Professional Documents
Culture Documents
Nber Omfp
Uploaded by
Joab Dan Valdivia CoriaOriginal Description:
Original Title
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Nber Omfp
Uploaded by
Joab Dan Valdivia CoriaCopyright:
Available Formats
Optimal Monetary and Fiscal Policy: A
Linear-Quadratic Approach
Pierpaolo Benigno
New York University
Michael Woodford
Princeton University
July 18, 2003
Abstract
We propose an integrated treatment of the problems of optimal monetary
and scal policy, for an economy in which prices are sticky (so that the supply-
side eects of tax changes are more complex than in standard scal analyses)
and the only available sources of government revenue are distorting taxes (so
that the scal consequences of monetary policy must be considered alongside
the usual stabilization objectives). Our linear-quadratic approach allows us
to nest both conventional analyses of optimal monetary stabilization policy
and analyses of optimal tax-smoothing as special cases of our more general
framework. We show how a linear-quadratic policy problem can be derived
which yields a correct linear approximation to the optimal policy rules from the
point of view of the maximization of expected discounted utility in a dynamic
stochastic general-equilibrium model. Finally, in addition to characterizing the
optimal dynamic responses to shocks under an optimal policy, we derive policy
rules through which the monetary and scal authorities may implement the
optimal equilibrium. These take the form of optimal targeting rules, specifying
an appropriate target criterion for each authority.
We would like to thank Stefania Albanesi, Marios Angeletos, Albert Marcet, Ramon Marimon,
seminar participants at New York University, Rutgers University, Universitat Pompeu Fabra, the
Macro Annual conference, and the editors for helpful comments, Brad Strum and Vasco Curdia for
research assistance, and the National Science Foundation for research support through a grant to
the NBER.
While there are by now substantial literatures seeking to characterize optimal
monetary and scal policy respectively, the two literatures have largely developed
in isolation, and upon apparently contradictory foundations. The modern literature
on dynamically optimal scal policy often abstracts from monetary aspects of the
economy altogether, and so implicitly allows for no useful role for monetary policy.
When monetary policy is considered within the theory of optimal scal policy, it is
most often in the context of models with exible prices; in these models, monetary
policy matters only (i) because the level of nominal interest rates (and hence the op-
portunity cost of holding money) determines the size of certain distortions that result
from the attempt to economize on money balances, and (ii) because the way in the
price level varies in response to real disturbances determines the state-contingent real
payos on (riskless) nominally-denominated government debt, which may facilitate
tax-smoothing in the case that explicitly state-contingent debt is not available. The
literature on optimal monetary policy has instead been mainly concerned with quite
distinct objectives for monetary stabilization policy, namely the minimization of the
distortions that result from prices or wages that do not adjust quickly enough to clear
markets. At the same time, this literature typically ignores the scal consequences of
alternative monetary policies; the characterizations of optimal monetary policy that
are obtained are thus strictly correct only for a world in which lump-sum taxes are
available.
Here we wish to consider the way in which the conclusions reached in each of
these two familiar literatures must be modied if one takes simultaneous account of
the basic elements of the policy problems addressed in each literature. On the one
hand, we wish to consider how conventional conclusions with regard to the nature of
an optimal monetary policy rule must be modied if one recognizes that the govern-
ments only sources of revenue are distorting taxes, so that the scal consequences
of monetary policy matter for welfare. And on the other hand, we wish to consider
how conventional conclusions with regard to optimal tax policy must be modied
if one recognizes that prices do not instantaneously clear markets, so that output
determination depends on aggregate demand, in addition to the supply-side factors
stressed in the conventional theory of optimal taxation.
A number of recent papers have also sought to jointly consider optimal monetary
and scal policy, in the context of models with sticky prices; important examples
include Correia et al., (2001), Schmitt-Grohe and Uribe (2001), and Siu (2001). Our
approach diers from those taken in these papers, however, in several respects. First,
1
we model price stickiness in a dierent way than in any of these papers, namely, by
assuming staggered pricing of the kind introduced by Calvo (1983). This particular
form of price stickiness has been widely used both in analyses of optimal monetary
policy in models with explicit microfoundations (e.g., Goodfriend and King, 1997;
Clarida et al., 1999; Woodford, 2003) and in the empirical literature on optimizing
models of the monetary transmission mechanism (e.g., Rotemberg and Woodford,
1997; Gali and Gertler, 1999; Sbordone, 2002).
Perhaps more importantly, we obtain analytical results rather than purely nu-
merical ones. To obtain these results, we propose a linear-quadratic approach to the
characterization of optimal monetary and scal policy, that allows us to nest both con-
ventional analyses of optimal monetary policy, such as that of Clarida et al. (1999),
and analyses of optimal tax-smoothing in the spirit of Barro (1979), Lucas and Stokey
(1983), and Aiyagari et al. (2002) as special cases of our more general framework.
We show how a linear-quadratic policy problem can be derived which yields a correct
linear approximation to the optimal policy rules from the point of view of the max-
imization of expected discounted utility in a dynamic stochastic general-equilibrium
model, building on the work of Benigno and Woodford (2003) for the case of optimal
monetary policy when lump-sum taxes are available.
Finally, we do not content ourselves with merely characterizing the optimal dy-
namic responses of our policy instruments (and other state variables) to shocks under
an optimal policy, given one assumption or another about the nature and statistical
properties of the exogenous disturbances to our model economy. Instead, we also
wish to derive policy rules that the monetary and scal authorities may reasonably
commit themselves to follow, as a way of implementing the optimal equilibrium. In
particular, we seek to characterize optimal policy in terms of optimal targeting rules
for monetary and scal policy, of the kind proposed in the case of monetary policy by
Svensson (1999), Svensson and Woodford (2003), and Giannoni and Woodford (2002,
2003). The rules are specied in terms of a target criterion for each authority; each
authority commits itself to use its policy instrument each period in whatever way is
necessary in order to allow it to project an evolution of the economy consistent with its
target criterion. As discussed in Giannoni and Woodford (2002), we can derive rules
of this form that are not merely consistent with the desired equilibrium responses
to disturbances, but that in addition (i) imply a determinate rational-expectations
equilibrium, so that there are not other equally possible (but less desirable) equilibria
2
consistent with the same policy; and (ii) bring about optimal responses to shocks
regardless of the character of and statistical properties of the exogenous disturbances
in the model.
1 The Policy Problem
Here we describe our assumptions about the economic environment and pose the
optimization problem that jointly optimal monetary and scal policies are intended
to solve. The approximation method that we use to characterize the solution to this
problem is then presented in the following section. Further details of the derivation
of the structural equations of our model of nominal price rigidity can be found in
Woodford (2003, chapter 3).
The goal of policy is assumed to be the maximization of the level of expected utility
of a representative household. In our model, each household seeks to maximize
U
t
0
E
t
0
t=t
0
tt
0
_
u(C
t
;
t
)
_
1
0
v(H
t
(j);
t
)dj
_
, (1.1)
where C
t
is a Dixit-Stiglitz aggregate of consumption of each of a continuum of
dierentiated goods,
C
t
__
1
0
c
t
(i)
1
di
_
1
, (1.2)
with an elasticity of substitution equal to > 1, and H
t
(j) is the quantity supplied
of labor of type j. Each dierentiated good is supplied by a single monopolistically
competitive producer. There are assumed to be many goods in each of an innite
number of industries; the goods in each industry j are produced using a type of
labor that is specic to that industry, and also change their prices at the same time.
The representative household supplies all types of labor as well as consuming all types
of goods.
1
To simplify the algebraic form of our results, we restrict attention in this
paper to the case of isoelastic functional forms,
u(C
t
;
t
)
C
1
1
t
C
1
t
1
1
,
1
We might alternatively assume specialization across households in the type of labor supplied; in
the presence of perfect sharing of labor income risk across households, household decisions regarding
consumption and labor supply would all be as assumed here.
3
v(H
t
;
t
)
1 +
H
1+
t
t
,
where , > 0, and {
C
t
,
H
t
} are bounded exogenous disturbance processes. (We use
the notation
t
to refer to the complete vector of exogenous disturbances, including
C
t
and
H
t
.)
We assume a common technology for the production of all goods, in which (industry-
specic) labor is the only variable input,
y
t
(i) = A
t
f(h
t
(i)) = A
t
h
t
(i)
1/
,
where A
t
is an exogenously varying technology factor, and > 1. Inverting the
production function to write the demand for each type of labor as a function of the
quantities produced of the various dierentiated goods, and using the identity
Y
t
= C
t
+G
t
to substitute for C
t
, where G
t
is exogenous government demand for the composite
good, we can write the utility of the representative household as a function of the
expected production plan {y
t
(i)}.
2
We can furthermore express the relative quantities demanded of the dierentiated
goods each period as a function of their relative prices. This allows us to write the
utility ow to the representative household in the form U(Y
t
,
t
;
t
), where
t
_
1
0
_
p
t
(i)
P
t
_
(1+)
di 1 (1.3)
is a measure of price dispersion at date t, in which P
t
is the Dixit-Stiglitz price index
P
t
__
1
0
p
t
(i)
1
di
_
1
1
, (1.4)
and the vector
t
now includes the exogenous disturbances G
t
and A
t
as well as the
preference shocks. Hence we can write our objective (1.1) as
U
t
0
= E
t
0
t=t
0
tt
0
U(Y
t
,
t
;
t
). (1.5)
2
The government is assumed to need to obtain an exogenously given quantity of the Dixit-Stiglitz
aggregate each period, and to obtain this in a cost-minimizing fashion. Hence the government
allocates its purchases across the suppliers of dierentiated goods in the same proportion as do
households, and the index of aggregate demand Y
t
is the same function of the individual quantities
{y
t
(i)} as C
t
is of the individual quantities consumed {c
t
(i)}, dened in (1.2).
4
The producers in each industry x the prices of their goods in monetary units for
a random interval of time, as in the model of staggered pricing introduced by Calvo
(1983). We let 0 < 1 be the fraction of prices that remain unchanged in any
period. A supplier that changes its price in period t chooses its new price p
t
(i) to
maximize
E
t
_
T=t
Tt
Q
t,T
(p
t
(i), p
j
T
, P
T
; Y
T
,
T
,
T
)
_
, (1.6)
where Q
t,T
is the stochastic discount factor by which nancial markets discount ran-
dom nominal income in period T to determine the nominal value of a claim to such
income in period t, and
Tt
is the probability that a price chosen in period t will
not have been revised by period T. In equilibrium, this discount factor is given by
Q
t,T
=
Tt
u
c
(C
T
;
T
)
u
c
(C
t
;
t
)
P
t
P
T
. (1.7)
The function (p, p
j
, P; Y, , ), dened in the appendix, indicates the after-tax
nominal prots of a supplier with price p, in an industry with common price p
j
, when
the aggregate price index is equal to P, aggregate demand is equal to Y , and sales
revenues are taxed at rate . Prots are equal to after-tax sales revenues net of the
wage bill, and the real wage demanded for labor of type j is assumed to be given by
w
t
(j) =
w
t
v
h
(H
t
(j); )
u
c
(C
t
;
t
)
, (1.8)
where
w
t
1 is an exogenous markup factor in the labor market (allowed to vary
over time, but assumed common to all labor markets),
3
and rms are assumed to be
wage-takers. We allow for wage markup variations in order to include the possibility
of a pure cost-push shock that aects equilibrium pricing behavior while implying
no change in the ecient allocation of resources. Note that variation in the tax rate
t
has a similar eect on this pricing problem (and hence on supply behavior); this
is the sole distortion associated with tax policy in the present model.
Each of the suppliers that revise their prices in period t choose the same new
price p
t
. Under our assumed functional forms, the optimal choice has a closed-form
solution
p
t
P
t
=
_
K
t
F
t
_ 1
1+
, (1.9)
3
In the case that we assume that
w
t
= 1 at all times, our model is one in which both households
and rms are wage-takers, or there is ecient contracting between them.
5
where (1 +) 1 > 0 is the elasticity of real marginal cost in an industry with
respect to industry output, and F
t
and K
t
are functions of current aggregate output
Y
t
, the current tax rate
t
, the current exogenous state
t
,
4
and the expected future
evolution of ination, output, taxes and disturbances, dened in the appendix.
The price index then evolves according to a law of motion
P
t
=
_
(1 )p
1
t
+P
1
t1
1
1
, (1.10)
as a consequence of (1.4). Substitution of (1.9) into (1.10) implies that equilibrium
ination in any period is given by
1
1
t
1
=
_
F
t
K
t
_ 1
1+
, (1.11)
where
t
P
t
/P
t1
. This denes a short-run aggregate supply relation between
ination and output, given the current tax rate
t
, current disturbances
t
, and ex-
pectations regarding future ination, output, taxes and disturbances. Because the
relative prices of the industries that do not change their prices in period t remain the
same, we can also use (1.10) to derive a law of motion of the form
t
= h(
t1
,
t
) (1.12)
for the dispersion measure dened in (1.3). This is the source in our model of welfare
losses from ination or deation.
We abstract here from any monetary frictions that would account for a demand for
central-bank liabilities that earn a substandard rate of return; we nonetheless assume
that the central bank can control the riskless short-term nominal interest rate i
t
,
5
which is in turn related to other nancial asset prices through the arbitrage relation
1 +i
t
= [E
t
Q
t,t+1
]
1
.
We shall assume that the zero lower bound on nominal interest rates never binds
under the optimal policies considered below,
6
so that we need not introduce any
4
The disturbance vector
t
is now understood to include the current value of the wage markup
w
t
.
5
For discussion of how this is possible even in a cashless economy of the kind assumed here,
see Woodford (2003, chapter 2).
6
This can be shown to be true in the case of small enough disturbances, given that the nominal
interest rate is equal to r =
1
1 > 0 under the optimal policy in the absence of disturbances.
6
additional constraint on the possible paths of output and prices associated with a
need for the chosen evolution of prices to be consistent with a non-negative nominal
interest rate.
Our abstraction from monetary frictions, and hence from the existence of seignor-
age revenues, does not mean that monetary policy has no scal consequences, for
interest-rate policy and the equilibrium ination that results from it have implica-
tions for the real burden of government debt. For simplicity, we shall assume that all
public debt consists of riskless nominal one-period bonds. The nominal value B
t
of
end-of-period public debt then evolves according to a law of motion
B
t
= (1 +i
t1
)B
t1
+P
t
s
t
, (1.13)
where the real primary budget surplus is given by
s
t
t
Y
t
G
t
t
. (1.14)
Here
t
, the share of the national product that is collected by the government as
tax revenues in period t, is the key scal policy decision each period; the real value
of (lump-sum) government transfers
t
is treated as exogenously given, as are gov-
ernment purchases G
t
. (We introduce the additional type of exogenously given scal
needs so as to be able to analyze the consequences of a purely scal disturbance,
with no implications for the real allocation of resources beyond those that follow from
its eect on the government budget.)
Rational-expectations equilibrium requires that the expected path of government
surpluses must satisfy an intertemporal solvency condition
b
t1
P
t1
P
t
= E
t
T=t
R
t,T
s
T
(1.15)
in each state of the world that may be realized at date t,
7
where R
t,T
Q
t,T
P
T
/P
t
is
the stochastic discount factor for a real income stream, and This condition restricts
7
See Woodford (2003, chapter 2) for derivation of this condition from household optimization
together with market clearing. The condition should not be interpreted as an a priori constraint on
possible government policy rules, as discussed in Woodford (2001). However, when we consider the
problem of choosing an optimal plan from the among the possible rational-expectations equilibria,
this condition must be imposed among the constraints on the set of equilibria that one may hope to
bring about.
7
the possible paths that may be chosen for the tax rate {
t
}. Monetary policy can
aect this constraint, however, both by aecting the period t ination rate (which
aects the left-hand side) and (in the case of sticky prices) by aecting the discount
factors {R
t,T
}.
Under the standard (Ramsey) approach to the characterization of an optimal
policy commitment, one chooses among state-contingent paths {
t
, Y
t
,
t
, b
t
,
t
} from
some initial date t
0
onward that satisfy (1.11), (1.12), and (1.15) for each t t
0
,
given initial government debt b
t
0
1
and price dispersion
t
0
1
, so as to maximize
(1.5). Such a t
0
optimal plan requires commitment, insofar as the corresponding
toptimal plan for some later date t, given the conditions b
t1
,
t1
obtaining at
that date, will not involve a continuation of the t
0
optimal plan. This failure of
time consistency occurs because the constraints on what can be achieved at date t
0
,
consistent with the existence of a rational-expectations equilibrium, depend on the
expected paths of ination, output and taxes at later dates; but in the absence of a
prior commitment, a planner would have no motive at those later dates to choose a
policy consistent with the anticipations that it was desirable to create at date t
0
.
However, the degree of advance commitment that is necessary to bring about an
optimal equilibrium is of only a limited sort. Let
W
t
E
t
T=t
Tt
u
c
(Y
T
G
T
;
T
)s
T
,
and let F be the set of values for (b
t1
,
t1
, F
t
, K
t
, W
t
) such that there exist paths
{
T
, Y
T
,
T
, b
T
,
T
} for dates T t that satisfy (1.11), (1.12), and (1.15) for each
T, that are consistent with the specied values for F
t
, K
t
, and W
t
, and that im-
ply a well-dened value for the objective U
t
dened in (1.5). Furthermore, for any
(b
t1
,
t1
, F
t
, K
t
, W
t
) F, let V (b
t1
,
t1
, X
t
;
t
) denote the maximum attainable
value of U
t
among the state-contingent paths that satisfy the constraints just men-
tioned, where X
t
(F
t
, K
t
, W
t
).
8
Then the t
0
optimal plan can be obtained as the
solution to a two-stage optimization problem, as shown in the appendix.
In the rst stage, values of the endogenous variables x
t
0
, where x
t
(
t
, Y
t
,
t
, b
t
,
t
),
and state-contingent commitments X
t
0
+1
(
t
0
+1
) for the following period, are chosen,
8
In our notation for the value function V,
t
denotes not simply the vector of disturbances in
period t, but all information in period t about current and future disturbances. This corresponds to
the disturbance vector
t
referred to earlier in the case that the disturbance vector follows a Markov
process.
