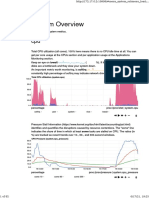
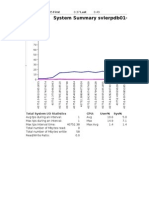
You might also like
- Autosys Cheat Sheet From CADocument4 pagesAutosys Cheat Sheet From CAwaltert1No ratings yet
- System Administrator Interview Cheat SheetDocument273 pagesSystem Administrator Interview Cheat Sheettaintd_luv2k43947100% (1)
- Ms Dynamics Nav Peformance Testing WPDocument23 pagesMs Dynamics Nav Peformance Testing WPgopihcNo ratings yet
- VmstatDocument3 pagesVmstatDanish InamdarNo ratings yet
- 20 Linux System Monitoring Tools Every SysAdmin Should KnowDocument69 pages20 Linux System Monitoring Tools Every SysAdmin Should Knowrajan21india5986No ratings yet
- 10 Useful Sar (Sysstat) Examples For UNIX - Linux Performance Monitoring PDFDocument16 pages10 Useful Sar (Sysstat) Examples For UNIX - Linux Performance Monitoring PDFsmarty4you9205No ratings yet
- Performance Tuning Basic Bejjanky Naresh KumarDocument36 pagesPerformance Tuning Basic Bejjanky Naresh Kumaranil0486100% (2)
- 20 Linux System Monitoring Tools Every SysAdmin Should KnowDocument35 pages20 Linux System Monitoring Tools Every SysAdmin Should KnowJin ZoongNo ratings yet
- 20 Linux System Monitoring Tools Every SysAdmin Should KnowDocument14 pages20 Linux System Monitoring Tools Every SysAdmin Should Knownareshram469No ratings yet
- Solaris Performance MonitoringDocument8 pagesSolaris Performance Monitoringsuresha2luNo ratings yet
- 20 Linux System Monitoring Tools Every SysAdmin Should KnowDocument13 pages20 Linux System Monitoring Tools Every SysAdmin Should KnowNnaemeka OkafoNo ratings yet
- Hunting Down CPU Related Issues With Oracle: A Functional ApproachDocument9 pagesHunting Down CPU Related Issues With Oracle: A Functional ApproachphanithotaNo ratings yet
- Perfromance Tuning-5Document4 pagesPerfromance Tuning-5Prasad KalumuNo ratings yet
- Monitoring Hardware ST06 Operating System Overview SM51 Analyzing CPU and Paging ST06Document14 pagesMonitoring Hardware ST06 Operating System Overview SM51 Analyzing CPU and Paging ST06Amit GandhiNo ratings yet
- Linuxperftools 140820091946 Phpapp01Document85 pagesLinuxperftools 140820091946 Phpapp01api-265708564No ratings yet
- 12 Iostat Examples For Solaris Performance TroubleshootingDocument5 pages12 Iostat Examples For Solaris Performance Troubleshootingshekhar785424No ratings yet
- AIX For System Administrators - PerformanceDocument3 pagesAIX For System Administrators - Performancedanielvp21No ratings yet
- 3 ControleDocument18 pages3 Controlekousseila kouukouNo ratings yet
- Top Linux Monitoring ToolsDocument38 pagesTop Linux Monitoring ToolsRutch ChintamasNo ratings yet
- System Overview: Total CPU Utilization (System - Cpu)Document82 pagesSystem Overview: Total CPU Utilization (System - Cpu)devProNo ratings yet
- Linux Sys Admin ToolsDocument24 pagesLinux Sys Admin ToolsPaarthi Kannadasan100% (1)
- Alerta SwapDocument2 pagesAlerta SwapJorge ApNo ratings yet
- CPU Bottlenecks in LinuxDocument4 pagesCPU Bottlenecks in LinuxAlonsoNo ratings yet
- How Oracle Uses Memory On AixDocument29 pagesHow Oracle Uses Memory On AixBart Simson100% (1)
- Hacking SAPDocument4 pagesHacking SAP4gen_2No ratings yet
- TestDocument1,528 pagesTestinsatsunnyNo ratings yet
- Troubleshoot A Failing To Start SAP HANA SystemDocument11 pagesTroubleshoot A Failing To Start SAP HANA SystemAdrianNo ratings yet
- Lenteur SSL Palo AltoDocument17 pagesLenteur SSL Palo AltoVivien PrieurNo ratings yet
