a natural t for melody analysis since melodic contours can be represented
as sequences. Dynamic programming approaches compute an edit distance as a
measure of melodic dissimilarity. Hu, Dannenberg and Lewis [Hu et al. 2002] devel-
oped a dynamic programming method and compared it to a probabilistic method.
The probabilistic method considers the question: What is the probability that a
melody is a mutation of another melody, given a table of mutation probabili-
ties? They presented results from experiments that showed that the probabilistic
method slightly outperforms the dynamic programming method.
Typke et. al. [Typke et al. 2003] developed a model where notes are rep-
resented as weighted points in a two-dimensional (2D) space, with the coordi-
nates of the points reecting the pitch and onset time of notes and the weights
of points depending on the corresponding notes duration and importance. The
8
Earth Movers Distance and the Proportional Transportation Distance were then
be used to measure melodic similarity. The Earth Movers Distance (EMD) mea-
sures a minimum ow for transforming one weighted point set into another. The
Proportional Transportation Distance (PTD) is a modied version of the EMD
that has a distance measure for which the triangle inequality holds. This method
is shown to out-perform an earlier method it is compared to.
Hofmann-Engl [Hofmann-Engl 2001] focused on melodic similarity from a cog-
nitive angle. The problem of similarity is seen as related to the transformation
process involved in mapping two objects onto each other and is approached by
dening a set of transformations (reections and translations). The similarity
value is based on the composition of two specic reections and is dened by a
similarity and interval vector.
Harmonic Similarity
We next consider systems developed to assess harmonic similarity. Pickens and
Crawford [Pickens & Crawford 2002] developed a new harmonic description tech-
nique where information from all the chords (a set of simultaneously sounded
pitches) is used. The rst step in this process is to reduce complex polyphonic
music to a sequence of simultaneities. A chord lexicon is then selected. Finally,
simultaneities are tted to the lexical chords by counting the number of pitches
in common to generate a harmonic description. This description is then combined
with Markov statistical methods to create models of both documents and queries.
Document models are compared to query models and then ranked by score for a
music information retrieval system. This method was evaluated, with favorable
results, using recall-precision graphs.
9
High-Level Pitch Similarity
Work that is most closely related to ours with regards to the domain focus and
methods used is that by Tzanetakis, Ermolinskyi and Cook [Tzanetakis et al.
2003]. Their method created pitch histograms and represented a piece using several
features extracted from the histograms. These representations were evaluated in
the context of genre classication. Genre classication is a problem closely related
to music similarity assessment. Three of our methods (presented in Chapter 3) are
related to this work with one method that uses pitch histograms and two others
that use key histograms. Since each key can be summarized as a pitch distribution,
our methods that use key histograms essentially consider the distribution of pitch
distributions.
In [Mardirossian & Chew 2005a], we introduced the use of key distributions in
measuring similarity, and a sum-of-squared-dierence metric for quantifying sim-
ilarity, and tested it on a limited set of Mozart variations, showing the results in
a self similarity matrix. In [Mardirossian & Chew 2006], we used an L
1
metric for
key distribution similarity assessment, and provided in depth probabilistic and sta-
tistical analyses of the outcomes of this method. We also considered the additional
statistic, the mean-time-in-key distribution, and used the L
2
norm for quantify-
ing similarity for (key distribution, mean-time-in-key distribution) pairs. The test
data set was vastly increased from the one used in [Mardirossian & Chew 2005a],
and contained 711 variations from 71 theme and variations by 10 composers.
Music Similarity Systems Based on Rhythm
Another domain in music similarity research is rhythm, the pattern of propor-
tional durations of notes. Paulus and Klapuri [Paulus & Klapuri 2002] developed
10
a system that measures the similarity of two rhythmic patterns, represented as
acoustic signals. They proposed two methods that constitute the algorithmic core
of the system. This includes a probabilistic musical meter estimation process which
segmentes a continuous musical signal into patterns and another process that per-
formes the actual similarity measurements. Acoustic features were extracted that
model the uctuation of loudness and brightness within the pattern. Dynamic
time warping was then applied to align the patterns to be compared. Simulations
were then run to measure the rhythmic similarity. The results showed that the sys-
tem behaves consistently by assigning high similarity measures to similar musical
rhythms.
Hofmann-Engl [Hofmann-Engl 2002] represented musical durations as chains
based on atomic beats. For example, a melody that consists of quarter, eighth
and sixteenth notes would have the sixteenth as its atomic beat, where all other
durations would be represented as multiples of the sixteenth notes. This form
of representation makes it possible to depict musical durations in a geometric 2D
space. Rhythmic similarity was dened by how much two rhythms deviate in shape
via a transformation mechanism. This type of similarity assessment method has
the following properties: (a) a quarter note and two eighth notes (split ratio 1:1)
are less similar than a quarter note, a dotted eighth note and a sixteenth note
(split ratio 1:3), (b) reversing two sequences produces the same similarity value
as the original sequences (c) longer sequences return higher similarity values, (d)
tempo change eects similarity values, (e) comparison order has no eect, and
(f) complex sequences and simple sequences are less similar. An experiment was
conducted to test this method that produced favorable results.
Chew, Volk and Lee [Chew et al. 2005] used the method of Inner Metric Anal-
ysis (IMA) to compute a rhythmic similarity metric. IMA reveals not only the
11
periodicity patterns in music, but also the accent patterns peculiar to each musi-
cal genre. These accent patterns tend to correspond to perceptual groupings of
the notes. The proposed algorithm uses IMA to map note onset information to an
accent prole that is then compared to template proles generated from rhythm
patterns typical of each genre. The music is classied as being from the genre
whose accent prole is most highly correlated with the sample prole. The algo-
rithm was evaluated using two variants on the model for Inner Metric Analysis
and it was found that that the correct genre is either the top rank choice or a close
second rank choice in almost 80% of the test pieces.
Music Similarity Systems Based on Timbre
We now review music similarity systems that consider timbre. Timbre is the quality
of a musical note or sound that distinguishes dierent types of sound production
or musical instruments. Herre, Allamanche and Ertel [Herre et al. 2003] developed
a system for assessing subjective sound similarity between pairs of musical items
by using a number of signal features. The proposed approach includes stages of
feature extraction, feature processing, clustering, and a classication process. The
novelty of this work comes from the extensive feature extraction and analysis as
well as the use of a large data set.
Aucouturier and Pachet [Aucouturier & Pachet 2002] developed a timbral sim-
ilarity measure based on a Gaussian model of cepstrum coecients. The Gaussian
models are used to match the timbre of dierent songs, which gives a similarity
measure based on the audio content of the music. Such a distance is computed
in two ways: (a) one song is matched to the timbre model of another song by
12
computing the probability of the data given the model and (b) the timbre models
of two songs are compared. These methods are illustrated in several applications.
Discussion
We presented above a subset of related work in the area of music similarity assess-
ment. These methods span the features of similarity: pitch, time, and timbre.
Among all these methods, notice the lack of uniformity in evaluation procedures.
While this is a problem that transcends music similarity, it is nonetheless important
to realize that the results presented here are biased. Although certain measures
have been taken to remedy this problem [Downie 2005], there is still much to be
done. An option would be to have a protocol of evaluation that would be followed
by anyone proposing a new method of similarity assessment.
13
Chapter 3: Quantifying Music
Similarity
As music similarity is a varied and subjective matter, so is the assessment of such
similarity. Similarity can be dened on any number of given features, such as
melody, rhythm, pitch, etc. This chapter describes the features and methods we
have chosen to use in the assessment of music similarity. We have focused on tonal
features. More specically, our work focuses on features that can be obtained from
either pitch or key information. A pitch in music is the property of a [musical
tone] that is determined by the frequency of the waves producing it: highness or
lowness of sound [Merriam-Webster 2007]. The key (a basic element of tonality)
of a piece describes the central tone of the piece [Britannica 2007].
This chapter describes the techniques that will be used to assess music simi-
larity. We will refer to a complete sample of music as a piece. These techniques
can be categorized by the features used for comparison and the similarity metrics
employed (refer to Table 1). All the proposed similarity assessment methods use
one of the following features: pitch class distributions, key sequences, or key distri-
butions and one of the following similarity metrics: L
1
norm, L
2
norm, or sequence
alignment. As shown in Table 1, Method PD uses the pitch class distribution fea-
ture and is based on the L
1
norm, Method KD uses the key distribution feature
14
and is based on the L
1
norm, Method KMD uses the key distribution feature and
is based on the L
2
norm while Method SA uses the key sequence feature and is
based on sequence alignment.
Pitch Class Key Key
Distribution Sequence Distribution
L
1
Norm Method PD Method KD
L
2
Norm Method KMD
Sequence Alignment Method SA
Table 1: Overview of Features and Similarity Metrics Used for Similarity Assess-
ment Methods
As noted above, four methods are presented for the comparisons, all of which
output a distance measure as the degree of dissimilarity between pieces being com-
pared. The rst method (Method PD) takes as input the pitch class distributions
of two pieces and generates a distance measure by calculating the sum of the abso-
lute dierence between the two distributions. The second method (Method SA)
takes as input the sequence of keys for two pieces and uses a sequence alignment
algorithm to generate a distance measure. The third method (Method KD) takes
as input the key distributions of two pieces and generates a distance measure by
calculating the sum of the absolute dierence between the two distributions. The
fourth method (Method KMD) takes as input the key distributions and mean-time-
in-key distributions of two pieces and generates a distance measure by calculating
the Euclidean distance between key and mean-time-in-key pairs.
Pitch Class Distributions Feature
The pitch class distribution feature, to be used for one similarity assessment
method, is a low-level feature that captures information regarding the complexity
of the tonal structure of pieces. A pitch class is the set of all pitches that are
15
a whole number of octaves apart. An octave is an interval whose higher note
has a sound-wave frequency of vibration double that of its lower note [Britannica
2007]. For example, the pitch class C consists of the Cs in all octaves. The bins of
the pitch class distributions are the 12 unique pitch classes: C, C/D, D, D/E,
E, F, F/F, G, G/A, A, A/B, and B. The pitch class distribution values are
normalized and stored in the vector E = {e
1
, e
2
, . . . , e
12
} where e
i
represents the
percentage of time that a note of the pitch class i appears in the piece. We nor-
malize the distributions to sum to one since dierent pieces with varying lengths
will also have a varying total number of pitches.
Segmentation
The rst step in three additional similarity assessment methods is segmenting a
piece. Each piece, say of length n, is segmented into a given number of slices, m, of
uniform length. When comparing pieces of diering lengths, m remains constant
while the length of each segment depends on n. m is constant so that the summary
description of dierent performances of the same piece will be approximately the
same. As will be shown in detail, the choice of m has some eect on the nal
result, but is reasonably stable over a range of m values. If m is very small, then
each slice will be too large to provide reasonable discriminatory information. If m
is very large, then each slice will be too small to produce any meaningful high-level
pitch structure information. The selection of m will be further discussed in later
sections.
16
Key Determination
The three methods requiring segmentation use key based features for similarity
assessment. Therefore, a method of determining key must be utilized. Any key-
nding algorithm may be invoked at this stage (see [Downie 2005] for references to
key-nding algorithms). We have used the Symbolic Key-Finding System (SKeFiS)
which is based on the Spiral Array [Chew 2001] [Chew 2000]. This system takes
as input symbolic data in the form of MIDI (Musical Instrument Digital Interface)
les. MIDI, unlike audio which contains actual audio signals, is comprised of event
messages such as the pitch and intensity of musical notes to play, control signals
for parameters such as volume, vibrato and panning, cues, and clock signals to set
the tempo. While SKeFiS is for use with symbolic input, it has been extended for
use with audio input [Chuan & Chew 2005] [Downie 2005].
This section presents an introduction to the Spiral Array, which SKeFiS is
based on, and then introduces a pitch spelling algorithm that is incorporated into
SKeFiS. Next, the process of key-nding, using the Center of Eect Generator
(CEG) method, is explained. Finally, an evaluation of SKeFiS is presented.
Spiral Array Model
SKeFiS is based on Chews Spiral Array model [Chew 2001] [Chew 2000] for tonal-
ity. The Spiral Array uses a set of nested spirals to represent tonal elements, such
as pitch classes, and keys. The outer most spiral represents pitch classes (shown
in Figure 2) such that adjacent pitches are positioned at each quarter turn of the
spiral. Neighboring pitches along the spiral are a perfect fth apart (approximately
exhibiting a frequency ratio of 2:3). Along the vertical axis, neighboring pitches are
related by major third intervals (approximately a frequency ratio of 4:5). Pitches
17
separated by octaves (ratios of 1:2) are assumed to be equivalent and map to the
same position. Q(t) represents the position on the spiral representing a pitch of
index t. Two parameters, the radius of the cylinder, r, and the height gain per
quarter turn, h, uniquely dene the position of a pitch representation, described
by Equation (1):
Q(t)
def
=
_
_
x
t
y
t
z
t
_
_
=
_
_
r sin
t
2
r cos
t
2
th
_
_
(1)
Figure 2: Pitch Class Representation on the Spiral Array [Chew 2001], [Chew 2000]
(Image used with permission of author)
Because of the Spiral Arrays three-dimensional conguration, other represen-
tations may be dened in the interior of the outer most spiral. Chords, major keys
and minor keys are represented within the interior space of the pitch class spiral.
18
Each of these representations maintains the spiral structure of the pitch class rep-
resentations. This results in a set of nested spirals, with pitch representations on
the outer most spiral and chords and keys on the inner spirals.
Pitch Spelling
In western tonal music several pitches are approximated by the same frequency
(these pitches are said to be enharmonically equivalent). In a MIDI le, enhar-
monically equivalent pitches are represented by the same numerical value. Each
MIDI number corresponds to two or three most probable letter names in the Spiral
Array model. In order to map pitches onto the Spiral Array, MIDI pitch numbers
need to be converted to contextually correct pitch names. Real-time pitch spelling
algorithms using the Spiral Array and various contextual windows have been pro-
posed in [Chew & Chen 2002] and [Chew & Chen 2005]. The method implemented
for this system is the sliding window algorithm detailed in [Chew & Chen 2002].
This method incrementally generates pitch spellings for note events (note by
note) based on tonal contexts derived from a short history window. The history
window is used to generate a center of eect that acts as a proxy for the key. In the
Spiral Array, the convex combination of a given set of pitch positions results in the
center of eect (c.e.) position. The algorithm maps each numeric pitch number to
its plausible pitch names on the Spiral Array, and selects the best match through a
nearest-neighbor search. This pitch spelling algorithm had an error rate of 2.00%
(31 errors out of 1516) in the tonally complex rst movement of Beethovens Sonata
(Op. 109). Most pieces will not shift contexts quite as often or as suddenly as this
piece. For the tonally more stable 3rd movement of the earlier Beethoven Sonata
(Op. 79), the pitch spelling had only an error rate of 0.07% (that is, only one error
out of 1374 notes).
19
CEG Key-Finding Algorithm
Once the correct pitch names are determined for a set of pitch numbers using the
pitch spelling algorithm, any collection of notes (for example, a melody, a cluster
of notes or an entire piece of music) can be mapped to pitch positions in the Spiral
Array. By taking a weighted average of the pitch representations, a c.e. can be
generated to represent the collection of notes. The distance of the c.e. to higher
level tonal entities represented in the Spiral Array reveals the anity of the note
collection to that higher level structure. Each pitch position can be weighted by
factors such as duration, beat-in-bar and time of occurrence to generate the c.e.s
coordinates.
For the CEG key-nding algorithm, each pitch class representation is weighted
by its proportional duration in the segment of music. Suppose there are s
v
notes
(or pitch events) in the time interval (0, v]. The cumulative c.e. of the notes
represented by the (pitch, duration) pairs {(
i
,
i
) : i = 1 . . . s
v
} is dened as
the sum of the pitch positions weighted by their respective durations as shown in
Equation (2):
c.e.
(0,v)
def
=
sv
i=1
i
D
v
i
D
v
=
sv
i=1
i
(2)
Once a c.e. is calculated for a piece, the key may then be determined through a
nearest neighbor search for the nearest key representation on the major and minor
key spirals. This algorithm has been shown to be more ecient and accurate in
identifying the most likely key than existing models for key-nding [Chew 2001].
20
For Bachs fugue subjects in the Well-Tempered Clavier Book I, this method
required on average of 3.75 pitch events to determine the correct key, compared
to 5.25 for Krumhansl & Schmucklers method [Krumhansl 1990] and 8.71 for
Longuet-Higgins & Steedmans method [Longuet-Higgins & Steedman 1971].
SKeFiS Evaluation
Any algorithm that is chosen for key-nding will introduce some error into the
analysis. An evaluation of SKeFiS will put the nal results into perspective by
determining the amount of this error. We will use the method of evaluation that
we proposed for [Downie 2005]. This method is an unbiased and objective way of
assessing the success rate of any key-nding algorithm (both symbolic MIDI and
audio based).
In the evaluation method, the error analysis centers on comparing the key
identied by an algorithm to the actual key of the piece. The key of the piece is
the one dened by the composer in the title of the piece. It is then determined how
close each identied key is to the corresponding correct key. Keys are considered
as close if they have one of the following relationships: distance of perfect fth,
relative major and minor, and parallel major and minor. The relative minor of a
particular major key (or the relative major of a minor key) is the key which has
the same key signature but a dierent tonic [Cole 2007]. The parallel minor of a
particular major key (or the parallel major of a minor key) is the minor key with
the same tonic [Cole 2007]. The tonic is the rst note of a musical scale [Cole 2007].
For example, A Minor is the relative minor of C Major since the key signature for
both keys contains no sharps or ats. C Minor is the parallel minor of C Major
since they are both C. Key assignments are allocated points based on the degree of
closeness between the identied key and the actual key. A correct key assignment
21
is given a full point, and incorrect assignments are allocated fractions of a point
according to Table 2.