8
subject to a set of constraints stated in the appendix, including the requirement that
the choices (b
t
0
,
t
0
, X
t
0
+1
) F for each possible state of the world
t
0
+1
. These
variables are chosen so as to maximize the objective
J[x
t
0
, X
t
0
+1
()](
t
0
), where we
dene the functional
J[x
t
, X
t+1
()](
t
) U(Y
t
,
t
;
t
) +E
t
V (b
t
,
t
, X
t+1
;
t+1
). (1.16)
In the second stage, the equilibrium evolution from period t
0
+1 onward is chosen to
solve the maximization problem that denes the value function V (b
t
0
,
t
0
, X
t
0
+1
;
t
0
+1
),
given the state of the world
t
0
+1
and the precommitted values for X
t
0
+1
associated
with that state. The key to this result is a demonstration that there are no restric-
tions on the evolution of the economy from period t
0
+ 1 onward that are required
in order for this expected evolution to be consistent with the values chosen for x
t
0
,
except consistency with the commitments X
t
0
+1
(
t
0
+1
) chosen in the rst stage.
The optimization problem in stage two of this reformulation of the Ramsey prob-
lem is of the same form as the Ramsey problem itself, except that there are additional
constraints associated with the precommitted values for the elements of X
t
0
+1
(
t
0
+1
).
Let us consider a problem like the Ramsey problem just dened, looking forward from
some period t
0
, except under the constraints that the quantities X
t
0
must take certain
given values, where (b
t
0
1
,
t
0
1
, X
t
0
) F. This constrained problem can similarly
be expressed as a two-stage problem of the same form as above, with an identical
stage two problem to the one described above. Stage two of this constrained problem
is thus of exactly the same form as the problem itself. Hence the constrained problem
has a recursive form. It can be decomposed into an innite sequence of problems, in
which in each period t, (x
t
, X
t+1
()) are chosen to maximize
J[x
t
, X
t+1
()](
t
), subject
to the constraints of the stage one problem, given the predetermined state variables
(b
t1
,
t1
) and the precommitted values X
t
.
Our aim here is to characterize policy that solves this constrained optimization
problem (stage two of the original Ramsey problem), i.e., policy that is optimal from
some date t onward given precommitted values for X
t
. Because of the recursive form of
this problem, it is possible for a commitment to a time-invariant policy rule from date
t onward to implement an equilibrium that solves the problem, for some specication
of the initial commitments X
t
. A time-invariant policy rule with this property is said
by Woodford (2003, chapter 7) to be optimal from a timeless perspective.
9
Such
9
See also Woodford (1999) and Giannoni and Woodford (2002).
9
a rule is one that a policymaker that solves a traditional Ramsey problem would be
willing to commit to eventually follow, though the solution to the Ramsey problem
involves dierent behavior initially, as there is no need to internalize the eects of
prior anticipation of the policy adopted for period t
0
.
10
One might also argue that it
is desirable to commit to follow such a rule immediately, even though such a policy
would not solve the (unconstrained) Ramsey problem, as a way of demonstrating
ones willingness to accept constraints that one wishes the public to believe that one
will accept in the future.
2 A Linear-Quadratic Approximate Problem
In fact, we shall here characterize the solution to this problem (and similarly, derive
optimal time-invariant policy rules) only for initial conditions near certain steady-
state values, allowing us to use local approximations in characterizing optimal pol-
icy.
11
We establish that these steady-state values have the property that if one starts
from initial conditions close enough to the steady state, and exogenous disturbances
thereafter are small enough, the optimal policy subject to the initial commitments
remains forever near the steady state. Hence our local characterization would de-
scribe the long run character of Ramsey policy, in the event that disturbances are
small enough, and that deterministic Ramsey policy would converge to the steady
state.
12
Of greater interest here, it describes policy that is optimal from a timeless
perspective in the event of small disturbances.
We rst must show the existence of a steady state, i.e., of an optimal policy (under
10
For example, in the case of positive initial nominal government debt, the t
0
optimal policy
would involve a large ination in period t
0
, in order to reduce the pre-existing debt burden, but a
commitment not to respond similarly to the existence of nominal government debt in later periods.
11
Local approximations of the same sort are often used in the literature in numerical character-
izations of Ramsey policy. Strictly speaking, however, such approximations are valid only in the
case of initial commitments X
t
0
near enough to the steady-state values of these variables, and the
t
0
optimal (Ramsey) policy need not involve values of X
t
0
near the steady-state values, even in the
absence of random disturbances.
12
Benigno and Woodford (2003) gives an example of an application in which Ramsey policy
does converge asymptotically to the steady state, so that the solution to the approximate problem
approximates the response to small shocks under the Ramsey policy, at dates long enough after t
0
.
We cannot make a similar claim in the present application, however, because of the unit root in the
dynamics associated with optimal policy.
10
appropriate initial conditions) that involves constant values of all variables. To this
end we consider the purely deterministic case, in which the exogenous disturbances
C
t
, G
t
,
H
t
, A
t
,
w
t
,
t
each take constant values
C,
G,
H,
A,
w
> 0 and
0 for
all t t
0
, and assume an initial real public debt b
t
0
1
=
b > 0. We wish to nd
an initial degree of price dispersion
t
0
1
and initial commitments X
t
0
=
X such
that the solution to the stage two problem dened above involves a constant policy
x
t
= x, X
t+1
=
X each period, in which
b is equal to the initial real debt and
is
equal to the initial price dispersion. We show in the appendix that the rst-order
conditions for this problem admit a steady-state solution of this form, and we verify
below that the second-order conditions for a local optimum are also satised.
Regardless of the initial public debt
b, we show that
= 1 (zero ination), and
correspondingly that
= 1 (zero price dispersion). Note that our conclusion that
the optimal steady-state ination rate is zero generalizes the result of Benigno and
Woodford (2003) for the case in which taxes are lump-sum at the margin. We may
furthermore assume without loss of generality that the constant values of
C and
H
are chosen (given the initial government debt
b) so that in the optimal steady state,
C
t
=
C and H
t
=
H each period.
13
The associated steady-state tax rate is given by
= s
G
+
+ (1 )
Y
,
where
Y =
C +
G > 0 is the steady-state output level, and s
G
G/
Y < 1 is the
steady-state share of output purchased by the government. As shown in the appendix,
this solution necessarily satises 0 < < 1.
We next wish to characterize the optimal responses to small perturbations of
the initial conditions and small uctuations in the disturbance processes around the
above values. To do this, we compute a linear-quadratic approximate problem, the
solution to which represents a linear approximation to the solution to the stage two
policy problem, using the method introduced in Benigno and Woodford (2003). An
important advantage of this approach is that it allows direct comparison of our results
with those obtained in other analyses of optimal monetary stabilization policy. Other
advantages are that it makes it straightforward to verify whether the second-order
conditions hold that are required in order for a solution to our rst-order conditions
to be at least a local optimum,
14
and that it provides us with a welfare measure with
13
Note that we may assign arbitrary positive values to
C,
H without changing the nature of the
implied preferences, as long as the value of is appropriately adjusted.
11
which to rank alternative sub-optimal policies, in addition to allowing computation
of the optimal policy.
We begin by computing a Taylor-series approximation to our welfare measure
(1.5), expanding around the steady-state allocation dened above, in which y
t
(i) =
Y
for each good at all times and
t
= 0 at all times.
15
As a second-order (logarithmic)
approximation to this measure, we obtain
16
U
t
0
= Y u
c
E
t
0
t=t
0
tt
0
Y
t
1
2
u
yy
Y
2
t
+
Y
t
u
t
u
t
+ t.i.p. +O(||||
3
), (2.1)
where
Y
t
log(Y
t
/
Y ) and
t
log
t
measure deviations of aggregate output and
the price dispersion measure from their steady-state levels, the term t.i.p. collects
terms that are independent of policy (constants and functions of exogenous distur-
bances) and hence irrelevant for ranking alternative policies, and |||| is a bound on
the amplitude of our perturbations of the steady state.
17
Here the coecient
1
1
1
w
< 1
measures the steady-state wedge between the marginal rate of substitution between
consumption and leisure and the marginal product of labor, and hence the ineciency
of the steady-state output level
Y . Under the assumption that
b > 0, we necessarily
14
Benigno and Woodford (2003) show that these conditions can fail to hold, so that a small amount
of arbitrary randomization of policy is welfare-improving, but argue that the conditions under which
this occurs in their model are not empirically plausible.
15
Here the elements of
t
are assumed to be c
t
log(
C
t
/
C),
h
t
log(
H
t
/
H), a
t
log(A
t
/
A),
w
t
log(
w
t
/
w
),
G
t
(G
t
G)/
Y , and
t
(
t
)/
Y , so that a value of zero for this vector corresponds
to the steady-state values of all disturbances. The perturbations
G
t
and
t
are not dened to be
logarithmic so that we do not have to assume positive steady-state values for these variables.
16
See the appendix for details. Our calculations here follow closely those of Woodford (2003,
chapter 6) and Benigno and Woodford (2003).
17
Specically, we use the notation O(||||
k
) as shorthand for O(||,
b
t01
,
1/2
t
0
1
,
X
t0
||
k
), where in
each case hats refer to log deviations from the steady-state values of the various parameters of the
policy problem. We treat
1/2
t
0
as an expansion parameter, rather than
t
0
because (1.12) implies
that deviations of the ination rate from zero of order only result in deviations in the dispersion
measure
t
from one of order
2
. We are thus entitled to treat the uctuations in
t
as being only
of second order in our bound on the amplitude of disturbances, since if this is true at some initial
date it will remain true thereafter.
12
have > 0, meaning that steady-state output is ineciently low. The coecients
u
yy
, u
and u
are dened in the appendix.
Under the Calvo assumption about the distribution of intervals between price
changes, we can relate the dispersion of prices to the overall rate of ination, allowing
us to rewrite (2.1) as
U
t
0
= Y u
c
E
t
0
t=t
0
tt
0
[
Y
t
1
2
u
yy
Y
2
t
+
Y
t
u
t
u
2
t
]
+ t.i.p. +O(||||
3
), (2.2)
for a certain coecient u
> 0 dened in the appendix, where
t
log
t
is the
ination rate. Thus we are able to write our stabilization objective purely in terms
of the evolution of the aggregate variables {
Y
t
,
t
} and the exogenous disturbances.
We note that when > 0, there is a non-zero linear term in (2.2), which means
that we cannot expect to evaluate this expression to second order using only an
approximate solution for the path of aggregate output that is accurate only to rst
order. Thus we cannot determine optimal policy, even up to rst order, using this
approximate objective together with approximations to the structural equations that
are accurate only to rst order. Rotemberg and Woodford (1997) avoid this problem
by assuming an output subsidy (i.e., a value < 0) of the size needed to ensure
that = 0. Here we do not wish to make this assumption, because we assume that
lump-sum taxes are unavailable, in which case = 0 would be possible only in the
case of a particular initial level of government assets
b < 0. Furthermore, we are more
interested in the case in which government revenue needs are more acute than that
would imply.
Benigno and Woodford (2003) propose an alternative way of dealing with this
problem, which is to use a second-order approximation to the aggregate-supply rela-
tion to eliminate the linear terms in the quadratic welfare measure. In the model that
they consider, where taxes are lump-sum (and so do not aect the aggregate supply
relation), a forward-integrated second-order approximation to this relation allows one
to express the expected discounted value of output terms
Y
t
as a function of purely
quadratic terms (except for certain transitory terms that do not aect the stage
two policy problem). In the present case, the level of distorting taxes has a rst-
order eect on the aggregate-supply relation (see equation (2.6) below), so that the
forward-integrated relation involves the expected discounted value of the tax rate as
13
well as the expected discounted value of output. However, as shown in the appendix,
a second-order approximation to the intertemporal solvency condition (1.15)
18
pro-
vides another relation between the expected discounted values of output and the tax
rate and a set of purely quadratic terms. These two second-order approximations to
the structural equations that appear as constraints in our policy problem can then
be used to express the expected discounted value of output terms in (2.2) in terms of
purely quadratic terms.
In this manner, we can rewrite (2.2) as
U
t
0
= E
t
0
t=t
0
tt
0
_
1
2
q
y
(
Y
t
t
)
2
+
1
2
q
2
t
_
+T
t
0
+ t.i.p. +O(||||
3
), (2.3)
where again the coecients are dened in the appendix. The expression
Y
t
indicates
a function of the vector of exogenous disturbances
t
dened in the appendix, while
T
t
0
is a transitory component. In the case that the alternative policies from date t
0
onward to be evaluated must be consistent with a vector of prior commitments X
t
0
,
one can show that the value of the term T
t
0
is implied (to a second-order approxima-
tion) by the value of X
t
0
. Hence for purposes of characterizing optimal policy from a
timeless perspective, it suces that we rank policies according to the value that they
imply for the loss function
E
t
0
t=t
0
tt
0
_
1
2
q
y
(
Y
t
t
)
2
+
1
2
q
2
t
_
, (2.4)
where a lower value of (2.4) implies a higher value of (2.3). Because this loss function
is purely quadratic (i.e., lacking linear terms), it is possible to evaluate it to second
order using only a rst-order approximation to the equilibrium evolution of ination
and output under a given policy. Hence log-linear approximations to the structural
relations of our model suce, yielding a standard linear-quadratic policy problem.
In order for this linear-quadratic problem to have a bounded solution (which then
approximates the solution to the exact problem), we must verify that the quadratic
18
Since we are interested in providing an approximate characterization of the stage two policy
problem, in which a precommitted value of W
t
appears as a constraint, it is actually a second-order
approximation to that constraint that we need. However, this latter constraint has the same form
as (1.15); the dierence is only in which quantities in the relation are taken to have predetermined
values.
14
objective (2.4) is convex. We show in the appendix that q
y
, q
> 0, so that the
objective is convex, as long as the steady-state tax rate and share of government
purchases s
G
in the national product are below certain positive bounds. We shall here
assume that these conditions are satised, i.e., that the governments scal needs are
not too severe. Note that in this case, our quadratic objective turns out to be of a form
commonly assumed in the literature on monetary policy evaluation; that is, policy
should seek to minimize the discounted value of a weighted sum of squared deviations
of ination from an optimal level (here zero) and squared uctuations in an output
gap y
t
Y
t
t
, where the target output level
Y
t
depends on the various exogenous
disturbances in a way discussed in the appendix. It is also perhaps of interest to note
that a tax smoothing objective of the kind postulated by Barro (1979) and Bohn
(1990) does not appear in our welfare measure as a separate objective. Instead, tax
distortions are relevant only insofar as they result in output gaps of the same sort
that monetary stabilization policy aims to minimize.
We turn next to the form of the log-linear constraints in the approximate policy
problem. A rst-order Taylor series expansion of (1.11) around the zero-ination
steady state yields the log-linear aggregate-supply relation
t
= [
Y
t
+
t
+c
t
] +E
t
t+1
, (2.5)
for certain coecients , > 0. This is the familiar New Keynesian Phillips curve
relation,
19
extended here to take account of the eects of variations in the level of
distorting taxes on supply costs.
It is useful to write this approximate aggregate-supply relation in terms of the
welfare-relevant output gap y
t
. Equation (2.5) can be equivalently be written as
t
= [y
t
+
t
+u
t
] +E
t
t+1
, (2.6)
where u
t
is composite cost-push disturbance, indicating the degree to which the
various exogenous disturbances included in
t
preclude simultaneous stabilization of
ination, the welfare-relevant output gap, and the tax rate. Alternatively we can
write
t
= [y
t
+(
t
t
)] +E
t
t+1
, (2.7)
19
See, e.g., Clarida et al. (1999) or Woodford (2003, chapter 3).
15
where
t
1
u
t
indicates the tax change needed at any time to oset thecost-
push shock, in order to allow simultaneous stabilization of ination and the output
gap (the two stabilization objectives reected in (2.4)).
The eects of the various exogenous disturbances in
t
on the cost-push term
u
t
are explained in the appendix. It is worth noting that under certain conditions u
t
is unaected by some disturbances. In the case that = 0, the cost-push term is
given by
u
t
= u
5
w
t
, (2.8)
where in this case, u
5
= q
1
y
> 0. Thus the cost-push term is aected only by varia-
tions in the wage markup
t
; it does not vary in response to taste shocks, technology
shocks, government purchases, or variations in government transfers. The reason is
that when = 0 and neither taxes nor the wage markup vary from their steady-
state values, the exible-price equilibrium is ecient; it follows that level of output
consistent with zero ination is also the one that maximizes welfare, as discussed in
Woodford (2003, chapter 6).
Even when > 0, if there are no government purchases (so that s
G
= 0) and
no scal shocks (meaning that
G
t
= 0 and
t
= 0), then the u
t
term is again of the
form (2.8), but with u
5
= (1 )q
1
y
, as discussed in Benigno and Woodford (2003).
Hence in this case neither taste or technology shocks have cost-push eects. The
reason is that in this isoelastic case, if neither taxes nor the wage markup ever vary,
the exible-price equilibrium value of output and the ecient level vary in exactly
the same proportion in response to each of the other types of shocks; hence ination
stabilization also stabilizes the gap between actual output and the ecient level.
Another special case is the limiting case of linear utility of consumption (
1
= 0); in
this case, u
t
is again of the form (2.8), for a dierent value of u
5
. In general, however,
when > 0 and s
G
> 0, all of the disturbances shift the exible-price equilibrium
level of output (under a constant tax rate) and the ecient level of output to diering
extents, resulting in cost-push contributions from all of these shocks.
The other constraint on possible equilibrium paths is the intertemporal govern-
ment solvency condition. A log-linear approximation to (1.15) can be written in the
form
b
t1
1
y
t
= f
t
+ (1 )E
t
T=t
Tt
[b
y
y
T
+b
(
T
T
)], (2.9)
16
where > 0 is the intertemporal elasticity of substitution of private expenditure,
and the coecients b
y
, b
are dened in the appendix, as is f
t
, a composite measure
of exogenous scal stress. Here we have written the solvency condition in terms of
the same output gap and tax gap as equation (2.7), to make clear the extent to
which complete stabilization of the variables appearing in the loss function (2.4) is
possible. The constraint can also be written in a ow form,
b
t1
1
y
t
+f
t
= (1)[b
y
y
t
+b
(
t
t
)]+E
t
[
b
t
t+1
1
y
t+1
+f
t+1
], (2.10)
together with a transversality condition.
