Solution of Discretized Equations
Uploaded by
Sandeep KadamSolution of Discretized Equations
Uploaded by
Sandeep Kadam5.
Solution of Discretized Equations
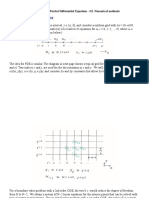
In the last two chapters, we have seen the principles underlying the discretization of the governing equations using schemes of the desired accuracy and stability behaviour. The result of the discretization of an equation is a system of coupled, often non-linear, algebraic equations. In this chapter, we will look at methods available to solve these discretized equations. Before discussing the details of the algebraic equation solvers, let us first examine the nature of the discretized equations by taking the example of generic scalar transport equation: d(rhophi)/dt + del.(rhouphi) = del.(gamma delphi) + Sphi (1)
where phi is the scalar and the other terms and variables have the usual significance. In principle, the following discussion can be extended to the solution of simultaneous solution of the mass, momentum and energy conservation equations. However, several additionals issues have to be considered before this is possible and a full discussion of this, i.e., the simultaneous solution of all the governing equations, is postponed to the next chapter. Consideration of the the generic scalar equation (1) is sufficient for the present purpose of studying the techniques for the solution of the discretized equations. Without much loss of generality, we restrict our attention to a two-dimensional case in cartesian coordinate system with constant properties and no source terms. For this case, equation (1) can be written as d(rhophi)/dt + d/dx(urho phi) + d/dy(vrhophi) = gamma (d2phi/dx2 + d2phi/dy2) (2) Considering a rectangular grid (Figure 1) with uniform spacing of dx and dy in the x- and ydirections and using a first order upwind scheme (assuming u and v to be positive) for the advection term, central scheme for the diffusion term and a first order implicit scheme for the time derivative, the discretized equation corresponding to equation (2) can be written as 1/dt( phiijn+1 phiijn) + u/dx( phiijn+1 phi-1jn+1) + v/dy(phiijn+1 phiij-1n+1) = gamma[(phhi+1jn+1 2phiijn+1 + phii-1jn+1)/dx^2 + (phiij+1n+1 2phhijn+1 + phiij-1n+1)/dy^2] (3) The above equation can be rearranged to cast it in the following form: aijphijn+1 + ai-1jphii-1jn+1 + ai+1jphii+1jn+1 + aij-1phiij-1n+1 + aiij+1phiij+1n+1 = bij (4) where ai-1j = ai+1j = aij-1 =
(5)
aij+1 = aij = bij = Considering a 5 x 5 grid with Dirichlet boundary conditions on a cartesian grid shown in Figure 2, for each time step, we have the following nine unknowns: phi22, phi32, phi42, phi23, phi33, phi43, phi24, phi34 and phi44. Correspondingly, we will have nine algebraic equations of the form of (4). Listing these in the above lexicographic order, i.e., in a permution involving (ijk), going through all the possible values of I while keeping before changing j and k and continuing this way until all the permutations are over, results in the following set of algebraic equations: (6) which can be put in matrix form as [A] [phi] = [b] where the A, phi and b are given by (8) Equations of the form (7) have to be solved at each time step in order to obtain the values of phiij. Before we address the question of how to solve these equations, a number of remarks are in order. In general, the flow may be characterized by a number of variables, e.g., laminar, newtonian, incompressible, non-reacting, isothermal two-dimensional flow requires the specification of u, v and p to completely characterize the flow field. A number of additional variables are required for the description of turbulent reacting flows as will be seen in Chapter 8. Each such variable will have a set of equations of the form (7). Often, these equations are coupled and the coefficients aij are non-linear and unknown (as they may involve variables which have not yet been solved for). In the general case, these are linearized and solved iteratively using methods to be discussed in Chapter 6. The process of linearization results in a set of equations of the form of equation (7) for each variable with constant (estimated) coefficients (which are regularly updated in the iterative scheme). These have to be repeatedly solved in order to arrive at the desired solution. Therefore, an efficient method for the solution of the linear algebraic equations is necessary in order to keep the computational requirements to within reasonable limits. In the present chapter, we discuss various options for doing so. It is pertinent, at this stage, to consider the general features of the set of equations we wish to solve. The number of equations in the set is equal to the number of grid points at which the variable is to be evaluated. For a typical CFD problem, the number of grid points is very large and can be of the order of 10000 to 1000000 or even higher for complicated three(7)