Relation to Points
Correct Key
Same 1
Perfect fth 0.5
Relative major/minor 0.3
Parallel major/minor 0.2
Table 2: Points Allocated to Keys Identied with Key-Finding Algorithms
SKeFiS was tested under the above stated evaluation parameters [Mardirossian
& Chew 2005b]. Prior to the evaluation, 30-second segments from the beginning
of 96 MIDI les were provided as a training set. Since key-nding on the Spiral
Array has been shown to require very little information to determine key [Chew
2001], we decided to use only a subset of the 30 seconds of music that was provided.
In order to determine the optimal length, we ran SKeFiS on truncated excerpts
of the sample test les ranging in length from 0.1 through 30 seconds. We then
compared the results against the ground truth to determine the score for each run.
The optimal segment length, having the highest score of 83.13%, was determined
to be for segments that were 27.9, 28.0, and 28.1 seconds long. We chose to use
28.0 second segments.
The evaluation was performed using 1252 MIDI les. Table 3 records the
evaluation results for SKeFiS. The error that this key-nding system introduces
may be attributed to both the pitch spelling and key determination portions. While
we realize that other key-nding systems may introduce less error, we will not focus
on identifying such a system. Finding a better algorithm is a never-ending battle
with an ever-increasing number of possible algorithms and an innite number of
22
Algorithm: SKeFiS Key-Finding
Total Score: 934
Percent Score: 74.6%
Correct Keys: 799
Perfect Fifth Errors: 210
Relative Major/Minor Errors: 80
Parallel Major/Minor Errors: 30
Other Errors: 133
Runtime(s): 471
Machine: OS: CentOS;
Processor: Dual AMD
Opteron 64 1.6Ghz;
RAM: 4GB;
Table 3: Evaluation Results for SKeFiS Key-Finding System
evaluation parameters. While we are aware of the error introduced by the key-
nding system used, it is not our main focus because of the modular nature of our
similarity assessment methods. Since any key-nding algorithm may be plugged
in, we instead focus on the xed components that make up the core of our methods.
Key Distributions Feature
The sequence of keys calculated for the slices is used to generate the key distri-
butions feature. This feature, to be used with two of the similarity assessment
methods, exploits the unique combination of keys within a piece to create a musi-
cal ngerprint. While each musical piece has a main key (referred to in the key
signature) that typically begins and ends the piece, throughout the course of a
piece, the key may uctuate to keys other than the main key. Therefore, two
pieces of music that visit the same distribution of keys can be thought of as being
more similar.
23
The sequence of keys is represented as an m-dimensional vector K =
{k
1
, k
2
, . . . , k
m
}. Each k
i
is the key identied by the key-nding algorithm for
segment i. The bins of the key histograms are the 55 possible major and minor
keys from C to C, shown as a vector of key names, P = {p
1
, p
2
, . . . , p
55
}. P has
55 elements because the Spiral Array does not assume enharmonic equivalence.
The key distribution values are stored in the vector F = {f
1
, f
2
, . . . , f
55
} where f
i
represents the number of times an element of K is equal to the i-th element of P.
Let us consider a simple example. If there were only two possible keys (A and B),
we would have P = {A, B}. Assume that m = 5 and the sequence of key segments
is K = {A, A, B, B, A}. Then F = {3, 2}.
Key progression in music is smooth and continuous with a constant reference to
and dependence on history key information. Our method of segmentation and key
identication assumes an independence of keys. In other words, when the key of a
slice is determined, the key of neighboring slices are not taken into consideration.
This is a disadvantage of the methods that could introduce a certain degree of
error. However, the inclusion of the pitch spelling algorithm may counter these
eects since it imposes some relation among consecutive segments.
Mean-Time-In-Key Distributions Feature
Another feature that will be used for similarity assessment in one of the proposed
methods is the mean-time-in-key distribution. This feature provides further infor-
mation about the tonal stability of a piece. Let O = {o
1
, o
2
, . . . , o
55
} be a vector
such that o
i
is the number of times a continuous sequence of elements correspond-
ing to p
i
occurs in the vector K. The mean-time-in-key distribution is stored in
24
the vector A = {a
1
, a
2
, . . . , a
55
}, where a
i
= f
i
/o
i
. Continuing with the previous
example, O = {2, 1} and A = {1.5, 2}.
Comparing Two Pitch Class Distributions
The rst method (Method PD) proposed for similarity assessment uses the pitch
class distributions, E vectors, of two pieces, and computes a distance between
them. This distance is inversely related to the degree of similarity between the
pieces compared. Therefore, the lower the value, the more similar the pieces are
interpreted as being. If two pieces are exactly the same, Method PD would return
a value of zero for their comparison. Refer to Figure 3 for the system diagram of
this method.
Figure 3: System Diagram for Method PD
Consider two pieces, Piece 1 and Piece 2, with pitch class distributions, E =
{e
1
, e
2
, . . . , e
12
} and E = {e
1
, e
2
, . . . , e
12
} respectively. E and E are treated as
probability mass functions (p.m.f.s), and the distance between them is measured
using the L
1
norm, shown in Equation (3):
12
i=1
|e
i
e
i
| (3)
25
The pitch class distribution feature provides a generalized overview of the pitch
content of a piece. Method PD denes similarity at the most specic level since it
takes into consideration the most low-level feature.
Comparing Two Key Sequences
The second method (Method SA) proposed for similarity assessment takes as
input the sequence of keys of comparison pieces and uses a dynamic program-
ming sequence alignment algorithm to determine a distance value as the degree
of dissimilarity between the pieces. There is an inverse relationship between the
distance value and the degree of similarity between pieces being compared. If
two pieces are exactly the same, Method SA would return a value of zero for
their comparison. Refer to Figure 4 for the system diagram. Recall that K is
the m-dimensional vector that contains the sequence of keys identied for a piece.
Consider two pieces, Piece 1 and Piece 2, with key sequences K = {k
1
, k
2
, . . . , k
m
}
and K = {k
1
, k
2
, . . . , k
m
} respectively. The sequence alignment algorithm deter-
mines a distance value between the two sequences K and K. Method SA denes
similarity at a specic level since it takes into consideration the actual order of
keys in a piece.
Figure 4: System Diagram for Method SA
26
The sequence alignment algorithm we use has been adapted from an algorithm
commonly used in bioinformatics. The methodologies often employed to compare
genes and proteins will be used here to compare sequences of keys. We provide an
overview of the bioinformatics sequence alignment algorithm. In the early 1970s,
molecular biologists Needleman and Wunsch proposed a denition of similarity,
which has become the standard denition, as well as a global alignment algorithm
(Needleman-Wunsch algorithm). Global alignments, which attempt to align every
element in every sequence, are most useful when the sequences being compared are
similar and of roughly equal size [Baxevanis & Ouellette 2001]. For our adaptation
to music similarity, we will focus on global alignments and will use the Needleman-
Wunsch algorithm.
We outline here the Needleman-Wunsch sequence alignment algorithm [Klein-
berg & Tardos 2005]. Suppose we wish to compare two strings X = {x
1
, x
2
, . . . , x
b
}
and Y = {y
1
, y
2
, . . . , y
d
}. The sets {1, 2, . . . , b} and {1, 2, . . . , d} represent the dif-
ferent positions in the strings X and Y. A matching of these sets is a set of ordered
pairs with the property that each item occurs in at most one pair. A matching G
of the two sets is an alignment if there are no crossing pairs: if (i, j), (i
, j
) G
and i < i
, then j < j
. The denition of similarity is based on nding the optimal
alignment between X and Y, according to the following criteria. Suppose G is a
given alignment between X and Y. There is a parameter > 0 that denes a gap
penalty. For each position that is not matched in G (creating a gap) a cost of is
incurred. For each pair of letters e and q in the alphabet, there is mismatch cost
of
eq
for lining up e with q. Note that
ee
= 0. The total cost of G is the sum
of its gap and mismatch costs and the goal is to obtain an alignment of minimum
cost. We observe that in an optimal alignment L (minimum cost), at least one of
the following holds true: (i ) (b, d) L, (ii ) the b
th
position of X is not matched or
27
(iii ) the d
th
position of Y is not matched. It follows that the minimum alignment
costs satisfy the recurrence in Equation (4):
OPT(i, j) = min[
x
i
y
j
+OPT(i1, j1), +OPT(i1, j), +OPT(i, j1)] (4)
The performance of the sequence alignment algorithm is dependent on the val-
ues of
x
i
y
j
and . In the application to music, these costs would need to take on a
range of values since there are degrees of relatedness between keys. The mismatch
cost of more closely related keys should be less than the mismatch cost of unrelated
keys. This same problem is encountered in the application of bioinformatics [Bax-
evanis & Ouellette 2001] where the sensitivity of weak alignments is increased
through the use of substitution matrices. A substitution matrix provides a range
of values for
x
i
y
j
. Since certain amino acids can substitute easily for one another
in related proteins, when calculating alignment scores, identical amino acids are
given greater value than substitutions, and conservative substitutions are given
values greater than non-conservative changes. In other words, a range of values is
developed. The use of substitution matrices is widespread in bioinformatics and a
variety of templates have been developed for use with protein alignment.
Relation
x
i
y
j
Between x
i
and y
j
Same 0
Perfect fth 1
Relative major/minor 2
Parallel major/minor 3
Other 4
Table 4: Mismatch Costs
x
i
y
j
Used for Sequence Alignment Algorithms
28
In this adaptation to music analysis, we have used a similar methodology in
developing a substitution matrix. In an alignment, identical keys or enharmonically
equivalent keys are given a value of zero and keys that are closely related are given
a smaller value than keys that are not related. The actual scoring methods we used
are equivalent to the scoring used in evaluating key nding algorithms (presented in
the SKeFiS Evaluation section). Refer to Table 4 for the actual values assigned
to
x
i
y
j
. Note that we set = 4. We also provided an excerpt of the actual
substitution matrix used in (5).
_
_
_
_
_
_
_
_
_
_
_
_
B F C G ...
B 0 1 4 4 ...
F 1 0 1 4 ...
C 4 1 0 1 ...
G 4 4 1 0 ...
... ... ... ... ... ...
_
_
_
_
_
_
_
_
_
_
_
_
(5)
Comparing Two Key Distributions
The third method (Method KD) proposed for similarity assessment uses the key
distributions, F vectors, of two pieces, and computes a distance between them.
This distance is inversely related to the degree of similarity between the pieces
compared. Therefore, the lower the value, the more similar the pieces are inter-
preted as being. If two pieces are exactly the same, Method KD would return a
value of zero for their comparison. Refer to Figure 5 for the system diagram of
this method.
Consider again two pieces, Piece 1 and Piece 2, with key distributions, F =
{f
1
, f
2
, . . . , f
55
} and F = {f
1
, f
2
, . . . , f
55
} respectively. F and F are treated as
29
Figure 5: System Diagram for Method KD
probability mass functions (p.m.f.s), and the distance between them is measured
using the L
1
norm, shown in Equation (6):
55
i=1
|f
i
f
i
| (6)
The key distribution feature measures the degree of tonal stability in a piece such
that a piece with an F vector containing peaks is more stable than a piece that
has a uniformly distributed F vector. Method KD denes similarity at the most
general level since it only considers general trends and does not takes into account
the order of keys in a piece.
Comparing Pairs of Key and Mean-Time-In-Key
Distribution
The fourth method (Method KMD) proposed for generating a dissimilarity mea-
sure uses both key distributions, represented by vectors F, and mean-time-in-key
distributions, represented by vectors A. It calculates the distance between pairs
of values of F and A as the measure of dissimilarity. As with the other methods,
Method KMD also has an inverse relationship between the value of the distance
30
measure and the degree of similarity between the pieces compared. Refer to Fig-
ure 6 for the system diagram of this method.
Figure 6: System Diagram for Method KMD
Consider again two pieces, Piece 1 and Piece 2, and let A = {a
1
, a
2
, . . . , a
55
}
and A = {a
1
, a
2
, . . . , a
55
} be the respective mean-time-in-key distributions for
the two pieces. This method uses the sum of the Euclidean distance between two
(F, A) pairs as the measure of similarity and is based on the L
2
norm, shown in
Equation (7):
55
i=1
_
(f
i
f
i
)
2
+ (a
i
a
i
)
2
(7)
The added feature of the mean-time-in-key gives further information about the
stability of a piece. For an F with peaks, consider its corresponding A vector. If
the values of A corresponding to the peaks of F are large, then the piece is more
stable than if these values were small. Method KMD denes similarity at a mid
level. It considers the general trends by including the key distributions feature,
31
but also takes into account some sequential information with the mean-time-in-key
distributions feature.
Example
Let us consider an example to illustrate Methods PD, SA, KD and KMD. Three
pieces are used for this example: Piece A is the theme section from Beethovens
La Molinara, Piece B is the third variation of the same piece, and Piece C is
the second variation of Schumanns Symphonische Et uden. These pieces, in MIDI
format, were obtained from [Schwob 2007]. Since Piece B is a variation of Piece A,
they are more similar than Pieces A and C, and Pieces B and C. Note that m = 15
for Methods SA, KD, and KMD.
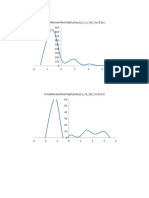
For an illustration of Method PD, consider the plots of E shown in Figure 7.
The assumption that Pieces A and B are similar while Pieces A and C, and Pieces
B and C are dierent is supported by an inspection of these plots. Using Method
PD yields a distance value of 0.18 for Pieces A and B, 1.07 for Pieces A and C, and
1.03 for Pieces B and C. Refer to (8) for the detailed matrix of the results. These
results further verify that Pieces A and B are similar while Piece C is dierent.
_
_
_
_
_
PieceA PieceB PieceC
PieceA 0.00 0.18 1.07
PieceB 0.18 0.00 1.03
PieceC 1.07 1.03 0.00
_
_
_
_
_
(8)
For an illustration of Method SA, consider the actual sequences of keys identi-
ed for each piece shown in Table 5. The values selected for the gap penalty as
well as the individual mismatch costs
x
i
y
j
are as outlined in the previous section
32
Figure 7: Plot of vector E for example Pieces A, B, and C
Piece A: {e, G, G, D, C, G, e, a, G, A, D, D, G, G, G}
Piece B: {G, G, d, e, G, G, c, a, G, e, G, b, G, G, G}
Piece C: {f, D, d, d, F, F, d, d, F, g, c, F, F, F, F}
Table 5: Sequences of Keys Identied for Example Pieces A, B and C
with = 4 and
x
i
y
j
ranging from 0 to 4. Using Method SA yields a distance value
of 22 for Pieces A and B, 58 for Pieces A and C, and 56 for Pieces B and C. Refer
to (9) for the detailed matrix of the results. These results illustrate that Method
SA is successful in determining that Pieces A and B are more similar than Pieces
A and C or Pieces B and C.
_
_
_
_
_
PieceA PieceB PieceC
PieceA 0 22 58
PieceB 22 0 56
PieceC 58 56 0
_
_
_
_
_
(9)
Consider the plots of F shown in Figure 8. The assumption that Pieces A and
B are similar while Pieces A and C, and Pieces B and C are dierent is supported
by direct inspection of these plots. Using Method KD yields a distance value of 10
for Pieces A and B, 30 for Pieces A and C, and 30 for Pieces B and C. Refer to (10)
33
Figure 8: Plot of vector F for example Pieces A, B, and C
for the detailed matrix of the results. These results further verify that Pieces A
and B are similar while Piece C is dierent.
_
_
_
_
_
PieceA PieceB PieceC
PieceA 0 10 30
PieceB 10 0 30
PieceC 30 30 0
_
_
_
_
_
(10)
Figure 9: Plot of vector A for example Pieces A, B, and C
34
The plots of A are shown in Figure 9. Notice that, as with the plots of F, the
plot for Piece C is signicantly dierent from the plots for Pieces A and B. Using
Method KMD (which considers both vectors F and A), yields a distance value of
12.43 for Pieces A and B, 34.55 for Pieces A and C, and 34.57 for Pieces B and C.
Refer to (11) for the detailed matrix of the results. These ndings further support
the initial assumptions and conrm that Pieces A and B are similar while Piece C
is dierent.
_
_
_
_
_
PieceA PieceB PieceC
PieceA 0 12.43 34.55
PieceB 12.43 0 34.57
PieceC 34.55 34.57 0
_
_
_
_
_
(11)
The methods developed in this chapter will be used in the following chapter
to conduct two sets of experiments. Each experiment uses a dierent data set
representing one of the levels of similarity. We will show how all the methods
perform at each level of similarity and how the success rate of each method increases
as the denition of similarity becomes more specic.
35
Chapter 4: Similarity
Experiments
This chapter presents two experiments that use Methods PD, SA, KD and KMD
(developed in Chapter 3). Each experiment uses a dierent data set. Recall the
levels of similarity presented in Figure 1. These experiments will analyze the
top three levels: same piece, same piece but dierent renditions, and theme and
variations. We will show how well Methods PD, SA, KD and KMD perform at
each level and how the success rate of each method increases as the denition
of similarity becomes more specic. Note that we will not conduct a specic
experiment on the rst level of similarity (same piece). This level provides a trivial
problem. Any method of similarity assessment should return perfect results when
comparing exact copies of the same piece. Instead, like the work in [Pickens 2004],
we will include the comparison of pieces to themselves in the experiments of the
two other levels since this will provide a good check of our system and methods.
The levels of similarity from Figure 1 may be divided into two distinct groups.
The rst group includes the three levels outlined above while the second group
includes the two more general levels of similarity (pieces by the same composer
and pieces from the same genre). We will show that the methods presented here
36
may be used for the comparison of pieces from the rst group while other methods
will need to be utilized for the comparison of pieces from the second group.