20
We note that the only reason why it should not be possible to completely stabilize
both ination and the output gap from some date t onward is if the sum
b
t1
+f
t
is non-
zero. The composite disturbance f
t
therefore completely summarizes the information
at date t about the exogenous disturbances that determines the degree to which
stabilization of ination and output is not possible; and under an optimal policy, the
state-contingent evolution of the ination rate, the output gap, and the real public
debt depend solely on the evolution of the single composite disturbance process {f
t
}.
This result contrasts with the standard literature on optimal monetary stabiliza-
tion policy, in which (in the absence of a motive for interest-rate stabilization, as
here) it is instead the cost-push term u
t
that summarizes the extent to which exoge-
nous disturbances require that uctuations in ination and in the output gap should
occur. Note that in the case that there are no government purchases and no scal
shocks, u
t
corresponds simply to (2.8). Thus, for example, it is concluded (in a model
with lump-sum taxes) that there should be no variation in ination in response to a
technology shock (Khan et al., 2002; Benigno and Woodford, 2003). But even in this
simple case, the scal stress is given by an expression of the form
f
t
h
t
(1 )E
t
T=t
Tt
f
T
, (2.11)
where the expressions h
t
and f
t
both generally include non-zero coecients on
preference and technology shocks, in addition to the markup shock, as shown in the
appendix. Hence many disturbances that do not have cost-push eects nonetheless
result in optimal variations in both ination and the output gap.
20
If we restrict attention to bounded paths for the endogenous variables, then a path satises (2.9)
in each period t t
0
if and only if it satises the ow budget constraint (2.10) in each period.
17
Finally, we wish to consider optimal policy subject to the constraints that F
t
0
, K
t
0
and W
t
0
take given (precommitted) values. Again, only log-linear approximations to
these constraints matter for a log-linear approximate characterization of optimal pol-
icy. As discussed in the appendix, the corresponding constraints in our approximate
model are precommitments regarding the state-contingent values of
t
0
and y
t
0
.
To summarize, our approximate policy problem involves the choice of state-contingent
paths for the endogenous variables {
t
, y
t
,
t
,
b
t
} from some date t
0
onward so as to
minimize the quadratic loss function (2.4), subject to the constraint that conditions
(2.7) and (2.9) be satised each period, given an initial value
b
t
0
1
and subject also to
the constraints that
t
0
and y
t
0
equal certain precommitted values (that may depend
on the state of the world in period t
0
). We shall rst characterize the state-contingent
evolution of the endogenous variables in response to exogenous shocks, in the rational-
expectations equilibrium that solves this problem. We then turn to the derivation of
optimal policy rules, commitment to which should implement an equilibrium of this
kind.
3 Optimal Responses to Shocks: The Case of Flex-
ible Prices
In considering the solution to the problem of stabilization policy just posed, it may
be useful to rst consider the simple case in which prices are fully exible. This is
the limiting case of our model in which = 0, with the consequence that q
= 0
in (2.4), and that
1
= 0 in (2.7). Hence our optimization problem reduces to the
minimization of
1
2
q
y
E
t
0
t=t
0
tt
0
y
2
t
(3.1)
subject to the constraints
y
t
+(
t
t
) = 0 (3.2)
and (2.9). It is easily seen that in this case, the optimal policy is one that achieves
y
t
= 0 at all times. Because of (3.2), this requires that
t
=
t
at all times. The
ination rate is then determined by the requirement of government intertemporal
solvency,
t
=
b
t1
+f
t
.
18
This last equation implies that unexpected ination must equal the innovation in
the scal stress,
t
E
t1
t
= f
t
E
t1
f
t
.
Expected ination, and hence the evolution of nominal government debt, are inde-
terminate. If we add to our assumed policy objective a small preference for ination
stabilization, when this has no cost in terms of other objectives,
21
then the optimal
policy will be one that involves E
t
t+1
= 0 each period, so that the nominal public
debt must evolve according to
b
t
= E
t
f
t+1
.
If, instead, we were to assume the existence of small monetary frictions (and zero
interest on money), the tie would be broken by the requirement that the nominal
interest rate equal zero each period.
22
The required expected rate of ination (and
hence the required evolution of the nominal public debt) would then be determined
by the variation in the equilibrium real rate of return implied by a real allocation in
which
Y
t
=
Y
t
each period. That is, one would have E
t
t+1
= r
t
, where r
t
is the
(exogenous) real rate of interest associated output at the target level each period,
and so
b
t
= r
t
E
t
f
t+1
.
We thus obtain simple conclusions about the determinants of uctuations in ina-
tion, output and the tax rate under optimal policy. Unexpected ination variations
occur as needed in order to prevent taxes from ever having to be varied in order to
respond to variations in scal stress, as in the analyses of Bohn (1990) and Chari
and Kehoe (1999). This allows a model with only riskless nominal government debt
21
Note that this preference can be justied in terms of our model, in the case that is positive
though extremely small. For there will then be a very small positive value for q
, implying that
reduction of the expected discounted value of ination is preferred to the extent that this does not
require any increase in the expected discounted value of squared output gaps.
22
The result relies upon the fact that the distortions created by the monetary frictions are mini-
mized in the case of a zero opportunity cost of holding money each period, as argued by Friedman
(1969). Neither the existence of eects of nominal interest rates on supply costs (so that an interest-
rate term should appear in the aggregate-supply relation (3.2)) nor the contribution of seignorage
revenues to the government budget constraint make any dierence to the result, since unexpected
changes in revenue needs can always be costlessly obtained through unexpected ination, while any
desired shifts in the aggregate-supply relation to oset cost-push shocks can be achieved by varying
the tax rate.
19
to achieve the same state-contingent allocation of resources as the government would
choose to bring about if it were able to issue state-contingent debt, as in the model
of Lucas and Stokey (1983).
Because taxes do not have to adjust in response to variations in scal stress, as
in the tax-smoothing model of Barro (1979), it is possible to smooth them across
states as well as over time. However, the sense in which it is desirable to smooth
tax rates is that of minimizing variation in the gap
t
t
, rather than variation in
the tax rate itself.
23
In other words, it is really the tax gap
t
t
that should be
smoothed. Under certain special circumstances, it will not be optimal for tax rates
to vary in response to shocks; these are the conditions, discussed above, under which
shocks have no cost-push eects, so that there is no change in
t
. For example, if
there are no government purchases and there is no variation in the wage markup,
this will be the case. But more generally, all disturbances will have some cost-push
eect, and result in variations in
t
. There will then be variations in the tax rate in
response to these shocks under an optimal policy. However, there will be no unit root
in the tax rate, as in the Barro (1979) model of optimal tax policy. Instead, as in
the analysis of Lucas and Stokey (1983), the optimal uctuations in the tax rate will
be stationary, and will have the same persistence properties as the real disturbances
(specically, the persistence properties of the composite cost-push shock).
Variations in scal stress will instead require changes in the tax rate, as in the
analysis of Barro (1979), if we suppose that the government issues only riskless in-
dexed debt, rather than the riskless nominal debt assumed in our baseline model.
(Again, for simplicity we assume that only one-period riskless debt is issued.) In
this case the objective function (2.4) and the constraints (2.9) and (3.2) remain the
same, but b
t1
b
t1
t
, the real value of private claims on the government at the
beginning of period t, is now a predetermined variable. This means that unexpected
ination variations are no longer able to relax the intertemporal government solvency
23
A number of authors (e.g., Chari et al., 1991, 1994; Hall and Krieger, 2000; Aiyagari et al.,
2002) have found that in calibrated exible-price models with state-contingent government debt,
the optimal variation in labor tax rates is quite small. Our results indicate this as well, in the
case that real disturbances have only small cost-push eects, and we have listed earlier various
conditions under which this will be the case. But under some circumstances, optimal policy may
involve substantial volatility of the tax rate, and indeed, more volatility of the tax rate than of
ination. This would be the case if shocks occur that have large cost-push eects while having
relatively little eect on scal stress.
20
condition. In fact, rewriting the constraint (2.9) in terms of b
t1
, we see that the
path of ination is now completely irrelevant to welfare.
The solution to this optimization problem is now less trivial, as complete stabi-
lization of the output gap is not generally possible. The optimal state-contingent
evolution of output and taxes can be determined using a Lagrangian method, as in
Woodford (2003, chapter 7). The Lagrangian for the present problem can be written
as
L
t
0
= E
t
0
t=t
0
tt
0
{
1
2
q
y
y
2
t
+
1t
[y
t
+
t
] +
2t
[(b
t1
1
y
t
)
(1 )(b
y
y
t
+b
t
) (b
1
y
t+1
)]} +
2,t
0
1
y
t
0
, (3.3)
where
1t
,
2t
are Lagrange multipliers associated with constraints (3.2) and (2.10)
respectively,
24
for each t t
0
, and
2,t
0
1
is the notation used for the multiplier
associated with the additional constraint that y
t
0
= y
t
0
. The latter constraint is added
in order to characterize optimal policy from a timeless perspective, as discussed at
the end of section 2; the particular notation used for the multiplier on this constraint
results in a time-invariant form for the rst-order conditions, as seen below.
25
We
have dropped terms from the Lagrangian that are not functions of the endogenous
variables y
t
and
t
, i.e., products of multipliers and exogenous disturbances, as these
do not aect our calculation of the implied rst-order conditions.
The resulting rst-order condition with respect to y
t
is
q
y
y
t
=
1t
+ [(1 )b
y
+
1
]
2t
2,t1
; (3.4)
that with respect to
t
is
1t
= (1 )b
2t
; (3.5)
and that with respect to b
t
is
2t
= E
t
2,t+1
. (3.6)
24
Alternatively,
2t
is the multiplier associated with constraint (2.9).
25
It should be recalled that in order for policy to be optimal from a timeless perspective, the state-
contingent initial commitment y
t0
must be chosen in a way that conforms to the state-contingent
commitment regarding y
t
that will be chosen in all later periods, so that the optimal policy can be
implemented by a time-invariant rule. Hence it is convenient to present the rst-order conditions in
a time-invariant form.
21
Each of these conditions must be satised for each t t
0
, along with the structural
equations (3.2) and (2.9) for each t t
0
, for given initial values b
t
0
1
and y
t
0
. We
look for a bounded solution to these equations, so that (in the event of small enough
disturbances) none of the state variables leave a neighborhood of the steady-state
values, in which our local approximation to the equilibrium conditions and our welfare
objective remain accurate.
26
Given the existence of such a bounded solution, the
transversality condition is necessarily satised, so that the solution to these rst-
order conditions represents an optimal plan.
An analytical solution to these equations is easily given. Using equation (3.2) to
substitute for
t
in the forward-integrated version of (2.9), then equations (3.4) and
(3.5) to substitute for y
t
as a function of the path of
2t
, and nally using (3.6) to
replace all terms of the form E
t
2,t+j
(for j 0) by
2t
, we obtain an equation that
can be solved for
2t
. The solution is of the form
2t
=
m
b
m
b
+n
b
2,t1
1
m
b
+n
b
[f
t
+ b
t1
],
coecients m
b
, n
b
are dened in the appendix. The implied dynamics of the govern-
ment debt are then given by
b
t
= E
t
f
t+1
n
b
2t
.
This allows a complete solution for the evolution of government debt and the multi-
plier, given the composite exogenous disturbance process {f
t
}, starting from initial
conditions b
t
0
1
and
2,t
0
1
.
27
Given these solutions, the optimal evolution of the
26
In the only such solution, the variables
t
, b
t
and y
t
are all permanently aected by shocks, even
when the disturbances are all assumed to be stationary (and bounded) processes. Hence a bounded
solution exists only under the assumption that random disturbances occur only in a nite number
of periods. However, our characterization of optimal policy does not depend on a particular bound
on the number of periods in which there are disturbances, or which periods these are; in order to
allow disturbances in a larger number of periods, we must assume a tighter bound on the amplitude
of disturbances, in order for the optimal paths of the endogenous variables to remain within a given
neighborhood of the steady-state values. Aiyagari et al. (2002) discuss the asymptotic behavior of
the optimal plan in the exact nonlinear version of a problem similar to this one, in the case that
disturbances occur indenitely.
27
The initial condition for
2,t
0
1
is in turn chosen so that the solution obtained is consistent
with the initial constraint y
t0
= y
t0
. Under policy that is optimal from a timeless perspective, this
initial commitment is in turn chosen in a self-consistent fashion, as discussed further in section 5.
Note that the specication of
2,t
0
1
does not aect our conclusions about the optimal responses
to shocks, emphasized in this section.
22
output gap and tax rate are given by
y
t
= m
2t
+n
2,t1
,
t
=
t
1
y
t
,
where m
, n
are again dened in the appendix. The evolution of ination remains
indeterminate. If we again assume a preference for ination stabilization when it is
costless, optimal policy involves
t
= 0 at all times.
In this case, unlike that of nominal debt, ination is not aected by a pure scal
shock (or indeed any other shock) under the optimal policy, but instead the output
gap and the tax rate are. Note also that in the above solution, the multiplier
2t
, the
output gap, and the tax rate all follow unit root processes: a temporary disturbance
to the scal stress permanently changes the level of each of these variables, as in the
analysis of the optimal dynamics of the tax rate in Barro (1979) and Bohn (1990).
However, the optimal evolution of the tax rate is not in general a pure random walk
as in the analysis of Barro and Bohn. Instead, the tax gap is an IMA(1,1) process,
as in the local analysis of Aiyagari et al. (2002); the optimal tax rate
t
may have
more complex dynamics, in the case that
t
exhibits stationary uctuations. In the
special case of linear utility (
1
= 0), n
= 0, and both the output gap and the tax
gap follow random walks (as both co-move with
2t
). If the only disturbances are
scal disturbances (
G
t
and
t
), then there are also no uctuations in
t
in this case,
so that the optimal tax rate follows a random walk.
More generally, we observe that optimal policy smooths
2t
, the value (in units
of marginal utility) of additional government revenue in period t, so that it follows
a random walk. This is the proper generalization of the Barro tax-smoothing result,
though it only implies smoothing of tax rates in fairly special cases. We nd a similar
result in the case that prices are sticky, even when government debt is not indexed,
as we now show.
4 Optimal Responses to Shocks: The Case of Sticky
Prices
We turn now to the characterization of the optimal responses to shocks in the case
that prices are sticky ( > 0). The optimization problem that provides a rst-
23
order characterization of optimal responses in this case is that of choosing processes
{
t
, y
t
,
t
,
b
t
} from date t
0
onward to minimize (2.4), subject to the constraints (2.7)
and (2.9) for each t t
0
, together with initial constraints of the form
t
0
=
t
0
, y
t
0
= y
t
0
,
given the initial condition
b
t
0
1
and the exogenous evolution of the composite distur-
bances {
t
, f
t
}. The Lagrangian for this problem can be written as
L
t
0
= E
t
0
t=t
0
tt
0
{
1
2
q
y
y
2
t
+
1
2
q
2
t
+
1t
[
1
t
+y
t
+
t
+
1
t+1
] +
+
2t
[
b
t1
1
y
t
(1 )(b
y
y
t
+b
t
) (
b
t
t+1
1
y
t+1
)]}
+[
1
1,t
0
1
+
2,t
0
1
]
t
0
+
1
2,t
0
y
t
0
,
by analogy with (3.3).
The rst-order condition with respect to
t
is given by
q
t
=
1
(
1t
1,t1
) + (
2t
2,t1
); (4.1)
that with respect to y
t
is given by
q
y
y
t
=
1t
+ [(1 )b
y
+
1
]
2t
2,t1
; (4.2)
that with respect to
t
is given by
1t
= (1 )b
2t
; (4.3)
and nally that with respect to
b
t
is given by
2t
= E
t
2,t+1
. (4.4)
These together with the two structural equations and the initial conditions are to
be solved for the state-contingent paths of {
t
,
Y
t
,
t
,
b
t
,
1t
,
2t
}. Note that the last
three rst order conditions are the same as for the exible-price model with indexed
debt; the rst condition (4.1) replaces the previous requirement that
t
= 0. Hence
the solution obtained in the previous section corresponds to a limiting case of this
problem, in which q
is made unboundedly large; for this reason the discussion above
of the more familiar case with exible prices and riskless indexed government debt
provides insight into the character of optimal policy in the present case as well.
24
In the unique bounded solution to these equations, the dynamics of government
debt and of the shadow value of government revenue
2t
are again of the form
2t
=
m
b
m
b
+n
b
2,t1
1
m
b
+n
b
[f
t
+
b
t1
],
b
t
= E
t
f
t+1
n
b
2t
,
though the coecient m
b
now diers from m
b
, in a way also described in the appendix.
The implied dynamics of ination and output gap are then given by
t
=
(
2t
2,t1
), (4.5)
y
t
= m
2t
+n
2,t1
, (4.6)
where m
, n
are dened as before, and
is dened in the appendix. The optimal
dynamics of the tax rate are those required to make these ination and output-
gap dynamics consistent with the aggregate-supply relation (2.7). Once again, the
optimal dynamics of ination, the output gap, and the public debt depend only on the
evolution of the scal stress variable {f
t
}; the dynamics of the tax rate also depend
on the evolution of {
t
}.
We now discuss the optimal response of the variables to a disturbance to the
level of scal stress. The laws of motion just derived for government debt and the
Lagrange multiplier imply that temporary disturbances to the level of scal stress
cause a permanent change in the level of both the Lagrange multiplier and the public
debt. This then implies a permanent change in the level of output as well, which in
turn requires (since ination is stationary) a permanent change in the level of the tax
rate. Since ination is proportional to the change in the Lagrange multiplier, the price
level moves in proportion to the multiplier, which means a temporary disturbance to
the scal stress results in a permanent change in the price level, as in the exible-
price case analyzed in the previous section. Thus in this case, the price level, output
gap, government debt, and tax rate all have unit roots, combining features of the
two special cases considered in the previous section.