- Slow Server? This Is The Flow Chart You're Looking For: Get On "Top" of ItDocument5 pagesSlow Server? This Is The Flow Chart You're Looking For: Get On "Top" of ItMatara HarischandraNo ratings yet
- Analyzing Esxtop DataDocument6 pagesAnalyzing Esxtop DataNasron NasirNo ratings yet
- Cpu Bottle Neck Issues NetappDocument10 pagesCpu Bottle Neck Issues NetappSrikanth MuthyalaNo ratings yet
- Size of Oracle Process UnixDocument5 pagesSize of Oracle Process Unixanoop666rNo ratings yet
- It 429 - Week 8&9Document24 pagesIt 429 - Week 8&9mjdcan_563730775No ratings yet
- Aix Jfs2 CacheDocument5 pagesAix Jfs2 CacheliuylNo ratings yet
- 20 Linux System Tool MonitorDocument19 pages20 Linux System Tool MonitorBắp NgọtNo ratings yet
- SAProuter - How To Setup The Saprouter - What Is The SaprouterDocument6 pagesSAProuter - How To Setup The Saprouter - What Is The SaprouterquentinejamNo ratings yet
- Useful UNIX Commands For WebSphereDocument10 pagesUseful UNIX Commands For WebSphereoracleconsultant75No ratings yet
- AIX I/O Performance TuningDocument16 pagesAIX I/O Performance TuningSubbarao AppanabhotlaNo ratings yet
- Unix Commands On Different OSsDocument7 pagesUnix Commands On Different OSsFlorian TituNo ratings yet
- HP TroubleshootingDocument4 pagesHP TroubleshootingvgskhereNo ratings yet
- AIX Performance Tuning: Presentation Current As of 7/9/2012Document37 pagesAIX Performance Tuning: Presentation Current As of 7/9/2012Dean DjordjevicNo ratings yet
- Apsdp1a 2012 05 11 03 22Document16 pagesApsdp1a 2012 05 11 03 22sunil_k919No ratings yet
- DeadlockansDocument11 pagesDeadlockansshini s gNo ratings yet
- DBA Interview Questions With Answers Part8Document13 pagesDBA Interview Questions With Answers Part8anu224149No ratings yet
- Solaris MemoryDocument12 pagesSolaris MemorySuresh SadasivanNo ratings yet
- Cpu Utilisation CommandsDocument7 pagesCpu Utilisation Commandsvijukm2000No ratings yet
- Linux Con 2010 Linux MonitoringDocument44 pagesLinux Con 2010 Linux MonitoringArsalan QureshiNo ratings yet
- Basic Linux Privilege EscalationDocument8 pagesBasic Linux Privilege EscalationAneudy Hernandez PeñaNo ratings yet
- SAS®9 On Solaris 10: The Doctor Is "In" (And Makes House Calls)Document16 pagesSAS®9 On Solaris 10: The Doctor Is "In" (And Makes House Calls)knl.sundeepNo ratings yet
- Operating Systems Lab - DR - Maheswari RDocument68 pagesOperating Systems Lab - DR - Maheswari RXYNCNo ratings yet
- Top 4 Reasons For Node EvictionDocument4 pagesTop 4 Reasons For Node EvictionIan HughesNo ratings yet
- RAID-0 (Stripe) On Solaris 10 Using Solaris Volume ManagerDocument7 pagesRAID-0 (Stripe) On Solaris 10 Using Solaris Volume ManagerazkarashareNo ratings yet
- AIX Commands and Tools For DB2 Troubleshooting AIX Solaris HPUX UNIX Linux System Storage Administration KSH - Perl ScriptingDocument19 pagesAIX Commands and Tools For DB2 Troubleshooting AIX Solaris HPUX UNIX Linux System Storage Administration KSH - Perl Scriptingsunny09meNo ratings yet
- Hpux Interview QuestionsDocument8 pagesHpux Interview QuestionsKuldeep Kushwaha100% (1)
- Auto MountDocument10 pagesAuto MountKrishna ForuNo ratings yet
- DRBD-Cookbook: How to create your own cluster solution, without SAN or NAS!From EverandDRBD-Cookbook: How to create your own cluster solution, without SAN or NAS!No ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- The Computer User's Survival Handbook: Why Is My Computer Slow?From EverandThe Computer User's Survival Handbook: Why Is My Computer Slow?No ratings yet
