You might also like
- Digital Integrated Circuit Design Using Verilog and SystemverilogFrom EverandDigital Integrated Circuit Design Using Verilog and SystemverilogRating: 3 out of 5 stars3/5 (4)
- Faar Field ManualDocument65 pagesFaar Field ManualAmit Srivastava100% (2)
- Hands-on Time Series Analysis with Python: From Basics to Bleeding Edge TechniquesFrom EverandHands-on Time Series Analysis with Python: From Basics to Bleeding Edge TechniquesRating: 5 out of 5 stars5/5 (1)
- Java Deep Learning Projects Implement 10 Real World Deep Learning Applications Using Deeplearning4j and Open Source ApisDocument428 pagesJava Deep Learning Projects Implement 10 Real World Deep Learning Applications Using Deeplearning4j and Open Source Apisankam praveenNo ratings yet
- R ProgrammingDocument60 pagesR Programmingzzztimbo100% (8)
- D3739-US Rev D EZIII Technical Manual0Document72 pagesD3739-US Rev D EZIII Technical Manual0raguilar1abc1No ratings yet
- Why Use Sauce LabsDocument2 pagesWhy Use Sauce LabskaranNo ratings yet
- Tesseract Osc OnDocument22 pagesTesseract Osc OnHannes S.No ratings yet
- Language Processing System NotesDocument55 pagesLanguage Processing System NotesAnamika MondalNo ratings yet
- Urdu Optical Character Recognition OCR Thesis Zaheer Ahmad Peshawar Its Soruce Code Is Available On MATLAB Site 21-01-09Document61 pagesUrdu Optical Character Recognition OCR Thesis Zaheer Ahmad Peshawar Its Soruce Code Is Available On MATLAB Site 21-01-09Zaheer Ahmad100% (1)
- Optical Character RecognitionDocument27 pagesOptical Character RecognitionAmit SrivastavaNo ratings yet
- Overview of Tesseract OCR EngineDocument5 pagesOverview of Tesseract OCR Enginerrs_1988No ratings yet
- An Overview of The Tesseract OCR Engine: 2. ArchitectureDocument6 pagesAn Overview of The Tesseract OCR Engine: 2. Architectureluis gNo ratings yet
- 1 OverviewDocument18 pages1 OverviewJeffrey YanNo ratings yet
- Optical Character Recognition (Ocr) : Karan Panjwani T.E - B, 68 Guided By: Prof. Shalini WankhadeDocument24 pagesOptical Character Recognition (Ocr) : Karan Panjwani T.E - B, 68 Guided By: Prof. Shalini WankhadeMansiNo ratings yet
- Tesseract I CD Ar 2007Document5 pagesTesseract I CD Ar 2007Nick HuNo ratings yet
- Offline Handwritten English Script Recognition: A SurveyDocument11 pagesOffline Handwritten English Script Recognition: A SurveyharshithaysNo ratings yet
- Chapter 1Document4 pagesChapter 1Er Mukesh MistryNo ratings yet
- C Programming Series: Basics For High-Performance ComputingDocument56 pagesC Programming Series: Basics For High-Performance ComputingVarun Kowshik DNo ratings yet
- An Overview of Tesseract OCR EngineDocument15 pagesAn Overview of Tesseract OCR EnginePhương Anh LêNo ratings yet
- Ocr Nanonets TesseractDocument39 pagesOcr Nanonets TesseractLeonNo ratings yet
- L4 - Transposition CipherDocument13 pagesL4 - Transposition CipherAdityaNo ratings yet
- R-Programming: Shubhangi JainDocument53 pagesR-Programming: Shubhangi JainShubhangi JainNo ratings yet
- R ProgrammingDocument61 pagesR Programmingmuragesh mathNo ratings yet
- R ProgrammingDocument60 pagesR Programmingnanaa02No ratings yet
- Introduction To Text MiningDocument82 pagesIntroduction To Text MiningRajesh SiraskarNo ratings yet
- Introduction To Computers and ProgrammingDocument41 pagesIntroduction To Computers and ProgrammingRajanikanth Bougolla BNo ratings yet
- R ProgrammingDocument37 pagesR ProgrammingfalconauNo ratings yet