28
Both price level and
2t
are
random walks. They jump immediately to new permanent level in response to change
in scal stress. In the case of purely transitory (white noise) disturbances, government
28
Schmitt-Grohe and Uribe (2001) similarly observe that in a model with sticky prices, the optimal
response of the tax rate is similar to what would be optimal in a exible-price model with riskless
indexed government debt.
25
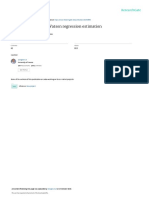
2 1 0 1 2 3 4 5 6 7 8
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
= 0.0236
= 0.05
= 0.1
= 0.25
= 1
= 25
=
Figure 1: Impulse response of the public debt to a pure scal shock, for alternative
degrees of price stickiness.
debt also jumps immediately to a new permanent level. Given the dynamics of the
price level and government debt, the dynamics of output and tax rate then jointly
determined by the aggregate-supply relation and the government budget constraint.
We further nd that the degree to which scal stress is relieved by a price-
level jump (as in the exible-price, nominal-debt case) as opposed to an increase
in government debt and hence a permanently higher tax rate (as in the exible-
price, indexed-debt case) depends on the degree of price stickiness. We illustrate
this with a numerical example. We calibrate a quarterly model by assuming that
= 0.99, = 0.473,
1
= 0.157, and = 0.0236, in accordance with the estimates
of Rotemberg and Woodford (1997). We furthermore assume an elasticity of substi-
tution among alternative goods of = 10, an overall level of steady-state distortions
= 1/3, a steady-state tax rate of = 0.2, and a steady-state debt level
b/
Y = 2.4
(debt equal to 60 percent of a years GDP). Given the assumed degree of market
power of producers (a steady-state gross price markup of 1.11) and the assumed size
26
2 1 0 1 2 3 4 5 6 7 8
0.4
0.3
0.2
0.1
0
0.1
0.2
0.3
= 0.0236
= 0.05
= 0.1
= 0.25
= 1
= 25
=
Figure 2: Impulse response of the tax rate to a pure scal shock.
of the tax wedge, the value = 1/3 corresponds to a steady-state wage markup of
w
= 1.08. If we assume that there are no government transfers in the steady state,
then the assumed level of tax revenues net of debt service would nance steady-state
government purchases equal to a share s
G
= 0.176 of output.
Let us suppose that the economy is disturbed by an exogenous increase in transfer
programs
t
, equal to one percent of aggregate output, and expected to last only for
the current quarter. Figure 1 shows the optimal impulse response of the government
debt
b
t
to this shock (where quarter zero is the quarter of the shock), for each of 7
dierent values for , the slope of the short-run aggregate-supply relation, maintaining
the values just stated for the other parameters of the model. The solid line indicates
the optimal response in the case of our baseline value for , based on the estimates
of Rotemberg and Woodford; the other cases represent progressively greater degrees
of price exibility, up to the limiting case of fully exible prices (the case = ).
Figures 2 and 3 similarly show the optimal responses of the tax rate and the ination
27
2 1 0 1 2 3 4 5 6 7 8
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
= 0.0236
= 0.05
= 0.1
= 0.25
= 1
= 25
=
Figure 3: Impulse response of the ination rate to a pure scal shock.
rate to the same disturbance, for each of the same 7 cases.
29
We see that the volatility of both ination and tax rates under optimal policy
depends greatly on the degree of stickiness of prices. Table 1 reports the initial
quarters response of the ination rate, and the long-run response of the tax rate, for
each of the 7 cases. The table also indicates for each case the implied average time
(in weeks) between price changes, T (log )
1
, where 0 < < 1 is the fraction
of prices unchanged for an entire quarter implied by the assumed value of .
30
We
29
In gure 1, a response of 1 means a one percent increase in the value of b
t
, from 60 percent to
60.6 percent of a years GDP. In gure 2, a response of 1 means a one percent decrease in
t
, from
20 percent to 20.2 percent. In gure 3, a response of 1 means a one percent per annum increase
in the ination rate, or an increase of the price level from 1 to 1.0025 over the course of a quarter
(given that our model is quarterly). The responses reported in Table 1 are measured in the same
way.
30
We have used the relation between and T for a continuous-time version of the Calvo model
in order to express the degree of price stickiness in terms of an average time between price changes.
28
Table 1: Immediate responses for alternative degrees of price stickiness.
T
0
.024 29 .072 .021
.05 20 .076 .024
.10 14 .077 .030
.25 9 .078 .044
1.0 5.4 .075 .113
25 2.4 .032 .998
0 0 1.651
rst note that our baseline calibration implies that price changes occur only slightly
less frequently than twice per year, which is consistent with survey evidence.
31
Next,
we observe that even were we to assume an aggregate-supply relation several times
as steep as the one estimated using U.S. data, our conclusions with regard to the size
of the optimal responses of the (long-run) tax rate and the ination rate would be
fairly similar. At the same time, the optimal responses with fully exible prices are
quite dierent: the response of ination is 80 times as large as under the baseline
sticky-price calibration (implying a variance of ination 6400 times as large), while the
long-run tax rate does not respond at all in the exible-price case.
32
But even a small
degree of stickiness of prices makes a dramatic dierence in the optimal responses;
for example, if prices are revised only every ve weeks on average, the variance of
ination is reduced by a factor of more than 200, while the optimal response of the
long-run tax rate to the increased revenue need is nearly the same size as under the
31
The indicated average time between price changes for the baseline case is shorter than that
reported in Rotemberg and Woodford (1997), both because we here assume a slightly larger value
of , implying a smaller value of , and because of the continuous-time method used here to convert
into an implied average time interval.
32
The tax rate does respond in the quarter of the shock in the case of exible prices, but with the
opposite sign to that associated with optimal policy under our baseline calibration. Under exible
prices, as discussed above, the tax rate does not respond to variations in scal stress at all. Because
the increase in government transfers raises the optimal level of output
Y
0
, for reasons explained
in the appendix, the optimal tax rate
0
actually falls, in order to induce equilibrium output to
increase; and under exible prices, this is the optimal response of
0
.
29
baseline degree of price stickiness. Thus we nd, as do Schmitt-Grohe and Uribe
(2001) in the context of a calibrated model with convex costs of price adjustment,
that the conclusions of the exible-price analysis are quite misleading if prices are
even slightly sticky. Under a realistic calibration of the degree of price stickiness,
ination should be quite stable, even in response to disturbances with substantial
consequences for the governments budget constraint, while tax rates should instead
respond substantially (and with a unit root) to variations in scal stress.
We can also compare our results with those that arise when taxes are lump-sum.
In this case, = 0, and the rst-order condition (4.3) requires that
2t
= 0. The
remaining rst-order conditions reduce to
q
t
=
1
(
1t
1,t1
),
q
y
y
t
=
1t
for each t t
0
as in Clarida et al. (1999) and Woodford (2003, chapter 7). In this
case the scal stress is no longer relevant for ination or output-gap determination.
Instead, only the cost-push shock u
t
is responsible for incomplete stabilization. The
determinants of the cost-push eects of underlying disturbances, and of the target
output level
Y
t
are also somewhat dierent, because in this case
1
= 0. For example,
a pure scal shock has no cost-push eect, nor any eect on
Y
t
, and hence no eect
on the optimal evolution of either ination or output.
33
Furthermore, as shown in the
references just mentioned, the price level no longer follows a random walk; instead,
it is a stationary variable. Increases in the price level due to a cost-push shock are
subsequently undone by period of deation.
Note that the familiar case from the literature on monetary stabilization policy
does not result simply from assuming that sources of revenue that do not shift the
aggregate-supply relation are available; it is also important that the sort of tax that
does shift the AS relation (like the sales tax here) is not available. We could nest
both the standard model and our present baseline case within a single, more general
framework by assuming that revenue can be raised using either the sales tax or a lump-
sum tax, but that there is an additional convex cost (perhaps representing collection
costs, assumed to reduce the utility of the representative household but not using
33
See Benigno and Woodford (2003) for detailed analysis of the determinants of u
t
and
Y
t
in this
case.
30
real resources) of increases in either tax rate. The standard case would then appear as
the limiting case of this model in which the collection costs associated with the sales
tax are innite, while those associated with the lump-sum tax are zero; the baseline
model here would correspond to an alternative limiting case in which the collection
costs associated with the lump-sum tax are innite, while those associated with the
sales tax are zero. In intermediate cases, we would continue to nd that scal stress
aects the optimal evolution of both ination and the output gap, as long as there is
a positive collection cost for the lump-sum tax. At the same time, the result that the
shadow value of additional government revenue follows a random walk under optimal
policy (which would still be true) will not in general imply, as it does here, that the
price level should also be a random walk; for the perfect co-movement of
1t
and
2t
that characterizes optimal policy in our baseline case will not be implied by the
rst-order conditions except in the case that there are no collection costs associated
with the sales tax. Nonetheless, the price level will generally contain a unit root
under optimal policy, even if it will not generally follow a random walk.
We also obtain results more similar to those in the standard literature on monetary
stabilization policy if we assume (realistically) that it is not possible to adjust tax
rates on such short notice in response to shocks as is possible with monetary policy.
As a simple way of introducing delays in the adjustment of tax policy, suppose that
the tax rate
t
has to be xed in period t d. In this case, the rst-order conditions
characterizing optimal responses to shocks are the same as above, except that (4.3)
is replaced by
E
t
1,t+d
= (1 )b
E
t
2,t+d
(4.7)
for each t t
0
. In this case, the rst-order conditions imply that E
t
t+d+1
= 0, but no
longer imply that changes in the price level must be unforecastable from one period
to the next. As a result, price-level increases in response to disturbances are typically
partially, but not completely, undone in subsequent periods. Yet there continues to
be a unit root in the price level (of at least a small innovation variance), even in the
case of an arbitrarily long delay d in the adjustment of tax rates.
31
5 Optimal Targeting Rules for Monetary and Fis-
cal Policy
We now wish to characterize the policy rules that the monetary and scal authorities
can follow in order to bring about the state-contingent responses to shocks described
in the previous section. One might think that it suces to solve for the optimal state-
contingent paths for the policy instruments. But in general this is not a desirable
approach to the specication of a policy rule, as discussed in Svensson (2003) and
Woodford (2003, chapter 7). A description of optimal policy in these terms would
require enumeration of all of the types of shocks that might be encountered later,
indenitely far in the future, which is not feasible in practice. A commitment to
a state-contingent instrument path, even when possible, also may not determine the
optimal equilibrium as the locally unique rational-expectations equilibrium consistent
with this policy; many other (much less desirable) equilibria may also be consistent
with the same state-contingent instrument path.
Instead, we here specify targeting rules in the sense of Svensson (1999, 2003)
and Giannoni and Woodford (2003). These targeting rules are commitments on the
part of the policy authorities to adjust their respective instruments so as to ensure
that the projected paths of the endogenous variables satisfy certain target criteria.
We show that under an appropriate choice of these target criteria, a commitment
to ensure that they hold at all times will determine a unique non-explosive rational-
expectations equilibrium, in which the state-contingent evolution of ination, output
and the tax rate solves the optimization problem discussed in the previous section.
Moreover, we show that it is possible to obtain a specication of the policy rules that
is robust to alternative specications of the exogenous shock processes.
We apply the general approach of Giannoni and Woodford (2002), which allows
the derivation of optimal target criteria with the properties just stated. In addition,
Giannoni and Woodford show that such target criteria can be formulated that re-
fer only to the projected paths of the target variables (the ones in terms of which
the stabilization objectives of policy are dened here, ination and the output
gap). Briey, the method involves constructing the target criteria by eliminating
the Lagrange multipliers from the system of the system of rst-order conditions that
characterize the optimal state-contingent evolution, regardless of character of the (ad-
ditive) disturbances. We are left with linear relations among the target variables, that
32
do not involve the disturbances and with coecients independent of the specication
of the disturbances, that represent the desired target criteria.
Recall that the rst-order conditions that characterize the optimal state-contingent
paths in the problem considered in the previous section are given by (4.1) (4.4). As
explained in the previous section, the rst three of these conditions imply that the
evolution of ination and of the output gap must satisfy (4.5) (4.6) each period.
We can solve (4.5) (4.6) for the values of
2t
,
2,t1
implied by the values of
t
, y
t
that are observed in an optimal equilibrium. We can then replace
2,t1
in these
two relations by the multiplier implied in this way by observed values of
t1
, y
t1
.
Finally, we can eliminate
2t
from these two relations, to obtain a necessary relation
between
t
and y
t
, given
t1
and y
t1
, given by
t
+
n
t1
+
(y
t
y
t1
) = 0. (5.1)
This target criterion has the form of a exible ination target, similar to the optimal
target criterion for monetary policy in model with lump-sum taxation (Woodford,
2003, chapter 7). It is interesting to note that, as in all of the examples of optimal
target criteria for monetary policy derived under varying assumptions in Giannoni
and Woodford (2003), it is only the projected rate of change of the output gap that
matters for determining the appropriate adjustment of the near-term ination target;
the absolute level of the output gap is irrelevant.
The remaining rst-order condition from the previous section, not used in the
derivation of (5.1), is (4.4). By similarly using the solutions for
2,t+1
,
2t
implied
by observations of
t+1
, y
t+1
to substitute for the multipliers in this condition, one
obtains a further target criterion
E
t
t+1
= 0 (5.2)
(Note that the fact that this always holds in the optimal equilibrium i.e., that
the price level must follow a random walk has already been noted in the previous
section.) We show in the appendix that policies that ensure that (5.1) (5.2) hold
for all t t
0
determine a unique non-explosive rational-expectations equilibrium.
Moreover, this equilibrium solves the above rst-order conditions for a particular
specication of the initial lagged multipliers
1,t
0
1
,
2,t
0
1
, which are inferred from
the initial values
t
0
1
, y
t
0
1
in the way just explained. Hence this equilibrium mini-
mizes expected discounted losses (2.4) given
b
t
0
1
and subject to constraints on initial
33
outcomes of the form
t
0
= (
t
0
1
, y
t
0
1
), (5.3)
y
t
0
= y(
t
0
1
, y
t
0
1
). (5.4)
Furthermore, these constraints are self-consistent in the sense that the equilibrium
that solves this problem is one in which
t
, y
t
are chosen to satisfy equations of
this form in all periods t > t
0
. Hence these time-invariant policy rules are optimal
from a timeless perspective.
34
And they are optimal regardless of the specication
of disturbance processes. Thus we have obtained robustly optimal target criteria, as
desired.
We have established a pair of target criteria with the property that if they are
expected to be jointly satised each period, the resulting equilibrium involves the
optimal responses to shocks. This result in itself, however, does not establish which
policy instrument should be used to ensure satisfaction of which criterion. Since the
variables referred to in both criteria can be aected by both monetary and scal
policy, there is not a uniquely appropriate answer to that question. However, the
following represents a relatively simple example of a way in which such a regime could
be institutionalized through separate targeting procedures on the part of monetary
and scal authorities.
Let the central bank be assigned the task of maximizing social welfare through
its adjustment of the level of short-term interest rates, taking as given the state-
contingent evolution of the public debt {
b
t
}, which depends on the decisions of the
scal authority. Thus the central bank treats the evolution of the public debt as
being outside its control, just like the exogenous disturbances {
t
}, and simply seeks
to forecast its evolution in order to correctly model the constraints on its own policy.
Here we do not propose a regime under which it is actually true that the evolution of
the public debt would be unaected by a change in monetary policy. But there is no
inconsistency in the central banks assumption (since a given bounded process {
b
t
}
will continue to represent a feasible scal policy regardless of the policy adopted by
the central bank), and we shall show that the conduct of policy under this assumption
does not lead to a suboptimal outcome, as long as the state-contingent evolution of
the public debt is correctly forecasted by the central bank.
34
See Woodford (2003, chapters 7, 8) for further discussion of the self-consistency condition that
the initial constraints are required to satisfy.
34
The central bank then seeks to bring about paths for {
t
, y
t
,
t
} from date t
0
onward that minimize (2.4), subject to the constraints (2.7) and (2.9) for each t t
0
,
together with initial constraints of the form (5.3) (5.4), given the evolution of the
processes {
t
, f
t
,
b
t
}. The rst-order conditions for this optimization problem are
given by (4.1), (4.2) and (4.4) each period, which in turn imply that (5.1) must
hold each period, as shown above. One can further show that a commitment by
the central bank to ensure that (5.1) holds each period determines the equilibrium
evolution that solves this problem, in the case of an appropriate (self-consistent)
choice of the initial constraints (5.3) (5.4). Thus (5.1) is an optimal target criterion
for a policy authority seeking to solve the kind of problem just posed; and since the
problem takes as given the evolution of the public debt, it is obviously a more suitable
assignment for the central bank than for the scal authority. The kind of interest-rate
reaction function that can be used to implement a exible ination target of this
kind is discussed in Svensson and Woodford (2003) and Woodford (2003, chapter 7).
Correspondingly, let the scal authority be assigned the task of choosing the level
of government revenue each period that will maximize social welfare, taking as given
the state-contingent evolution of output {y
t
}, which it regards as being determined by
monetary policy. (Again, it need not really be the case that the central bank ensures
a particular state-contingent path of output, regardless of what the scal authority
does. But again, this assumption is not inconsistent with our model of the economy,
since it is possible for the central bank to bring about any bounded process {y
t
} that
it wishes, regardless of scal policy, in the case that prices are sticky.) If the scal
authority regards the evolution of output as outside its control, its objective reduces
to the minimization of
E
t
0
t=t
0
tt
0
2
t
. (5.5)
But this is a possible objective for scal policy, given the eects of tax policy on
ination dynamics (when taxes are not lump-sum) indicated by (2.7).
Forward integration of (2.7) implies that
t
= E
t
T=t
Tt
y
T
+E
t
T=t
Tt
(
T
T
). (5.6)
Thus what matters about scal policy for current ination determination is the
present value of expected tax rates; but this in turn is constrained by the intertempo-
ral solvency condition (2.9). Using (2.9) to substitute for the present value of taxes
35
in (5.6), we obtain a relation of the form
t
=
1
[
b
t1
1
y
t
+f
t
] +
2
E
t
T=t
Tt
y
T
, (5.7)
for certain coecients
1
,
2
> 0 dened in the appendix. If the scal authority
takes the evolution of output as given, then this relation implies that its policy in
period t can have no eect on
t
. However, it can aect ination in the following
period through the eects the current government budget on
b
t
. Furthermore, since
the choice of
b
t
has no eect on ination in later periods (given that it places no
constraint on the level of public debt that may be chosen in later periods),
b
t
should
be chosen so as to minimize E
t
2
t+1
.