The rst experiment, presented in the Experiment: Dierent Renditions of a
Piece section, uses a data set of renditions while the second experiment, presented
in the Experiment: Theme and Variations section, uses a data set of variations.
For each experiment, all four methods of similarity assessment were used to com-
pare all pieces in the data set to one another. The results were split into two groups.
Group S contains all the distance values obtained from comparing similar pieces
while Group D contains all the distance values obtained from comparing dierent
pieces. In the rst experiment, pieces are dened as similar if they are renditions
of the same piece and dierent if they are not. In the second experiment, pieces
are dened ad similar if they are variations of the same piece and dierent if
they are not.
For each experiment and method, we conducted extensive statistical analysis
to compare Groups S and D. First, we constructed empirical quantile-quantile
plots [Chambers et al. 1983] which consists of plotting the quantiles of one empirical
distribution against the corresponding one in the other. If the two distributions are
identical, then all the points on the plot would lie on the line x = y. Departures
from this line indicate a dierence in the distributions. Next, we conducted a
Kolmogorov-Smirnov (K-S) test [Conover 1980] to compare the distributions of
the two groups. The null hypothesis, H
0
, for this test is that the two groups come
from the same underlying continuous distribution. If we can reject H
0
, then we
can state that Groups S and D come from dierent underlying distributions. We
then conducted a Mann-Whitney (or Wilcoxon) rank sum test [Conover 1980] to
determine whether the data in the two groups are from dierent populations. The
37
null hypothesis, H
0
, is that the two groups come from distributions with equal
medians.
For the remainder of the analysis, we assigned a cuto point for determining
if two pieces can be considered similar. If the value of a comparison is less than
this cuto point, we concluded that the pieces were similar. If it was greater
than or equal to the cuto point, we conclude that the pieces were dierent.
Since Groups S and D overlap, this categorization scheme will introduce a certain
amount of error. We computed these errors: Type I errors refer to the probability
of a comparison from Group D returning a value less than the cuto point and Type
II errors refer to the probability of a comparison from Group S returning a value
greater than or equal to the cuto point. We calculated further probabilities by
answering the following questions: if we pick a comparison at random, and its value
is less than the cuto point, what is the probability that this comparison comes
from Group S? Also, if we pick a comparison at random, and its value is greater
than or equal to the cuto point, what is the probability that this comparison does
not come from Group S?
The above outlined analysis helps to understand the nature and performance
of all the methods. We will use these ndings to draw conclusions about the
methods and data sets by comparing the performance of each method according
to the dierent metrics used.
Experiment: Dierent Renditions of a Piece
The experiment in this section considers the second level of similarity which con-
tains dierent renditions of a piece. Recall that a rendition of a piece is any other
piece that presents the original piece in slightly altered form. This includes, but
38
is not limited to, dierent performances, use of instrumentation, and expressive
performance of the same piece. We assume that dierent renditions of a piece
are similar one to another. We can make this assumption since all renditions of
a piece are derived from the same underlying score. Note that the converse may
not necessarily be true. Even though we expect dierent pieces (not renditions) to
be less similar than renditions of the same piece, we cannot assume that they will
not be similar. We will refer to the set of renditions of one particular piece as a
Rendition Set.
We have amassed a collection of Rendition Sets from [Schwob 2007] spanning
ten composers and periods ranging from Baroque and Classical, to Romantic.
Table 6 summarizes the statistics on the data set used for this experiment.
Composer No. of No. of Avg. Piece
Rendition Sets Pieces Length (min:sec)
Bach 18 55 07:36
Beethoven 36 208 07:29
Brahms 17 58 09:00
Chopin 14 71 03:13
Handel 4 16 04:32
Haydn 20 54 04:37
Liszt 7 27 08:24
Mozart 28 79 07:42
Schubert 9 34 04:29
Vivaldi 19 60 03:59
TOTAL 172 662 06:28
1
Table 6: Summary of Pieces in the Data Set Used for the Experiment with Dierent
Renditions of a Piece
Methods PD, SA, KD and KMD were used in this experiment to compare all 662
renditions in the data set to one another. Repeated comparisons were discarded.
For each method, we divided these comparisons into two groups. Group S contains
1
Average piece length over all pieces.
39
all comparisons of pieces from the same Rendition Set while Group D contains all
comparisons of pieces from dierent Rendition Sets.
Analysis of Results for Method PD
We compared the pieces in the data set using Method PD and split the results
into Groups S and D. Since we assume, for the purposes of this experiment, that
renditions of pieces are similar one to another while non-renditions are not, we
would expect that the distribution of Group S would dier from the distribution
of Groups D. We constructed an empirical quantile-quantile plot [Chambers et al.
1983] shown in Figure 10. It is clear from Figure 10 that Group S does not come
from the same underlying distribution as Groups D since the plot is not close to
the line x = y. This observation supports our initial assumptions and veries
that Method PD is successful at distinguishing between pieces from the same and
dierent Rendition Sets.
Figure 10: Quantile-Quantile Plot Comparing Groups S and D of Rendition Sets
Data Using Method PD
We conducted a K-S test [Conover 1980] to compare the distributions of the
two groups. The null hypothesis, H
0
, for this test is that the two groups come
40
from the same underlying continuous distribution. The test yielded a K-S statistic
value of 0.9678 and a p value of 0.0000. We can thus reject the null hypothesis H
0
and verify that the distribution of Group S is indeed signicantly dierent from
the distribution of Groups D.
We next conducted a Mann-Whitney rank sum test [Conover 1980] to deter-
mine whether the data in the two groups are from dierent populations. The null
hypothesis, H
0
, is that the two groups come from distributions with equal medians.
This test yields a rank sum statistic of 4.7973 10
6
and a p value of 0.0000. We
can reject H
0
and conclude that the medians of Group S and Group D are not
equal. The implication of these results is that pieces from the same Rendition Sets
are similar while pieces from dierent Rendition Sets are dierent. Furthermore,
Method PD is successful at identifying these similarities.
Figure 11: Distributions of Distance Measure, Obtained Using Method PD,
Divided into Groups S and D for Rendition Sets Data
The distributions of Groups S and D are shown in Figure 11. Note that since
the number of comparisons in each group diers greatly, we normalized the results
so that the distributions sum to one. By inspection, we can see that the plot for
Group S is signicantly dierent from that for Groups D. Next, we performed some
probabilistic analyses of classication errors should Method PD be used for music
41
categorization. Recall that Method PD returns a single value for every comparison
made between two pieces. If two pieces are exactly the same, this value is equal
to zero. As the degree of dierence between the pieces increases, so does this
measure. In a rudimentary categorization scheme, we could select a cuto point
for determining if two pieces can be considered renditions of the same piece. If the
value is less than this cuto point, we conclude that the pieces are from the same
Rendition Set and similar. If it is greater than or equal to the cuto point, we
conclude that the pieces are from dierent Rendition Sets and dissimilar.
The cuto point is set to 0.2 which is the point at which the outlines of the
two distributions cross in Figure 11. This point was also selected to minimize the
sum of Type I and II errors. Let
A = Two pieces are from the same Rendition Set, and
B = Their distance value is less than 0.2.
Next we computed Type I (false positive) and Type II (false negative) probabilities
for Method PD. The probability of a Type I error, P(B|A
) = 1.02% while the
probability of a Type II error is P(B
|A) = 2.29%. These computed error rates
are both rather low.
Now, consider the question: if we pick a data point at random, and its value
is less than 0.2, what is the probability that this data point belongs to Group S?
We can state the answer as P(A|B). Also consider the converse of this question:
if we pick a data point at random, and its value is greater than or equal to 0.2,
what is the probability that this data point does not belong to Group S? This
answer can be stated as P(A
|B
). We calculated that P(A|B) = 45.29% and
P(A
|B
) = 99.98%. These values are skewed (lower P(A|B) and higher P(A
|B
))
since Groups D has far more data points than Group S. Thus, a randomly selected
data point is much more likely to be from Group D than Group S.
42
Analysis of Results for Method SA
Using Method SA, we compared the pieces in the data set and split the results into
Groups S and D. Note that we selected the segmentation parameter m to equal
87 since this is the point that minimizes the sum of Type I and Type II errors.
This selection will be discussed in detail in the Segmentation Parameter Selection
section. Since we assume, for the purposes of this experiment, that renditions of
pieces are similar one to another while non-renditions are not, we would expect
that the distribution of Group S would dier from the distribution of Groups D.
We constructed an empirical quantile-quantile plot [Chambers et al. 1983] shown
in Figure 12. It is clear from Figure 12 that Group S does not come from the same
underlying distribution as Groups D since the plot is not close to the line x = y.
This observation supports our initial assumptions and veries that Method SA is
successful at distinguishing between pieces from the same and dierent Rendition
Sets.
Figure 12: Quantile-Quantile Plot Comparing Groups S and D of Rendition Sets
Data Using Method SA
We conducted a K-S test [Conover 1980] to compare the distributions of the
two groups. The null hypothesis, H
0
, for this test is that the two groups come
43
from the same underlying continuous distribution. The test yielded a K-S statistic
value of 0.8379 and a p value of 0.0000. We can thus reject the null hypothesis H
0
and verify that the distribution of Group S is indeed signicantly dierent from
the distribution of Groups D.
We next conducted a Mann-Whitney rank sum test [Conover 1980] to deter-
mine whether the data in the two groups are from dierent populations. The null
hypothesis, H
0
, is that the two groups come from distributions with equal medians.
This test yields a rank sum statistic of 1.5484 10
7
and a p value of 0.0000. We
can reject H
0
and conclude that the medians of Group S and Group D are not
equal. The implication of these results is that pieces from the same Rendition Sets
are similar while pieces from dierent Rendition Sets are dierent. Furthermore,
Method SA is successful at identifying these similarities.
Figure 13: Distributions of Distance Measure, Obtained Using Method SA, Divided
into Groups S and D for Rendition Sets Data
The distributions of Groups S and D are shown in Figure 13. Note that since
the number of comparisons in each group diers greatly, we normalized the results
so that the distributions sum to one. By inspection, we can see that the plot for
Group S is signicantly dierent from that for Groups D. Next, we performed some
probabilistic analyses of classication errors should Method SA be used for music
44
categorization. Recall that Method SA returns a single value for every comparison
made between two pieces. If two pieces are exactly the same, this value is equal
to zero. As the degree of dierence between the pieces increases, so does this
measure. We, once again, select a cuto point for determining if two pieces can be
considered renditions of the same piece. Recall, if the value is less than this cuto
point, we conclude that the pieces are from the same Rendition Set and similar.
If it is greater than or equal to the cuto point, we conclude that the pieces are
from dierent Rendition Sets and dissimilar.
The cuto point is set to 184 which is the point at which the outlines of the
two distributions cross in Figure 13. This point was also selected to minimize the
sum of Type I and II errors. Let
A = Two pieces are from the same Rendition Set, and
B = Their distance value is less than 184.
Next we computed Type I (false positive) and Type II (false negative) probabilities
for Method SA. The probability of a Type I error, P(B|A
) = 3.97% while the
probability of a Type II error is P(B
|A) = 12.24%. These computed error rates
are promising with a rather low Type I error rate and a slightly higher Type II
error rate.
Now, consider the question: if we pick a data point at random, and its value is
less than 184, what is the probability that this data point belongs to Group S? We
can state the answer as P(A|B). Also consider the converse of this question: if we
pick a data point at random, and its value is greater than or equal to 184, what is
the probability that this data point does not belong to Group S? This answer can be
stated as P(A
|B
). We calculated that P(A|B) = 16.04% and P(A
|B
) = 99.89%.
These values are skewed (very low P(A|B) and very high P(A
|B
)) since Groups
45
D has far more data points than Group S. Thus, a randomly selected data point
is much more likely to be from Group D than Group S.
Analysis of Results for Method KD
We next compared the pieces in the data set using Method KD and again split
the results into Groups S and D. This section analyzes the distributions of the two
groups of results for Method KD. For this method, the segmentation parameter m
is set to 15 since this is the point that minimizes the sum of Type I and Type II
errors. This selection will be discussed in detail in the Segmentation Parameter
Selection section. As with Method SA, we expect the distribution of Group S
to dier from the distribution of Groups D for Method KD. Refer to Figure 14
for the empirical quantile-quantile plot [Chambers et al. 1983] for Method KD. It
is clear from Figure 14 that Group S does not come from the same underlying
distribution as Groups D. This observation supports our initial assumptions and
veries that Method KD is successful at distinguishing between pieces from the
same and dierent Rendition Sets.
Figure 14: Quantile-Quantile Plot Comparing Groups S and D of Rendition Sets
Data Using Method KD
46
We conducted a K-S test [Conover 1980] for Method KD to compare the dis-
tributions of the two groups. Recall that the null hypothesis, H
0
, for this test is
that the two groups come from the same underlying continuous distribution. The
test yielded a K-S statistic value of 0.8005 and a p value of 0.0000. We can thus
reject the null hypothesis H
0
and verify that the distribution of Group S is indeed
signicantly dierent from the distribution of Group D.
We next conducted a Mann-Whitney rank sum test [Conover 1980] for Method
KD to determine whether the data in the two groups is from dierent populations.
Recall that the null hypothesis, H
0
, is that the two groups come from distributions
with equal medians. This test yields a rank sum statistic of 2.5073 10
7
and a
p value of 0.0000. We can reject H
0
and conclude that the medians of Group S
and Group D are not equal. The implication of these results is that pieces from
the same Rendition Sets are similar while pieces from dierent Rendition Sets are
dierent and that Method KD is successful at identifying these similarities.
Figure 15: Distributions of Distance Measure, Obtained Using Method KD,
Divided into Groups S and D for Rendition Sets Data
The distributions of Groups S and D are shown in Figure 15. The results
were normalized for these distributions since the number of elements in Group D
greatly outweighs those in Group S. Notice that an inspection of the plots veries
47
that Group S is signicantly dierent from that for Groups D. We also performed
probabilistic analyses of classication errors for Method KD. Method KD returns
a single value for every comparison made between two pieces. If two pieces are
exactly the same, this value is equal to zero. As the degree of dierence between the
pieces increases, so does this measure. Once again, we selected a cuto point for
determining if two pieces can be considered renditions of the same piece. Recall
that if the value is less than this cuto point, we conclude that the pieces are
similar. If it is greater than or equal to the cuto point, we conclude that the
pieces are dissimilar.
In this case, the cuto point is set to 16 which is the point at which the outlines
of the two distributions cross as well as the point at which the sum of Type I and
II errors is minimized. Now let
A = Two pieces are from the same Rendition Set, and
B = Their distance value is less than 16.
The probability of a Type I error, P(B|A
) = 4.73% while the probability of a
Type II error is P(B
|A) = 15.22%. Method KD yields a lower Type I error rate
and a slightly higher Type II error rate.
We next consider the question: if we pick a data point at random, and its value
is less than 16, what is the probability that this data point belongs to Group S?
We can state the answer as P(A|B). Also consider the converse of this question:
if we pick a data point at random, and its value is greater than or equal to 16,
what is the probability that this data point does not belong to Group S? This
answer can be stated as P(A
|B
). We calculated that P(A|B) = 13.40% while
P(A
|B
) = 99.86%. These values are skewed in the same manner as the previous
methods since our data set has not changed and therefore, a randomly selected
data point is more likely to be from Group D than Group S.
48
Analysis of Results for Method KMD
We next compared the Rendition Sets data using Method KMD and split the
results into Groups S and D. This section analyzes the distributions of the two
groups of results for Method KMD. For this method, the segmentation parameter
m is set to 9 since this is the point that minimizes the sum of Type I and Type II
errors. This selection will be discussed in detail in the Segmentation Parameter
Selection section. As with the other methods, we expect the distribution of Group
S to dier from the distribution of Groups D for Method KMD. Refer to Figure 16
for the empirical quantile-quantile plot [Chambers et al. 1983] for Method KMD. It
is clear from Figure 16 that Group S and Group D come from dierent underlying
distributions. This observation supports our initial assumptions and veries that
Method KMD is successful at distinguishing between pieces from the same and
dierent Rendition Sets.
Figure 16: Quantile-Quantile Plot Comparing Groups S and D of Rendition Sets
Data Using Method KMD
We conducted a K-S test [Conover 1980] for Method KMD to compare the
distributions of the two groups. Recall that the null hypothesis, H
0
, for this test
is that the two groups come from the same underlying continuous distribution.
49
The test yielded a K-S statistic value of 0.7917 and a p value of 0.0000. We can
therefore reject the null hypothesis H
0
and verify that the distribution of Group S
is indeed signicantly dierent from the distribution of Groups D.
We next conducted a Mann-Whitney rank sum test [Conover 1980] for Method
KMD to determine whether the data in the two groups is from dierent popula-
tions. Recall that the null hypothesis, H
0
, is that Groups S and D come from dis-
tributions with equal medians. This test yields a rank sum statistic of 2.877810
7
and a p value of 0.0000. We can reject H
0
and conclude that the medians of Group
S and Group D are not equal. The implication of these results is that pieces from
the same Rendition Sets are similar while pieces from dierent Rendition Sets are
dierent and that Method KMD is successful at identifying these similarities.
Figure 17: Distributions of Distance Measure, Obtained Using Method KMD,
Divided into Groups S and D for Rendition Sets Data
The normalized distributions of Groups S and D are shown in Figure 17. These
distributions are similar to those of the other methods in that the distribution
of Group S is signicantly dierent from that for Groups D. We also performed
probabilistic analyses of classication errors for Method KMD. Method KMD also
returns a single value, representing the degree of dierence, for every comparison
made between two pieces. We used the same methodology as with the analysis
50
of results for the other methods and selected a cuto point for determining if two
pieces can be considered renditions of the same piece. Recall that if the value is
less than this cuto point, we conclude that the pieces are similar. If it is greater
than or equal to the cuto point, we conclude that the pieces are dissimilar.