dimensional flows. Hence, the set of equations we are dealing with is very large. Hence speed of solution and memory requirements are important considerations in choosing an efficient method. Another general feature of the equations is the sparseness of the coefficient matrix A. Since the value of a variable phiij is typically expressed in terms of its immediate neighbours, each equation will have only a few non-zero coefficients. For example, in the example considered, phiij is expressed in terms of its four neighbours and the computational molecule, see Figure 3, involves five nodal points and correspondingly, the algebraic equations contain at most five non-zero coefficients. If schemes of higher order accuracy are used, or if a threedimensional case is considered in a non-orthogonal coordinate system, more number of nodes may be involved. Schemes with a 19-node computational molecule have been proposed. This implies that each of the equations of (7) may contain up to 19 non-zero coefficients. For a problem with 10000 grid points, the non-zero coefficeints could therefore be 190000 which is considerably less than the general case in which all the 10000 x 10000 = 108 coefficients would be non-zero. Thus, the coefficient matrix A is generally very sparse. Also, the non-zero coefficients may lie in the case of strucutred grids along certain diagonals as is evident from equation (8). The number of these diagonals depends on the terms present in the governing partial differential equation and the discretization and linearization schemes used to obtain the linearized algebraic equations. This diagonal structure of the coefficient matrix is not in general present in an unstrucutred mesh. Finally, the coefficient matrix usually exhibits the diagonal dominance feature, i.e, the magnitude of the diagonal element is greater than the sum of the magnitudes of the off-diagonal elements. While this is not a requirement for the general case, this is certianly a desirable feature and special care is taken in the discretization and linearization process to ensure this in its weak form, i.e., that diagonal dominance is present for at leat one of the set of equations while for the others the magnitude of the diagonal element is at least equal to the sum of the magnitudes of the off-diagonal elements. These are the general features of the set of linear algebraic equations which we need to solve. Two large classes of methods are available for the resolution of these linear algebraic equations: direct and iterative methods. Direct methods are based on a finite number of arithmetic operations leading to the exact solution of a linear algebraic system except for roundoff errors that are inevitable in a computed solution. Iterative methods, on the other hand, are based on producing a succession of approximate solutions which leads to the exact solution after an infinite number of steps. In practice, due to round-off and other considerations (such as the need to update the coefficient matrix A to account for non-linearity), a finitely accurate solution is sought. When this is the case, the number of arithmetic operations required to solve the equation using a direct method can be very high, and it is often much larger than that required by an iterative method to achieve a given level of accuracy. Also, iterative methods take account account of the sparseness of the coefficient matrix while direct methods, except in special cases, do not do so. For all these reasons, iterative methods are invariably used to solve the linearized algebraic equations in CFD problems. However, many techniques used for accelerating the
convergence rate of iterative methods are based on approximations derived from direct methods. Also, when multigrid methods or coupled solution methods are used, both iterative and direct methods may be used in the overall scheme of solution. In view of this, we discuss both direct and iterative methods. The basic methods of each class are discussed in Sections 5.1 and 5.2, respectively. These are followed in Section 5.3 by more advanced iterative methods and in Section 5.4 by multigrid methods.
5.1 Direct Methods 5.1.1 Cramer's rule This is one of the most elementary methods and is often taught in school-level algebra courses. For a system of equations described as sum over I of (aijphi I ) = bi the solution for phii can be obtained as phi I = |Ai| / |A| (10) (9)
where the matrix Ai is obtained by replacing the ith column by the column vector bi. Thus, for the system of three equations given by 2 phi + 3 phi2 + 4 phi3 = 5 6 phi1 + 7 phi2 + 8 phi3 = 9 10 phi1 + 13 phi2 + 14 phi3 = 12 phi1, phi2 and phi3 are given by |5 3 4| phi1 = | 9 7 8 | | 12 13 14 | |2 3 4| |6 7 8| | 10 13 14|
|2 5 4| phi1 = | 6 9 8 | | 10 12 14 |
|2 3 4| |6 7 8| | 10 13 14|
|2
5|
|2 3 4|
phi1 = | 6 7 9 | | 10 13 12 |
|6 7 8| | 10 13 14|
While this method is elementary and yields a solution for any non-singular matrix A, it is very inefficient when the size of the matrix is large. The number of arithmetic operations required to obtain the solution varies as (n+1)!, where n is the number of unknowns (or equations), for large n. Thus, the number of arithmetic operations for 10 equations is of the order of 4 x 107 and can be obtained in a fraction of a second using a Gigaflop personal computer. For the solution of 20 equations, the number of required is of the order of 5 x 1019 which increases to 8 x 1033 for a system of only 30 equations. Even the fastest computer on the earth would require billions of years to get a solution in this case involving the equivalent of 30 grid points. Hence extreme caution should be exercised in using Cramers rule in CFD computations. 5.1.2 Gaussian elimination In contrast to the Cramers rule, Gaussian elimination method is a very useful and efficient way of solving a general system of algebraic equations, i.e., one which does not have any structural simplifications such as bandedness, symmetry and sparseness, etc. The method consists of two parts. In the first part, the system of n equations and n variables is systematically and successively reduced to a smaller system containing a smaller number of variables by a process known as forward elimination. This ultimately results in a coefficient matrix in the form of an upper triangular matrix which is readily solved in the second part using a process known as back substitution. These steps are explained below. Consider the set of equations given by a11u1 + a12u2 + .................................... = c1 a21u1 + a22u2 + .................................... = c2 . . . an1u1 + an2u2 + .................................... = cn
