You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5814)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (844)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Financial Summary of Google's Acquisition of YouTubeDocument4 pagesFinancial Summary of Google's Acquisition of YouTubecmcandrew21No ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Top 40 CRMDocument10 pagesTop 40 CRMSanjeev KumarNo ratings yet
- Daria Aksyuta Portfolio 2015Document33 pagesDaria Aksyuta Portfolio 2015DashaNo ratings yet
- Usability Test: Google Docs and Microsoft WordDocument4 pagesUsability Test: Google Docs and Microsoft WordbrynnelsonNo ratings yet
- Advanced Patient or Elder Fall Detection Based On Movement and Sound DataDocument5 pagesAdvanced Patient or Elder Fall Detection Based On Movement and Sound DataHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Performance EvaluationDocument1 pagePerformance EvaluationHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Affective Text Based Emotion Mining in Social MediaDocument9 pagesAffective Text Based Emotion Mining in Social MediaHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- IRI 12288 Dehradun Kochuveli Weekly SF ExpressDocument1 pageIRI 12288 Dehradun Kochuveli Weekly SF ExpressHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Gnatt Chart: Page 1 of 1 Exported On November 17, 2013 2:38:08 AM PSTDocument1 pageGnatt Chart: Page 1 of 1 Exported On November 17, 2013 2:38:08 AM PSTHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Efficient and Discovery of Patterns in Sequences DataDocument19 pagesEfficient and Discovery of Patterns in Sequences DataHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Sensors: Hierarchical Leak Detection and Localization Method in Natural Gas Pipeline Monitoring Sensor NetworksDocument26 pagesSensors: Hierarchical Leak Detection and Localization Method in Natural Gas Pipeline Monitoring Sensor NetworksHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Cloud Security Using Third Party Auditing and Encryption ServiceDocument37 pagesCloud Security Using Third Party Auditing and Encryption ServiceHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Public Building Monitoring Using GprsDocument3 pagesPublic Building Monitoring Using GprsHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- A Privacy Preservation Model For Facebook-Style Social Network SystemsDocument18 pagesA Privacy Preservation Model For Facebook-Style Social Network SystemsHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Jamming Aware Traffic Allocation For Multiple Path Routing Using Portfolio Selection PDFDocument6 pagesJamming Aware Traffic Allocation For Multiple Path Routing Using Portfolio Selection PDFHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- IEEE Paper CodesDocument1 pageIEEE Paper CodesHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
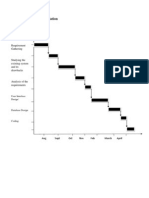
- Planning and FormulationDocument1 pagePlanning and FormulationHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Organizing User Search HistoriesDocument3 pagesOrganizing User Search HistoriesHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- A Novel Method of Spam Mail Detection Using Text Based Clustering ApproachDocument11 pagesA Novel Method of Spam Mail Detection Using Text Based Clustering ApproachHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Select Works of Porphyry Translated by Thomas TaylorDocument299 pagesSelect Works of Porphyry Translated by Thomas TaylorThrice_GreatestNo ratings yet
- Google Apps Directory Sync - Administration GuideDocument150 pagesGoogle Apps Directory Sync - Administration GuideMaxime Morelon100% (1)
- Android 6.0 MarshmallowDocument19 pagesAndroid 6.0 Marshmallowshubham kanojia100% (1)
- Gapps RemoveDocument2 pagesGapps Removesatish mudnoorNo ratings yet
- Etidorhpa or The End of EarthDocument430 pagesEtidorhpa or The End of EarthdipterNo ratings yet
- Skill Checklist - Google Certified Educator Level 1Document6 pagesSkill Checklist - Google Certified Educator Level 1HansOrberg1234No ratings yet
- New Text DocumentDocument15 pagesNew Text DocumentGarima AroraNo ratings yet
- GL Bauer, atDocument242 pagesGL Bauer, atczeNo ratings yet
- Google Initiating CoverageDocument56 pagesGoogle Initiating CoverageStefanoMannaNo ratings yet
- Lom LogDocument18 pagesLom LogMbak InemNo ratings yet
- 246 - 15ec82 - Fon Module 4 - 5Document42 pages246 - 15ec82 - Fon Module 4 - 5Mohammed ZeeshanNo ratings yet
- Google 2016 Environmental ReportDocument72 pagesGoogle 2016 Environmental ReportTechCrunchNo ratings yet
- JWT F100 2017 PDFDocument148 pagesJWT F100 2017 PDFGabriel Enrique Nuñez MendezNo ratings yet
- 20 Great Google SecretsDocument4 pages20 Great Google Secretsmadawa1994No ratings yet
- Jason Spero: With Johanna WertherDocument41 pagesJason Spero: With Johanna WertherVasco MarquesNo ratings yet
- Principles of Psychology, William JamesDocument717 pagesPrinciples of Psychology, William JamesEnzo Cáceres100% (2)
- Lom LogDocument82 pagesLom LogAnderson SouzaNo ratings yet
- Google Mobile Advertising Exam AnswersDocument34 pagesGoogle Mobile Advertising Exam AnswersCertificationAnswersNo ratings yet
- Lom LogDocument84 pagesLom Logiicall4160No ratings yet
- NihongiDocument895 pagesNihongiKauê Metzger OtávioNo ratings yet
- Mighty Curative Powers of Mesmerism (The)Document157 pagesMighty Curative Powers of Mesmerism (The)totheken100% (1)
- ARCHIBUS Room ReservationDocument2 pagesARCHIBUS Room Reservationcatalin2roNo ratings yet
- Automated Ticketing SystemDocument24 pagesAutomated Ticketing SystemUdara SeneviratneNo ratings yet
- ScribdburleDocument5 pagesScribdburleMelira PtacekNo ratings yet
- Exam 1 - English Proficiency-AM-Javines, LilibethDocument2 pagesExam 1 - English Proficiency-AM-Javines, LilibethLi JavinesNo ratings yet
- 1Q 14 VCchart PDFDocument25 pages1Q 14 VCchart PDFBayAreaNewsGroupNo ratings yet