In this case, the cuto point is set to 13 which is the point at which the outlines
of the two distributions cross as well as the point at which the sum of Type I and
II errors is minimized. Now let
A = Two pieces are from the same Rendition Set, and
B = Their distance value is less than 13.
The probability of a Type I error, P(B|A
) = 6.59% while the probability of a
Type II error is P(B
|A) = 14.37%. Method KMD yields a lower Type I error rate
and a slightly higher Type II error rate.
We next consider the question: if we pick a data point at random, and its value
is less than 13, what is the probability that this data point belongs to Group S
(P(A|B))? We also consider the converse of this question: if we pick a data point
at random, and its value is greater than or equal to 13, what is the probability
that this data point does not belong to Group S (P(A
|B
))? We calculated that
P(A|B) = 10.09% while P(A
|B
) = 99.87%. These values are skewed in the same
manner as they were with the other methods since a randomly selected data point
is more likely to be from Group D than Group S.
Segmentation Parameter Selection
For Methods SA, KD and KMD, we performed some analysis to determine the
optimal value for the segmentation parameter m. We dened optimality as the
minimization of the sum of Type I and Type II errors. While other cases would
51
require either Type I or Type II errors to have more weight, we have treated the
two types of errors as being equal and have thus selected to minimize the sum as
opposed to one particular error type.
Figure 18: Plot of Type I, Type II and Total Errors for Method SA of Rendition
Sets Data
Figure 19: Plot of Type I, Type II and Total Errors for Method KD of Rendition
Sets Data
We have tested Methods SA, KD, and KMD with a segmentation parameter
value set in the range of 3 to 99. Our smallest value for m is set to 3 in order
to capture the natural structure of most western classical pieces which begin in
a certain key, travel to other keys, and nally return to the original key. We
subsequently set the value of m to all multiples of 3 less than 100. We stopped
52
Figure 20: Plot of Type I, Type II and Total Errors for Method KMD of Rendition
Sets Data
at m = 99 since there was a general trend of the sum of the Type I and II errors
increasing or remaining constant. Refer to Figures 18, 19 and 20 for the plots of
the errors for Methods SA, KD, and KMD respectively.
For the analysis presented in the previous sections, we selected m to equal the
value corresponding to the minimum value of the sum of the errors. As outlined
in Table 7, we set m = 87 for Method SA, m = 15 for Method KD and m = 9
for Method KMD. An inspection of Figures 18, 19 and 20 veries that these are
in fact the segmentation values that result in the lowest sum of the errors. It is
important to note that this analysis also reveals the exibility of our methods.
This is evident in the fact that the range of errors for the dierent values of m is
rather narrow. Even though we have selected the most optimal values for m, other
values will have similar results. This parameter insensitivity will allow a user of
these methods to spend less time in selecting a value for m.
Interestingly, as shown in Table 7, the optimal segmentation size for Method
SA is much larger than for the other methods. This could be due to the fact that,
on the levels of similarity, renditions exhibit a high degree of similarity. Because
of this, Method SA, which assesses similarity dierently from Methods KD and
53
Method Segmentation Value
Method SA 87
Method KD 15
Method KMD 9
Table 7: Segmentation Value for Methods SA, KD and KMD Using the Renditions
Data
KMD, requires longer and more detailed sequences of data to perform optimally.
However, this observation must be paired with the observation that the total error
is stable across m values. Therefore, even though the absolute optimal size for m
might be 87 for Method SA, there are other sizes of m, closer to the values of m
for the other methods, that produce comparable results. For example, Method SA
produces a Type I error of 4.90%, a Type II error of 12.72% and a Total error of
17.62% for m = 24. The value for the Total error is quite close to that of the Total
error with m = 87 (16.21%).
Results Overview
This section outlines the results for this experiment. The experiment was con-
ducted on a set of Rendition Sets data. We compared all the pieces in the data set
using all four similarity assessment methods (Methods PD, SA, KD and KMD).
Our results were split into Groups S and D. Group S consists of the results for
pieces from the same Rendition Sets while Group D consists of the results for
pieces from dierent Rendition Sets. For all four methods, quantile-quantile and
K-S tests conrmed that Group S and D do not come from the same underlying
distribution. Mann-Whitney rank sum tests revealed that Group S comes from a
dierent population than Group D. We used a cuto categorization method and
calculated Type I and Type II errors as outlined in Table 8. For each method, we
also calculated the probability that a randomly selected comparison with a value
54
less than the cuto belongs to Group S (P(A|B)). We also calculated the converse
probability that a randomly selected comparison with a value greater than or equal
to the cuto belongs to Group D (P(A
|B
)). These probabilities are summarized
in Table 9.
Method Type I Error Type II Error
Method PD 1.02% 2.29%
Method SA 3.97% 12.24%
Method KD 4.73% 15.22%
Method KMD 6.59% 14.37%
Table 8: Type I and Type II Errors for Methods PD, SA, KD and KMD Using the
Renditions Data
Method P(A|B) P(A
|B
)
Method PD 45.29% 99.98%
Method SA 16.04% 99.89%
Method KD 13.40% 99.86%
Method KMD 10.09% 99.87%
Table 9: Probabilities for Methods PD, SA, KD and KMD Using the Renditions
Data
Experiment: Theme and Variations
The experiment in this section deals with the third level of similarity which con-
tains pieces that are variations on a theme. Recall that the theme and variations
genre consists of music where an initial melody, the theme, is rst presented in
an introductory section; it is then altered as variations to the original theme in
subsequent sections. We assume that dierent variations of a piece are similar to
one another by relying on the composers judgment since variations were composed
to have commonalities with the theme (and by default, with one another). Note
that the converse may not be true. Even though we expect dierent pieces to be
55
less similar than variations of a piece, we cannot assume that they will not be
similar. We will refer to each set of theme and variations as the Variation Set.
We have amassed a collection of Variation Sets from [Schwob 2007] spanning ten
composers and periods ranging from Baroque and Classical, to Romantic. Table 10
summarizes the statistics on the data set used for this experiment.
Composer No. of No. of Avg. Piece
Variation Sets Pieces Length (min:sec)
Bach 3 48 01:48
Beethoven 20 205 00:51
Brahms 8 128 00:57
Chopin 4 21 00:57
Handel 5 40 00:32
Haydn 12 93 00:53
Liszt 3 22 00:37
Mozart 10 99 01:01
Schubert 4 34 01:10
Schumann 2 21 01:27
Table 10: Summary of Pieces in the Data Set Used for the Experiment with Theme
and Variations
We used Methods PD, SA, KD, and KMD to compare all the pieces in this data
set to one another. We compared all 711 pieces to one another, discarding repeated
comparisons. We divided the comparisons into two groups for each method, as we
did with the previous experiment. Group S contains all comparisons of pieces
from the same Variation Set while Group D contains all comparisons of pieces
from dierent Variation Sets.
Analysis of Results for Method PD
We compared the pieces in the data set using Method PD and split the results into
Groups S and D. We will analyze the distributions of these two groups of results.
Since we concluded that variations of a theme are similar to one another while
56
non-variations are not, we would expect that the distribution of Group S would
dier from the distribution of Groups D. We constructed an empirical quantile-
quantile plot [Chambers et al. 1983] shown in Figure 21. It is clear from Figure 21
that Group S does not come from the same underlying distribution as Groups D
since the plot is not close to the line x = y. This observation supports our initial
assumptions and veries that Method PD is successful at distinguishing between
pieces from the same and dierent Variation Sets.
Figure 21: Quantile-Quantile Plot Comparing Groups S and D of Variation Sets
Data Using Method PD
We conducted a K-S test [Conover 1980] to compare the distributions of the
two groups. Recall that the null hypothesis, H
0
, for this test is that the two groups
come from the same underlying continuous distribution. The test yielded a K-S
statistic value of 0.6534 and a p value of 0.0000. We can thus reject the null
hypothesis H
0
and verify that the distribution of Group S is signicantly dierent
from the distribution of Group D.
We next conducted a Mann-Whitney rank sum test [Conover 1980] to determine
whether the data in the two groups is from dierent populations. Recall the null
hypothesis, H
0
, is that the two groups come from distributions with equal medians.
57
This test yields a rank sum statistic of 1.1689 10
8
and a p value of 0.0000. We
can reject H
0
and conclude that the medians of Group S and Group D are not
equal. The implication of these results is that pieces from the same Variation Sets
are similar while pieces from dierent Variation Sets are dierent. Furthermore,
Method PD is successful at identifying these similarities.
Figure 22: Distributions of Distance Measure, Obtained Using Method PD,
Divided into Groups S and D for Variation Sets Data
The distributions of Groups S and D are shown in Figure 22. We normalized
the results so that the distributions sum to one. Notice that the plot for Group S
is signicantly dierent from that for Groups D. Next, we performed probabilistic
analyses of classication errors as we did with the previous experiment. Recall
that Method PD returns a single value for every comparison made between two
pieces. If two pieces are exactly the same, this value is equal to zero and as the
degree of dierence between the pieces increases, so does this measure. We again
select a cuto point for determining if two pieces can be considered variations of
the same piece. If the value is less than this cuto point, we conclude that the
pieces are similar. If it is greater than or equal to the cuto point, we conclude
that the pieces are dissimilar.
58
The cuto point is set to 0.6 which is the point at which the outlines of the
two distributions cross in Figure 22 and the point that minimizes the sum of Type
I and II errors. Let
A = Two pieces are from the same Variation Set, and
B = Their distance value is less than 0.6.
Next we computed Type I and Type II probabilities for Method PD. The proba-
bility of a Type I error, P(B|A
) = 20.32% while the probability of a Type II error
is P(B
|A) = 15.68%.
Now, consider the question: if we pick a data point at random, and its value is
less than 0.6, what is the probability that this data point belongs to Group S? We
can state the answer as P(A|B). Also consider the converse of this question: if we
pick a data point at random, and its value is greater than or equal to 0.6, what is
the probability that this data point does not belong to Group S? This answer can be
stated as P(A
|B
). We calculated that P(A|B) = 7.70% and P(A
|B
) = 99.61%.
These values are skewed (very low P(A|B) and very high P(A
|B
)) since Groups
D has far more data points than Group S. Thus, a randomly selected data point
is much more likely to be from Group D than Group S.
Analysis of Results for Method SA
Using Method SA, we compared the pieces in the data set and split the results into
Groups S and D. We will analyze the distributions of these two groups of results.
Note that we selected the segmentation parameter m to equal 45 since this is the
point that minimizes the sum of Type I and Type II errors. This selection will
be discussed in detail in the Segmentation Parameter Selection section. Since
we concluded that variations of a theme are similar to one another while non-
variations are not, we would expect that the distribution of Group S would dier
59
from the distribution of Groups D. We constructed an empirical quantile-quantile
plot [Chambers et al. 1983] shown in Figure 23. It is clear from Figure 23 that
Group S does not come from the same underlying distribution as Groups D since
the plot is not close to the line x = y. This observation supports our initial
assumptions and veries that Method SA is successful at distinguishing between
pieces from the same and dierent Variation Sets.
Figure 23: Quantile-Quantile Plot Comparing Groups S and D of Variation Sets
Data Using Method SA
We conducted a K-S test [Conover 1980] to compare the distributions of the
two groups. Recall that the null hypothesis, H
0
, for this test is that the two groups
come from the same underlying continuous distribution. The test yielded a K-S
statistic value of 0.5672 and a p value of 0.0000. We can thus reject the null
hypothesis H
0
and verify that the distribution of Group S is signicantly dierent
from the distribution of Group D.
We next conducted a Mann-Whitney rank sum test [Conover 1980] to determine
whether the data in the two groups is from dierent populations. Recall the null
hypothesis, H
0
, is that the two groups come from distributions with equal medians.
This test yields a rank sum statistic of 1.6701 10
8
and a p value of 0.0000. We
60
can reject H
0
and conclude that the medians of Group S and Group D are not
equal. The implication of these results is that pieces from the same Variation Sets
are similar while pieces from dierent Variation Sets are dierent. Furthermore,
Method SA is successful at identifying these similarities.
Figure 24: Distributions of Distance Measure, Obtained Using Method SA, Divided
into Groups S and D for Variation Sets Data
The distributions of Groups S and D are shown in Figure 24. We normalized
the results so that the distributions sum to one. Notice that the plot for Group S
is signicantly dierent from that for Groups D. Next, we performed probabilistic
analyses of classication errors as we did with the previous experiment. Recall
that Method SA returns a single value for every comparison made between two
pieces. If two pieces are exactly the same, this value is equal to zero and as the
degree of dierence between the pieces increases, so does this measure. We again
select a cuto point for determining if two pieces can be considered variations of
the same piece. If the value is less than this cuto point, we conclude that the
pieces are similar. If it is greater than or equal to the cuto point, we conclude
that the pieces are dissimilar.
61
The cuto point is set to 108 which is the point at which the outlines of the
two distributions cross in Figure 24 and the point that minimizes the sum of Type
I and II errors. Let
A = Two pieces are from the same Variation Set, and
B = Their distance value is less than 108.
Next we computed Type I and Type II probabilities for Method SA. The proba-
bility of a Type I error, P(B|A
) = 15.36% while the probability of a Type II error
is P(B
|A) = 27.92%.
Now, consider the question: if we pick a data point at random, and its value is
less than 108, what is the probability that this data point belongs to Group S? We
can state the answer as P(A|B). Also consider the converse of this question: if we
pick a data point at random, and its value is greater than or equal to 108, what is
the probability that this data point does not belong to Group S? This answer can be
stated as P(A
|B
). We calculated that P(A|B) = 8.62% and P(A
|B
) = 99.34%.
These values are skewed (very low P(A|B) and very high P(A
|B
)) since Groups
D has far more data points than Group S. Thus, a randomly selected data point
is much more likely to be from Group D than Group S.
Analysis of Results for Method KD
We next compared the pieces in the data set using Method KD and again split
the results into Groups S and D. This section analyzes the distributions of the two
groups of results for Method KD. For this method, the segmentation parameter m is
set to 45 since this is the point that minimizes the sum of Type I and Type II errors.
This selection will be discussed in detail in the Segmentation Parameter Selection
section. We expect the distribution of Group S to dier from the distribution of
62
Groups D for Method KD. Refer to Figure 25 for the empirical quantile-quantile
plot [Chambers et al. 1983] for Method KD. It is clear from Figure 23 that Group S
does not come from the same underlying distribution as Groups D. This observation
supports our initial assumptions and veries that Method KD is successful at
distinguishing between pieces from the same and dierent Variation Sets.
Figure 25: Quantile-Quantile Plot Comparing Groups S and D of Variation Sets
Data Using Method KD
We conducted a K-S test [Conover 1980] for Method KD to compare the dis-
tributions of the two groups. Recall that the null hypothesis, H
0
, for this test is
that the two groups come from the same underlying continuous distribution. The
test yielded a K-S statistic value of 0.6297 and a p value of 0.0000. We can thus
reject the null hypothesis H
0
and verify that the distribution of Group S is indeed
signicantly dierent from the distribution of Groups D.
We next conducted a Mann-Whitney rank sum test [Conover 1980] for Method
KD to determine whether the data in the two groups is from dierent populations.
Recall that the null hypothesis, H
0
, is that the two groups come from distributions
with equal medians. This test yields a rank sum statistic of 1.5982 10
8
and a
p value of 0.0000. We can reject H
0
and conclude that the medians of Group S
63
and Group D are not equal. The implication of these results is that pieces from
the same Variation Sets are similar while pieces from dierent Variation Sets are
dierent and that Method KD is successful at identifying these similarities.
Figure 26: Distributions of Distance Measure, Obtained Using Method KD,
Divided into Groups S and D for Variation Sets Data
The distributions of Groups S and D are shown in Figure 26. The results
were normalized for these distributions since the number of elements in Group D
greatly outweighs those in Group S. Notice that an inspection of the plots veries
that Group S is signicantly dierent from that for Groups D. We also performed
probabilistic analyses of classication errors for Method KD. Method KD returns
a single value for every comparison made between two pieces. If two pieces are
exactly the same, this value is equal to zero. As the degree of dierence between
the pieces increases, so does this measure. Once again, we and selected a cuto
point for determining if two pieces can be considered variations of the same piece.
Recall that if the value is less than this cuto point, we conclude that the pieces
are similar. If it is greater than or equal to the cuto point, we conclude that the
pieces are dissimilar.
64
In this case, the cuto point is set to 44 which is the point at which the outlines
of the two distributions cross as well as the point at which the sum of Type I and
II errors is minimized. Now let
A = Two pieces are from the same Variation Set, and
B = Their distance value is less than 44.
The probability of a Type I error, P(B|A
) = 11.54% while the probability of a
Type II error is P(B
|A) = 25.49%. Method KD yields a lower Type I error rate
and a higher Type II rate.
We next consider the question: if we pick a data point at random, and its value
is less than 44, what is the probability that this data point belongs to Group S?
We can state the answer as P(A|B). Also consider the converse of this question:
if we pick a data point at random, and its value is greater than or equal to 44,
what is the probability that this data point does not belong to Group S? This
answer can be stated as P(A
|B
). We calculated that P(A|B) = 11.48% while
P(A
|B
) = 99.42%. These values are skewed in the same manner as with the other
methods since our data set has not changed and therefore, a randomly selected data
point is more likely to be from Group D than Group S.
Analysis of Results for Method KMD
We next compared the Variation Sets data using Method KMD and split the results
into Groups S and D. This section analyzes the distributions of the two groups of
results for Method KMD. For this method, the segmentation parameter m is set
to 45 since this is the point that minimizes the sum of Type I and Type II errors.