The rst-order condition for the optimal choice of
b
t
is then simply (5.2), which
we nd is indeed a suitable target criterion for the scal authority. The decision rule
implied by this target criterion is seen to be
b
t
= E
t
f
t+1
+
1
E
t
y
t+1
(
2
/
1
)E
t
T=t+1
Tt1
y
T
,
which expresses the optimal level of government borrowing as a function of the scal
authoritys projections of the exogenous determinants of scal stress and of future
real activity. It is clearly possible for the scal authority to implement this target
criterion, and doing so leads to a determinate equilibrium path for ination, given
the path of output. We thus obtain a pair of targeting rules, one for the central bank
and one for the scal authority, that if both pursued will implement an equilibrium
that is optimal from a timeless perspective. Furthermore, each individual rule can be
rationalized as a solution to a constrained optimization problem that the particular
policy authority is assigned to solve.
6 Conclusion
We have shown that it is possible to jointly analyze optimal monetary and scal policy
within a single framework. The two problems, often considered in isolation, turn out
to be more closely related than might have been expected. In particular, we nd that
variations in the level of distorting taxes should be chosen to serve the same objectives
as those emphasized in the literature on monetary stabilization policy: stabilization
36
of ination and of a (properly dened) output gap. A single output gap can be
dened that measures the total distortion of the level of economic activity, resulting
both from the stickiness of prices (and the consequent variation in markups) and from
the supply-side eects of tax distortions. It is this cumulative gap that one wishes
to stabilize, rather than the individual components resulting from the two sources;
and both monetary policy and tax policy can be used to aect it. Both monetary
policy and tax policy also matter for ination determination in our model, because
of the eects of the tax rate on real marginal cost and hence on the aggregate-supply
relation. Indeed, we have exhibited a pair of robustly optimal targeting rules for the
monetary and scal authorities respectively, under which both authorities consider
the consequences of their actions for near-term ination projections in determining
how to adjust their instruments.
And not only should the scal authority use tax policy to serve the traditional
goals of monetary stabilization policy; we also nd that the monetary authority should
take account of the consequences of its actions for the government budget. In the
present model, that abstracts entirely from transactions frictions, these consequences
have solely to do with the implications of alternative price-level and interest-rate paths
for the real burden of interest payments on the public debt, and not any contribution
of seignorage to government revenues. Nonetheless, under a calibration of our model
that assumes a debt burden and a level of distorting taxes that would not be unusual
for an advanced industrial economy, taking account of the existence of a positive
shadow value of additional government revenue (owing to the non-existence of lump-
sum taxes) makes a material dierence for the quantitative characterization of optimal
monetary policy. In fact, we have found that the crucial summary statistic that
indicates the degree to which various types of real disturbances should be allowed to
aect short-run projections for either ination or the output gap is not the degree to
which these disturbances shift the aggregate-supply curve for a given tax rate (i.e., the
extent to which they represent cost-push shocks), but rather the degree to which
they create scal stress (shift the intertemporal government solvency condition).
Our conclusion that monetary policy should take account of the requirements for
government solvency does not imply anything as strong as the result of Chari and
Kehoe (1999) for a exible-price economy with nominal government debt, according
to which surprise variations in the ination rate should be used to completely oset
variations in scal stress, so that tax rates need not vary (other than as necessary to
37
stabilize the output gap). We nd that in the case of even a modest degree of price
stickiness much less than what seems to be consistent with empirical evidence
for the U.S. it is not optimal for ination to respond to variations in scal stress
by more than a tiny fraction of the amount that would be required to eliminate
the scal stress (and that would be optimal with fully exible prices); instead, a
substantial part of the adjustment should come through a change in the tax rate.
But the way in which the acceptable short-run ination projection should be aected
by variations in the projected output gap is substantially dierent in an economy with
only distorting taxes than would be the case in the presence of lump-sum taxation.
For with distorting taxes, the available tradeo between variations in ination and in
the output gap depends not only on the way these variables are related to one another
through the aggregate-supply relation, but also on the way that each of them aects
the government budget.
38
A Appendix
A.1 Derivation of the aggregate-supply relation (equation
(1.11))
In this section, we derive equation (1.11) in the main text and we dene the variables
F
t
and K
t
. In the Calvo model, a supplier that changes its price in period t chooses
a new price p
t
(i) to maximize
E
t
_
T=t
Tt
Q
t,T
(p
t
(i), p
j
T
, P
T
; Y
T
,
T
,
T
)
_
,
where
Tt
is the probability that the price set at time t remains xed in period T,
Q
t,T
is the stochastic discount factor given by (1.7), and the prot function () is
dened as
(p, p
j
, P; Y, , ) (1)pY (p/P)
w
v
h
(f
1
(Y (p
j
/P)
/A); )
u
c
(Y G; )
Pf
1
(Y (p/P)
/A).
(A.8)
Here Dixit-Stiglitz monopolistic competition implies that the individual supplier
faces a demand curve each period of the form
y
t
(i) = Y
t
(p
t
(i)/P
t
)
,
so that after-tax sales revenues are the function of p given in the rst term on the
right-hand side of (A.8). The second term indicates the nominal wage bill, obtained by
inverting the production function to obtain the required labor input, and multiplying
this by the industry wage for sector j. The industry wage is obtained from the labor
supply equation (1.8), under the assumption that each of the rms in industry j
(other than i, assumed to have a negligible eect on industry labor demand) charges
the common price p
j
. (Because all rms in a given industry are assumed to adjust
their prices at the same time, in equilibrium the prices of rms in a given industry are
always identical. We must nonetheless dene the prot function for the case in which
rm i deviates from the industry price, in order to determine whether the industry
price is optimal for each individual rm.)
We note that supplier is prots are a concave function of the quantity sold y
t
(i),
since revenues are proportional to y
1
t
(i) and hence concave in y
t
(i), while costs are
39
convex in y
t
(i). Moreover, since y
t
(i) is proportional to p
t
(i)
, the prot function is
also concave in p
t
(i)
. The rst-order condition for the optimal choice of the price
p
t
(i) is the same as the one with respect to p
t
(i)
; hence the rst-order condition
with respect to p
t
(i) is both necessary and sucient for an optimum.
For this rst-order condition, we obtain
E
t
_
T=t
Tt
Q
t,T
_
p
t
(i)
P
T
_
Y
T
T
(p
t
(i), p
j
t
)
_
= 0,
with
T
(p, p
j
)
_
(1
T
)
1
w
T
v
h
(f
1
(Y
T
(p
j
/P
T
)
/A
T
);
T
)
u
c
(Y
T
G
T
;
T
) A
T
f
(f
1
(Y
T
(p/P
T
)
/A
T
))
P
T
p
_
Using the denitions
u(Y
t
;
t
) u(Y
t
G
t
;
t
),
v(y
t
(i);
t
) v(f
1
(y
t
(i)/A
t
);
t
) = v(H
t
(i);
t
),
and noting that each rm in an industry will set the same price, so that p
t
(i) = p
j
t
=
p
t
, the common price of all goods with prices revised at date t, we can rewrite the
above rst-order condition as
E
t
_
T=t
()
Tt
Q
t,T
_
p
t
P
T
_
Y
T
_
(1
T
)
1
w
T
v
y
(Y
T
(p
t
/P
T
)
;
T
)
u
c
(Y
T
;
T
)
P
T
p
t
_
_
= 0.
Substituting the equilibrium value for the discount factor, we nally obtain
E
t
_
T=t
Tt
u
c
(Y
T
;
T
)
_
p
t
P
T
_
Y
T
_
p
t
P
T
(1
T
)
1
w
T
v
y
(Y
T
(p
t
/P
T
)
;
T
)
u
c
(Y
T
;
T
)
_
_
= 0.
(A.9)
Using the isoelastic functional forms given in the text, we obtain a closed-form
solution to (A.9), given by
p
t
P
t
=
_
K
t
F
t
_ 1
1+
, (A.10)
where F
t
and K
t
are aggregate variables of the form
F
t
E
t
T=t
()
Tt
(1
T
)f(Y
T
;
T
)
_
P
T
P
t
_
1
, (A.11)
40
K
t
E
t
T=t
()
Tt
k(Y
T
;
T
)
_
P
T
P
t
_
(1+)
, (A.12)
in which expressions
f(Y ; ) u
c
(Y ; )Y, (A.13)
k(Y ; )
1
w
v
y
(Y ; )Y, (A.14)
and where in the function k(), the vector of shocks has been extended to include the
shock
w
t
. Substitution of (A.10) into the law of motion for the Dixit-Stiglitz price
index
P
t
=
_
(1 )p
1
t
+P
1
t1
1
1
(A.15)
yields a short-run aggregate-supply relation between ination and output of the form
(1.11) in the text.
A.2 Recursive formulation of the policy problem
Under the standard (Ramsey) approach to the characterization of an optimal policy
commitment, one chooses among state-contingent paths {
t
, Y
t
,
t
, b
t
,
t
} from some
initial date t
0
onward that satisfy
1
1
t
1
=
_
F
t
K
t
_ 1
1+
, (A.16)
t
= h(
t1
,
t
), (A.17)
b
t1
P
t1
P
t
= E
t
T=t
R
t,T
s
T
, (A.18)
where
s
t
t
Y
t
G
t
t
(A.19)
for each t t
0
, given initial government debt b
t
0
1
and price dispersion
t
0
1
, so as
to maximize
U
t
0
= E
t
0
t=t
0
tt
0
U(Y
t
,
t
;
t
). (A.20)
Here we note that the denition (1.3) of the index of price dispersion implies the law
of motion
t
=
t1
(1+)
t
+ (1 )
_
1
1
t
1
_
(1+)
1
, (A.21)
41
which can be written in the form (A.17); this is the origin of that constraint.
We now show that the t
0
optimal plan (Ramsey problem) can be obtained as the
solution to a two-stage optimization problem. To this purpose, let
W
t
E
t
T=t
Tt
u
c
(Y
T
G
T
;
T
)s
T
,
and let F be the set of values for (b
t1
,
t1
, F
t
, K
t
, W
t
) such that there exist paths
{
T
, Y
T
,
T
, b
T
,
T
} for dates T t that satisfy (A.16), (A.17) and (A.18) for each T,
that are consistent with the specied values for F
t
, K
t
, dened in (A.23) and (A.24),
and W
t
, and that imply a well-dened value for the objective U
t
dened in (A.20).
Furthermore, for any (b
t1
,
t1
, F
t
, K
t
, W
t
) F, let V (b
t1
,
t1
, X
t
;
t
) denote the
maximum attainable value of U
t
among the state-contingent paths that satisfy the
constraints just mentioned, where X
t
(F
t
, K
t
, W
t
).
35
Among these constraints is
the requirement that
W
t
=
b
t1
t
u
c
(Y
t
G
t
;
t
), (A.22)
in order for (A.18) to be satised. Thus a specied value for W
t
implies a restriction
on the possible values of
t
and Y
t
, given the predetermined real debt b
t1
and the
exogenous disturbances.
The two-stage optimization problem is the following. In the rst stage, values
of the endogenous variables x
t
0
, where x
t
(
t
, Y
t
,
t
, b
t
,
t
), and state-contingent
commitments X
t
0
+1
(
t
0
+1
) for the following period, are chosen so as to maximize
an objective dened below. In the second stage, the equilibrium evolution from
period t
0
+ 1 onward is chosen to solve the maximization problem that denes the
value function V (b
t
0
,
t
0
, X
t
0
+1
;
t
0
+1
), given the state of the world
t
0
+1
and the
precommitted values for X
t
0
+1
associated with that state.
In dening the objective for the rst stage of this equivalent formulation of the
Ramsey problem, it is useful to let (F, K) denote the value of
t
that solves (A.16)
for given values of F
t
and K
t
, and to let s(x; ) denote the real primary surplus s
t
dened by (A.19) in the case of given values of x
t
and
t
. We also dene the functional
relationships
J[x, X()](
t
) U(Y
t
,
t
;
t
) +E
t
V (b
t
,
t
, X
t+1
;
t+1
),
35
As stated in the text, in our notation for the value function V,
t
denotes not simply the vector
of disturbances in period t, but all information in period t about current and future disturbances.
42
F[x, X()](
t
) (1
t
)f(Y
t
;
t
) +E
t
{(F
t+1
, K
t+1
)
1
F
t+1
},
K[x, X()](
t
) k(Y
t
;
t
) +E
t
{(F
t+1
, K
t+1
)
(1+)
K
t+1
},
W[x, X()](
t
) u
c
(Y
t
G
t
;
t
)s(x
t
;
t
) +E
t
W
t+1
,
where f(Y ; ) and k(Y ; ) are dened in (A.13) and (A.14).
Then in the rst stage, x
t
0
and X
t
0
+1
() are chosen so as to maximize
J[x
t
0
, X
t
0
+1
()](
t
0
) (A.23)
over values of x
t
0
and X
t
0
+1
() such that
(i)
t
0
and
t
0
satisfy (A.17);
(ii) the values
F
t
0
=
F[x
t
0
, X
t
0
+1
()](
t
0
), (A.24)
K
t
0
=
K[x
t
0
, X
t
0
+1
()](
t
0
) (A.25)
satisfy
t
0
= (F
t
0
, K
t
0
); (A.26)
(iii) the value
W
t
0
=
W[x
t
0
, X
t
0
+1
()](
t
0
) (A.27)
satises (A.22) for t = t
0
; and
(iv) the choices (b
t
0
,
t
0
, X
t
0
+1
) F for each possible state of the world
t
0
+1
.
These constraints imply that the objective
J[x
t
0
, X
t
0
+1
()](
t
0
) is well-dened, and
that values (x
t
0
, X
t
0
+1
()) are chosen for which the stage two problem will be well-
dened, whichever state of the world is realized in period t
0
+ 1. Furthermore, in
the case of any stage-one choices consistent with the above constraints, and any
subsequent evolution consistent with the constraints of the stage-two problem, (A.26)
implies that (A.16) is satised in period t
0
, while (A.22) implies that (A.18) is satised
in period t
0
. Constraint (i) above implies that (A.17) is also satised in period t
0
.
Finally, the constraints of the stage-two problem imply that both (A.16), (A.17) and
(A.18) are satised in each period t t
0
+ 1; thus the state-contingent evolution
that solves the two-stage problem is a rational-expectations equilibrium. Conversely,
one can show that any possible rational-expectations equilibrium satises all of these
constraints.
One can then reformulate the Ramsey problem, replacing the set of requirements
for rational-expectations equilibrium by the stage-one constraints plus the stage-two
43
constraints. Since no aspect of the evolution from period t
0
+1 onward, other than the
specication of X
t
0
+1
(), aects the stage-one constraints, the optimization problem
decomposes into the two stages dened above, where the objective (A.23) corresponds
to the maximization of U
t
0
in the rst stage.
The optimization problem in stage two of this reformulation of the Ramsey prob-
lem is of the same form as the Ramsey problem itself, except that there are additional
constraints associated with the precommitted values for the elements of X
t
0
+1
(
t
0
+1
).
Let us consider a problem like the Ramsey problem just dened, looking forward from
some period t
0
, except under the constraints that the quantities X
t
0
must take certain
given values, where (b
t
0
1
,
t
0
1
, X
t
0
) F. This constrained problem can similarly
be expressed as a two-stage problem of the same form as above, with an identical
stage two problem to the one described above. The stage one problem is also identical
to stage one of the Ramsey problem, except that now the plan chosen in stage one
must be consistent with the given values X
t
0
, so that conditions (A.24), (A.25) and
(A.27) are now added to the constraints on the possible choices of (x
t
0
, X
t
0
+1
()) in
stage one. (The stipulation that (b
t
0
1
,
t
0
1
, X
t
0
) F implies that the constraint
set remains non-empty despite these additional restrictions.)
Stage two of this constrained problem is thus of exactly the same form as the prob-
lem itself. Hence the constrained problem has a recursive form. It can be decomposed
into an innite sequence of problems, in which in each period t, (x
t
, X
t+1
()) are cho-
sen to maximize
J[x
t
, X
t+1
()](
t
), given the predetermined state variables (b
t1
,
t1
)
and the precommitted values X
t
, subject to the constraints that
(i)
t
is given by (A.26), Y
t
is then given by (A.22), and
t
is given by (A.17);
(ii) the precommitted values X
t
are fullled, i.e.,
F[x
t
, X
t+1
()](
t
) = F
t
, (A.28)
K[x
t
, X
t+1
()](
t
) = K
t
, (A.29)
W[x
t
, X
t+1
()](
t
) = W
t
; (A.30)
and
(iii) the choices (b
t
,
t
, X
t+1
) F for each possible state of the world
t+1
.
Our aim in the paper is to provide a local characterization of policy that solves
this recursive optimization, in the event of small enough disturbances, and initial
conditions (b
t
0
1
,
t
0
1
, X
t
) F that are close enough to consistency with the steady
state characterized in the next section of this appendix.
44
A.3 The deterministic steady state
Here we show the existence of a steady state, i.e., of an optimal policy (under appro-
priate initial conditions) of the recursive policy problem just dened that involves
constant values of all variables. We now consider a deterministic problem in which
the exogenous disturbances
C
t
, G
t
,
H
t
, A
t
,
w
t
,
t
each take constant values
C,
H,
A,
w
> 0 and
G,
0 for all t t
0
, and we start from initial conditions b
t
0
1
=
b > 0.
(The value of
b is arbitrary, subject to an upper bound discussed below.) We wish
to nd an initial degree of price dispersion
t
0
1
and initial commitments X
t
0
=
X
such that the recursive (or stage two) problem involves a constant policy x
t
0
= x,
X
t+1
=
X each period, in which
b is equal to the initial real debt and
is equal to
the initial price dispersion.