- Dumpstate LogDocument31 pagesDumpstate LogMary Lopez DiazNo ratings yet
- HP UX General PDFDocument64 pagesHP UX General PDFTHYAGARAJANNo ratings yet
- LoadRunner NotesDocument36 pagesLoadRunner NotessrujanNo ratings yet
- LSF Users GuideDocument53 pagesLSF Users GuideSav SuiNo ratings yet
- FDMEE Sizing Guide FinalDocument16 pagesFDMEE Sizing Guide FinalDeva RajNo ratings yet
- System Monitoring StepsDocument18 pagesSystem Monitoring StepsKishore KumarNo ratings yet
- Managing Memory in SASDocument17 pagesManaging Memory in SASboggalaNo ratings yet
- Performance Tuning Document Um ApplicationsDocument11 pagesPerformance Tuning Document Um Applicationsschnoodle3No ratings yet
- Application Performance Measurement and Analysis Made Easier and More AutomaticDocument4 pagesApplication Performance Measurement and Analysis Made Easier and More Automaticscribd-itNo ratings yet
- Building MySQL Infrastructure For Performance and ReliabilityDocument43 pagesBuilding MySQL Infrastructure For Performance and Reliabilityikke den dikkeNo ratings yet
- Linux Performance Tuning and PerformanceDocument13 pagesLinux Performance Tuning and Performanceshameer100% (4)
- Performance Testing Analysis TemplateDocument18 pagesPerformance Testing Analysis TemplatejenadebisankarNo ratings yet
- Monitor Qlik Sense SitesDocument43 pagesMonitor Qlik Sense SitesLucki Alan Fernandez SalcedoNo ratings yet
- How To Sos ReportDocument6 pagesHow To Sos ReportMary Rose LayagueNo ratings yet
- 20 Linux System Monitoring Tools Every SysAdmin Should KnowDocument69 pages20 Linux System Monitoring Tools Every SysAdmin Should Knowrajan21india5986No ratings yet
- INFA NotesDocument161 pagesINFA NotesPradeep KothakotaNo ratings yet
- Best Practices: Performance Monitoring in A Data WarehouseDocument51 pagesBest Practices: Performance Monitoring in A Data WarehouseWDNo ratings yet
- Red Hat Enterprise Linux-7-Performance Tuning Guide-en-US PDFDocument115 pagesRed Hat Enterprise Linux-7-Performance Tuning Guide-en-US PDFKleyton Henrique Dos SantosNo ratings yet
- MonitoringDocument8 pagesMonitoringsid_srmsNo ratings yet
- 0806 02 Los5 - UgDocument124 pages0806 02 Los5 - Ugbmds kocakNo ratings yet
- What Activities Need To Be Done in Capacity Planning For A Data Warehouse Consolidation ProjectDocument9 pagesWhat Activities Need To Be Done in Capacity Planning For A Data Warehouse Consolidation ProjectNorica TraicuNo ratings yet
- ZenPack Details Guide 4.1Document172 pagesZenPack Details Guide 4.1cocanaNo ratings yet
- 20 Command Line Tools To Monitor Linux PerformanceDocument23 pages20 Command Line Tools To Monitor Linux PerformanceAldo EnginerNo ratings yet
- Awrrpt 1 21748 21771Document314 pagesAwrrpt 1 21748 21771Malathi SvNo ratings yet
- DB2Monitoring Db2f0e973Document1,137 pagesDB2Monitoring Db2f0e973cdefghNo ratings yet
- A Load Balancing Model Based On Cloud Partitioning For The Public Cloud - DoneDocument4 pagesA Load Balancing Model Based On Cloud Partitioning For The Public Cloud - DoneRaja Rao KamarsuNo ratings yet
- New Pass4itsure Lpi 117-201 Dumps PDF - LPI Level 2 Exam 201Document6 pagesNew Pass4itsure Lpi 117-201 Dumps PDF - LPI Level 2 Exam 201Frank M. DavisNo ratings yet
- Naskah DramaDocument14 pagesNaskah Dramaalfia hafizahNo ratings yet