You might also like
- Modelo Vista ControladorDocument3 pagesModelo Vista Controladorlaureano100% (4)
- Diagramas de Casos de Uso - Universidad de AlcaláDocument4 pagesDiagramas de Casos de Uso - Universidad de AlcaláAntonio VarelaNo ratings yet
- Análisis y Diseño de Un Caso de UsoDocument11 pagesAnálisis y Diseño de Un Caso de Usolunati luna100% (13)
- Descripciones de Casos de UsoDocument7 pagesDescripciones de Casos de Usofedepiecho100% (3)
- Requerimientos Del:usuario, Sitemas, FuncionalesDocument7 pagesRequerimientos Del:usuario, Sitemas, Funcionaleslaureano100% (5)
- Plantilla de Caso de PruebasDocument6 pagesPlantilla de Caso de PruebaslaureanoNo ratings yet
- Manual de SQLDocument44 pagesManual de SQLRaul98% (54)
- Arreglo UnidimensionalDocument2 pagesArreglo UnidimensionallaureanoNo ratings yet
- Graficos Lattice PDFDocument7 pagesGraficos Lattice PDFYossNo ratings yet
- Convertidor 24 A 12vcdDocument15 pagesConvertidor 24 A 12vcdenriquevazquez27No ratings yet
- Taller de Informática CuestionarioDocument7 pagesTaller de Informática CuestionarioleNo ratings yet
- Ejemplo Analisis Pestel Con Una Empresa en El Edo de MexicoDocument2 pagesEjemplo Analisis Pestel Con Una Empresa en El Edo de MexicoEsk SosaNo ratings yet
- Manual Del Supervisor CleaverDocument5 pagesManual Del Supervisor Cleaveradrian del angelNo ratings yet
- X Eeeeeeeeeee Eeeeeeeeeeeeeee Eeeeeeeeeeeeeee EeeeeeeeeeeeeeeDocument5 pagesX Eeeeeeeeeee Eeeeeeeeeeeeeee Eeeeeeeeeeeeeee EeeeeeeeeeeeeeeLuis Arturo CachiNo ratings yet
- Guia Basica para Hacer Instalaciones Electricas ResidencialesDocument13 pagesGuia Basica para Hacer Instalaciones Electricas Residencialesjesus_guedezNo ratings yet
- Introducción A La InformáticaDocument73 pagesIntroducción A La Informáticamaferwong120No ratings yet
- Manual Fiat DobloDocument218 pagesManual Fiat Dobloloboden2571% (7)
- Tez Sonido Catálogo Tarifa 2018Document58 pagesTez Sonido Catálogo Tarifa 2018VEMATELNo ratings yet
- TVS Max-Zt-125Document72 pagesTVS Max-Zt-125Alex Rivera33% (3)
- Perdida en Una Red de Fibra ÓpticaDocument6 pagesPerdida en Una Red de Fibra ÓpticaLuis VelascoNo ratings yet
- Requisitos de Los Sistemas de InformacionDocument5 pagesRequisitos de Los Sistemas de InformacionsantiagoNo ratings yet
- Laboratorio 06Document11 pagesLaboratorio 06Gonzalo Barrios Amesquita0% (1)
- Linea Del Tiempo Revolución TecnológicaDocument2 pagesLinea Del Tiempo Revolución TecnológicaDNo ratings yet
- Programa - Asignatura (Hardware I)Document4 pagesPrograma - Asignatura (Hardware I)GonzaloNo ratings yet
- ContactenosDocument1 pageContactenosfernando yanezNo ratings yet
- Manual ELSAWIN (Instalación)Document2 pagesManual ELSAWIN (Instalación)JannsbNo ratings yet
- Actividad Evaluativa - Eje 3 Informatica Forense IDocument11 pagesActividad Evaluativa - Eje 3 Informatica Forense IrybkingNo ratings yet
- Presupuesto para Los Eventos de CapacitacionDocument4 pagesPresupuesto para Los Eventos de CapacitacionMariza BritoNo ratings yet
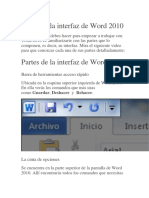
- Partes de La Interfaz de Word 2010Document14 pagesPartes de La Interfaz de Word 2010Walakitang Alto WankyNo ratings yet
- Embebidos Hoja Guia 1 2020BDocument3 pagesEmbebidos Hoja Guia 1 2020BJonathan Fernando SfNo ratings yet
- Sequent Plug Drive Manual Software - BRC - Alberdi GNCDocument48 pagesSequent Plug Drive Manual Software - BRC - Alberdi GNCeckyz100% (1)
- Sílabo Herramientas Informaticas 2023 - Puente PiedraDocument165 pagesSílabo Herramientas Informaticas 2023 - Puente Piedra♡Bₒₜₛᵢₜₒ♡No ratings yet
- Guia de Aprendizaje 3Document9 pagesGuia de Aprendizaje 3J09 DiazNo ratings yet
- LR 1100 SP - 8061-0 PDFDocument32 pagesLR 1100 SP - 8061-0 PDFanmec20100% (1)
- Evolución de Los ProcesadoresDocument8 pagesEvolución de Los Procesadoresdavid lopezNo ratings yet
- Cambio Pantalla c111 RocheDocument10 pagesCambio Pantalla c111 Rochebrahim escobar ismaelNo ratings yet
- Solucion ObjectBrowser CelularesDocument12 pagesSolucion ObjectBrowser CelularesFerchu BalboaNo ratings yet
- Herramientas Que Aseguran Dispositivos Finales Con WindowsDocument3 pagesHerramientas Que Aseguran Dispositivos Finales Con WindowsMartin MendezNo ratings yet