- Optical Character Recognition Using MATLAB: Sandeep Tiwari, Shivangi Mishra, Priyank Bhatia, Praveen Km. YadavDocument4 pagesOptical Character Recognition Using MATLAB: Sandeep Tiwari, Shivangi Mishra, Priyank Bhatia, Praveen Km. Yadavجمال سينغNo ratings yet
- Ocr GttsDocument49 pagesOcr GttsKshitij NishantNo ratings yet
- R ProgrammingDocument60 pagesR Programmingpriya090909No ratings yet
- Why We Study Automata TheoryDocument27 pagesWhy We Study Automata TheoryAnamika Maurya0% (1)
- CDDocument1 pageCDRahul SharmaNo ratings yet
- Multimedia and WS-CS 550-Content Analysis v1Document27 pagesMultimedia and WS-CS 550-Content Analysis v1devices.hcsNo ratings yet
- Google'S Pagerank and Beyond:: The Science of Search Engine RankingsDocument158 pagesGoogle'S Pagerank and Beyond:: The Science of Search Engine RankingsvssvssNo ratings yet
- Data Types and Memory Management: CSCI 3136 Principles of Programming LanguagesDocument66 pagesData Types and Memory Management: CSCI 3136 Principles of Programming Languagesashokmohan87No ratings yet
- Presentation On OCR of Noisy Images Using MATLABDocument23 pagesPresentation On OCR of Noisy Images Using MATLABSmriti SinghNo ratings yet
- Feature EngineeringDocument44 pagesFeature EngineeringVenkata Gnaneswar DasariNo ratings yet
- PPL-Unit 3Document28 pagesPPL-Unit 3praveennallavellyNo ratings yet
- Introduction To Data Science With R ProgrammingDocument40 pagesIntroduction To Data Science With R ProgrammingVimal KumarNo ratings yet
- An Analysis of The Performance of Named Entity Recognition Over Ocred DocumentsDocument2 pagesAn Analysis of The Performance of Named Entity Recognition Over Ocred DocumentsPaul BismuthNo ratings yet
- Embedded Systems Course ContentDocument8 pagesEmbedded Systems Course Contentsrkreddy1234No ratings yet
- SL NO. Name Usn Number Roll NoDocument10 pagesSL NO. Name Usn Number Roll NoVîñåÿ MantenaNo ratings yet
- BalricLing Athens VGDocument23 pagesBalricLing Athens VGVoula GiouliNo ratings yet
- BIS RaysRecogDocument16 pagesBIS RaysRecogSaranyaRoyNo ratings yet
- Unit 1 Big Data Analytics - An Introduction (Final)Document65 pagesUnit 1 Big Data Analytics - An Introduction (Final)Murtaza VasanwalaNo ratings yet
- Basic Programming Language OverviewDocument202 pagesBasic Programming Language Overviewahmad rehmanNo ratings yet
- OCR PresentationDocument16 pagesOCR PresentationAniket JainNo ratings yet
- Detection of Bold Italic and Underline Fonts For Hindi OCRDocument4 pagesDetection of Bold Italic and Underline Fonts For Hindi OCRseventhsensegroupNo ratings yet
- CSS Syllabus: Subject: Computer ScienceDocument6 pagesCSS Syllabus: Subject: Computer Sciencewajeeh rehmanNo ratings yet
- Script IdentificationDocument2 pagesScript Identificationdharanisathyan35No ratings yet
- Lecture 1: Part I: Emerging Database Technology, Research and ApplicationsDocument11 pagesLecture 1: Part I: Emerging Database Technology, Research and ApplicationsGuzhal HariNo ratings yet
- BSM 461 Introduction To Big Data: Kevser Ovaz Akpınar, PHDDocument22 pagesBSM 461 Introduction To Big Data: Kevser Ovaz Akpınar, PHDNermin KayaNo ratings yet
- High Accuracy Optical Character Recognition Using Neural Networks With Centroid DitheringDocument7 pagesHigh Accuracy Optical Character Recognition Using Neural Networks With Centroid DitheringMuhammed AjeerNo ratings yet
- Thesis On Speaker Recognition SystemDocument4 pagesThesis On Speaker Recognition Systemafbtegwly100% (1)
- 5 Papers Extraction - Hor Kimchheng - Evening - Cohort 12Document6 pages5 Papers Extraction - Hor Kimchheng - Evening - Cohort 12HOR KicmhhengNo ratings yet