This selection will be discussed in detail in the Segmentation Parameter Selection
section. As with the other methods, we expect the distribution of Group S to dier
65
from the distribution of Groups D for Method KMD. Refer to Figure 27 for the
empirical quantile-quantile plot [Chambers et al. 1983] for Method KMD. It is
clear from Figure 27 that Group S and Group D come from dierent underlying
distributions. This observation supports our initial assumptions and veries that
Method KMD is successful at distinguishing between pieces from the same and
dierent Variation Sets.
Figure 27: Quantile-Quantile Plot Comparing Groups S and D of Variation Sets
Data Using Method KMD
We conducted a K-S test [Conover 1980] for Method KMD to compare the
distributions of the two groups. Recall that the null hypothesis, H
0
, for this test
is that the two groups come from the same underlying continuous distribution.
The test yielded a K-S statistic value of 0.6273 and a p value of 0.0000. We can
therefore reject the null hypothesis H
0
and verify that the distribution of Group S
is indeed signicantly dierent from the distribution of Groups D.
We next conducted a Mann-Whitney rank sum test [Conover 1980] for Method
KMD to determine whether the data in the two groups is from dierent popu-
lations. Recall that the null hypothesis, H
0
, is that Groups S and D come from
distributions with equal medians. This test yields a rank sum statistic of 1.65410
8
66
and a p value of 0.0000. We can reject H
0
and conclude that the medians of Group
S and Group D are not equal. The implication of these results is that pieces from
the same Variation Sets are similar while pieces from dierent Variation Sets are
dierent and that Method KMD is successful at identifying these similarities.
Figure 28: Distributions of Distance Measure, Obtained Using Method KMD,
Divided into Groups S and D for Variation Sets Data
The normalized distributions of Groups S and D are shown in Figure 28. These
distributions are similar to those of the other methods in that the distribution
of Group S is signicantly dierent from that for Groups D. We also performed
probabilistic analyses of classication errors for Method KMD. Method KMD also
returns a single value, representing the degree of dierence, for every comparison
made between two pieces. We used the same methodology as with the analysis
of results for the other methods and selected a cuto point for determining if two
pieces can be considered variations of the same piece. Recall that if the value is
less than this cuto point, we conclude that the pieces are similar. If it is greater
than or equal to the cuto point, we conclude that the pieces are dissimilar.
In this case, the cuto point is set to 47 which is the point at which the outlines
of the two distributions cross as well as the point at which the sum of Type I and
II errors is minimized. Now let
67
A = Two pieces are from the same Variation Set, and
B = Their distance value is less than 47.
The probability of a Type I error, P(B|A
) = 12.97% while the probability of a
Type II error is P(B
|A) = 24.35%. Method KMD yields a lower Type I error rate
and a slightly higher Type II error rate.
We next consider the question: if we pick a data point at random, and its value
is less than 47, what is the probability that this data point belongs to Group S
(P(A|B))? We also consider the converse of this question: if we pick a data point
at random, and its value is greater than or equal to 47, what is the probability
that this data point does not belong to Group S (P(A
|B
))? We calculated that
P(A|B) = 10.49% while P(A
|B
) = 99.44%. These values are skewed in the same
manner as they were with the other methods since a randomly selected data point
is more likely to be from Group D than Group S.
Segmentation Parameter Selection
For Methods SA, KD and KMD, we performed some analysis to determine the
optimal value for the segmentation parameter m. We dened optimality as the
minimization of the sum of Type I and Type II errors. While other cases would
require either Type I or Type II errors to have more weight, we have treated the
two types of errors as being equal and have thus selected to minimize the sum as
opposed to one particular error type.
We have tested Methods SA, KD, and KMD with a segmentation parameter
value set in the range of 3 to 99. Recall that the smallest value for m is set to
3 in order to capture the natural structure of most western classical pieces which
begin in a certain key, travel to other keys, and nally return to the original key.
We subsequently set the value of m to all multiples of 3 less than 100. We stopped
68
Figure 29: Plot of Type I, Type II and Total Errors for Method SA of Variation
Sets Data
Figure 30: Plot of Type I, Type II and Total Errors for Method KD of Variation
Sets Data
at m = 99 since there was a general trend of the sum of the Type I and II errors
increasing. Refer to Figures 29, 30 and 31 for the plots of the errors for Methods
SA, KD, and KMD respectively.
For the analysis presented in the previous sections, we selected m to equal the
value corresponding to the minimum value of the sum of the errors. As outlined
in Table 11, we set m = 45 for Methods SA and KD and KMD. An inspection of
Figures 29, 30 and 31 veries that these are in fact the segmentation values that
result in the lowest sum of the errors. It is important to note that this analysis
69
Figure 31: Plot of Type I, Type II and Total Errors for Method KMD of Variation
Sets Data
also reveals the exibility of our methods. This is evident in the fact that the
range of errors for the dierent values of m is rather narrow. Even though we have
selected the most optimal values for m, other values will have similar results. This
parameter insensitivity will allow a user of these methods to spend less time in
selecting a value for m.
Method Segmentation Value
Method SA 45
Method KD 45
Method KMD 45
Table 11: Segmentation Value for Methods SA, KD and KMD Using the Variations
Data
Interestingly, as shown in Table 11, unlike the previous experiment, the optimal
segmentation size for all the methods is the same in this experiment. This could
be due to the fact that, on the levels of similarity, variations exhibit a lesser degree
of similarity. Because of this, all the methods require shorter and more generalized
sequences of data to perform optimally. However, this observation must be paired
with the observation that the total error is stable across m values. Therefore, even
though the absolute optimal sizes for m might be 45 for all the methods, there
70
are other sizes of m, that produce comparable results. For example, Method KD
produces a Type I error of 14.20%, a Type II error of 23.14% and a Total error
of 37.35% for m = 15. The value for the Total error is quite close to that of the
Total error with m = 45 (37.03%).
Results Overview
This section outlines the results for this experiment. The experiment was con-
ducted on a set of Variation Sets data. We compared all the pieces in the data set
using all four similarity assessment methods (Methods PD, SA, KD and KMD).
Our results were split into Groups S and D. Group S consists of the results for
pieces from the same Variation Sets while Group D consists of the results for pieces
from dierent Variation Sets. For all four methods, quantile-quantile and K-S tests
conrmed that Group S and D do not come from the same underlying distribution.
Mann-Whitney rank sum tests revealed that Group S comes from a dierent pop-
ulation than Group D. We used a cuto categorization method to calculate Type I
and Type II errors as outlined in Table 12. For each method, we also calculated the
probability that a randomly selected comparison with a value less than the cuto
belongs to Group S (P(A|B)). We also calculated the converse probability that
a randomly selected comparison with a value greater than or equal to the cuto
belongs to Group D (P(A
|B
)). These probabilities are summarized in Table 13.
Method Type I Error Type II Error
Method PD 20.32% 15.68%
Method SA 15.36% 27.92%
Method KD 11.54% 25.49%
Method KMD 12.97% 24.35%
Table 12: Type I and Type II Errors for Methods PD, SA, KD and KMD Using
the Variations Data
71
Method P(A|B) P(A
|B
)
Method PD 7.70% 99.61%
Method SA 8.62% 99.34%
Method KD 11.48% 99.42%
Method KMD 10.49% 99.44%
Table 13: Probabilities for Methods PD, SA, KD and KMD Using the Variations
Data
Method Performance Analysis
Let us now consider the performance of Methods PD, SA, KD, and KMD on the
Rendition Sets and Variation Sets data. We will rst analyze the performance of
the four methods for each experiment. Refer to Figures 32 (Renditions Exper-
iment) and 33 (Variations Experiment) for the plot of the Type I, Type II and
Total errors computed for each method. For the following analysis, recall Method
KD is a high level similarity assessment method since it does not take into account
any sequential information while Method SA is a more low level method since it
is mainly concerned with the sequences of key progression. Method KMD shares
properties with both Methods KD and SA since it takes into account some sequen-
tial information but also relies on the high level key distributions. Method PD is
the most low-level method since it relies on a low level feature for comparisons.
For the rst experiment, which considered Rendition Sets, notice (shown in
Figure 32) that both Type I and Type II errors (and therefore the Total error) are
lowest when Method PD is employed. Given the nature of the Rendition Sets data
(a more specic level of similarity), it follows that a method that considers a low
level feature as a basis for analysis would perform better.
The results of the second experiment, which considers Variation Sets, follows
a dierent pattern from the rst experiment. Here, Type I error is lowest when
Method KD is used, Type II error is lowest when Method PD is used and the
72
Figure 32: Plot of Type I, Type II and Total Errors for Methods PD, SA, KD and
KMD of Rendition Sets Data
Figure 33: Plot of Type I, Type II and Total Errors for Methods PD, SA, KD and
KMD of Variation Sets Data
Total error is lowest when any of Methods PD, KD or KMD are used. Unlike the
Rendition Sets data, the Variation Sets data is at a broader level of similarity.
Therefore, Method PD, which considers low level data, does not perform nearly
as well as it does at the Renditions Set data level. At the Variation Sets level,
methods that consider more high level features and that dene similarity more
loosely become more successful.
The above analysis considered each experiment individually. We now analyze
the performance of the similarity assessment methods across data sets. Recall
73
Figure 34: Plot of Type I, Type II and Total Errors for Rendition and Variation
Sets data of Method PD
Figure 35: Plot of Type I, Type II and Total Errors for Rendition and Variation
Sets data of Method SA
that we stated that the methods developed have a success rate that increases as
the denition of similarity becomes more specic. It follows that all the methods
would perform better with the Rendition Sets data than with the Variation Sets
data. This is illustrated in Figures 34, 35, 36 and 37. Notice that in all the gures
(for Method PD, SA, KD and KMD respectively), all errors are much lower for
Rendition Sets data than for Variation Sets data. These methods are designed
to work at levels where the denition of similarity is more specic. Since the
data in the Rendition Sets represents pieces that have a more specic denition of
74
Figure 36: Plot of Type I, Type II and Total Errors for Rendition and Variation
Sets data of Method KD
Figure 37: Plot of Type I, Type II and Total Errors for Rendition and Variation
Sets data of Method KMD
similarity than the data in the Variation Sets, the methods perform better for the
Rendition Sets data experiment.
Our main conclusion from these experiments is that each similarity assessment
method performs better when it is paired with the appropriate data. Method
PD works best with Rendition Sets data since the data exhibits a high degree of
similarity and the method is a low level method that takes into account the details
of the low level feature of pitch. But for the Variation Sets data, Method PD is
not as successful. Instead, since the Variation Sets data exhibits a more general
75
degree of similarity, Methods KD and KMD work as well as Method PD since they
evaluate similarity at a higher level. All the methods provide promising results for
similarity assessment. For further use, it would be important to conduct an analysis
of the data used. A particular method may be better selected if there is knowledge
of the level of similarity exhibited in the data. Also, these methods may be used
to make comparisons such that judgments about the degree of similarity between
pieces would be made by taking into account multiple comparisons. For example,
the dissimilarity value for Pieces A and B would be compared to the dissimilarity
value of Pieces A and C to draw conclusions about the overall similarity of the
pieces.
76
Chapter 5: Related Work on
Music Visualization
This chapter reviews a selection of the many music visualization systems developed
so as to put the work presented in Chapters 6 and 7 in perspective. Music visual-
ization has the potential to reveal characteristics in music that would otherwise be
hidden. They can also serve as a basis for similarity assessment. Any visualization
method could be used to compare the visualizations of dierent pieces.
Music visualization can be broadly categorized into two categories: visual-
izations of collections and individual pieces. Since our work does not consider
collections, this review will be limited to visualizations of individual pieces. These
systems may be further sub-categorized as follows: representations of direct versus
interpreted data, and static versus dynamic presentations. Direct data refers to
data that is extracted directly from the music (such as pitch and onset time), while
interpreted data refers to information that must be determined from extracted data
(for example, tempo and key). Note that the visualization proposed in Chapter 6
is a dynamic visualization of interpreted data while the visualization proposed in
Chapter 7 is a static visualization of interpreted data.
77
Static Visualization of Direct Data
Let us consider static visualizations of direct data. The most basic visualizations
in this category are waveforms and spectrograms which, in a two-dimensional (2D)
version, usually show time on the x-axis, and have primary values of interest on
the y-axis. Additional mappings of these primary values are often shown using
color or grayscale ranges. There are a number of standard music software pack-
ages that provide these basic visualizations. For example Pro Tools, developed by
DigiDesign [DigiDesign 2007], is a digital audio workstation widely used by profes-
sionals in music production. While the visualizations and views provided by such
a powerful software package are indispensable to the music professional, our focus
here is more on visualizations that either interpret or analyze the music data and
produce a visualization as an end product.
Misra, Wang, and Cook [Misra et al. 2005] developed a set of tools entitled
sndtools that generate visualizations (real-time) of direct data with some added
features and dimensionality. More specically, sndtools is a set of cross platform,
open-source tools for simultaneously displaying related audio and visual informa-
tion in real-time. One of the tools oered in sndtools is sndpeek which is a waveform
and spectrum visualizer with several other features. Figure 38 shows a screen shot
of sndpeek in action. The components of sndpeek include a time-domain waveform
which can be input from a microphone or from various types of audio les, a fast
Fourier transform (FFT) magnitude spectrum, a three-dimensional (3D) waterfall
plot which is a cascading FFT magnitude spectrum with previous frames fading
into the background, a Lissajous plot that shows the correlation between left and
right channels (stereo signals) and spectral features such as centroid, rms, rollo
and ux which are extracted using the MARSYAS framework [Tzanetakis & Cook
2000].
78
Figure 38: Screen Shot of sndpeek [Misra et al. 2005] (Image used with permission
of author)
Dynamic Visualization of Direct Data
We now turn to dynamic visualizations of direct data. Consider Malinowskis
Music Animation Machine [Malinowski 2007] which dynamically shows notes in
a simplied piano roll representation. The Music Animation Machine display is an
animated score without any measures or clefs. Colored bars are used to represent
the notes of a piece. The vertical placement of each bar indicates the pitch of its
note, the horizontal placement indicates its timing relative to the other notes of
the piece, and the length of the bar shows its duration. These bars scroll across the
screen as the piece plays; when a bar reaches the center of the screen, it brightens
as its corresponding note sounds. The dierent colors of the bars denote dierent
instruments, voices, thematic material, or tonality. Refer to Figure 39 for a screen
shot of the Music Animation Machine. In this example, color is used to represent
dynamics level such that the louder the note, a brighter red is used while the softer
the note, a deeper blue is used.
79
Figure 39: Screen Shot of Music Animation Machine [Malinowski 2007] Visualizing
William Byrds A Voluntarie: for my ladye nevell (Image used with permission of
author)
Another dynamic visualization of direct data, Impromptu, has been developed
by Bamberger [Bamberger 2000]. While Impromptu was designed as a teaching tool
to help in the development musical intuitions, it incorporates a visually modied
form of the piano roll representation introduced above. Impromptu is a drag-and-
drop system that allows for the manipulation of musical entities referred to as
Tune Blocks. As the user makes changes and additions, Impromptu updates the
visualization. Figure 40 presents a screen shot of Impromptu.
Figure 40: Screen Shot of Impromptu [Bamberger 2000] (Image used with permis-
sion of author)
80
Static Visualization of Interpreted Data
We now consider static visualizations of interpreted data. One approach to music
visualization is to create self-similarity maps. In the work developed by Foote
and Cooper [Foote & Cooper 2001], the acoustic similarity between all instants
of an audio recording are calculated and displayed on a 2D grid. An audio le is
visualized as a square with time displayed on the x-axis from left to right as well
as on the y-axis from bottom to top. Within the square, the brightness of a point
(i, j) is proportional to the audio similarity between time i and j. Similar regions
are bright while dissimilar regions are dark. Refer to Figure 41 for an example of
the self-similarity matrix. Figure 41 shows the rst two bars of Bachs Prelude No.
1 in C Major, from The Well-Tempered Clavier (BWV 846).
Figure 41: Self-similarity Visualization of Bachs BWV 846 [Foote & Cooper 2001]
(Image used with permission of author)
Another self-similarity visualization, The Shape of Song, has been developed
by Wattenberg et. al. [Wattenberg 2007]. The diagrams developed by The Shape of
Song display musical form as a sequence of translucent arches. Each arch connects
81
two repeated, identical passages of a composition. By using repeated passages as
landmarks, the maps reveal deep structures in musical compositions. Figure 42
displays the visualization of three of the Goldberg Variations by Bach. This is a
good example with which to illustrate how music visualization may be used for
similarity assessment. We can assume that the pieces are similar since they are
variations. The images in Figure 42 reveal the similarities that exist in the music.
Figure 42: Self-similarity Visualization of Bachs Goldberg Variations [Wattenberg
2007] (Image used with permission of author)
Sapp [Sapp 2001] developed a multi-timescale visualization technique for dis-
playing the output from key-nding algorithms. In his visualization, the horizontal
axis represents time in the score, while the vertical axis represents the duration
of an analysis window used to select music for the key-nding algorithm. Each
analysis window result is colored according to the determined key. Three types of
diagrams are proposed. The rst divides a piece into successively smaller analysis
window units with the top level of the diagram displaying the key of the entire
piece, the second level splitting the music into two equal parts and displaying the
key for the music in each half, and so on. The second type of diagram gives equal
82
resolution at all time scales. Instead of coloring the entire analysis window duration
with the key color, a single pixel centered in the middle of the analysis window is
drawn. The third type of diagram takes into account key probabilities to generate
color-interpolated key based visualizations on the general form of the second type
of diagrams. Figure 43 shows an example of the second type of visualization using
Mozarts Viennese Sonatina No. 1 in C Major Movement 1 (K.439b).