(11)
The objective of the forward elimination is to transform the coefficient matrix {aij} into an upper triangular array by eliminating some of the unknowns from of the equations by algebraic operations. This can be initiated by choosing the first equation as the "pivot" equation and using it to eliminate the u1 term from each equation. This is done by multiplying the first equation by a21/a11 and substracting it from the second equation. Multiplying the pivot equation by a31/a11 and subtracting it from the third equation eliminates u1 from the third equation. This procedure is continued until u1 is eliminated from all the equations except the first one. This results in a
system of equations in which the first equation remains unchanged and the subsequent (n-1) equations form a subset with modified coefficients (as compared to the original aij) in which u1 does not appear: a11u1 + a12u2 + .................................... = c1 a22u2 + a23u3 + .................... = c2 . . . an2u2 + an3u3 + ........................ = cn
(12)
Now, the first equation of this subset is used as pivot to eliminate u2 from all the equations below it. The third equation in the altered system is then used as the next pivot equation and the process is continued until only an upper triangular form remains: a11u1 + a12u2 + .................................... a22u2 + a'23u3 + ......................... a33u3 + a34u4 + ................ . an-1n-1un-1 + an-1nun annun = c1 = c'2 = c3 = cn-1 = cn
(13)
This completes the forward elimination process. The back substitution process consists of solving the set of equations given by (13) by successive substituion starting from the bottommost equation. Since this equation contains only one variable, namely, un, it can be readily calculated as un = cn/ ann. Knowing un, the equation immediately above it can be solved by subsituting the value of un into it. This process is repeated until all the variables are obtained. Of the two steps, the forward elimination step is the most consuming and requires about n3/3 arithmetic operations for large n. The back substitution process requires only about n2/2 arithmeticoperations. Thus, for large n, the total number of arithmetic operations required to solve a linear system of n equations by Gaussian elimination varies as n3 which is significantly less than the (n+1)! operations required by Cramers rule. While Gaussian elimination is the most efficient method for full matrices without any specific structure, it does not take advantage of the sparseness of the matrix. Also, unlike in the case of iterative methods, there is no possibilty of getting an approximate solution involving fewer number of arithmetic operations. Thus, full solution, and only full solution, is possible at the end of the back substitution process. This feature of lack of an intermediate, approximation solution is shared by all direct methods and is a disadvantage when solving a set of non-linear algebraic equations as the coefficient matrix needs to be updated repeatedly in an overall iterative scheme as the Newton-Raphson
method. Finally, for large systems that are not sparse, Gaussian elimination, when done using finite-precision arithmetic, is susceptible to accumulation of round-off errors and a proper pivoting strategy is required to reduce this. Pivoting strategy is also required to eliminate the possibility of zero-diagonal element as this will lead to a division by zero. A number of pivoting strategies have been discussed in Marion (19??) although accumulation of round-off error may not pose a major problem in CFD-related situations as the coefficient matrix is very sparse. 5.1.3 Gauss-Jordon elimination A variant of the Gaussian elimination method is the Gauss-Jordan elimination method. Here, variables are eliminated from rows both above and below the pivot equation. The resulting coefficient matrix is a diagonal matrix containing non-zero elements only along the diagonal. This eliminates the back substitution process. However, no computational advantage is gained as the number of arithmetic operations required for the elimination process is about three times higher than that required for the Gaussian elimination method. Gauss-Jordon elimination can be used to find the inverse of the coefficient matrix efficiently. It is also particularly attractive when solving for a number of right hand side vectors [b] in equation (7). Thus, Gauss-Jordon method can be used to simultaneously solve the following sets of equations: [A] .[x1 |_| x2 |_| x3 |_| Y] = [b1 |_| b2|_| b3 |_| I] which is a compact notation for the following system of equations: A. x1 = b1 A.x2 = b2 Ax3 = b3 and A.Y = I (14)
where I is the identity matrix and Y is obviously the inverse of A, i.e., A-1. The computed A-1 can be used later, i.e., not at the time of solving equation (14) to solve for an additional right hand side vector b4, i.e., to solve A.x4 = b4 as x4 = A-1b4 at very little additional cost. Since computations are usually done with finite-precision arithmetic, the computed solution, x4, may be affected by round-off error, which however may not be a hazard in CFD-related problems as the coefficient matrix A is usually sparse and the resulting round-off error is therefore smaller than in solving full matrices.