- Introduction To NOSQL and Cassandra: @rantav @outbrainDocument60 pagesIntroduction To NOSQL and Cassandra: @rantav @outbrainchrisjaureNo ratings yet
- Optical Character Recognition: Unlocking the Power of Computer Vision for Optical Character RecognitionFrom EverandOptical Character Recognition: Unlocking the Power of Computer Vision for Optical Character RecognitionNo ratings yet
- String Algorithms in C: Efficient Text Representation and SearchFrom EverandString Algorithms in C: Efficient Text Representation and SearchNo ratings yet
- Computer Systems 5Th Edition Full ChapterDocument41 pagesComputer Systems 5Th Edition Full Chapterjoy.dial537100% (27)
- Automated Technology (Phil), Inc. (Atec) : Reported byDocument5 pagesAutomated Technology (Phil), Inc. (Atec) : Reported byJess ChanceNo ratings yet
- PSRAM DatasheetDocument24 pagesPSRAM DatasheetwyHumsh9No ratings yet
- Hand Writing RecognitionDocument12 pagesHand Writing Recognitionnaitiknakrani1803No ratings yet
- Vijeo TrainingDocument6 pagesVijeo TrainingKhaldoon AlnashiNo ratings yet
- Case Study Idea Some Sage AdviceDocument1 pageCase Study Idea Some Sage Adviceavinash_k007No ratings yet
- CH 5,6,7Document110 pagesCH 5,6,7shikha jainNo ratings yet
- Sepa FileDocument8 pagesSepa FileRajendra PilludaNo ratings yet
- The AVR Microcontroller and C CompilerDocument6 pagesThe AVR Microcontroller and C CompilerAhsan MughalNo ratings yet
- P.G.D.C.A. Semester - I DCA-104: Office Automation Tools: Hemchandracharya North Gujarat University, PatanDocument2 pagesP.G.D.C.A. Semester - I DCA-104: Office Automation Tools: Hemchandracharya North Gujarat University, PatanVadi GaneshNo ratings yet
- CSC Request For Eligibility PDFDocument4 pagesCSC Request For Eligibility PDFLea VioletaNo ratings yet
- TUGAS BESAR Pemodelan Optimasi S2Document2 pagesTUGAS BESAR Pemodelan Optimasi S2soniyoraNo ratings yet
- Database Server Comparison: Dell PowerEdge R630 vs. Lenovo ThinkServer RD550Document18 pagesDatabase Server Comparison: Dell PowerEdge R630 vs. Lenovo ThinkServer RD550Principled TechnologiesNo ratings yet
- SyllabusDocument129 pagesSyllabusDevansh RautelaNo ratings yet
- NeffDocument16 pagesNeffAliAbdulKarimNo ratings yet
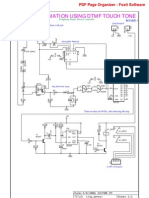
- DTMF TouchTone.Document12 pagesDTMF TouchTone.Gigin IgnatiusNo ratings yet
- Modeling & SimulationDocument51 pagesModeling & Simulationsnemo300% (1)
- UPI Swan294 ID Number 5421939 Group Number 17Document12 pagesUPI Swan294 ID Number 5421939 Group Number 17Suyangzi WangNo ratings yet
- Hibernate Reverse EngineeringDocument2 pagesHibernate Reverse EngineeringketsorbitNo ratings yet
- 100 MCQs On JavaDocument26 pages100 MCQs On JavaDr. KarthickeyanNo ratings yet
- Splunk Use Cases WebinarDocument26 pagesSplunk Use Cases Webinarjpl1100% (1)
- Using The Phase Plot Tool For MATLABDocument3 pagesUsing The Phase Plot Tool For MATLABJojo KawayNo ratings yet
- GSI Fusion GL - Budget Entry and Reporting - R11Document10 pagesGSI Fusion GL - Budget Entry and Reporting - R11rasiga6735No ratings yet
- Xport 360 ManualDocument25 pagesXport 360 ManualsouljahhNo ratings yet
- Suyue Li, Jian Xiong, Lin Gui, and Youyun Xu,: Member, IEEE, Member, IEEE, Senior Member, IEEEDocument13 pagesSuyue Li, Jian Xiong, Lin Gui, and Youyun Xu,: Member, IEEE, Member, IEEE, Senior Member, IEEEKrishna KrishnaNo ratings yet
- NDJ OilPlam Eng Booklet 130311FDocument165 pagesNDJ OilPlam Eng Booklet 130311FLigar PangestuNo ratings yet