Figure 43: Key Visualization of Mozarts K. 439b [Sapp 2001] (Image used with
permission of author)
Dynamic Visualization of Interpreted Data
An early work by Cohn [Cohn 1997] established mappings of music onto the har-
monic network (also known as the tonnetz ). The harmonic network is a represen-
tation of pitch relations where each node represents a pitch class which is a set of
pitches related by a multiple of an octave. It can be assembled by arranging the 12
notes of the chromatic scale on a 2D grid of rows and columns beginning with the
circle of fths. The circle of fths depicts relationships among the 12 pitch classes
83
comprising the scale. To generate the rst row, the circle of fths is disconnected
and laid out in a straight line. The same row of fths is then shifted and placed
below and between the notes in the rst row so the notes are a minor third apart.
This pattern is repeated again below the second and third rows, and so on. The
harmonic network, while rst seen as a at plane that extended innitely in all
directions, can also be formed into the surface of a torus [Lubin 1974].
We now transition to visualizations of interpreted data that are also dynamic.
Related to the harmonic network visualization is Toiviainen & Krumhansls [Toivi-
ainen & Krumhansl 2003] visualization of listeners continuous ratings of tonal
contexts on a toroid representation of keys (shown in 2D). Their work measured
and modeled real-time responses using self-organizing maps. For an example, refer
to Figure 44. This is a grayscale snapshot of the dynamic visualization of Bachs
Organ Duetto (BWV 805). Figure 44 shows the projections at the beginning of:
(a) measure 11, (b) measure 18, (c) measure 25, and (d) measure 34.
Figure 44: Snapshot of Visualization of Listeners Continuous Ratings of Tonal
Context [Toiviainen & Krumhansl 2003] (Image used with permission of author)
84
Gomez & Bonada [Gomez & Bonada 2005] developed a tool to visualize the
tonal content of polyphonic audio signals. This tool includes dierent views that
may be used for the analysis of tonal content of a music piece through visualization
of chord and key estimation, and tonal similarity assessment. An example of one
of the views, Key Correlation, is presented in Figure 45. This view shows the
key estimation in a certain window compared to the global key estimation. The
window size is a user-dened parameter. Major keys are depicted on the left (in
blue) while minor keys are depicted on the right (in green). The x-axis represents
the pitch classes. The top row has the pitch classes ordered with the chromatic
scale while the bottom row has them ordered with the circle of fths. An example
of another view, KeyGram is presented in Figure 46. The KeyGram view displays
the tonal evolution of a piece on the surface of a torus.
Figure 45: Snapshot of Key Correlation Visualization [Gomez & Bonada 2005]
(Image used with permission of author)
The following works also maintain history information. Langer & Goebl [Langer
& Goebl 2003] introduced a method for displaying tempo and loudness variations
of expressive music performance. This visualization can accommodate both MIDI
and audio data. In this dynamic visualization that is synchronized with the music,
a dot moves through a 2D space representing tempo (x-axis) and loudness (y-
axis), leaving behind a trace of the recent trajectory that may be interpreted as
85
Figure 46: Snapshot of KeyGram Visualization [Gomez & Bonada 2005] (Image
used with permission of author)
the performance path. Refer to Figure 47 for an example of the visualization. This
example shows Chopins Etude (Op. 10 No. 3), performed by Maurizio Pollini.
The expression trajectories of bars 1 to 14 is shown on the left while the trajectories
of bars 1 to 21 is shown on the right. The trajectories of the rst 14 bars are still
observable in the right gure as very faint lines.
Figure 47: Snapshot of Tempo-Loudness Visualization [Langer & Goebl 2003]
(Image used with permission of author)
Chew & Francois [Chew & Francois 2005] developed an interactive system
for tonal visualization of music at multiple scales. Their MuSA.RT analysis and
visualization system aims to create an environment by which musical performances
can be mapped in real-time to a concrete and visual metaphor for tonal space, such
that the establishment and evolution of the tonal context may be displayed. The
86
visualizations have tonal information from music performances mapped (in real-
time) to a three-dimensional representation of tonal space (described in detail in the
Spiral Array Model section in Chapter 3). The visualizations also portray musical
memory as trajectories that touch on the recently visited tonal regions. Figure 48
shows snapshots of MuSA.RT with Pachelbels Canon in D Major. This piece has
a bassline that is continually repeated over the course of the piece. Notice that the
repeating bassline as well as repeating harmony are displayed in the visualization.
Figure 48: Snapshot of MuSA.RT Visualization [Chew & Francois 2005] (Image
used with permission of author)
Our dynamic visualization approach can be considered a 2D counterpart of
this work, with the dierence that it shows not only the keys as they unfold,
it also portrays the cumulative key information as dynamically varying spatial
distributions of colored discs.
87
In the next chapter (Chapter 6), we will present our dynamic music visual-
ization method. This visualization method not only unfolds over time, it also
maintains history information. It simultaneously presents the progression of keys
as well as the up-to-date distribution of keys. While all the visualization methods
presented here focus on important features to visualize, none consider the dynamic
progressions of key.
88
Chapter 6: Dynamic Music
Visualization
The work on dynamic music visualization presented in this chapter is part of a 2006-
2007 Digital Dissertation Fellowship which is a year-long fellowship designed to
foster multimedia research that expands the potential of academic publication via
emergent and transitional media. The deliverable on this project is a hands-on
web-based interactive interface, where a user could listen to the music, see its visual
description, and follow the (numerical) results computed algorithmically. Music
unfolds over time, and a successful and intuitive visualization of music should
also progress in the same manner. Presentation of time-based visualizations of
music can only be accomplished with the help of multimedia content, and would
be impossible using only text or pictures. The visualization component of the
interface is based on Lerdahls Tonal Pitch Space [Lerdahl 2001], which portrays
all major and minor keys on a two-dimensional (2D) plane. The distribution of keys
of a piece being visualized is indicated as growing colored discs, where the colors
correspond to the keys detected, and the size of the discs to the key frequency.
89
Information Design Qualities of Dynamic Visual-
ization Method
In our previous work ([Mardirossian & Chew 2005a; 2006]) and in Chapters 3 and 4,
we investigated how key progressions and distributions could be successfully used
to assess similarity between pieces, demonstrating that key progressions and dis-
tributions, although summarizations of the musical content, can serve as good
representations of pieces. The current visualization method is an extension and
improvement of the key progression and distribution approach, expanding and
adding richness to the simple histogram representation through an increase in
dimensionality, addition of color, and animation.
Escaping Flatland
According to Tufte [Tufte 1990], an acknowledged expert in information design
and visual literacy, increasing the number of dimensions of a visualization sharp-
ens the information resolution. Even though the world we navigate through is
three-dimensional, our portrayal of information is often caught in the 2D at-
lands of paper and video screens. According to Tufte, escaping this atland is
the essential task of envisioning information - for all the interesting worlds (phys-
ical, biological, imaginary, human) that we seek to understand are inevitably and
happily multivariate in nature. Not atlands. This escape from atlands and
an increase in resolution power can be achieved through either an increase in the
number of dimensions represented on the plane surfaces or through the increase in
data density which is the amount of information per unit area.
As an example, consider the four-dimensional perspective map in Fig-
ure 49 [Tufte 1990]. The dimensions here are comprised of the atland of the
90
Figure 49: Kellom Tomlinson, The Art of Dancing, Explained by Reading and Fig-
ures (London, 1735), book I, plate XII (Image used with permission of publisher)
oor, the coded gestures in dance notation of body motion, and time sequence.
The oor plane is linked to the music by numbers, with varying steps for vary-
ing sounds such that the numbers have a double function of sequencing steps and
relating movements to the music.
Our proposed visualization method is an improvement over the histogram
method of display because of the added dimensionality. In the histogram, the keys
were shown on a one-dimensional line, while in the new visual interface, the keys
(all major and minor keys) are shown on a 2D plane, thus capturing the network
of inter-relations amongst keys. The frequency of the keys (the third dimension)
is shown in the size of the discs. Furthermore, the progression of disc growth
shows the range of movement of keys within the piece over time. Hence, we have
essentially four dimensions of information captured in a dynamic 2D interface.
91
Small Multiple Design
Tufte refers to representations that are sequenced over time like the frames of a
movie, or ordered by a quantitative variable not used in the image itself, as small
multiple designs. Tufte states that this type of information design, multivariate
and rich with data, answer directly [the question of compared to what?] by
visually enforcing comparisons of changes, of the dierences among objects, of the
scope of alternatives.
Figure 50: Rules and Regulations for the Government of Employees of the Operat-
ing Department of the Hudson and Manhattan Railroad Company, Eective Octo-
ber 1st, 1923 (New York, 1923) (Image used with permission of publisher)
Consider, as an example of small multiple design, Figure 50 [Tufte 1990]. This
drawing of the rules for railroad operation shows varying signal lights on the ends
of a train entabled in a rulebook for railroad employees.
92
Our proposed visualization method incorporates these ideas of small multiple
design by taking a sequence of keys and showing the evolution frame-by-frame over
time. This dynamic visualization allows one to see the sequential progression of
keys, an important component in communicating with music.
Color and Information
Since the human eye is incredibly sensitive to color variations, it is natural and ele-
mentary to attempt to tie color to the representation of information. Yet, Tufte rec-
ognizes that this task is such a complex matter that avoiding catastrophe becomes
the rst principle in brining color to information: Above all, do no harm. Tufte
has provided guidelines for avoiding catastrophe. He states that the fundamental
uses of color in information design are: to label (color as noun), to measure (color
as quantity), to imitate reality (color as representation), and to enliven or decorate
(color as beauty).
Figure 51: Oliver Byrne, The First Six Books of the Elements of Euclid in Which
Coloured Diagrams and Symbols Are Used Instead of Letters for the Greater Ease
of Learners (London, 1847) (Image used with permission of publisher)
Figure 51 [Tufte 1990] illustrates the power of using color for representing and
conveying ideas and information. Here, color serves mainly as a label. The author
93
discards more traditional letter-coded approaches to geometry. In this partial
proof, each element is identied by consistent shape, color, and orientation. Angles
are not referenced by arbitrary names, but are instead shown.
Our visualization method serves all the fundamental uses of color outlined by
Tufte. More specically, color labels by distinguishing between keys, measures by
displaying the amount of time spent in each key, imitates reality by showing the
relationship between keys, and decorates since the same visualization in black and
white would not be nearly as visually pleasing.
System Description
This section describes the components of our dynamic music visualization method,
which displays the progression of the tonal content of a music piece. We begin by
slicing a piece of music into m segments of uniform time length, and determining
the key for each segment using SKeFiS. We then map the sequence of keys onto
a 2D space that contains points representing all possible keys. Refer to Figure 52
for the system diagram.
Figure 52: System Diagram for Dynamic Visualization Method
Note that the rst two steps in Figure 52 are identical to those outlined in the
Segmentation and Key Determination sections in Chapter 3 respectively. Recall
from the Segmentation section that we begin by segmenting each piece into a
given number of segments, m, of uniform length. Once a piece is segmented, the
key of each segment must be determined. While any key-nding algorithm may
be invoked to identify the keys (see [Downie 2005] for references to key-nding
94
algorithms), we utilize the SKeFiS key-nding system again as outlined in the Key
Determination section. The input to the dynamic visualization is this sequence of
keys generated for a piece.
Tonal Pitch Space
In music theory, pitch spaces model relationships between pitches based on the
degree of relatedness among them, with closely related pitches placed near one
another, and less closely related pitches placed farther apart. Models of pitch
space may be in the form of graphs, groups, lattices, or geometrical gures such
as helixes. For this visualization method, we use Lerdahls 2D representation of
major and minor keys in his Tonal Pitch Space [Lerdahl 2001].
Refer to Table 14 for a depiction of Lerdahls key space; major keys are notated
in capital letters while minor keys are not. In this arrangement of keys, the circle
of fths is placed on the horizontal axis while relative and parallel major/minor
relationships alternate along the vertical axis. Recall that the circle of fths depicts
relationships among the 12 pitch classes comprising the scale. Also recall that the
relative minor of a particular major key (or the relative major of a minor key) is
the key which has the same key signature but a dierent tonic. The parallel minor
of a particular major key (or the parallel major of a minor key) is the minor key
with the same tonic. The tonic is the rst note of a musical scale. Note that the
Tonal Pitch Space may be extended innitely as we cycle through all keys. As
shown in Table 14, the keys . . . , G, C, F, . . . represent the circle of fths and are
positioned on the horizontal axis of the Tonal Pitch Space. Also, a is the relative
minor of C while c is the parallel minor of C.
95
d g c f b e a
F B E A D G C
f b e a d g c
A D G C F B E
a d g c f b e
C F B E A D G
c f b e a d g
Table 14: Key Representation on Tonal Pitch Space
Color Selection
Every possible key is assigned a dierent color for visualization. The circle of fths
and the color wheel are merged to determine the color assignments. Figure 53
depicts the circle of fths with each key assigned to a color from the color wheel.
Keys on the outer ring represent major keys while keys on the inner ring represent
minor keys. The main idea of this color assignment is to have keys that are
considered to be close one to another be assigned colors that are also related. For
example, C Major and A Minor (A Minor is the relative minor of C Major) are
assigned a dark and light green respectively.
Figure 53: Color Assignments for Major and Minor Keys
96
Animation
This section outlines the way the animated visualization looks and progresses.
The background of the visualization contains points that represent the keys in
the Tonal Pitch Space. Each point is a dierent color according to the coloring
scheme outlined above. The visualization is synchronized with the music. As a
piece progresses, the disc over the key of the present segment grows by one unit,
indicating the key of that segment, and the cumulative information of the key
distribution. Each time a key is re-visited, the disc over that point grows. At the
end of the piece, the visualization displays a 2D version of the distribution of keys
for the piece, with the size of discs representing the frequency of the keys.
User Interface
The visualization method outlined above has been implemented in an intuitive user
interface to promote ease-of-use and to encourage the process of exploration and
discovery. Refer to Figure 54 for a snapshot of the interface. The user can select to
view the visualization synchronized with the music, or without music replay, and
a set delay between each frame. The user may also select the piece to visualize
by clicking on the desired piece in the menu. The last parameter controlled by
the user is the segmentation size m, selected by moving the slider, the value of
which ranges from 5 to 60. This parameter controls the level of detail, and degree
of stability, of the visualizations. As m increases, so does the level of granularity
of the information displayed. The user may obtain any key name by placing the
mouse over a point on the grid of keys.
97
Figure 54: Snapshot of Dynamic Visualization Interface
Example
Consider the rst variation of Beethovens 32 Variations in C Minor
(WoO80) [Schwob 2007]. Refer to Figure 55 for a frame-by-frame illustration of
the visualization of this piece. The segmentation parameter, m, was chosen to be
8, the number of bars in the piece. The sequence of identied keys for the slices is
as follows: C Minor, F Major, C Minor, C Major, C Minor, C Minor, F Minor, C
Minor. Each frame shows the up-to-date analysis of each slice. In each frame, the
disc corresponding to the key of the current segment grows in size. For example,
we know from the visualization that the piece begins and ends in the key of the
piece (C Minor) because, in both the rst and last frame, the disc corresponding
to the C Minor point grows in size. Additionally, recall that the Tonal Pitch Space
has each key repeated such that the window on the grid dictates which keys will
be shown multiple times. In this particular example, there are no repeats because
of the relatively small size of each frame. In contrast, there are many repeated
keys (and key distribution patterns) in Figure 54.
98
Figure 55: Frame-by-Frame Dynamic Visualization of Beethovens WoO80 First
Variation
Validation
This section presents a formal validation of this visualization method. If a music
visualization method aims to go beyond being simply aesthetically pleasing, and
strives to transform music into a visual medium, then it must share certain impor-
tant characteristics with the music. We test whether our proposed visualization
method is in fact a good mapping of music onto a visual space by considering its
invariance under the transformations outlined by Dorrell in [Dorrell 2005], namely,
pitch and octave translation, time and amplitude scaling, and time translation.
These are the types of changes in music that do not inuence human ability in the
recognition of a piece. For this analysis we consider the theme of Mozarts Ah,
Vous Dirai-je, Maman (K265) [Schwob 2007]. The piece is segmented into 9 slices
for the visualizations; Figure 56 shows the last visualization frame.
Pitch Translation Invariance
Pitch Translation transposes a piece into a dierent key. Transposition does not
alter the musical quality of a piece in any signicant way. In fact, we do not
normally consider a piece transposed into a dierent key as being a dierent piece.
99
Figure 56: Last Frame of Dynamic Visualization of Mozarts K265 Theme - Orig-
inal Piece and Alterations
The patterns revealed by our visualization method remain intact, and are simply
shifted over to the area of the new key. Consider again the example of Mozarts
K265 theme which is originally in the key of C Major. We transposed it to the key
of F Major. Refer to Figures 56(a) and 56(b) for the last frame of the visualization
of the original and transposed piece respectively.
Octave Translation Invariance
Octave Translation refers to the transposition of a piece into a dierent octave. It
does not alter the quality of the music either, and could be considered a special
type of pitch transposition. Refer to Figure 56(c) for the last frame of the visu-
alization of the example piece transposed down one octave. Notice that since the
points representing the keys on the Tonal Pitch Space do not distinguish between
100
octaves, the visualization is identical to the original. Octave translation bears dif-
ferent similarities to the original than other transpositions. This is reected in the
visualization, where octave translation has no eect while other transpositions are
indicated by a spatial translation.
Time Scaling Invariance
Time Scaling refers to the changing of the tempo. If a piece is played faster
or slower, we recognize it as being the same piece. This is translated into the
visualization in Figure 56(d), which shows a time-scaled version of Mozarts K265.
We sped up the original piece by doubling its tempo. Since each piece is segmented
into an equal number of segments, time-scaling has no eect on the visualization.
For both the original and fast version, each segment has the exact same content.
Amplitude Scaling Invariance
Amplitude Scaling refers to changing the volume of a piece. This simply states that
turning the volume up or down does not change the music. This could however
have an eect on certain computation methods. Because our visualization method
is based on tonal features, the amplitude has no eect.