We thus consider the problem of maximizing
U
t
0
=
t=t
0
tt
0
U(Y
t
,
t
) (A.31)
subject to the constraints
K
t
p(
t
)
1+
1
= F
t
, (A.32)
F
t
= (1
t
)f(Y
t
) +
1
t+1
F
t+1
, (A.33)
K
t
= k(Y
t
) +
(1+)
t+1
K
t+1
, (A.34)
W
t
= u
c
(Y
t
)(
t
Y
t
) +W
t+1
, (A.35)
W
t
=
u
c
(Y
t
)b
t1
t
, (A.36)
t
=
t1
(1+)
t
+ (1 )p(
t
)
(1+)
1
, (A.37)
and given the specied initial conditions b
t
0
1
,
t
0
1
, X
t
0
, where we have dened
p(
t
)
_
1
1
t
1
_
.
We introduce Lagrange multipliers
1t
through
6t
corresponding to constraints
(A.32) through (A.37) respectively. We also introduce multipliers dated t
0
corre-
sponding to the constraints implied by the initial conditions X
t
0
=
X; the latter
multipliers are normalized in such a way that the rst-order conditions take the same
45
form at date t
0
as at all later dates. The rst-order conditions of the maximization
problem are then the following. The one with respect to Y
t
is
U
y
(Y
t
,
t
) (1
t
)f
y
(Y
t
)
2t
k
y
(Y
t
)
3t
t
f
y
(Y
t
)
4t
+
+u
cc
(Y
t
)(
G+
)
4t
u
cc
(Y
t
)b
t1
1
t
5t
= 0; (A.38)
that with respect to
t
is
U
(Y
t
,
t
) +
6t
(1+)
t+1
6,t+1
= 0; (A.39)
that with respect to
t
is
1 +
1
p(
t
)
(1+)
1
1
p
(
t
)K
t
1,t
( 1)
2
t
F
t
2,t1
(1 +)
(1+)1
t
K
t
3,t1
+u
c
(Y
t
)b
t1
2
t
5t
+
(1 +)
t1
(1+)1
t
6t
(1 +)
1
(1 )p(
t
)
(1+)
1
p
(
t
)
6t
= 0; (A.40)
that with respect to
t
is
2t
4t
= 0; (A.41)
that with respect to F
t
is
1t
+
2t
1
t
2,t1
= 0; (A.42)
that with respect to K
t
is
p(
t
)
1+
1
1t
+
3t
(1+)
t
3,t1
= 0; (A.43)
that with respect to W
t
is
4t
4,t1
+
5t
= 0; (A.44)
and nally, that with respect to b
t
is
5t
= 0. (A.45)
We search for a solution to these rst-order conditions in which
t
=
,
t
=
, Y
t
=
Y ,
t
= and b
t
=
b at all times. A steady-state solution of this kind
also requires that the Lagrange multipliers take constant values. We furthermore
conjecture the existence of a solution in which
= 1, as stated in the text. Note
46
that such a solution implies that
= 1, p(
) = 1, p
) = ( 1)/(1 ), and
K =
F. Using these substitutions, we nd that (the steady-state version of) each of
the rst-order conditions (A.38) (A.45) is satised if the steady-state values satisfy
1
= (1 )
2
,
[f
y
(
Y ) k
y
(
Y ) u
cc
(
Y
G)(
G+
)]
2
= U
y
(
Y , 1),
3
=
2
,
4
=
2
,
5
= 0,
(1 )
6
= U
Y , 1).
These equations can obviously be solved (uniquely) for the steady-state multipliers,
given any value
Y > 0.
Similarly, (the steady-state versions of) the constraints (A.32) (A.37) are satis-
ed if
(1 )u
c
(
Y
G) =
1
w
v
y
(
Y ), (A.46)
Y =
G+
+ (1 )
b, (A.47)
K =
F = (1 )
1
k(
Y ),
W = u
c
(
Y
G)
b.
Equations (A.46) (A.47) provide two equations to solve for the steady-state values
Y and . Under standard (Inada-type) boundary conditions on preferences, equation
(A.46) has a unique solution Y
1
() >
G for each possible value of 0 < 1;
36
this
value is a decreasing function of , and approaches
G as approaches 1. We note
furthermore that at least in the case of all small enough values of
G, there exists
a range of tax rates 0 <
1
< <
2
1 over which Y
1
() >
G/.
37
Given our
assumption that
b > 0 and that
G,
0, (A.47) is satised only by positive values of
36
There is plainly no possibility of positive supply of output by producers in the case that
t
1
in any period; hence the steady state must involve < 1.
37
This is true for any tax rate at which (1 )u
c
(
G(
1
1)) exceeds (/( 1))
w
v
y
(
G/).
Fixing any value 0 < < 1, our Inada conditions imply that this inequality holds for all small
enough values of
G. And if the inequality holds for some 0 < < 1, then by continuity it must hold
for an open interval of values of .
47
; and for each > 0, this equation has a unique solution Y
2
(). We note furthermore
that the locus Y
1
() is independent of the values of
and
b, while Y
2
() approaches
G/ as
and
b approach zero. Fixing the value of
G (at a value small enough for the
interval (
1
,
2
) to exist), we then observe that for any small enough values of
b > 0
and
0, there exist values 0 < < 1 at which Y
2
() < Y
1
(). On the other hand,
for all small enough values of > 0, Y
2
() > Y
1
(). Thus by continuity, there must
exist a value 0 < < 1 at which Y
1
( ) = Y
2
( ).
38
This allows us to obtain a solution
for 0 < < 1 and
Y > 0, in the case of any small enough values of
G,
0 and
b > 0. The remaining equations can then be solved (uniquely) for
K =
F and for
W.
We have thus veried that a constant solution to the rst-order conditions exists.
With a method to be explained below, we check that this solution is indeed at least
a local optimum. Note that as asserted in the text, this deterministic steady state
involves zero ination, and a steady-state tax rate 0 < < 1.
A.4 A second-order approximation to utility (equations (2.1)
and (2.2))
We derive here equations (2.1) and (2.2) in the main text, taking a second-order ap-
proximation to (equation (A.20)) following the treatment in Woodford (2003, chapter
6). We start by approximating the expected discounted value of the utility of the
representative household
U
t
0
= E
t
0
t=t
0
tt
0
_
u(Y
t
;
t
)
_
1
0
v(y
t
(i);
t
)di
_
. (A.48)
First we note that
_
1
0
v(y
t
(i);
t
)di =
1 +
Y
1+
t
A
1+
t
H
t
= v(Y
t
;
t
)
t
where
t
is the measure of price dispersion dened in the text. We can then write
38
In fact, there must exist at least two such solutions, since the Inada conditions also imply
that Y
2
() > Y
1
() for all close enough to 1. These multiple solutions correspond to a Laer
curve result, under which two distinct tax rates result in the same equilibrium level of government
revenues. We select the lower-tax, higher-output solution as the one around which we compute our
Taylor-series expansions; this is clearly the higher-utility solution.
48
(A.48) as
U
t
0
= E
t
0
t=t
0
tt
0
[u(Y
t
;
t
) v(Y
t
;
t
)
t
] . (A.49)
The rst term in (A.49) can be approximated using a second-order Taylor expan-
sion around the steady state dened in the previous section as
u(Y
t
;
t
) = u + u
c
Y
t
+ u
t
+
1
2
u
cc
Y
2
t
+ u
c
Y
t
+
1
2
t
u
t
+O(||||
3
)
= u +
Y u
c
(
Y
t
+
1
2
Y
2
t
) + u
t
+
1
2
Y u
cc
Y
2
t
+
+
Y u
c
Y
t
+
1
2
t
u
t
+O(||||
3
)
=
Y u
c
Y
t
+
1
2
[
Y u
c
+
Y
2
u
cc
]
Y
2
t
Y
2
u
cc
g
t
Y
t
+ t.i.p. +O(||||
3
)
=
Y u
c
_
Y
t
+
1
2
(1
1
)
Y
2
t
+
1
g
t
Y
t
_
+
+t.i.p. +O(||||
3
), (A.50)
where a bar denotes the steady-state value for each variable, a tilde denotes the
deviation of the variable from its steady-state value (e.g.,
Y
t
Y
t
Y ), and a hat refers
to the log deviation of the variable from its steady-state value (e.g.,
Y
t
ln Y
t
/
Y ).
We use
t
to refer to the entire vector of exogenous shocks,
t
_
G g
t
q
t
w
t
_
,
in which
t
(
t
)/Y ,
G
t
(G
t
G)/Y , g
t
G
t
+s
C
c
t
, q
t
h
t
+(1 +)a
t
,
w
t
ln
w
t
/
w
, c
t
ln
C
t
/
C, a
t
ln A
t
/
A,
h
t
ln
H
t
/
H. Moreover, we use the
denitions
1
1
s
1
C
with s
C
C/Y and s
C
+s
G
= 1. We have used the Taylor
expansion
Y
t
/
Y = 1 +
Y
t
+
1
2
Y
2
t
+O(||||
3
)
to get a relation for
Y
t
in terms of
Y
t
. Finally the term t.i.p. denotes terms that
are independent of policy, and may accordingly be suppressed as far as the welfare
ranking of alternative policies is concerned.
49
We may similarly approximate v(Y
t
;
t
)
t
by
v(Y
t
;
t
)
t
= v + v(
t
1) + v
y
(Y
t
Y ) + v
y
(
t
1)(Y
t
Y ) + (
t
1) v
t
+
+
1
2
v
yy
(Y
t
Y )
2
+ (Y
t
Y ) v
y
t
+O(||||
3
)
= v(
t
1) + v
y
Y
_
Y
t
+
1
2
Y
2
t
_
+ v
y
(
t
1)
Y
Y
t
+ (
t
1) v
t
+
+
1
2
v
yy
Y
2
Y
2
t
+
Y
Y
t
v
y
t
+ t.i.p.+O(||||
3
)
= v
y
Y [
t
1
1 +
+
Y
t
+
1
2
(1 +)
Y
2
t
+ (
t
1)
Y
t
Y
t
q
t
+
t
1
1 +
q
t
] + t.i.p.+O(||||
3
).
We take a second-order expansion of (A.21), obtaining
t
=
t1
+
1
(1 +)(1 +)
2
t
2
+ t.i.p.+O(||||
3
). (A.51)
This in turn allows us to approximate v(Y
t
;
t
)
t
as
v(Y
t
;
t
)
t
= (1 )
Y u
c
_
t
1 +
+
Y
t
+
1
2
(1 +)
Y
2
t
Y
t
q
t
_
+ t.i.p. +O(||||
3
),
(A.52)
where we have used the steady state relation v
y
= (1) u
c
to replace v
y
by (1) u
c
,
and where
1
_
1
__
1
w
_
< 1
measures the ineciency of steady-state output
Y .
Combining (A.50) and (A.52), we nally obtain equation (2.1) in the text,
U
t
0
= Y u
c
E
t
0
t=t
0
tt
0
Y
t
1
2
u
yy
Y
2
t
+
Y
t
u
t
u
t
+ t.i.p. +O(||||
3
), (A.53)
where
u
yy
( +
1
) (1 )(1 +),
u
t
[
1
g
t
+ (1 )q
t
],
u
(1 )
1 +
.
50
We nally observe that (A.51) can be integrated to obtain
t=t
0
t
=
(1 )(1 )
(1 +)(1 +)
t=t
0
2
t
+ t.i.p. +O(||||
3
). (A.54)
By substituting (A.54) into (A.53), we obtain
U
t
0
= Y u
c
E
t
0
t=t
0
tt
0
[
Y
t
1
2
u
yy
Y
2
t
+
Y
t
u
t
u
2
t
]
+t.i.p. +O(||||
3
).
This coincides with equation (2.2) in the text, where we have further dened
(1 )(1 )
( +
1
)
(1 +)
, u
( +
1
)(1 )
.
A.5 A second-order approximation to the AS equation (equa-
tion (1.11))
We now compute a second-order approximation to the aggregate supply equation
(A.16), or equation (1.11) in the main text. We start from (A.10) that can be written
as
p
t
=
_
K
t
F
t
_ 1
1+
,
where p
t
p
t
/P
t
. As shown in Benigno and Woodford (2003), a second-order expan-
sion of this can be expressed in the form
(1 +)
(1 )
p
t
= z
t
+
(1 +)
(1 )
E
t
(
p
t+1
P
t,t+1
) +
1
2
z
t
X
t
+
1
2
(1 +)
p
t
Z
t
+
1
2
(1 +)E
t
{(
p
t+1
P
t,t+1
)Z
t+1
}
+
2(1 )
(1 2 )(1 +)E
t
{(
p
t+1
P
t,t+1
)
P
t,t+1
}
+s.o.t.i.p. +O(||||
3
), (A.55)
where we dene
P
t,T
log(P
t
/P
T
),
z
t
(
Y
t
q
t
) +
1
(
C
t
c
t
)
S
t
+
w
t
,
51
Z
t
E
t
_
+
T=t
()
Tt
[X
T
+ (1 2 )
P
t,T
]
_
,
and in this last expression
X
T
(2 +)
Y
T
q
T
+
w
T
+
S
T
1
(
C
T
c
T
),
where
S
t
= ln(1
t
)/(1 ). Here s.o.t.i.p. refers to second-order (or higher)
terms independent of policy; the rst-order terms have been kept as these will matter
for the log-linear aggregate-supply relation that appears as a constraint in our policy
problem.
We next take a second-order expansion of the law of motion (A.15) for the price
index, obtaining
p
t
=
1
1
2
(1 )
2
2
t
+O(||||
3
), (A.56)
where we have used the fact that
p
t
=
1
t
+O(||||
2
),
and
P
t1,t
=
t
. We can then plug (A.56) into (A.55) obtaining
t
=
1
2
1
(1 )
2
t
+
( +
1
)
z
t
+E
t
t+1
1
2
(1 )
E
t
2
t+1
+
1
2
( +
1
)
z
t
X
t
1
2
(1 )
t
Z
t
+
2
(1 )E
t
{
t+1
Z
t+1
}
2
(1 2 )E
t
{
2
t+1
} + s.o.t.i.p. +O(||||
3
). (A.57)
We note further that a second-order approximation to the identity C
t
= Y
t
G
t
yields
C
t
= s
1
C
Y
t
s
1
C
G
t
+
s
1
C
(1 s
1
C
)
2
Y
2
t
+s
2
C
Y
t
G
t
+ s.o.t.i.p. +O(||||
3
), (A.58)
and that
S
t
=
(1 )
2
t
+O(||||
3
), (A.59)
where
/(1 ). By substituting (A.58) and (A.59) into the denition of z
t
in
(A.57), we nally obtain a quadratic approximation to the AS relation.
52
This can be expressed compactly in the form
V
t
= (c
x
x
t
+c
t
+
1
2
x
t
C
x
x
t
+x
t
C
t
+
1
2
c
2
t
) +E
t
V
t+1
+s.o.t.i.p. +O(||||
3
) (A.60)
where we have dened
x
t
_
t
Y
t
_
,
c
x
=
_
1
_
,
c
=
_
0 0
1
( +
1
)
1
( +
1
)
1
( +
1
)
1
_
,
C
x
=
_
(1
1
)
(1
1
) (2 +
1
) +
1
(1 s
1
C
)( +
1
)
1
_
,
C
=
_
0 0
1
0 0
0
1
s
1
C
(+
1
)
1
(1
1
)
(+
1
)
(1+)
(+
1
)
(1+)
(+
1
)
_
,
c
=
(1 +)( +
1
)
V
t
=
t
+
1
2
v
2
t
+v
z
t
Z
t
,
Z
t
= z
x
x
t
+z
t
+z
t
+E
t
Z
t+1
,
in which the coecients
/( +
1
),
and
v
(1 +)
1
(1 )
, v
z
(1 )
2
,
v
k
1
(1 2 ),
z
x
_
(2 +
1
) +v
k
( +
1
)
(1 v
k
)
_
,
z
_
0 0
1
(1 v
k
) (1 +v
k
) (1 v
k
)
_
,
z
v
k
.
53
Note that in a rst-order approximation, (A.60) can be written as simply
t
= [
Y
t
+
t
+c
t
] +E
t
t+1
, (A.61)
where
c
t
( +
1
)
1
[
1
g
t
q
t
+
w
t
].
We can also integrate (A.60) forward from time t
0
to obtain
V
t
0
= E
t
0
t=t
0
tt
0
(c
x
x
t
+
1
2
x
t
C
x
x
t
+x
t
C
t
+
1
2
c
2
t
)
+t.i.p. +O(||||
3
), (A.62)
where the term c
t
is now included in terms independent of policy. (Such terms
matter when part of the log-linear constraints, as in the case of (A.61), but not when
part of the quadratic objective.)
A.6 A second-order approximation to the intertemporal gov-
ernment solvency condition (equation (1.15))
We now derive a second-order approximation to the intertemporal government sol-
vency condition. We use the denition
W
t
E
t
T=t
Tt
u
c
(Y
T
;
T
)s
T
, (A.63)
where
s
t
t
Y
t
G
t
t
, (A.64)
and
W
t
=
b
t1
t
u
c
(C
t
;
t
). (A.65)
54
First, we take a second-order approximation of the term u
c
(C
t
;
t
)s
t
obtaining
u
c
(C
t
;
t
)s
t
= s u
c
+ u
cc
s
C
t
+ u
c
s
t
+ s u
c
t
+
1
2
s u
ccc
C
2
t
+ u
cc
C
t
s
t
+ s
C
t
u
cc
t
+ s
t
u
c
t
+ s.o.t.i.p. +O(||||
3
),
= s u
c
+ u
cc
s
C
C
t
+ u
c
s
t
+ s u
c
t
+
1
2
s( u
cc
C + u
ccc
C
2
)
C
2
t
+
C u
cc
C
t
s
t
+
s
C u
cc
C
t
+ u
c
t
s
t
+ s.o.t.i.p. +O(||||
3
)
= s u
c
+ u
c
[
1
s
C
t
+ s
t
+ s u
1
c
u
c
t
+
1
2
s
2
C
2
t
1
s
t
C
t
+
s
C u
1
c
u
cc
C
t
+ u
1
c
u
c
t
s
t
] + s.o.t.i.p. +O(||||
3
)
= s u
c
+ u
c
[
1
s(
C
t
c
t
) + s
t
+
1
2
s
2
C
2
t
1
s
t
(
C
t
c
t
)
2
s c
t
C
t
]
+s.o.t.i.p. +O(||||
3
) (A.66)
where we have followed previous denitions and use the isoelastic functional forms
assumed and note that we can write u
1
c
u
c
t
=
1
c
t
and
C u
1
c
u
cc
t
=
2
c
t
.