5.1.4 LU decomposition LU decomposition is one of several factorization techniques used to decompose the coefficient matrix A into a product of two matrices so that the resulting equation is easier to solve. In LU decomposition, the matrix A is written as the product of a lower (L) and an upper (U) triangular matrix, i.e., [A] = [L] [U] or aij = sum over k of (lik ukj). Such decomposition is
possible for any non-singular square matrix. Before we discuss the algorithm for this decomposition, i.e., the method of finding lij an uij for a given aij, let us examine the simplification of the solution resulting from this factorization. With the LU decomposition, the matrix equation [A] [phi] = [b] can be written as [L][U][phi] = [b] which can be solved in two steps as [L] [y] = [b] [U][phi] = [y] (15a) (15b) (14) (7)
Solution of equations (15a) and (15b) can be obtained easily by forward and backward substitution, respectively. Thus, the LU decomposition renders the solution of (7) easy. The key to the overall computational efficiency lies in the effort required to find the elements of [L] and [U]. For a given non-singular matrix A, the LU decomposition is not unique. This can be seen readily by writing the decomposition in terms of the elements as | | | | | | | = | | | | | | | | | | | | | | | (16) | |
Since aij = sum (lik ukj), equation (16) gives N2 equations, where N is the number of rows (or columns) in matrix A, while the number of unknowns, i.e., the elements of L and U matrices, are N2+N. An efficient algorithm, known as Crouts decomposition, results if the N diagonal elements of L, i.e., lii, are set to unity. This makes the number of remaining unknowns equal to the number of available equations which can be solved rather trivially by rearranging the equations in a certain order. The Crouts algorithm for finding the the lij and uij can be summarized as follows: Set lii = 1 for k = 1, 2, . N For each j = 1, 2, . N, solve for (17) uij = aij - sum(k = 1 to I-1) of (likukj) for I = 1, 2, , j lij = 1/ujj(aij- sum(k = 1to j-1 of (likukj) for I = j+1, =2, N
Pivoting is necessary to avoid division by zero (which can be achieved by basic pivoting) as well as to reduce round-off error (which can be achieved by partial pivoting involving row-wise permutations of the matrix A). A variation of the Crouts decomposition is the Doolittle decomposition where the diagonal elements of the upper triangular matrix are all set to unity and the rest of uij (I=/j) and lij are found by an algorithm similar to that in equation (17). It can be shown that this procedure is equivalent to the forward elimination step of the Gaussian elimination method described in section 5.1.2 above. Thus, the number of arithmetic operations to perform the LU decomposition is N3/3. However, the final solution solution is obtained by a forward substitution step followed by a back substitution step, each of which would take about n2/2 number of arithmetic operations. Thus, for large N, the Gaussian elimination and the LU decomposition are nearly equivalent in terms of the number of the number of arithmetic operations required to obtaine the solution. The principal advantage of the LU decomposition method lies in the fact that the LU decomposition step does not require manupulation of the right hand side vector, b, of equation (7). While LU decomposition is rarely used on its own in large CFD problems, an approximate or incomplete form of it is used to accelerate the convergence of some iterative methods, as will be discussed below. 5.1.5 Cholesky Decomposition
This is a special form of the LU decomposition for matrices which are symmetric and positive definte. If matrix A is symmetric, then Aij = Aji (18) and if it is positive definite, then for all non-zero vectors v, v.A.v >0 (19) which is the equivalent of saying that all the eigenvalues of A are real and posiitive. A sufficient condition for positive definiteness is the Scarborough condition of general diagonal dominance, namely, |aii| >= sum over j = 1 to N but j=/I of (|aij| for all I = sum over j= 1 to N but j=/I of (|aij|) for at least one I
(20)
For matrices which satisfy conditions (18) and (19), the LU decompositon can be performed as (21) A = LLT requiring half the number of arithmetic operations and without any pivoting. Noting that Lij = LjiT, the algorithm for Cholesky decomposition can be written as Lii = (aii sum over k = 1 to I-1 of (Lik^2))^0.5 and Lji = 1/Lii(aij-sumover k = 1 to I-1(LikLjk) for j = I+1, I+2 , N (22)
