You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5819)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- Edexcel International GCSE 9 1 Computer Science Student BookDocument319 pagesEdexcel International GCSE 9 1 Computer Science Student BookChaima Ahmed Gaid100% (3)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- PDFDocument18 pagesPDFmage kieloi100% (3)
- Virtual Base ClassDocument4 pagesVirtual Base ClassmanjulakinnalNo ratings yet
- Spectral DensityDocument6 pagesSpectral Densityharrison9No ratings yet
- 09 ECE 3125 ECE 3242 - Practice Problems - March 14 2012Document3 pages09 ECE 3125 ECE 3242 - Practice Problems - March 14 2012creepymaggotsNo ratings yet
- Control SystemDocument49 pagesControl SystemYashwant ChaudharyNo ratings yet
- Scirobotics Add6864Document14 pagesScirobotics Add6864Kamal KaiNo ratings yet
- Chap2 BookDocument20 pagesChap2 Bookleonemoe3762No ratings yet
- PCML NotesDocument249 pagesPCML NotesNeeraj SirvisettiNo ratings yet
- Spectral Spurs Due To Quantization in Nyquist ADCsDocument18 pagesSpectral Spurs Due To Quantization in Nyquist ADCsNRicalNo ratings yet
- Topic 4 - Computational Thinking, Problem-Solving and Programming (IB Computer Science Revision Notes)Document7 pagesTopic 4 - Computational Thinking, Problem-Solving and Programming (IB Computer Science Revision Notes)Nethra SubramanianNo ratings yet
- Merino 2018Document13 pagesMerino 2018MofaNo ratings yet
- Cyberland ISCDocument4 pagesCyberland ISCNarek KhachatryanNo ratings yet
- 2-Discrete Fourier Transform PDFDocument80 pages2-Discrete Fourier Transform PDFHiteshNo ratings yet
- Operations ResearchDocument36 pagesOperations ResearchAshish BanstolaNo ratings yet
- Experiment 5: Aim: To Implement Mc-Culloch and Pitt's Model For A Problem. TheoryDocument7 pagesExperiment 5: Aim: To Implement Mc-Culloch and Pitt's Model For A Problem. TheoryNidhi MhatreNo ratings yet
- CA02CA3103 RMTGraphical Method For LPPDocument24 pagesCA02CA3103 RMTGraphical Method For LPPansarabbasNo ratings yet
- NR 310504 Theory of ComputationDocument9 pagesNR 310504 Theory of ComputationSrinivasa Rao G100% (2)
- Holt 5-2 Solving Systems by SubstitutionDocument37 pagesHolt 5-2 Solving Systems by SubstitutionjonquepostaNo ratings yet
- Column Generation With GamsDocument19 pagesColumn Generation With GamsBrayan IbañezNo ratings yet
- Student - 26th Dec - Solver - Shortest Path ProblemDocument7 pagesStudent - 26th Dec - Solver - Shortest Path ProblemPravalika ReddyNo ratings yet
- Machine Learning For Sport Results Prediction Using AlgorithmsDocument8 pagesMachine Learning For Sport Results Prediction Using AlgorithmsChaimaa AadiaNo ratings yet
- Markov Determinantal Point ProcessesDocument10 pagesMarkov Determinantal Point ProcessesvahidNo ratings yet
- Lab ManualDocument10 pagesLab ManualDhruvil ShahNo ratings yet
- Classification DecisionTreesNaiveBayeskNNDocument75 pagesClassification DecisionTreesNaiveBayeskNNDev kartik AgarwalNo ratings yet
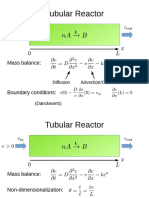
- Tubular Reactor: Mass BalanceDocument21 pagesTubular Reactor: Mass BalanceyohannesNo ratings yet
- Diferencias Cientifico e Ingenieros - Color PDFDocument1 pageDiferencias Cientifico e Ingenieros - Color PDFMonica Alejandra Rivera ToroNo ratings yet
- Braille Recognition For Reducing Asymmetric CommunDocument15 pagesBraille Recognition For Reducing Asymmetric CommunZath OnamNo ratings yet
- Distributed 10Document56 pagesDistributed 10gouzouNo ratings yet
- Roots of Equations - Open MethodsDocument12 pagesRoots of Equations - Open Methodsأحمد دعبسNo ratings yet