Plugging (A.58) into (A.66) we obtain
u
c
(C
t
;
t
)s
t
= s u
c
[1
1
Y
t
+
1
g
t
+ s
1
s
t
+
1
2
[
1
(s
1
C
1) +
2
]
Y
2
t
+
1
s
1
(
Y
t
g
t
) s
t
1
(s
1
C
G
t
+
1
g
t
)
Y
t
] + s.o.t.i.p. +
+O(||||
3
) (A.67)
by using previous denitions.
We recall now that the primary surplus is dened as
s
t
=
t
Y
t
G
t
t
which can be expanded in a second-order expansion to get
s
1
s
t
= (1 +
g
)(
Y
t
+
t
) s
1
d
(
G
t
+
t
) +
(1 +
g
)
2
(
Y
t
+
t
)
2
+s.o.t.i.p. +O(||||
3
), (A.68)
where we have dened s
d
s/Y ,
g
= (G + )/s and
t
= (
t
)/Y . Substituting
55
(A.68) into (A.67), we obtain
u
c
(C
t
;
t
)s
t
= s u
c
[1
1
Y
t
+ (1 +
g
)(
Y
t
+
t
) +
1
g
t
s
1
d
(
G
t
+
t
)
+
(1 +
g
)
2
2
t
+ (1 +
g
)(1
1
)
t
Y
t
+
+
1
2
_
1 +
g
+
1
(s
1
C
1) +
2
2
1
(1 +
g
)
Y
2
t
+
1
[s
1
C
G
t
+ (
1
1
g
)g
t
s
1
d
(
G
t
+
t
)]
Y
t
+
1
(1 +
g
)g
t
t
] + s.o.t.i.p. +O(||||
3
). (A.69)
Substituting (A.69) into (A.63), we obtain
W
t
= (1 )[b
x
x
t
+b
t
+
1
2
x
t
B
x
x
t
+x
t
B
t
] +E
t
W
t+1
s.o.t.i.p. +O(||||
3
) (A.70)
where
W
t
(W
t
W)/
Wand
b
x
=
_
(1 +
g
) (1 +
g
)
1
_
,
b
=
_
s
1
d
s
1
d
1
0 0
_
,
B
x
=
_
(1 +
g
) (1
1
)(1 +
g
)
(1
1
)(1 +
g
) (1 +
g
) + (s
1
C
1)
1
+
2
2
1
(1 +
g
)
_
,
B
=
_
0 0
1
(1 +
g
) 0 0
s
1
d
1
s
1
d
1
s
1
C
1
1
(
1
1
g
) 0 0
_
,
We further note from (A.70) that
W
t
(
b
t1
t
1
C
t
+ c
t
) +
1
2
(
b
t1
t
1
C
t
+ c
t
)
2
+O(||||
3
).
Substituting in (A.58), we obtain
W
t
b
t1
1
(
Y
t
g
t
)
1
(1 s
1
C
)
2
Y
2
t
1
s
1
C
Y
t
G
t
+
1
2
(
b
t1
1
(
Y
t
g
t
))
2
+ s.o.t.i.p. +O(||||
3
)
which can be written as
W
t
=
b
t1
t
+w
x
x
t
+w
t
+
1
2
x
t
W
x
x
t
+x
t
W
t
+
1
2
[
b
t1
t
+w
x
x
t
+w
t
]
2
+s.o.t.i.p. +O(||||
3
)
56
w
x
=
_
0
1
_
,
w
=
_
0 0
1
0 0
_
,
W
x
=
_
0 0
0 (s
1
C
1)
1
_
,
W
=
_
0 0 0 0 0
0 s
1
C
1
0 0 0
_
.
Note that in the rst-order approximation we can simply write (A.70) as
b
t1
t
+ w
x
x
t
+w
t
= (1 )[b
x
x
t
+b
t
]
+ E
t
[
b
t
t+1
+w
x
x
t+1
+w
t+1
]. (A.71)
Moreover integrating forward (A.70), we obtain that
W
t
0
= (1 )E
t
0
t=t
0
tt
0
[b
x
x
t
+
1
2
x
t
B
x
x
t
+x
t
B
t
] + t.i.p. +O(||||
3
), (A.72)
where we have moved b
t
in t.i.p.
A.7 A quadratic policy objective (equations (2.3) and (2.4))
We now derive a quadratic approximation to the policy objective function. To this
end, we combine equation (A.62) and (A.72) in a way to eliminate the linear term in
(A.53). Indeed, we nd
1
,
2
such that
1
b
x
+
2
c
x
= a
x
[0 ].
The solution is given by
1
=
2
=
(1 +
g
)
,
where
= ( +
1
)(1 +
g
)
(1 +
g
) +
1
.
57
We can write
E
t
0
t=t
0
tt
0
Y
t
= E
t
0
t=t
0
tt
0
[
1
b
x
+
2
c
x
]x
t
= E
t
0
t=t
0
tt
0
[
1
2
x
t
D
x
x
t
+x
t
D
t
+
1
2
d
2
t
]
+
1
W
t
0
+
2
1
V
t
0
+ t.i.p. +O(||||
3
)
where
D
x
1
B
x
+
2
C
x
, etc.
Hence
U
t
0
= E
t
0
t=t
0
tt
0
_
a
x
x
t
1
2
x
t
A
x
x
t
x
t
A
1
2
a
2
t
_
+ t.i.p. +O(||||
3
)
= E
t
0
t=t
0
tt
0
_
1
2
x
t
Q
x
x
t
+x
t
Q
t
+
1
2
q
2
t
_
+T
t
0
+ t.i.p. +O(||||
3
)
= E
t
0
t=t
0
tt
0
_
1
2
q
y
(
Y
t
t
)
2
+
1
2
q
2
t
_
+T
t
0
+
+t.i.p. +O(||||
3
) (A.73)
In particular, we obtain that = u
c
Y and that
Q
x
=
_
0 0
0 q
y
_
,
with
q
y
(1 )( +
1
) + ( +
1
)
(1 +
g
)(1 +)
+
1
(1 +
)(1 +
g
)
1
s
1
C
1 +
g
+
;
moreover we have dened
Q
=
_
0 0 0 0 0
q
1
q
2
q
3
q
4
q
5
_
,
58
with
q
1
=
s
1
d
1
,
q
2
=
1
s
1
d
+
1
s
1
C
(1 +
g
+
,
q
3
= (1 )
1
1
(1 +)(1 +
g
)
,
q
4
= (1 )
(1 +)(1 +
g
)
,
q
5
=
1 +
g
(1 +) ,
and
q
=
(1 +
g
)(1 +)( +
1
)
+
(1 )( +
1
)
.
We have further dened
Y
t
, the desired level of output, as
t
= q
1
y
q
t
.
Finally,
T
t
0
Y u
c
[
1
W
t
0
+
2
1
V
t
0
]
is a transitory component. Equation (A.73) corresponds to equation (2.3) in the main
text. In particular, given the commitments on the initial values of the vector X
t
0
,
W
t
0
implies that
W
t
0
is given when characterizing the optimal policy from a timeless
perspective. Moreover, F
t
0
and K
t
0
imply that V
t
0
and Z
t
0
are as well given. It follows
that the value of the transitory component T
t
0
is predetermined under the stage two
of the Ramsey problem. Hence, over the set of admissible policies, higher values of
(A.73) correspond to lower values of
E
t
0
t=t
0
tt
0
_
1
2
q
y
(
Y
t
t
)
2
+
1
2
q
2
t
_
. (A.74)
It follows that we may rank policies in terms of the implied value of the discounted
quadratic loss function (A.74) which corresponds to equation (2.4) in the main text.
Because this loss function is purely quadratic (i.e., lacking linear terms), it is possible
to evaluate it to second order using only a rst-order approximation to the equilib-
rium evolution of ination and output under a given policy. Hence the log-linear
approximate structural relations (A.61) and (A.71) are suciently accurate for our
59
purposes. Similarly, it suces that we use log-linear approximations to the variables
V
t
0
and
W
t
0
in describing the initial commitments, which are given by
V
t
0
=
t
0
,
W
t
0
=
b
t
0
1
t
0
+w
x
x
t
0
+w
t
0
=
b
t
0
1
t
0
1
(
Y
t
0
g
t
0
).
Then an optimal policy from a timeless perspective is a policy from date t
0
on-
ward that minimizes the quadratic loss function (A.74) subject to the constraints
implied by the linear structural relations (A.61) and (A.71) holding in each period
t t
0
, given the initial values
b
t
0
1
,
t
0
1
, and subject also to the constraints that
certain predetermined values for
V
t
0
and
W
t
0
(or alternatively, for
t
0
and for
Y
t
0
)
be achieved.
39
We note that under the assumption that +
1
>
= /(1 ),
> 0, which implies that q
> 0. Moreover, if
s
C
>
1
(1 +
g
+
)
(1 )( +
1
) + ( +
1
)(1 +
g
)(1 +) +
1
(1 +
g
)(1 +
)
,
then q
y
> 0 and the objective function is convex. Since the expression on the right-
hand side of this inequality is necessarily less than one (given that > 0), the
inequality is satised for all values of s
G
less than a positive upper bound.
A.8 The log-linear aggregate-supply relation and the cost-
push disturbance term
The AS equation (A.61) can be written as
t
= [y
t
+
t
+u
t
] +E
t
t+1
, (A.75)
where u
t
is composite cost-push shock dened as u
t
c
t
+
Y
t
. We can write
(A.75) as
t
= [y
t
+(
t
t
)] +E
t
t+1
, (A.76)
where we have further dened
u
t
= u
t
Y
t
+c
t
,
39
The constraint associated with a predetermined value for Z
t0
can be neglected, in a rst-order
characterization of optimal policy, because the variable Z
t
does not appear in the rst-order approx-
imation to the aggregate-supply relation.
60
where
u
1
q
y
s
1
d
1
,
u
2
1
s
1
d
q
y
1
s
1
C
(1 +
g
+
)
q
y
,
u
3
2
(1 +
)(1 +
g
)
q
y
( +
1
)
+
2
s
1
C
1 +
g
+
q
y
( +
1
)
,
u
4
u
3
,
u
5
= u
3
+
(1 )
q
y
,
We nally dene
t
1
u
t
in a way that we can write (A.61)
t
= [(
Y
t
t
) +(
t
t
)] +E
t
t+1
, (A.77)
which is equation (2.7) in the text.
A.9 The log-linear intertemporal solvency condition and the
scal stress disturbance term
The ow budget constraint (A.71) can be solved forward to yield the intertemporal
solvency condition
b
t1
1
y
t
= f
t
+ (1 )E
t
T=t
Tt
[b
y
y
T
+b
(
T
T
)] (A.78)
where f
t
, the scal stress disturbance term, is dened as
f
t
1
(g
t
t
) (1 )E
t
T=t
Tt
[b
y
Y
T
+b
T
+b
T
]
=
1
(g
t
t
) + (1 )E
t
T=t
Tt
[
1
T
(b
1
c
)
T
].
This can be rewritten in a more compact way as
f
t
h
t
+ (1 )E
t
T=t
Tt
f
T
,
61
where
h
1
q
y
2
s
d
,
f
1
q
y
1
s
d
+
1
s
d
,
h
2
2
s
1
d
q
y
+
2
s
1
C
(1 +
g
+
)
q
y
,
f
2
1
s
1
d
q
y
2
s
1
C
(1 +
g
+
q
y
+
1
s
d
,
h
3
2
(1 +
)(1 +
g
)
q
y
2
s
1
C
1 +
g
+
q
y
+
(1 )
1
q
y
+
1
(1 +)(1 +
g
)
q
y
,
f
3
1
(1 )
1
q
y
+
1
1
(1 +)(1 +
g
)
q
y
1
(1 +
1
)(1 +
g
),
h
4
1
(1 )
q
y
1
(1 +)(1 +
g
)
q
y
,
f
4
1
(1 )
q
y
+
1
(1 +)(1 +
g
)
q
y
(1 +
g
),
h
5
1
(1 +
g
) (1 +)
q
y
,
f
5
1
(1 +
g
) (1 +)
q
y
+
1
(1 +
g
).
A.10 Denition of the coecients in sections 3, 4 and 5
The coecients m
, n
, n
b
, m
b
, m
b
,
are dened as
m
q
1
y
1
(1 )b
+q
1
y
[(1 )b
y
+
1
],
n
q
1
y
1
,
n
b
b
(
1
1)(m
+n
),
m
b
n
[(1 )b
1
(1 )b
y
1
],
62
m
b
1
n
(1 )[b
1
b
y
]n
+ (1 )
1
1
b
q
1
(
1
(1 )b
1
+ 1),
1
q
1
q
y
,
1
1
q
1
[(1 )b
y
+
1
],
2
1
q
1
1
.
The coecients
1
and
2
of section 5 are dened as
1
(1 )b
2
(1 )(b
b
y
)
(1 )b
+
.
A.11 Proof of determinacy of equilibrium under the optimal
targeting rules
We now show that there is a determinate equilibrium if policy is conducted so as to
ensure that the two target criteria
E
t
t+1
= 0 (A.79)
and
y
t
+
1
(m
+n
)
t
t
= 0 (A.80)
are satised in each period t t
0
. Note that (A.80) can be written as
y
t
=
3
t
+
4
t1
(A.81)
where
3
1
4
1
.
Use (A.79), combined with
t
=
1
1
y
t
1
E
t
t+1
. (A.82)
63
and
E
t
y
t+1
=
1
t
to eliminate E
t
t+1
, E
t
y
t+1
and
t
t
from
b
t1
t
1
y
t
+f
t
= (1 )[b
y
y
t
+b
(
t
t
)]
+ E
t
[
b
t
t+1
1
y
t+1
+f
t+1
].
Then further use (A.80) to eliminate y
t
from the resulting expression. One obtains
an equation of the form
b
t
=
1
b
t1
+m
41
t
+m
42
t1
+m
43
y
t1
+
t
,
where
t
is an exogenous disturbance. The system consisting of this equation plus
(A.80) and (A.79) can then be written as
E
t
z
t+1
= Mz
t
+N
t
,
where
z
t
_
t1
y
t1
b
t1
_
_
, M
_
_
0 0 0 0
1 0 0 0
m
31
m
32
1 0
m
41
m
42
m
43
1
_
_
, N
_
_
0
0
0
n
41
_
_
.
Because M is lower triangular, its eigenvalues are the four diagonal elements:
0, 0, 1, and
1
. Hence there is exactly one eigenvalue outside the unit circle, and
equilibrium is determinate (but possesses a unit root). Because of the triangular
form of the matrix, one can also easily solve explicitly for the elements of the left
eigenvector
v
= [v
1
v
2
v
3
1]
associated with the eigenvalue
1
, where
v
1
= (1 +
g
)[
1
1]
4
(1
1
4
) (1 )(1 +
g
)()
1
+(1 +
g
)[
1
1]
3
,
v
2
= (1 +
g
)[
1
1]
4
,
v
3
= (1 +
g
)[
1
1].
64
Pre-multiplying the vector equation by v
, one obtains a scalar equation with a unique
non-explosive solution of the form
v
z
t
=
j=0
j+1
E
t
t+j
.
In the case that v
1
= 0, this can be solved for
t
as a linear function of
t1
, y
t1
,
b
t1
and the exogenous state vector as it follows
t
=
1
v
1
b
t1
v
2
v
1
t1
v
3
v
1
y
t1
+
1
v
1
f
t
. (A.83)
The solution for
t
can then be substituted into the above equations to obtain the
equilibrium dynamics of y
t
and
b
t
as well, and hence of
t
also.
65
References
[1] Aiyagari, S. Rao, Albert Marcet, Thomas Sargent, and Juha Seppala (2002),
Optimal Taxation without State-Contingent Debt, Journal of Political Econ-
omy.
[2] Barro, Robert J. (1979), On the Determination of Public Debt, Journal of
Political Economy 87: 940-971.
[3] Benigno, Pierpaolo, and Michael Woodford (2003), Ination Stabilization and
Welfare: The Case of Large Distortions, in preparation.
[4] Bohn, Henning (1990), Tax Smoothing with Financial Instruments, American
Economic Review 80: 1217-1230.
[5] Chari, V.V., Lawrence Christiano J., and Patrick Kehoe (1991), Optimal Fiscal
and Monetary Policy: Some Recent Results, Journal of Money, Credit, and
Banking 23: 519-539.
[6] Chari, V.V., Lawrence Christiano J., and Patrick Kehoe, (1994) Optimal Fiscal
Policy in a Business Cycle Model, Journal of Political Economy 102: 617-652.
[7] Chari, V.V., and Patrick J. Kehoe (1999), Optimal Fiscal and Monetary Policy,
in J.B. Taylor and M. Woodford, eds., Handbook of Macroeconomics, vol. 1C,
North-Holland.
[8] Clarida, Richard, Jordi Gali, and Mark Gertler (1999), The Science of Monetary
Policy: a New Keynesian Perspective, Journal of Economic Literature, 37 (4),
pp. 1661-1707
[9] Correia, Isabel, Juan Pablo Nicolini and Pedro Teles (2001), Optimal Fiscal
and Monetary Policy: Equivalence Results, unpublished manuscript, Bank of
Portugal.
[10] Friedman, Milton (1969),The Optimum Quantity of Money, in The Optimum
Quantity of Money and Other Essays, Chicago: Aldine.
[11] Giannoni, Marc, and Michael Woodford (2002), Optimal Interest-Rate Rules:
I. General Theory, NBER working paper no. 9419, December.
66
[12] Giannoni, Marc, and Michael Woodford (2003), Optimal Ination Targeting
Rules, in B.S. Bernanke and M. Woodford, eds., Ination Targeting, Chicago:
University of Chicago Press, forthcoming.
[13] Hall, George, and Stefan Krieger (2000), The Tax Smoothing Implications of
the Federal Debt Paydown, Brookings Papers on Economic Activity 2: 253-301.