Time Translation Invariance
Time Translation refers to the time at which a piece is played. This is perhaps the
most obvious invariance. A piece is exactly the same if it is played now, in ve
minutes, or in a year. Our visualization will also look the same for the same piece
no matter when it is invoked.
101
Demonstrations
This section demonstrates the functionality of the dynamic visualization method
with several examples. The ability to see the high level tonal progression of a piece
over time, and its usage of dierent tonalities, could provide insight into the deep
structures and nature of individual pieces, as well as dierent genres of music. We
will consider examples from two genres: classical western music and traditional
Armenian music. We will demonstrate with visualizations that classical pieces
begin and end in the key of the piece but travel to other keys throughout the
course of the piece. Armenian pieces, on the other hand, follow a more sequential
pattern and visit a number of keys without revisiting any.
Classical Music
Classical and popular western music have a common structure that we have come
to expect. In general, classical pieces begin in the key of the piece, then travel
through the terrain of various other keys, and ultimately return to the original
key at the end of the piece. These pieces can be thought of as having a center
star around which the piece revolves even though there is variation in how far a
piece will stray from this center, and how often it will return to visit it through
the course of the piece. We will next consider a number of classical music example
pieces obtained from [Schwob 2007]. We will illustrate the visualization for three
pieces and show an overview of twenty ve other pieces.
As an example, consider the visualization of the Bachs Prelude and Fugue in
B Minor (BWV 544) shown in Figure 57. Notice, in the rst frame, that the piece
begins in B Minor (the key of the piece). The key then travels to F Minor in frame
2, travels to E Minor in frame 3, revisits B Minor for frame 4 and 5, travels to A
102
Figure 57: Frame-by-Frame Dynamic Visualization of Bachs BWV 544
Major for frame 6, revisits F Minor in frame 7, and nally returns to B Minor in
the last frame.
Figure 58: Frame-by-Frame Dynamic Visualization of Beethovens Op. 93
Now consider the visualization of Beethovens Symphony No. 8 in F Major -
1. Allegro vivace e con brio (Op. 93) shown in Figure 58. This visualization also
begins in the key of the piece (F Major). It then travels to C Major for frame 2,
returns to F Major for frame 3, travels to C Major again for frame 4, moves to D
Minor in frame 5, and returns to F Major for the last two frames.
Next we consider the example of Chopins Etude in C Major (Op. 10 No. 1)
illustrated in Figure 59. This piece also begins in the key of the piece (C Major),
travels to A Minor in frame 2, travels to F Major for frames 3 and 4, moves to G
103
Figure 59: Frame-by-Frame Dynamic Visualization of Chopins Op. 10 No. 1
Major in frame 5, returns to F Major in frame 6, returns to G Major in frame 7,
and nally returns to the key of the piece (C Major) in the last frame. Notice that
all the example pieces begin and end in the same key.
The above three examples illustrated the general nature of key progressions in
classical music. We next consider an additional set of twenty ve classical pieces
(shown in Figure 60) (m = 9) that also exhibit the pattern of beginning in the key
of the piece, visiting a number of other keys throughout the piece, before nally
returning to and ending in the key of the piece. Notice that all the example pieces
being and end in the same key. For the given set of pieces, 12% remain in the key
for the entire piece, 32% have 2 key changes (begin in the key of the piece, move
to another key, return to the key of the piece), 8% have 3 key changes, 16% have 4
key changes, 16% have 5 key changes, 8% have 6 key changes, and 8% have 8 key
changes. Note that 56% of the keys in these classical pieces are major keys while
44% are minor keys.
104
Figure 60: Color Coded Key Progressions for Twenty Five Classical Pieces
Armenian Music
In contrast to the general visual sequence and patterns laid out by classical music,
Armenian traditional music generates a dierent pattern. Instead of having a cen-
ter of interest, the visualization tool reveals a sequential pattern of key progression
that does not return to the original key. Typically, a piece begins in and stays in
one key for a period of time, and then moves to a neighboring key. The piece typ-
ically does not end in the key it which it began. There is variation in the number
of keys visited as well as the range of keys spanned. We present the results from
105
a collection of Armenian pieces obtained from [Muradian 2007]. We will illustrate
the visualization for three pieces and show an overview of twenty ve more pieces.
Figure 61: Frame-by-Frame Dynamic Visualization of Armenian dance song Barer
Consider the Armenian dance song entitled Barer (Dances). Refer to Fig-
ure 61 for a frame-by-frame view of the visualization of this piece with m = 8.
Notice how the piece begins in B Minor and remains there from frames 1 through
5, then travels to D Major for frame 6, and ends by traveling to G Major for frames
7 and 8.
Figure 62: Frame-by-Frame Dynamic Visualization of Armenian dance song
Amber Goran
Now consider the Armenian folk song entitled Amber Goran (Lost Clouds)
(m = 8). Notice in Figure 62 that the piece begins and stays in F Major for frames
1 through 4, and then travels to F Minor for the remainder of the piece.
106
Figure 63: Frame-by-Frame Dynamic Visualization of Armenian dance song
Apheres Oor Es
Lastly, consider the visualization of the piece Apheres Oor Es (Where Are
You Brother) as shown in Figure 63. The piece is in C Major for frames 1 to 5.
It then travels to F Minor for frames 6 and 7 before moving to A Major for the
last frame.
The above three examples illustrate, by means of the dynamic visualization,
the general tonal structure of Armenian music. To provide further examples of the
sequential progression of keys in Armenian music, consider the additional twenty
ve pieces shown in Figure 64 where m = 9. All the pieces visit a key and remain
there before moving to another set of keys. The total number of keys visited varies
piece by piece, but none of the pieces revisit a key. From the twenty ve examples,
28% of the pieces visit only one key, 56% visit two keys, while 16% visit a total
of three keys. Note that 74% of the keys in the Armenian pieces are minor keys
while only 26% are major keys.
Results Overview and Discussion
The previous sections outlined the performance of the visualization method on two
music genres: classical western music and traditional Armenian music. We showed,
107
Figure 64: Color Coded Key Progressions for Twenty Five Armenian Songs
by means of 28 examples that classical pieces begin in the key of the piece, then
travel to various other keys, and ultimately return to the original key at the end
of the piece. We also showed, by means of 28 examples that traditional Armenian
pieces behave dierently from classical pieces. They begin and stay in one key for
a period of time, and then sequentially move to a set of neighboring keys. No keys
are revisited.
Interestingly, during our analysis portion, we encountered a couple of Arme-
nian pieces that behaved like the classical pieces. This prompted us to conduct
further listening tests which revealed that these pieces, in fact, did not sound like
108
Armenian pieces but had instead a western pop quality to them. These pieces
were ultimately excluded since they were not traditional Armenian pieces.
109
Chapter 7: Static Aggregate
Music Visualization
In Chapter 6 we presented a dynamic music visualization system that displays the
progression and distribution of keys as growing colored discs. Recall that one of
the parameters on the user interface is the segmentation size m. As m increases,
so does the level of granularity of the information displayed. This ability to zoom
in and out of the dynamic visualization is a powerful exploratory tool for the user.
While each visualization on its own provides a great deal of information about the
piece, a collection of visualizations of the piece with dierent values for m provides
even greater insight. For example, some pieces are rather stable and are unchanged
when viewed with dierent values for m while others show a great deal of change
in the visualization pattern when m is varied.
We have developed a static aggregate visualization system that can be used
in conjunction with the dynamic visualization. This static visualization allows
a user to get a quick-glance overview of the visualization for many values of m.
This new visualization method can be loosely thought of as the aerial view of the
dynamic visualization system. This method exploits the tonal properties of music
to derive a hierarchical description for each piece. Each piece of music can be
characterized by a description tree that summarizes its tonality for every segment
110
at each hierarchical level. The SKeFiS key-nding system is used throughout this
method to determine keys. The root of the tree (level 0) contains the key of the
entire piece. At the next level, the piece is halved (time-wise) and each node at
this level contains the key of one half. As the depth increases, the piece is further
subdivided and a key is calculated for each segment.
Segmentation
At each level, {0, 1, . . . j}, the piece is partitioned into 2
segments. The rst
level contains 2
0
= 1 sections, the second level contains 2
1
= 2 sections, and so
on. The nal level contains 2
j
sections. This maximum depth, j, is given by the
formula in 12 where represents the length of the piece in seconds. The formula
in 12 ensures that the nal level contains 2
j
segments, each of length close to
(and perhaps a little under) one second. Note that no metrical (time) structure is
assumed for the piece. At each stage, every segment is simply halved.
j = log
2
(12)
Visualization
Every possible key is assigned a particular color for visualization. We use the
same coloring scheme as in Chapter 6. Recall that the circle of fths and the
color wheel were merged together to determine the color assignments (shown in
Figure 53). The visualization is a representation of the hierarchical tree in a
circular shape. Figure 65 illustrates the tree like structure of the data obtained for
the visualization as well as the layout of the actual visualization. The left hand
portion of Figure 65 illustrates how a piece is segmented while the right hand
111
portion illustrates how the identied keys are positioned in the visualization. Note
the following representations used in Figure 65: (a) key of 100% of the piece, (b)
key of the rst 50% of the piece, (c) key of the last 50% of the piece, (d) key of
the rst 25% of the piece, (e) key of the 25% to 50% of the piece, (f) key of the
50% to 75% of the piece, and (e) key of last 25% of the piece.
Figure 65: Aerial Visualization of Hierarchical Description Tree Conguration
Example
To demonstrate the usefulness of this aggregate static visualization method, we
provide three examples. These examples will demonstrate the additional informa-
tion that is displayed in these visualizations. More specically, they will illustrate
the multi-scale stability of the pieces. For the comparisons, all the pieces have
been normalized to the same key, C Major.
Let us consider three pieces, obtained from [Hewlett 2007], as examples. Piece
A is the second movement of Corellis Trio Sonata (Op. 4, No. 3), Piece B is the
third movement of Corellis Trio Sonata (Op. 1 No. 5) and Piece C is the third
movement of Beethovens Violin Concerto (Op. 61). Figures 66, 67 and 68 display
the rst four levels of the normalized aerial static visualization for Pieces A, B and
C respectively. These examples illustrate how these visualizations could be used
112
Figure 66: Normalized Aerial Visualization of Example Piece A
in conjunction with the dynamic visualizations to give an overview of the tonal
structure of a piece.
Figure 67: Normalized Aerial Visualization of Example Piece B
Piece A, as shown in Figure 66 is rather stable across dierent m values. This
is apparent in the fact that at every level and for every segment (except for two),
the piece remains in the same normalized key (C Major). By viewing this aerial
visualization, a user will get a better idea of the pieces behavior and degree of
stability.
Piece B, as shown in Figure 67, is less stable than Piece A. Notice that in all the
levels (apart from the rst), the piece uctuates through a range of keys. Although
there is more uctuation in Piece B than A, the range of keys visited in Piece B is
113
Figure 68: Normalized Aerial Visualization of Example Piece C
rather narrow. This can be observed in Figure 67 where the colors of the keys are
closely related colors. They are all in the family of green/yellow colors.
Piece C, as shown in Figure 68, is the least stable from all the pieces. This
piece has not only the uctuations in key than Piece B has, but also a wider range
of keys visited that Piece B. Notice that the range of colors in Figure 68 is rather
wide.
Discussion
This visualization method is similar in its approach to work by Sapp [Sapp 2001].
An example of Sapps visualization was presented in 43. Our approach is dierent
from Sapps approach in that we display each segment independently as colored
discs. Also, our visualization is in a circular formation that allows for easier com-
parisons across levels. A drawback of the circular formation is that it is not an
exact model of music. This conguration gives the inaccurate impression that the
end of a piece is followed by the beginning. On the other hand, this circular for-
mation provides a certain degree of exibility by utilizing the power of rotation.
For example, consider Piece A with the following sequence of keys: A Minor, C
114
Major, G Major, G Major and Piece B with the following sequence of keys: G
Major, A Minor, C Major, G Major. While in a linear formation the sequence of
keys for Pieces A and B may seem quite dierent, a circular formation would reveal
that a rotation of the sequence of Piece B would result in the sequence of Piece
A. Another advantage of the circular formation is that higher levels that contain
ner grain data are shown on the outer rings. This fanning-out of the data in the
circular formation provides a clearer picture of the details of the higher levels over
a linear formation.
115
Chapter 8: Conclusion
The work presented here can be subdivided into two main areas of focus: quantify-
ing the degree of similarity between pieces of music and visualizations of music. We
present here an overview of our work in music similarity followed by an overview
of our work on music visualization. We conclude with our plans for future work in
both areas.
Music Similarity
This section provides a review of our work on music similarity assessment. We
have developed levels of music similarity that help to clarify the confusion about
the meaning of similarity. We have used these levels as guidelines in our work.
They have helped us in devising methods, selecting data sets, and determining the
scope and application of our methods.
We have developed four methods of similarity assessment. Method PD gener-
ates a pitch class distribution feature and compares the pitch class distributions
of two pieces to obtain a distance measure. The remainder of the methods rst
segment a piece into a given number of uniform time slices, and determine the key
for each slice. Method SA uses the sequence of keys of two pieces and generates a
distance measure by using a sequence alignment algorithm. For Method KD, we
116
use the sequence of keys to generate a key distribution feature. We compare the
key distributions of two pieces to obtain a distance measure. For Method KMD,
we use the sequence of keys to generate a mean-time-in-key distribution feature.
We compare pairs from the key and mean-time-in-key distributions of two pieces
to obtain a distance measure.
We have conducted two sets of experiments using Methods PD, SA, KD and
KMD. The rst experiment considers the second level of similarity which contains
dierent renditions of a piece. The data set for this experiment contains a total
of 172 sets of renditions with a total of 662 pieces. We used all four methods to
compare all the pieces in the data set to one another. We split the results into two
groups (Group S contains the results for the comparison of similar pieces while
Group D contains the results for the comparison of dierent pieces) and conducted
extensive statistical analysis on the results. A quantile-quantile plot [Chambers
et al. 1983] and a Kolmogorov-Smirnov test [Conover 1980] conrmed that Groups
S and D come from dierent underlying distributions for Methods PD, SA, KD,
and KMD. A Mann-Whitney rank sum test [Conover 1980] conrmed that Groups
S and D come from distributions with dierent medians for all the methods. We
calculated Type I and Type II errors for all the methods, as shown in Table .
For all the methods, we also calculated the probability that a randomly selected
comparison with a value less than a cuto belongs to Group S (P(A|B)). We also
calculated the converse probability that a randomly selected comparison with a
value greater than or equal to a cuto belongs to Group D (P(A
|B
)). These
probabilities are summarized in Table 8.2.
The second experiment considers the third level of similarity which contains
dierent variations of a piece. The data set for this experiment contains a total of
71 sets of variations with a total of 711 pieces. We used all four methods to compare
117
Method Type I Error Type II Error
Method PD 1.02% 2.29%
Method SA 3.97% 12.24%
Method KD 4.73% 15.22%
Method KMD 6.59% 14.37%
Table 15: Type I and Type II Errors for Methods PD, SA, KD and KMD Using
the Renditions Data
Method P(A|B) P(A
|B
)
Method PD 45.29% 99.98%
Method SA 16.04% 99.89%
Method KD 13.40% 99.86%
Method KMD 10.09% 99.87%
Table 16: Probabilities for Methods PD, SA, KD and KMD Using the Renditions
Data
all the pieces in the data set to one another. We split the results into Groups S and
D again and conducted extensive statistical analysis on the results. A quantile-
quantile plot [Chambers et al. 1983] and a Kolmogorov-Smirnov test [Conover 1980]
conrmed that Groups S and D come from dierent underlying distributions for
Methods PD, SA, KD, and KMD. A Mann-Whitney rank sum test [Conover 1980]
conrmed that Groups S and D come from distributions with dierent medians for
all the methods. We calculated Type I and Type II errors for all the methods, as
shown in Table 8.3. For all the methods, we also calculated the probability that
a randomly selected comparison with a value less than a cuto belongs to Group
S (P(A|B)). We also calculated the converse probability that a randomly selected
comparison with a value greater than or equal to a cuto belongs to Group D
(P(A
|B
)). These probabilities are summarized in Table 8.4.
For both experiments, we did further analysis to determine the optimal value for
the segmentation parameter for Methods SA, KD and KMD. The segmentation
parameter determines the number of slices to segment pieces into. We dened
118
Method Type I Error Type II Error
Method PD 20.32% 15.68%
Method SA 15.36% 27.92%
Method KD 11.54% 25.49%
Method KMD 12.97% 24.35%
Table 17: Type I and Type II Errors for Methods PD, SA, KD and KMD Using
the Variations Data
Method P(A|B) P(A
|B
)
Method PD 7.70% 99.61%
Method SA 8.62% 99.34%
Method KD 11.48% 99.42%
Method KMD 10.49% 99.44%
Table 18: Probabilities for Methods PD, SA, KD and KMD Using the Variations
Data
optimality as the minimization of the sum of Type I and Type II errors. Table 8.5
displays the optimal values of the segmentation parameter.
Method Renditions Exp. Variations Exp.
Method SA 87 45
Method KD 15 45
Method KMD 9 45
Table 19: Segmentation Parameter Size for Methods SA, KD and KMD
We also considered the performance of Methods PD, SA, KD, and KMD on the
two data sets. We determined that for the rst experiment, Method PD returns
the lowest Type I, Type II and Total errors. For the second experiment, Method
KD returns the lowest Type I error, Method PD returns the lowest Type II error
and Methods PD, KD and KMD return the lowest Total error. We also determined
that all the methods perform better with the rst data set than with the second.
These ndings are in agreement with our initial claims that the methods developed
would have a success rate that increases as the denition of similarity becomes more
specic.