Since the conditions of symmetry and positive definiteness of A are not satisfied in many cases dealing with fluid flow problems, the Cholesky decomposition is not used itself as a solution scheme but an incomplete version of it is used in conjugate gradient methods to be described later in this chapter. 5.1.6 Direct Methods for Banded Matrices Banded coefficient matrices often result in using CFD problems based on structured mesh algorithms. In addition to allowing for more efficient storage of the coefficients (wherein the non-zero values of the coefficient matrix are not usually stored), banded matrices often permit simplification of the general elimination/ decomposition techniques described above to such an extent that very efficient solution methods may be found for simple, but not uncommon, banded matrices. Here, we examine the specialized algorithms for three such banded matrices: tridiagonal, pentadiagonal and block tridiagonal systems. Consider the set of algebraic equations represented by Tx = s (23)
where T is an n x n tridiagonal matrix with elements Ti, I-1 = ci, Ti,I = ai and Ti, I+1 = bi. The standard LU decomposition of T then produces an L and U matrices which are bidiagonal. This process can be simplified to produce an equivalent upper bidaigonal matrix of the form Ux = y (24)
where the diagonal elements of U are all unity, i.e., Ui,I = 1 for all i. Denoting the superdiagonal elements of U, namely, Ui,I+1 by di, equation (24) implies conversion of the ith equation of the tridiagonal system of equation (23), namely, cixi-1 + aixi + bixi+1 = si (25) to be expressed as xi + dixi+1 = yi (26) where the coefficients di and yi are yet to be determined. This is done as follows. Solving (26) for xi, we have xi = yi - dixi+1 Thus, xi-1 = y-1 - di-1xi Substituting the above expression for xi-1 into (25) and rearranging, we have xi + bi/(ai-ci*di-1) xi+1 = (si-yi-1*ci)/(ai-ci*di-1) (27)
Comparing equations (26) and (27), we get the following recurrence relations to determine di and yi: di = bi/(ai-ci*di-1) yi = (si-ci*yi-1)/(ai-ci*di-1) (28) Also, for the first row, i.e., I = 1, we have d1 = b1/a1 and y1 = s1/a1. Using equation (28), the tridiagonal matrix can be converted into an upper bidiagonal matrix as shown schematically in Figure [Link]. It can be seen that the resulting matrix equation, Ux=y, can be solved readily by back-substitution. The above procedure, involving a simplification of the Gaussian elimination procedure, to solve the tridiagonal system given by equation (23) is known as the Thomas algorithm or the tridiagonal matrix algorithm (TDMA). It can be summarized as follows: Step I : Determine the coefficients, di and yi, of the bidiagonal system (24) using the following formulae: d1 = b1/a1 and y1 = s1/a1 di+1 = bi+1/(ai+1-ci+1di) | yi+1 = (si+1 ci+1yi)/(ai+1-ci+1di) |
for I = 1 to N-1
(29)
and
Step II: Solve the bidiagonal system (24) by back-substitution: xN = yN and xi = yi-dixi+1 for I = N-1, N-2, 2,1 (30)
The Thomas algorithm, encapsulated in equations (29) and (30), is very efficient and the number of arithmetic operations required for solution of equation (23) varies as N (compared to ~N3 for Gaussian elimination and LU decompostion techniques). No pivoting strategy is incoporated in the Thomas algorithm and it may fail therefore if a division by zero is encountered. It can be shown that this possibility does not arise if the matrix T is diagonally dominant, which is usually the case in many applications. In such cases, the Thomas algorithm provides a very efficient method for solving the set of linear equations. In a number of cases, the elements ai, bi and ci of the matrix T in equation (23) may not be scalars but may themselves be matrices (Anderson et al., 1984) and equation (23) may take the following form: | [B1] [C1] |[A2} [B2] | [A3] | |[X1]| | |[X2]| | |[X3]| |[Y1] |[Y2]| = |[Y3]| (31)
[C2} [B3]
[C3]
| | |
[AN
| | | | | | [BN] | |[XN]|
| | | | |[YN]|
where [A], [B], [C] , [X] and [Y] are square matrices. Matrix of the form of the coefficient matrix in equation (31) are called block-tridiagonal matrix. The Thomas algorithm for scalar coefficients can be used to solve block-tridiagonal matrices also. The only modification required is that the division by the scalar coefficient should be replaced by multiplication with the inverse of the corresponding matrix. Thus, the Thomas algorithm for block-tridiagonal systems can be written as d1 = a1-1b1 y1 = ai-1s1 di+1 = (ai+1-ci+1di)-1(bi+1) | yi+1 = (ai+1 ci+1di)-1(zi+1-ci+1yi) | and the back substitution step is given by xN = yN xi = yi-dixi+1 (33a) (33b) (32a) (32b) (32c) (32d)
for I = 1, N-1
If the sub-matrices [A], [B] etc. are large, the matrix inversion steps in equation (32) may be performed without explicitly evaluating the inverse, for example, by solving a1d1=b1 instead of as given in equation (32a). The Thomas algorithm for tridiagonal matrices can be extended to the solution of pentadiagonal systems. Consider the set of equations Px = s (34) where P is a pentadiagonal matrix, i.e., it has non-zero elements only along five adjacent diagonals. Let these non-zero elements be represented by five row vectors as Pi,I-2=ei; Pi,I-1 = di; Pi,I = ai; Pi,I+1=bi; Pi,I+2=ci (35)