[14] Khan, Aubhik, Robert G. King, and Alexander L. Wolman (2002), Optimal
Monetary Policy, NBER working paper no. 9402, December.
[15] Lucas, Robert E., Jr., and Nancy L. Stokey (1983), Optimal Fiscal and Mon-
etary Policy in an Economy without Capital, Journal of Monetary Economics
12: 55-93.
[16] Rotemberg, Julio J., and Michael Woodford (1997), An Optimization-Based
Econometric Framework for the Evaluation of Monetary Policy, in B.S.
Bernanke and Rotemberg (eds.), NBER Macroeconomic Annual 1997, Cam-
bridge, MA: MIT Press. 297-346.
[17] Sbordone, Argia M. (2002), Prices and Unit Labor Costs: A New Test of Price
Stickiness, Journal of Monetary Economics 49: 265-292.
[18] Schmitt-Grohe, Stephanie, and Martin Uribe (2001), Optimal Fiscal and Mon-
etary Policy under Sticky prices, Rutgers University working paper no. 2001-06,
June.
[19] Siu, Henry E. (2001), Optimal Fiscal and Monetary Policy with Sticky Prices,
unpublished manuscript, Northwestern University, November.
[20] Svensson, Lars E.O. (1999), Ination Targeting as a Monetary Policy Rule,
Journal of Monetary Economics 43: 607-654.
[21] Svensson, Lars E.O. (2003), What Is Wrong with Taylor Rules? Using Judg-
ment in Monetary Policy through Targeting Rules, Journal of Economic Liter-
ature, forthcoming.
[22] Svensson, Lars E.O., and Michael Woodford (2003), Implementing Optimal Pol-
icy through Ination-Forecast Targeting, in B.S. Bernanke and M. Woodford,
eds., Ination Targeting, Chicago: Univ. of Chicago Press, forthcoming.
67
[23] Woodford, Michael (1999), Commentary: How Should Monetary Policy Be
Conducted in an Era of Price Stability? in Federal Reserve Bank of Kansas
City, New Challenges for Monetary Policy.
[24] Woodford, Michael (2001), Fiscal Requirements for Price Stability, Journal of
Money, Credit and Banking 33: 669-728.
[25] Woodford, Michael (2003), Interest and Prices: Foundations of a Theory of
Monetary Policy, forthcoming, Princeton University Press.
68
You might also like
- International Policy Coordination and Simple Monetary Policy RulesDocument29 pagesInternational Policy Coordination and Simple Monetary Policy Rulesramadhanangsu123No ratings yet
- Roes 8739Document28 pagesRoes 8739Radu FlorianNo ratings yet
- Optimal Fiscal and Monetary Policy - Equivalence (2008)Document31 pagesOptimal Fiscal and Monetary Policy - Equivalence (2008)FábioNo ratings yet
- Monetary Policy in The Open Economy Revisited: Price Setting and Exchange Rate FlexibilityDocument44 pagesMonetary Policy in The Open Economy Revisited: Price Setting and Exchange Rate FlexibilityDerrick GohNo ratings yet
- Monetary and Fiscal Policy Interactions: Some Empirical Evidence in The Euro-AreaDocument23 pagesMonetary and Fiscal Policy Interactions: Some Empirical Evidence in The Euro-AreaeeeeewwwwwwwwNo ratings yet
- L1ad202 601Document28 pagesL1ad202 601AlejandroNo ratings yet
- Fical PolicyDocument51 pagesFical Policyrasel_203883No ratings yet
- 2005 - NominalRigiditiesPM - Christiano Et - AlDocument45 pages2005 - NominalRigiditiesPM - Christiano Et - AlJuan Manuel Báez CanoNo ratings yet
- In Ation Targeting As A Monetary Policy RuleDocument44 pagesIn Ation Targeting As A Monetary Policy RulesangroniscarlosNo ratings yet
- KocherlakotaPhelan FRBMineapolis 1999Document9 pagesKocherlakotaPhelan FRBMineapolis 1999alexandrosvlaNo ratings yet
- Essays On Fiscal Policy: Cladea's XII Doctoral ConsortiumDocument21 pagesEssays On Fiscal Policy: Cladea's XII Doctoral ConsortiumzamirNo ratings yet
- Public Debt, Discretionary Policy, and Inflation PersistenceDocument28 pagesPublic Debt, Discretionary Policy, and Inflation PersistenceAndres OrdoñezNo ratings yet
- Optimal Monetary Policy in Open Economies RevisitedDocument74 pagesOptimal Monetary Policy in Open Economies RevisitedDr. Maryam IshaqNo ratings yet
- Monetary Policy in A Small Open Economy. The Case of Paraguay - BCP - Portal GuaraniDocument22 pagesMonetary Policy in A Small Open Economy. The Case of Paraguay - BCP - Portal GuaraniportalguaraniNo ratings yet
- Ricardo MoreiraDocument18 pagesRicardo MoreiraGrim MariusNo ratings yet
- Public Debt, Price Levels, and Monetary-Fiscal Policy CoordinationDocument69 pagesPublic Debt, Price Levels, and Monetary-Fiscal Policy CoordinationSulman ShafiqNo ratings yet
- Does Trade Liberalization Impact in Ation Dynamics? Evidence From A Natural ExperimentDocument36 pagesDoes Trade Liberalization Impact in Ation Dynamics? Evidence From A Natural ExperimentDaniel A. DiasNo ratings yet
- Economic Modelling GFDocument35 pagesEconomic Modelling GFAnonymous XR7iq7No ratings yet
- General Equilibrium and The New Neoclassical Synthesis - HeringsDocument40 pagesGeneral Equilibrium and The New Neoclassical Synthesis - HeringsyeisonNo ratings yet
- Alternative Monetary Policy Rules For Small Open EconomiesDocument42 pagesAlternative Monetary Policy Rules For Small Open Economiesadadarahim6778No ratings yet
- Interest Rate Pass-Through, Monetary Policy Rules and Macroeconomic StabilityDocument39 pagesInterest Rate Pass-Through, Monetary Policy Rules and Macroeconomic Stabilitybrendan lanzaNo ratings yet
- Media 22258 SMXXDocument34 pagesMedia 22258 SMXXMissaoui IbtissemNo ratings yet
- A GARCH Option Pricing Model With Filtered Historical SimulationDocument53 pagesA GARCH Option Pricing Model With Filtered Historical SimulationIoana NistoroaieNo ratings yet
- Monetary Policy, Currency Unions and Open Economy MacrodynamicsDocument50 pagesMonetary Policy, Currency Unions and Open Economy MacrodynamicsrerereNo ratings yet
- Research Papers On Interest Rate ParityDocument4 pagesResearch Papers On Interest Rate Parityxmniibvkg100% (1)
- Monetary and Fiscal Policies in A Search and Matching Model With Endogenous GrowthDocument23 pagesMonetary and Fiscal Policies in A Search and Matching Model With Endogenous GrowthrrrrrrrrNo ratings yet
- Lecture Note - 1, Basic Concepts - 1Document13 pagesLecture Note - 1, Basic Concepts - 1andrewcanadaNo ratings yet
- Taylor RulesDocument15 pagesTaylor RulesNida KhanNo ratings yet
- Are The Effects of Monetary Policy Asymmetric?Document27 pagesAre The Effects of Monetary Policy Asymmetric?marhelunNo ratings yet
- Evaluating Rules in The Fed's Report and Measuring DiscretionDocument25 pagesEvaluating Rules in The Fed's Report and Measuring DiscretionCésar ÁngelesNo ratings yet
- A Cointegrated Structural VAR Model of The Canadian Economy: William J. Crowder Mark E. WoharDocument38 pagesA Cointegrated Structural VAR Model of The Canadian Economy: William J. Crowder Mark E. WoharRodrigoNo ratings yet
- No 25Document29 pagesNo 25eeeeewwwwwwwwNo ratings yet
- Monetary Policy, in Ation, and The Business Cycle Jordi Galí Crei and Upf June 2007Document19 pagesMonetary Policy, in Ation, and The Business Cycle Jordi Galí Crei and Upf June 2007zamirNo ratings yet
- Stock Market's 1% Gain From Unexpected Fed Rate CutsDocument37 pagesStock Market's 1% Gain From Unexpected Fed Rate CutsCathy ChenNo ratings yet
- Optimal Fiscal Policy and Capital Taxation in Overlapping Generations ModelsDocument25 pagesOptimal Fiscal Policy and Capital Taxation in Overlapping Generations ModelsFranzar VicliviaNo ratings yet
- 7 VARs and Monetary PolicyDocument34 pages7 VARs and Monetary PolicyRicardo CaffeNo ratings yet
- Bernanke, Kuttner Stock Market Reaction to Monetary Policy ChangesDocument56 pagesBernanke, Kuttner Stock Market Reaction to Monetary Policy ChangescolorfulsalemNo ratings yet
- Macroeconomic Stabilisation: Fixed Exchange Rates Vs Inflation Targeting Vs Price Level TargetingDocument15 pagesMacroeconomic Stabilisation: Fixed Exchange Rates Vs Inflation Targeting Vs Price Level TargetingmarhelunNo ratings yet
- WalshDocument26 pagesWalshAtenasNo ratings yet
- Tax IncidenceDocument87 pagesTax IncidenceandydotfengNo ratings yet
- November 2002 Fiscal Perspective on Currency Crises and 'Original SinDocument39 pagesNovember 2002 Fiscal Perspective on Currency Crises and 'Original SinEzequielglNo ratings yet
- Limits On Interest Rate Rules in The IS Model: William Kerr and Robert G. KingDocument29 pagesLimits On Interest Rate Rules in The IS Model: William Kerr and Robert G. KingGabriela M AnișoaraNo ratings yet
- Expectations, Real Exchange Rates, and Monetary Policy: Michael B. Devereux Charles Engel UBC WisconsinDocument31 pagesExpectations, Real Exchange Rates, and Monetary Policy: Michael B. Devereux Charles Engel UBC WisconsinIgoriok911_105921426No ratings yet
- NOEM Palgrave 1Document18 pagesNOEM Palgrave 1betalaksonoNo ratings yet
- Interest Rate Through, Monetary Policy Rules and Macro Economic StabilityDocument29 pagesInterest Rate Through, Monetary Policy Rules and Macro Economic StabilityĐặng Thế HòaNo ratings yet
- 2016 EconomiesDocument18 pages2016 EconomiesYosra BaazizNo ratings yet
- New Perspectives On Monetary Policy, Inßation, and The Business CycleDocument51 pagesNew Perspectives On Monetary Policy, Inßation, and The Business CycleHülya Ergin BayraktarNo ratings yet
- 1991 Leeper Equilibria Under Active and Passive Monetary and Fiscal PolicyDocument19 pages1991 Leeper Equilibria Under Active and Passive Monetary and Fiscal PolicyRômullo CarvalhoNo ratings yet
- Alternative Theory of Real Exchange RateDocument30 pagesAlternative Theory of Real Exchange Rategiliad.souzaNo ratings yet
- Cfmdp2013 01 PaperDocument30 pagesCfmdp2013 01 PaperAdminAliNo ratings yet
- Equilibrium Exchange Rate Theories Under Flexible Exchange Rate RegimesDocument23 pagesEquilibrium Exchange Rate Theories Under Flexible Exchange Rate RegimesPutrirasyidNo ratings yet
- Monetary Policy Analysis: A Dynamic Stochastic General Equilibrium ApproachDocument45 pagesMonetary Policy Analysis: A Dynamic Stochastic General Equilibrium Approachندى الريحانNo ratings yet
- Wiley The Scandinavian Journal of EconomicsDocument20 pagesWiley The Scandinavian Journal of EconomicsAadi RulexNo ratings yet
- Ruge Murcia PDFDocument43 pagesRuge Murcia PDFJoab Dan Valdivia CoriaNo ratings yet
- Unveiling Special Policy Regime, Judgment and Taylor Rules in TunisiaDocument22 pagesUnveiling Special Policy Regime, Judgment and Taylor Rules in TunisiaYosra BaazizNo ratings yet
- Discount Rate - Environmental EconomicsDocument6 pagesDiscount Rate - Environmental EconomicsRoberta DGNo ratings yet
- NotesDocument55 pagesNotessreginatoNo ratings yet
- Does The Exchange Rate Regime Matter For Inflation? Evidence From Transition EconomiesDocument29 pagesDoes The Exchange Rate Regime Matter For Inflation? Evidence From Transition Economiessaqibkhan2421No ratings yet
- 11-01 - CópiaDocument61 pages11-01 - CópiaDanielDanielliNo ratings yet
- Microfoundations of A Monetary Policy Rule, Poole's Rule: SSRN Electronic Journal April 2019Document45 pagesMicrofoundations of A Monetary Policy Rule, Poole's Rule: SSRN Electronic Journal April 2019Joab Dan Valdivia CoriaNo ratings yet
- Graduate Macro Theory II: The Real Business Cycle Model: Eric Sims University of Notre Dame Spring 2017Document25 pagesGraduate Macro Theory II: The Real Business Cycle Model: Eric Sims University of Notre Dame Spring 2017Joab Dan Valdivia CoriaNo ratings yet
- The Brazilian Crisis OF 1998-1999: ORIGINS: and ConsequencesDocument42 pagesThe Brazilian Crisis OF 1998-1999: ORIGINS: and ConsequencesJoab Dan Valdivia CoriaNo ratings yet
- Weighted Nadaraya-Watson Regression Estimation: Statistics & Probability Letters February 2001Document13 pagesWeighted Nadaraya-Watson Regression Estimation: Statistics & Probability Letters February 2001Joab Dan Valdivia CoriaNo ratings yet
- COVID-19 Pandemic in Bolivia - Wikipedia PDFDocument18 pagesCOVID-19 Pandemic in Bolivia - Wikipedia PDFJoab Dan Valdivia CoriaNo ratings yet
- Arise 20 and 20 MalomaDocument9 pagesArise 20 and 20 MalomaJoab Dan Valdivia CoriaNo ratings yet
- Estimating A Vecm in StataDocument3 pagesEstimating A Vecm in StataJoab Dan Valdivia CoriaNo ratings yet
- Aa 1998 100 4 1066Document2 pagesAa 1998 100 4 1066Joab Dan Valdivia CoriaNo ratings yet
- Stata - Outreg CommandDocument16 pagesStata - Outreg CommandCagri YildirimNo ratings yet
- 2009 6824 1 PBDocument4 pages2009 6824 1 PBJoab Dan Valdivia CoriaNo ratings yet
- Home Price Monitor 2012 8 29 PDFDocument13 pagesHome Price Monitor 2012 8 29 PDFJoab Dan Valdivia CoriaNo ratings yet
- Some Unpleasant Monetarist ArithmeticDocument19 pagesSome Unpleasant Monetarist ArithmeticJesseNo ratings yet
- What Is Wrong With Taylor Rules? Using Judgment in Monetary Policy Through Targeting RulesDocument77 pagesWhat Is Wrong With Taylor Rules? Using Judgment in Monetary Policy Through Targeting RulesJoab Dan Valdivia CoriaNo ratings yet
- Monetary PolicyDocument30 pagesMonetary PolicyJoab Dan Valdivia CoriaNo ratings yet
- Myrdal's Analysis of Monetary Equilibrium Author(s) : G. L. S. Shackle Source: Oxford Economic Papers, No. 7 (Mar., 1945), Pp. 47-66 Published By: Stable URL: Accessed: 20/06/2014 21:46Document21 pagesMyrdal's Analysis of Monetary Equilibrium Author(s) : G. L. S. Shackle Source: Oxford Economic Papers, No. 7 (Mar., 1945), Pp. 47-66 Published By: Stable URL: Accessed: 20/06/2014 21:46Joab Dan Valdivia CoriaNo ratings yet
- 2015 AprilDocument37 pages2015 AprilJoab Dan Valdivia CoriaNo ratings yet
- Stata Semiparametric Regression ModelsDocument109 pagesStata Semiparametric Regression ModelsJoab Dan Valdivia CoriaNo ratings yet
- The B.E. Journal of Macroeconomics: TopicsDocument30 pagesThe B.E. Journal of Macroeconomics: TopicsJoab Dan Valdivia CoriaNo ratings yet
- The Contributions of Milton Friedman To Economics: Robert L. HetzelDocument30 pagesThe Contributions of Milton Friedman To Economics: Robert L. HetzelNaresh SehdevNo ratings yet
- Predicted Probabilities and Marginal Effects After (Ordered) Logit/probit Using Margins in StataDocument13 pagesPredicted Probabilities and Marginal Effects After (Ordered) Logit/probit Using Margins in Statajuchama4256No ratings yet
- Quarterly Journal of Economics Volume 89 Issue 3 1975 (Doi 10.2307 - 1885259) Leo Sveikauskas - The Productivity of CitiesDocument22 pagesQuarterly Journal of Economics Volume 89 Issue 3 1975 (Doi 10.2307 - 1885259) Leo Sveikauskas - The Productivity of CitiesJoab Dan Valdivia CoriaNo ratings yet
- Financial Systems and Income Inequality: Joana Elisa MALDONADODocument40 pagesFinancial Systems and Income Inequality: Joana Elisa MALDONADOJoab Dan Valdivia CoriaNo ratings yet
- Accounting For Differences in Aggregate State ProductivityDocument21 pagesAccounting For Differences in Aggregate State ProductivityJoab Dan Valdivia CoriaNo ratings yet
- Estimating House Price Appreciation: A Comparison of MethodsDocument15 pagesEstimating House Price Appreciation: A Comparison of MethodsJoab Dan Valdivia CoriaNo ratings yet
- WP Tse 983Document64 pagesWP Tse 983Joab Dan Valdivia CoriaNo ratings yet
- Why Is U.S. National Saving So Low?Document36 pagesWhy Is U.S. National Saving So Low?Ayush PoddarNo ratings yet
- Gls Int Macro PDFDocument1,018 pagesGls Int Macro PDFJoab Dan Valdivia CoriaNo ratings yet
- Guide PDFDocument8 pagesGuide PDFJoab Dan Valdivia CoriaNo ratings yet
- Stata - Outreg CommandDocument16 pagesStata - Outreg CommandCagri YildirimNo ratings yet