119
Music Visualization
This section reviews our work on music visualization. We have developed a
dynamic music visualization system as well as a static aggregate visualization that
may be used in conjunction with the dynamic visualization.
The dynamic visualization displays the progression of the tonal content of a
music piece. We begin by segmenting a piece into uniform time slices, and deter-
mining the key for each slice. The sequence of keys is then mapped onto a 2D
space that contains points representing all possible keys. The distribution of keys
of a piece being visualized is indicated as growing colored discs, where the colors
correspond to the keys detected, and the size of the discs to the key frequency. This
type of visualization is an improvement over more basic diagrams since it expands
and adds richness to the simple histogram representation through an increase in
dimensionality, addition of color, and animation. These improvements help to
maintain standards of information design.
The dynamic visualization system is a successful translation of music onto a
visual space. We illustrate this by considering the invariance of the visualization
under certain transformations that do not alter our recognition of music. They
include: pitch translation, octave translation, time scaling, and time translation.
We show that the visualization remains intact under the musical changes.
We demonstrate the dynamic visualization system using two music genres. We
consider classical and Armenian music. Classical music tends to follow a pattern
of beginning in the key of the piece, traveling to neighboring keys throughout the
course of the piece before returning to the key of the piece in the end. In contrast,
Armenian music follows a more sequential pattern where the piece begins in a key,
remains there for a period of time before moving on to other keys. It rarely ends in
120
the key it rst visited. We use the visualization method to illustrate these patterns
for a total of 28 classical and 28 Armenian pieces.
We have also developed a static aggregate visualization system. This visualiza-
tion allows a user to get a quick-glance overview of the dynamic visualization of a
piece segmented into many slices. This new visualization method can be loosely
thought of as the aerial view of the dynamic visualization system. Each piece
of music is characterized by a description tree that summarizes its tonality for
every segment at each hierarchical level. The rst level contains the key of the
entire piece, the second level contains the keys of the two halves of the piece, and
so on. The visualization is generated using this tree of keys. It is in a circular
organic formation. We illustrate the usefulness of this visualization through several
examples.
Future Work
In this section, we consider a number of possible extensions to our work. These
extensions span both areas of music similarity and music visualization. Our rst
extension deals with data. While we have bypassed the problem of collecting data
for which there is agreement about similarity by dening the levels of similarity,
our data sets of renditions and variations are certainly not all encompassing of
available data. Our methods of similarity assessment and their evaluation would
be improved with the addition of new data. While collecting new data is always
a possibility, it is a challenge since there is a limited number of pieces that are
available for use. We also propose an additional approach to the evaluation of
our methods that does not require additional data. We plan to use a jackkning
approach which will allow us to utilize our current limited data set. Jackkning can
121
be used to estimate the bias and standard error in a statistic by using a random
sample of observations to calculate it. The statistic estimate is systematically
recomputed by leaving out one observation at a time from the sample [Sprent
1989].
In our evaluations of the proposed music similarity assessment methods, we
selected the segmentation parameter values and the analysis cuto points by min-
imizing the sum of the Type I and Type II errors. Instead of minimizing the sum
of Type I and Type II errors, we propose an alternative of selecting values that
make Type I and Type II errors equal. This alternate approach addresses the fact
that currently, most of the methods result in skewed errors with a higher Type II
error than a Type I error.
We also plan to modify Method KMD. Recall that this method of similar-
ity assessment calculates a distance value by computing the Euclidean distance
between pairs of key and mean-time-in-key distributions. One problem with this
approach is that the two distributions are on dierent scales. This results in the
key distribution overpowering the mean-time-in-key distribution. We propose nor-
malizing both distributions as a way to transpose them to the same scale.
Lastly, recall that we illustrated the behavior of the dynamic music visualization
using classical music and traditional Armenian music. In future work, we plan
to expand this type of analysis to additional genres and music categories. Also
note that further research will need to be conducted to verify that key analysis is
meaningful for Armenian music. We must determine whether Armenian music is
based on the tonal concepts that dene the idea of key.
122
References
Aucouturier, J.J. & Pachet, F. (2002). Music Similarity Measures: Whats the Use?
In Proceedings of the International Symposium on Music Information Retrieval .
Bamberger, J. (2000). Developing Musical Intuitions: A Project-Based Introduction
to Making and Understanding Music. Oxford University Press.
Baxevanis, A. & Ouellette, B. (2001). Bioinformatics: A Practical Guide to the
Analysis of Genes and Proteins. John Wiley and Sons, Inc.
Britannica, E. (2007). Encyclopedia Britannica. www.britannica.com.
Chambers, J., Cleveland, W., Kleiner, B. & Tukey, P. (1983). Graphical Methods
for Data Analysis. Chapman and Hall.
Chew, E. (2000). Towards a Mathematical Model of Tonality. Ph.D. thesis, Mas-
sachusetts Institute of Technology.
Chew, E. (2001). Modeling Tonality: Applications to Music Cognition. In Proceed-
ings of the Annual Meeting of the Cognitive Science Society.
Chew, E. & Chen, Y.C. (2002). Mapping MIDI to the Spiral Array: Disambiguat-
ing Pitch Spellings. In Computational Modeling and Problem Solving in the Net-
worked World - Proceedings of the 8th INFORMS Computer Society Conference.
Chew, E. & Chen, Y.C. (2005). Real Time Pitch Spelling Using the Spiral Array.
Computer Music Journal .
Chew, E. & Francois, A. (2005). Interactive Multi-Scale Visualizations of Tonal
Evolution in MuSA.RT Opus 2. Newton Lee (ed.): Special Issue on Music Visu-
alization and Education, ACM Computers in Entertainment.
Chew, E., Volk, A. & Lee, C.Y. (2005). Dance Music Classication Using Inner
Metric Analysis A Computational Approach and Case Study Using 101 Latin
American Dances and National Anthems. In The Next Wave in Computing,
Optimization, and Decision Technologies, Operations Research/Computer Sci-
ence Interfaces, Springer.
123
Chuan, C.H. & Chew, E. (2005). Fuzzy Analysis in Pitch Class Determination for
Polyphonic Audio Key Finding. In Proceedings of the International Conference
on Music Information Retrieval .
Cli, D. & Freeburn, H. (2000). Exploration of Point-Distribution Models for
Similarity-based Classication and Indexing of Polyphonic Music. In Proceed-
ings of the International Symposium on Music Information Retrieval .
Cohn, R. (1997). Neo-Riemannian Operations, Parsimonious Trichords, and Their
Tonnetz Representations. Journal of Music Theory.
Cole, R. (2007). Virginia Tech Multimedia Music Dictionary.
www.music.vt.edu/musicdictionary.
Conover, W. (1980). Practical Nonparametric Statistics. John Wiley and Sons, Inc.
DigiDesign (2007). Digidesign. www.digidesign.com.
Dorrell, P. (2005). What Is Music? Solving a Scientic Mystery. Phillip Dorrell.
Downie, S. (2003). Toward the Scientic Evaluation of Music Information Retrieval
Systems. In Proceedings of the International Symposium on Music Information
Retrieval .
Downie, S. (2005). 1st Annual Music Information Retrieval Evaluation eXchange.
www.music-ir.org/mirex2005.
Foote, J. & Cooper, M. (2001). Visualizing Musical Structure and Rhythm via Self-
Similarity. In Proceedings of the International Conference on Computer Music.
Gomez, E. & Bonada, J. (2005). Tonality Visualization of Polyphonic Audio. In
Proceedings of the International Computer Music Conference.
Haus, G. & Pollastri, E. (2001). An Audio Front End for Query-by-Humming
Systems. In Proceedings of the International Symposium on Music Information
Retrieval .
Herre, J., Allamanche, E. & Ertel, C. (2003). How Similar Do Songs Sound?
Towards Modeling Human Perception of Musical Similarity. In Proceedings of
the IEEE International Workshop on Applications of Signal Processing to Audio
and Acoustics.
Hewlett, W. (2007). MuseData. www.musedata.org.
Hofmann-Engl, L. (2001). Towards a Cognitive Model of Melodic Similarity. In
Proceedings of the International Symposium on Music Information Retrieval .
124
Hofmann-Engl, L. (2002). Rhythmic Similarity: A Theoretical and Empirical
Approach. In Proceedings of the International Conference on Music Perception
and Cognition.
Hu, N., Dannenberg, R. & Lewis, A. (2002). A Probabilistic Model of Melodic
Similarity. In Proceedings of the International Computer Music Conference.
Kleinberg, J. & Tardos, E. (2005). Algorithm Design. Addison Wesley.
Krumhansl, C. (1990). Cognitive Foundations of Musical Pitch. Oxford University
Press.
Langer, J. & Goebl, W. (2003). Visualizing Expressive Performance in Tempo-
Loudness Space. Computer Music Journal .
Lerdahl, F. (2001). Tonal Pitch Space. Oxford University Press.
Longuet-Higgins, H. & Steedman, M. (1971). On Interpreting Bach. In Machine
Intelligence.
Lubin, S. (1974). Techniques for the Analysis of Development in Middle-Period
Beethoven. Ph.D. thesis, New York University.
Malinowski, S. (2007). Music Animation Machine. www.musanim.com.
Mardirossian, A. & Chew, E. (2005a). Key Distributions as Musical Fingerprints
for Similarity Assessment. In Proceedings of the IEEE International Workshop
on Multimedia Information Processing and Retrieval .
Mardirossian, A. & Chew, E. (2005b). SKeFiS - a Symbolic (MIDI) Key Finding
System. In Extended Abstracts of the 1st Annual Music Information Retrieval
Evaluation eXchange.
Mardirossian, A. & Chew, E. (2006). Music Summarization Via Key Distribu-
tions: Analyses of Similarity Assessment Across Variations. In Proceedings of
the International Conference on Music Information Retrieval .
Merriam-Webster (2007). Merriam-Webster Online Dictionary. www.m-w.com.
Misra, A., Wang, G. & Cook, P.R. (2005). sndtools: Real-Time Audio DSP and 3D
Visualization. In Proceedings of the International Computer Music Conference.
Muradian, H. (2007). Armenian MIDI. www.armenianbizdirectory.com/himidi.html.
Pampalk, E. (2006). Computational Models of Music Similarity and Their Appli-
cation in Music Information Retrieval . Ph.D. thesis, Vienna University of Tech-
nology.
125
Paulus, J. & Klapuri, A. (2002). Measuring the Similarity of Rhythmic Patterns.
In Proceedings of the International Symposium on Music Information Retrieval .
Pickens, J. (2004). Harmonic Modeling for Polyphonic Music Retrieval . Ph.D.
thesis, University of Massachusetts Amherst.
Pickens, J. & Crawford, T. (2002). Harmonic Models for Polyphonic Music
Retrieval. In Proceedings of the ACM Conference in Information Knowledge and
Management.
Sapp, C. (2001). Harmonic Visualizations of Tonal Music. In Proceedings of the
International Computer Music Conference.
Schwob, P. (2007). Classical Music Archives. www.classicalarchives.com.
Sprent, P. (1989). Applied Nonparametric Statistical Methods. Chapman and Hall.
Toiviainen, P. & Krumhansl, C. (2003). Measuring and Modeling Real-Time
Responses to Music: The Dynamics of Tonality Induction. Perception.
Tufte, E. (1990). Envisioning Information. Graphics Press.
Typke, R., Giannopoulos, P., Veltkamp, R., Wiering, F. & van Oostrum, R. (2003).
Using Transportation Distances for Measuring Melodic Similarity. In Proceedings
of the International Symposium on Music Information Retrieval .
Tzanetakis, G. & Cook, P. (2000). MARSYAS: A Framework for Audio Analysis.
Organised Sound.
Tzanetakis, G., Ermolinskyi, A. & Cook, P. (2003). Pitch Histograms in Audio
and Symbolic Music Information Retrieval. Journal of New Music Research.
Uitdenbogerd, A. & van Schyndel, R. (2002). A Review of Factors Aecting Music
Recommender Success. In Proceedings of the International Symposium on Music
Information Retrieval .
Unal, E., Narayanan, S., Shih, M.H., Chew, E. & Kuo., C.C. (2005). Creating
Data Resources for Designing User-centric Front-ends for Query by Humming
Systems. ACM Multimedia Systems Journal, Special Issue on Music Information
Retrieval .
Wattenberg, M. (2007). The Shape of Song. www.turbulence.org/Works/song.
126
You might also like
- Hotelreviewreshelpfulnesslo Lo Var InclzeroDocument2 pagesHotelreviewreshelpfulnesslo Lo Var InclzerosommukhNo ratings yet
- Ac SignalingDocument30 pagesAc SignalingsommukhNo ratings yet
- Section 6 Is Far Too LongDocument1 pageSection 6 Is Far Too LongsommukhNo ratings yet
- 214.7 (MH)Document6 pages214.7 (MH)sommukhNo ratings yet
- Chan Jeliazkov 2009Document20 pagesChan Jeliazkov 2009sommukhNo ratings yet
- Consumer Learning From Online ReviewsDocument17 pagesConsumer Learning From Online ReviewssommukhNo ratings yet
- Xtsur HelpDocument5 pagesXtsur HelpsommukhNo ratings yet
- Gibbs Regime 2Document5 pagesGibbs Regime 2sommukhNo ratings yet
- A Multivariate Probit Model For Inferring Missing Haplotype/genotype DataDocument31 pagesA Multivariate Probit Model For Inferring Missing Haplotype/genotype DatasommukhNo ratings yet
- "C://mvnprob - Dat1" "C://mvnprob - Dat1": Inf InfDocument2 pages"C://mvnprob - Dat1" "C://mvnprob - Dat1": Inf InfsommukhNo ratings yet
- Brian Neelon R ProgramsDocument3 pagesBrian Neelon R ProgramssommukhNo ratings yet
- Brief Review of Literature and Identification of Some Key Research QuestionsDocument5 pagesBrief Review of Literature and Identification of Some Key Research QuestionssommukhNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Beat 182 03-2021 ENDocument100 pagesBeat 182 03-2021 ENBeatzShack OfficialNo ratings yet
- Finale Quick Reference Guide For MacintoshDocument40 pagesFinale Quick Reference Guide For Macintosh14GroganNo ratings yet
- 480L V4 Owners ManualDocument150 pages480L V4 Owners ManualJayBezusNo ratings yet
- Pa500ORT FactoryDataDocument40 pagesPa500ORT FactoryDatacdiazr01No ratings yet
- SP3 Manual Rev ADocument136 pagesSP3 Manual Rev ASantos RafaelNo ratings yet
- A Live Performance System in Pure Data: Pitch Contour As Figurative GestureDocument10 pagesA Live Performance System in Pure Data: Pitch Contour As Figurative Gesturerickygraham2009100% (1)
- How To Stream Your TRAKTOR Performance To YouTube Live or Twitch - Native InstrumentsDocument16 pagesHow To Stream Your TRAKTOR Performance To YouTube Live or Twitch - Native InstrumentsgvaNo ratings yet
- GEM GM-X Owners ManualDocument24 pagesGEM GM-X Owners ManualsevcsaNo ratings yet
- Heavier7Strings-1.2.0 User ManualDocument66 pagesHeavier7Strings-1.2.0 User ManualemanuelNo ratings yet
- Geist ManualDocument92 pagesGeist Manuallionpaw2012No ratings yet
- FCB1010 Manual PDFDocument17 pagesFCB1010 Manual PDFhwfitzjrNo ratings yet
- The Complete Guide For EWQLSODocument109 pagesThe Complete Guide For EWQLSOSkribahNo ratings yet
- HansZimmerPercussion UserManualDocument19 pagesHansZimmerPercussion UserManualhogarNo ratings yet
- Quadraverb Plus EFTP Manual LatestDocument15 pagesQuadraverb Plus EFTP Manual LatestDarren Whiteley100% (2)
- Yamaha P-95 PDFDocument36 pagesYamaha P-95 PDFKarlStewartNo ratings yet
- Spark ManualDocument31 pagesSpark ManualMaria MartinezNo ratings yet
- Rhythm Converter ManualDocument21 pagesRhythm Converter ManualVinciane BaudouxNo ratings yet
- Roland JV-1080 Patches Soundset (Don Solaris)Document21 pagesRoland JV-1080 Patches Soundset (Don Solaris)CirrusStratusNo ratings yet
- Roland GR-55 FLOORBOARD - HELP - 1502251Document118 pagesRoland GR-55 FLOORBOARD - HELP - 1502251marinrebic100% (1)
- DJ-1800 User ManualDocument66 pagesDJ-1800 User ManualMarian GiNo ratings yet
- Genny DocumentationDocument17 pagesGenny Documentationgeorgerkid gaming the hedgehog100% (1)
- JV-2080 Patch List CommentsDocument9 pagesJV-2080 Patch List Commentsanon_940987082No ratings yet
- Studio One 6.0 Reference Manual en 05012023Document520 pagesStudio One 6.0 Reference Manual en 05012023Thiago Ferraz100% (1)
- Trademarks: Mainboard User's ManualDocument39 pagesTrademarks: Mainboard User's Manualhenry barbozaNo ratings yet
- Fractal Audio Footswitch Functions Guide PDFDocument22 pagesFractal Audio Footswitch Functions Guide PDFerikNo ratings yet
- Irig Pro IO User ManualDocument14 pagesIrig Pro IO User ManualAnyelo Rojas CórdovaNo ratings yet
- 2.manual Roland G-800Document282 pages2.manual Roland G-800Viorel AldeaNo ratings yet
- 2012DJTechCatalog SDocument80 pages2012DJTechCatalog SdjdwNo ratings yet
- Latest Equipment CompilationDocument7 pagesLatest Equipment CompilationRoger WehbeNo ratings yet
- Cakewalk - Access Z3ta+ - Virus TI VSTi v1Document5 pagesCakewalk - Access Z3ta+ - Virus TI VSTi v1homereqNo ratings yet