You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5819)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- NamesDocument367 pagesNamesEvan Smith0% (1)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- CEMU KeysDocument4 pagesCEMU KeysGino67% (3)
- WordsDocument5,916 pagesWordsJosh EdgcombNo ratings yet
- Common OMMONDocument1,243 pagesCommon OMMONbbdddNo ratings yet
- MongoDB Crud Guide PDFDocument82 pagesMongoDB Crud Guide PDFDante LlimpeNo ratings yet
- ASM With DB On Linux StepsDocument50 pagesASM With DB On Linux StepsMabu DbaNo ratings yet
- 11.5.10.4 Software Need CheckDocument4 pages11.5.10.4 Software Need CheckMabu DbaNo ratings yet
- Data Guard ScenariosDocument1 pageData Guard ScenariosMabu DbaNo ratings yet
- Oracle - 1Z0-027 Oracle Exadata Database Machine X3 AdministrationDocument5 pagesOracle - 1Z0-027 Oracle Exadata Database Machine X3 AdministrationMabu DbaNo ratings yet
- Transportable TablespaceDocument6 pagesTransportable TablespaceMabu DbaNo ratings yet
- GGSCIDocument10 pagesGGSCIMabu DbaNo ratings yet
- CatalogDocument3 pagesCatalogMabu DbaNo ratings yet
- CatalogDocument3 pagesCatalogMabu DbaNo ratings yet
- CompoundDocument4,280 pagesCompoundMabu DbaNo ratings yet
- Powershell Script 1Document9 pagesPowershell Script 1Mabu DbaNo ratings yet
- Ch.3 - Configuring A RouterDocument26 pagesCh.3 - Configuring A RouterArad RezaNo ratings yet
- Microsoft Windows Millennium Edition README For Installing Windows Me OntoDocument7 pagesMicrosoft Windows Millennium Edition README For Installing Windows Me Ontoraymondbailey2002No ratings yet
- Unit - IV 1. What Is Mean by Microcontroller?: Internal Blocks of MicrocontrollerDocument6 pagesUnit - IV 1. What Is Mean by Microcontroller?: Internal Blocks of MicrocontrollerkesavantNo ratings yet
- OpenCV OOPDocument311 pagesOpenCV OOPthanhlam2410No ratings yet
- VFP RichtextboxDocument26 pagesVFP RichtextboxJhon ThomasNo ratings yet
- DBMS AssignmentDocument3 pagesDBMS Assignmenthim02No ratings yet
- CISA Acronyms PDFDocument8 pagesCISA Acronyms PDFSarfaraz ArifNo ratings yet
- Step by Guide Rman For Dataguard-ID 469493.1Document11 pagesStep by Guide Rman For Dataguard-ID 469493.1Kirtikumar RahateNo ratings yet
- SAMA5D2 System in PackageDocument30 pagesSAMA5D2 System in PackageAgus OrtizNo ratings yet
- MDLS40466SPDocument45 pagesMDLS40466SPNelson Pimiento SerranoNo ratings yet
- Module 1 - Computer Fundamentals PPTDocument54 pagesModule 1 - Computer Fundamentals PPT77丨S A W ً100% (1)
- Nephology QuizDocument3 pagesNephology QuizBright StarNo ratings yet
- User's Guide NetViewDocument320 pagesUser's Guide NetViewanonNo ratings yet
- Define Computer PDFDocument54 pagesDefine Computer PDFamitukumar88% (8)
- Installing MySQL Cluster 7.0 - OpenSolarisDocument7 pagesInstalling MySQL Cluster 7.0 - OpenSolarismysql_clustering3251No ratings yet
- Monitoring Netflow With NfSenDocument5 pagesMonitoring Netflow With NfSenThanhNN0312No ratings yet
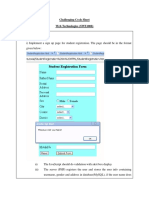
- Challenging Cycle Sheet Web Technologies (SWE1008) PHP and MysqlDocument4 pagesChallenging Cycle Sheet Web Technologies (SWE1008) PHP and Mysqlmsroshi madhuNo ratings yet
- 03 Chapter 15 Algorithms For Query Processing OptimizationDocument35 pages03 Chapter 15 Algorithms For Query Processing OptimizationAshok VaradarajanNo ratings yet
- Connection Pool CompareDocument4 pagesConnection Pool ComparePrashant ShirsathNo ratings yet
- Dell Poweredge R920technical Guide 2018junDocument52 pagesDell Poweredge R920technical Guide 2018junLeads InsightsNo ratings yet
- Wifite PYDocument118 pagesWifite PYJoao Jose Santos NetoNo ratings yet
- Unity Deep Dive LG PDFDocument260 pagesUnity Deep Dive LG PDFrashidNo ratings yet
- EAS Oracle WhitepaperDocument19 pagesEAS Oracle Whitepaperganesh rajanNo ratings yet
- LocallifecycleownerDocument9 pagesLocallifecycleownerMohamed Abdelhakim HacineNo ratings yet
- Views Vs Mview in Oracle PDFDocument43 pagesViews Vs Mview in Oracle PDFPrasannaNo ratings yet
- COB3.Close - of - Business-Important Concepts and COB Crashes-R14 PDFDocument30 pagesCOB3.Close - of - Business-Important Concepts and COB Crashes-R14 PDFPreethi GopalanNo ratings yet
- 4 Spark CassandraDocument15 pages4 Spark CassandrausernameusernaNo ratings yet
- Multipath and Dual CablingDocument6 pagesMultipath and Dual Cablingamitkr2301No ratings yet