You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (843)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5808)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (346)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Project Proposal On Granite Stone Cutting and Processing FactoryDocument39 pagesProject Proposal On Granite Stone Cutting and Processing FactoryYomnuf Tefera100% (2)
- Corporate FinanceDocument22 pagesCorporate FinanceGeorge Shevtsov80% (5)
- Banking LawsDocument67 pagesBanking LawsPatricia Ann CaubaNo ratings yet
- Itinerary Trip Japan 6-13 Oct 2018 (Final)Document10 pagesItinerary Trip Japan 6-13 Oct 2018 (Final)safanj12No ratings yet
- FANUC IpendantDocument2 pagesFANUC IpendantJenish Macwan100% (1)
- Tyre With Splined Kiln Tyre Fastening System, Type 1Document29 pagesTyre With Splined Kiln Tyre Fastening System, Type 1Rahmat Hidayat100% (1)
- Errata 2008 PDFDocument2 pagesErrata 2008 PDFAtul KumbharNo ratings yet
- The Evaluation of Temporary Earthquake Houses Dismantling Process in The Context of Building Waste ManagementDocument9 pagesThe Evaluation of Temporary Earthquake Houses Dismantling Process in The Context of Building Waste ManagementJohn Rameses BaroniaNo ratings yet
- Long Term FinanceDocument25 pagesLong Term FinanceAr Muhammad RiyasNo ratings yet
- Chapter 3 QuantiDocument5 pagesChapter 3 QuantiChristine NavidadNo ratings yet
- M4S Guideline of ICHDocument115 pagesM4S Guideline of ICHRegulatoryoneNo ratings yet
- Prime Synergie Company Profile 4 InfomediaDocument25 pagesPrime Synergie Company Profile 4 InfomediaUpy EmbaiNo ratings yet
- 212spflyer PDFDocument2 pages212spflyer PDFTulioLopezJNo ratings yet
- Point Supported Glass DetailsDocument2 pagesPoint Supported Glass DetailsKoala BNo ratings yet
- Notice WritingDocument4 pagesNotice Writingharmanpreet kaurNo ratings yet
- Guideline For ERMP - July - 2020 PDFDocument18 pagesGuideline For ERMP - July - 2020 PDFJamal100% (1)
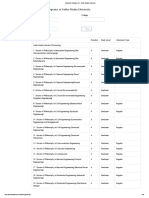
- Program List: Available Programs in Addis Ababa UniversityDocument27 pagesProgram List: Available Programs in Addis Ababa UniversityYohannes Belay (the episode guy)No ratings yet
- Computer Ethics: Instructor: Anam ZaiDocument37 pagesComputer Ethics: Instructor: Anam Zaiayesha ambreenNo ratings yet
- Survey On Use and Library Study Pattern of Electronic Resources Among Under Graduate Students: A StudyDocument10 pagesSurvey On Use and Library Study Pattern of Electronic Resources Among Under Graduate Students: A StudyImpact JournalsNo ratings yet
- Design & Implementation of Patient Monitoring System Using MicrocontrollerDocument9 pagesDesign & Implementation of Patient Monitoring System Using MicrocontrollerBereket Abi Mulugeta100% (1)
- KWHotel Configuration ModuleDocument30 pagesKWHotel Configuration Modulemaclans marketingNo ratings yet
- Merit Testing Service-Pakistan: A Symbol of Merit in Testing and AssessmentDocument2 pagesMerit Testing Service-Pakistan: A Symbol of Merit in Testing and AssessmentMohsiNo ratings yet
- 0205 Multi-User OperationDocument6 pages0205 Multi-User Operationbuturca sorinNo ratings yet
- Six Rules For Writing Clean CodeDocument2 pagesSix Rules For Writing Clean CodenevdullNo ratings yet
- How ClassDojo Reward Points Effect Students' Learning Attitude and Classroom ParticipationDocument14 pagesHow ClassDojo Reward Points Effect Students' Learning Attitude and Classroom ParticipationTerry TungNo ratings yet
- May 2022 - Natural Capital Accounting RoadmapDocument105 pagesMay 2022 - Natural Capital Accounting RoadmapOCENR Legazpi CityR.M.AbacheNo ratings yet
- How To Flash Nokia Phones Using Phoenix Service SoftwareDocument4 pagesHow To Flash Nokia Phones Using Phoenix Service Softwarearticlecms56No ratings yet
- Jan 2023Document20 pagesJan 2023Mohamed TarekNo ratings yet
- Muhammad Javaid Iqbal S/O Muhammad Iqbal Attari Saroba - .: Web Generated BillDocument1 pageMuhammad Javaid Iqbal S/O Muhammad Iqbal Attari Saroba - .: Web Generated BillM Javaid IqbalNo ratings yet
- 2024 - S1 - CFAF05D Study Guide v2Document27 pages2024 - S1 - CFAF05D Study Guide v2Monwa BisiNo ratings yet