The pentadiagonal system given by equation (34) can be converted first to a quadradiagonal system Qx = s (36) where Q contains non-zero elements in (I,I-1), (I,I), (I, I+1) and (I, I+2), and then to an upper tridiagonal system Tx = s (37)
where T contains non-zero elements in (I,I), (I,I+1) and (I,I+2) which can be solved by backsubstitution. Denoting the elements of the matrices Q and T in a manner analogous to that given for P in equation (35) as Qi,I-1 = di; Qi,I = ai; Ti,I = ai; Qi,I+1 = bi; Qi, I+2 = ci Ti,I+1 = bi; Ti,I+2 = ci (38) (39)
The procedure adopted for the tridiagonal system can be extended to obtain recurrence relations to determine the elements of Q, T, s and s. These details are not given but the resulting pentadiagonal matrix algorithm (PDMA) for the solution of the pentadiagonal system of equation (34), involving three steps, is given below: Step I : Find the elements of Q and s using the following formulae: a1 = a1 d2 = d2 and for I = 2 to N-1, ci aI+1 bI+1 dI+1 sI+1 b1 = b1 a2 = a2 c1 = c1 b2 = b2 s1 = s1 s2 = s2
= ci = ai+1 - bI*(ei+1/dI) = bi+1 - cI*(ei+1/dI) = di+1 - aI*(ei+1/dI) = si+1 - sI*(ei+1/dI)
(40)
Step II: Find the elements of T and s using the following formulae: b1 = b1/a1 c1 = c1/a1 s1 = s1/a1 bI+1 = (bI+1-dI+1*cI)/(aI+1-dI+1*bI) cI+1 = cI+1/(aI+1-dI+1*bI) (41) sI+1 = (sI+1 -dI+1*sI)/ (aI+1-dI+1*bI)
for I = 1 to N-1
Step III: Find xi by modified backward substitution using the following formulae: xN = sN xN-1 = sN-1 - bN-1*xN xi = sI - bI*xi+1 - cI*xi+2
and for I = N-2, N-3, , 1
(42)
Similar to the Thomas algorithm, the pentadiagonal scheme given above is a special version of Gaussian elimination procedure in which arithmetic operations involving the zero elements of the coefficient matrix are pruned out leaving a compact and efficient scheme. Even more efficient methods such as cyclic reduction methods are available for specialized matrices
(Pozrikidis, 1998) but these are not discussed here. It should be noted that the TDMA and PDMA schemes given above are valid only when the three or five diagonals, respectively, are adjacent to each other. If there are zero diagonal elements in between, as illustrated in Figure 5. Xxx, then the above schemes may not work. Specifically, the discretization of the transient heat conduction equation in two-dimensions results in a penta-diagonal system but one in which the diagonals are not adjacent to each other. The PDMA scheme cannot be used to solve this system, and thus has limited application in CFD-related problems. For such cases, the alternating direction implicit (ADI) method can be used which makes use of the TDMA scheme to solve equations implicitly in one direction at a time. This method is discussed later.
5.2 Basic Iterative Methods Iterative methods adopt a completely different approach to the solution of the set of linear algebraic equations. Instead of solving the original equation Ax = b they solve x = Px + q (7) (43)
where the matrix P and the vector q are constructed from A and b in equation (7). Equation (43) is solved by the method of successive approximations, also known as Picards method. Starting with an arbitrary initial vector x0, a sequence of vectors xk, k>=0 is produced from the formula xk+1 = Pxk + q k >=0 (44)
The iterative method is said to be convergent if lim k-> inf (xk) = x for every initial vector x0 (45)
Whether or not an iterative method converges depends on the choice of the matrix P, known as iteration matrix, in equation (43). Even for convergent methods, the rate of convergence is not necessarily the same. (For non-linear algebraic equations additional considerations arise but the choice of the initial vector, x0, is also important; however, for linear problems, this is not the case.) Thus, an iterative method for the linear algebraic equation (7) is characterized by the construction of P and q; by the conditions for convergence of the sequence (44) and by the rate of convergence. Once these are determined, the implementation of an iterative scheme is rather simple compared to the direct methods so much so that Gauss, in 1823, was supposed to have
