You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5809)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (843)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (346)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Current LogDocument7 pagesCurrent LogTate YatesNo ratings yet
- TOGAF 9 Template - Architecture Building BlocksDocument6 pagesTOGAF 9 Template - Architecture Building Blockspiero_zidaneNo ratings yet
- Amity School of Distance Learning Post Box No. 503, Sector-44 Noida - 201303 E-Commerce Assignment A Marks 10 Answer All QuestionsDocument9 pagesAmity School of Distance Learning Post Box No. 503, Sector-44 Noida - 201303 E-Commerce Assignment A Marks 10 Answer All QuestionsseemaNo ratings yet
- Flash Lite 2 GettingstartedDocument42 pagesFlash Lite 2 Gettingstartedapi-3730515100% (2)
- Flash Lite 1 GettingstartedDocument38 pagesFlash Lite 1 Gettingstartedapi-3730515No ratings yet
- Unix Cook BookDocument23 pagesUnix Cook Bookapi-3730515100% (1)
- XintroDocument11 pagesXintroapi-3730515No ratings yet
- InstphpwinDocument7 pagesInstphpwinapi-3730515No ratings yet
- Instphpmyadmin WinDocument6 pagesInstphpmyadmin Winapi-3730515No ratings yet
- Unix IntroDocument4 pagesUnix Introapi-3730515No ratings yet
- Kernel HackingDocument27 pagesKernel HackingSamir Sanchez GarnicaNo ratings yet
- Book FreebsdDocument691 pagesBook Freebsdapi-3774955No ratings yet
- InstmysqlwinDocument17 pagesInstmysqlwinapi-3730515No ratings yet
- InstphpmyadminlinuxDocument6 pagesInstphpmyadminlinuxapi-3730515No ratings yet
- Dev IntroDocument32 pagesDev Introapi-3730515No ratings yet
- InstmysqllinuxDocument21 pagesInstmysqllinuxapi-3730515No ratings yet
- LPI101 Sample TestDocument2 pagesLPI101 Sample Testapi-3730515No ratings yet
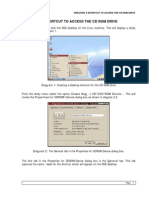
- Add CDROMShortcutsDocument3 pagesAdd CDROMShortcutsapi-3730515No ratings yet
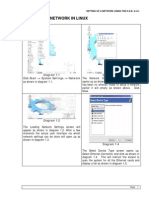
- Setting Up A NetworkDocument7 pagesSetting Up A Networkapi-3730515No ratings yet
- InstfedoraDocument24 pagesInstfedoraapi-3730515No ratings yet
- Rhce SkillsDocument4 pagesRhce SkillsShashiRekhaNo ratings yet
- GCCDocument496 pagesGCCdrgoodenNo ratings yet
- gcc-2 95Document6 pagesgcc-2 95api-3730515No ratings yet
- Codehelp: Lec-4: Components of Os 1. Kernel: A Kernel Is That Part of The Operating System Which Interacts Directly WithDocument2 pagesCodehelp: Lec-4: Components of Os 1. Kernel: A Kernel Is That Part of The Operating System Which Interacts Directly WithMd Aman AtaNo ratings yet
- Iso 27001Document10 pagesIso 27001DummyNo ratings yet
- User Request/Certification of Access Rights Form For Emds (For Agency)Document1 pageUser Request/Certification of Access Rights Form For Emds (For Agency)Philip Jansen GuarinNo ratings yet
- Hotel Reservation SystemDocument15 pagesHotel Reservation SystemVarsha PalNo ratings yet
- ERP Introduction Benefits The Evolution of ERP The Conceptual Model of ERP The Structure of ERPDocument15 pagesERP Introduction Benefits The Evolution of ERP The Conceptual Model of ERP The Structure of ERPSaurabh GuptaNo ratings yet
- Presentation CNPM GROUP 8Document17 pagesPresentation CNPM GROUP 8PeterNo ratings yet
- ArchiMate CookbookDocument55 pagesArchiMate CookbookArie Wibowo Sutiarso100% (1)
- HU21CSEN0100752 DBMS LAB RECORD-compressedDocument53 pagesHU21CSEN0100752 DBMS LAB RECORD-compressedDurgempudi Sri Sai Krishna Reddy 222010323019No ratings yet
- Introduction To Digital Technology Syllabus - OlsonDocument4 pagesIntroduction To Digital Technology Syllabus - Olsonapi-264456676No ratings yet
- Aws MaterialDocument20 pagesAws MaterialSushrata NNo ratings yet
- SAP PM For RetailDocument4 pagesSAP PM For RetailNoppawan BuangernNo ratings yet
- Zimbra Installation On CentOS Step by Step Guide - Part3 CentOS DNS SetupDocument5 pagesZimbra Installation On CentOS Step by Step Guide - Part3 CentOS DNS SetupAsri KamalNo ratings yet
- Download pdf Togaf 9 Foundation Study Guide Preparation For The Togaf 9 Part 1 Examination 4Th Edition Rachel Harrison ebook full chapterDocument54 pagesDownload pdf Togaf 9 Foundation Study Guide Preparation For The Togaf 9 Part 1 Examination 4Th Edition Rachel Harrison ebook full chapterlaura.landrus760No ratings yet
- Sample PIA Template v2Document6 pagesSample PIA Template v2Cyril ArnestoNo ratings yet
- soapUI Pro - Tutorial PDFDocument4 pagessoapUI Pro - Tutorial PDFGangadhar SankabathulaNo ratings yet
- Fortigate Traffic Optimization - Network & Security BlogDocument5 pagesFortigate Traffic Optimization - Network & Security BlogSAGALOGNo ratings yet
- AAA QuestionsDocument3 pagesAAA QuestionsJowel RanaNo ratings yet
- Software Project Management (MCQS)Document83 pagesSoftware Project Management (MCQS)Aditya SharmaNo ratings yet
- Informatica 1011 DeveloperToolGuideDocument252 pagesInformatica 1011 DeveloperToolGuidesanthoshNo ratings yet
- Important Abbreviation For Data Communication and NetworkingDocument2 pagesImportant Abbreviation For Data Communication and NetworkingNoor KhanNo ratings yet
- Kush Misra: Education SkillsDocument1 pageKush Misra: Education SkillsAniruddha DubeyNo ratings yet
- Getting To Know The Ins and Outs of Oracle Partitioning in Oracle Database 11gDocument48 pagesGetting To Know The Ins and Outs of Oracle Partitioning in Oracle Database 11gSud KaviNo ratings yet
- Chapter 3Document117 pagesChapter 3lemajambo7No ratings yet
- Oracle® Database: Concepts 11g Release 2 (11.2)Document454 pagesOracle® Database: Concepts 11g Release 2 (11.2)kterkalNo ratings yet
- Fyp 2k23 Mine RealDocument84 pagesFyp 2k23 Mine Realfaisal gujjarNo ratings yet
- SS17837 - Internet Multimedia Subsytem (IMS)Document31 pagesSS17837 - Internet Multimedia Subsytem (IMS)Abishek Maran SNo ratings yet
- How To Improve Your SEO by Using Schema MarkupDocument3 pagesHow To Improve Your SEO by Using Schema MarkupTechno KryonNo ratings yet