written in reference to the iterative method (see Axelsson, 1994) I recommend this modus operandi. you will hardly eliminate anymore, at least not when you have more than two unknowns. The indirect method can be pursued while half asleep or while thinking about other things. This advantage of simplicity is negated by the theoretical limit infinite number of iterations needed to get the exact solution. However, there is a practical limitthe machine accuracy or round-off error-- to the accuracy that can be attained when solving equations using modern computers and it is sufficient to undertake only a finite number of iterations to achieve this for any converging iterative methods. Finally, when the algebraic equations are solved in a CFD context involving non-linear equations, it is not necessary to solve the equations even to machine accuracy. Some of these and other characteristicsboth advantageous and disadvantageous in comparison with direct methodsare dicussed below for three classical iterative methods, namely, the Jacobi method, the Gauss-Seidel method and the relaxation or more specifically, the successive overrelaxation (SOR) method. We first discuss how the iteration matrix P is constructed from the coefficient matrix A in each case and follow this up by an analysis of its convergence behaviour. All the three methods involve splitting of the matrix A into two matrices as A=M-N (46) where M is an easily invertible matrix, i.e., of diagonal or triangular or block diagonal or block triangular structure. It is noted that diagonal systems, i.e., systems in which the coefficeint matrix is diagonal, can be solved (inverted, although the inverse of the matrix may not be explicitly computed in practice) readily, triangular matrices can be solved efficiently by forward or back-substitution. Substituting the above splitting into equation (7), we obtain (M-N)x = b Mx = Nx + b x = M-1Nx + M-1b
or or
(47)
which is in the form of equation (43) with P = M-1N and q = M-1b. In practice, M-1 is not computed and the iterative scheme derived from equation (47) is written as Mxk+1 = Nxk + b (48)
We can now discuss the above-mentioned three classical schemes in this framework. 5.2.1 Jacobi Method In the Jacobi method, the set of equations comprising equation (7) are reordered, if necessary, in such a way that the diagonal elements of the coefficient matrix A are not zero and
M is taken as a diagonal matrix containing all the diagonal elements of A. Thus, if the matrix A is split into three matrices, namely, D, E, and F such that Dij Eij Fij = aij deltaij = -aij if I < j or 0 otherwise = -aij if I > j and 0 otherwise
(49)
and
then A can be written as A=D-E-F In the Jacobi method, M=D N = E+F resulting in the iteration scheme Dx= (E+F)x + b x = D-1(E+F) + D-1b = D-1(D-A) + D-1b x = (I-D-1A)x + D-1b (50)
(51)
or or
(52)
The implementation of the Jacobi scheme follows the iterative formula Dxk+1 = (E+F)xk + b (53) and, due to the diagonal form of D, is quite simple to solve. Denoting the iteration index k by a superscript, one iteration of the Jacobi scheme for the linear system given by equation (7) takes the following form: a11x1k+1 = -a12x2k a22x2k+1 = -a21x1k . . an-1n-1xn-1k+1= -an-1,ax1k -an-1,2x2k an,nxnj+1 = -an1x1k -an2x2k - a13x3k .-a1n-1xn-1k -a23x3k ..-a2n-1xn-1k -a1nxnk - b1 -a2nxnk - b2
(54) -an-1,3x3k .. -an-1,nxnk- bn-1 -an3x3k-an-1,nxn-1k - bn
Its convergence behaviour will be analyzed later in the section. 5.2.2 Gauss-Seidel Method In the Gauss-Seidel method, the matrices M and N of equation (46) are taken as
M = D-E
N=F
(55)
where D, E and F are given by equation (49) as above. The resulting iteration scheme is (D-E)x= Fx + b or x = (D-E)-1Fx + (D-E)-1b (56) The implementation of the Gauss-Seidel scheme follows the iterative formula (D-E)xk+1 = Fxk + b (57)
Although equation (57) appears to be more complicated than the corresponding Jacobi formula given by equation (53), it can be rearranged to give the following equally simple formula: Dxk+1 = Exk+1 + Fxk + b (58) which allows sequential evaluation of xi in a form very similar to that of the Jacobi method. Denoting the iteration index k by a superscript as before, one iteration of the Gauss-Seidel scheme for the linear system given by equation (7) takes the following form: a11x1k+1 = -a12x2k - a13x3k .-a1n-1xn-1k -a1nxnk - b1 a22x2k+1 = -a21x1k+1 -a23x3k ..-a2n-1xn-1k -a2nxnk - b2 . . (59) an-1n-1xn-1k+1= -an-1,ax1k+1 -an-1,2x2k+1 -an-1,3x3k+1 .. -an-1,nxnk- bn-1 an,nxnj+1 = -an1x1k+1 -an2x2k+1 -an3x3k+1-an-1,nxn-1k - bn 5.2.3 Successive Over-relaxation (SOR) Method The rate of convergence of either the Jacobi method or the Gauss-Seidel method can be changed by a simple technique known as relaxation in which the value of the variable at k+1th iteration is taken as xk+1 = xk + w*dxk (60) where dxk is the estimated improvement in xk, i.e. (xk+1 - xk) where xk+1 is the value estimated by Jacobi/Gauss-Seidel method using equation (54) or (59). If w <1, then equation (60) leads to under-relaxation and if w > 1, then to over-relaxation. It can be shown (Cliaret, 1989) that convergence is possible only for 0 < w < 2, and that too under certain other conditions. Underrelaxation is often used to solve non-linear algebraic equations where divergence is often a real possibility. In the context of solution of linear algebraic equations, over-relaxation is often used to improve the convergence rate resulting in the method known as successive over-relaxation (SOR). When applied to the Jacobi method, the splitting of the matrix A corresponds to
M = D/w N = (1-w)/w D + E + F resulting in the iteration scheme (D/w) x= [(1-w)/w D+ E+F]x + b x =(D/w)-1[(1-w)/wD + E+F]x + (D/w)-1b
(61)
or
(62)
Denoting the iteration index k by a superscript, one iteration of the Jacobi scheme with SOR for the linear system given by equation (7) takes the following form: a11x1k+1 a22x2k+1 . an,nxnj+1 = a11x1k - w{a11x1k + a12x2k + a13x3k + .+ a1nxnk - b1} = a22x2k - w{a21x1k + a22x2k + a23x3k +1.+a2nxnk - b2} (63) = annxnk - w{an1x1k +an2x2k + an3x3k + +annxnk - bn}
When SOR is applied to the Gauss-Seidel method, the splitting of the matrix A corresponds to M = D/w -E N = (1-w)/w D + F resulting in the iteration scheme (D/w-E) x= [(1-w)/w D+F]x + b x =(D/w-E)-1[(1-w)/wD +F]x + (D/w-E)-1b (64)
or
(65)
Denoting the iteration index k by a superscript, one iteration of the Gauss-Seidel scheme with SOR for the linear system given by equation (7) takes the following form: a11x1k+1 a22x2k+1 . an,nxnk+1 = a11x1k - w{a11x1k + a12x2k + a13x3k + .+ a1nxnk - b1} = a22x2k - w{a21x1k+1 + a22x2k + a23x3k +1.+a2nxnk - b2} (66) = annxnk - w{an1x1k+1 +an2x2k+1 + an3x3k+1 + +annxnk - bn}
It can be seen that the implementation of the successive over-relaxation technique requires little extra overhead in per-iteration work while significant speed-up of convergence rate (up to an order of magnitude) can be obtained with an optimum value of the relaxation parameter, wopt. However, as will be shown later, the optimum value is not known a priori in many cases and may have to be estimated on a trial and error basis in the initial stages of the computation. An essential difference between the Jacobi and the Gauss-Seidel methods lies in the order in which the values of xi are found using equations (54) and (59), respectively. In the Jacobi method, the order of the solution of equations (54) does not matter, and may be computed even
in parallel. Hence the Jacobi method is also known as simultaneous iteration method. In the Gauss-Seidel method, the evaluation of successive xi has to be done in a prescribed order due to the substitution of the latest values of known values and thus it is termed as successive iteration method. Thus, the term successive over-relaxation (SOR) method is usually applied in the context of a Gauss-Seidel SOR scheme (for example, see Cliarlet, 1989; Axelsson, 1994). 5.2.4 Block Iterative Methods The above iterative methods have been applied to the evaluation of xi, I = 1 to N, each of which is a scalar, corresponding to the value of a variable at a grid point. In such a case, the iterative schemes are called point methods, for example, point Jacobi method and point GaussSeidel method with SOR. These methods can be readily extended to the case when the coefficient matrix has a block structure such as the block tridiagonal structure given by equation (31). In this case, the matrix A can still be split into D, E and F each of which may consist of further sub-matrices. An example of such decomposition is shown in Figure [Link] (Fig. on p. 169 of Ciarlet). The Jacobi or Gauss-Seidel iterative schemes are then applicable according to this block decompostion. The corresponding iterative scheme is then called block-Jacobi or blockGauss-Seidel scheme. Consider the block-decomposition of the matrix A shown in Figure [Link] where the original n x n system of linear equations is decomposed into a 4 x 4 system of equations consisting of elements Apq. If this is split into matrices D, E, F, then D consists of the submatrices {A11, A22, A33, A44}, E consists of {A21, A31, A32, A41, A42, A43} and F of {A12, A13, A14, A23, A24, A34. A block-Gauss-Seidel method with SOR for this 4 x 4 system can be written readily as A11x1k+1 = A11x1k - w{A11x1k + A12x2k + A13x3k + A14x4k - b1} A22x2k+1 = A22x2k - w{A21x1k + A22x2k + A23x3k + A24x4k - b2} A33x3k+1 = A11x1k - w{A31x1k + A32x2k + A33x3k + A34x4k - b3} A44x4k+1 = A11x1k - w{A41x1k + A42x2k + A43x3k + A44x4k - b4}
(67)
where xi and bi themselves are vectors. Thus, each of the above four equations themselves represents a further set of linear equations to be solved either by direct or iterative methods. This kind of situation often arises in the coupled solution of Navier-Stokes equations, as will be discussed in the next chapter. 5.3 Convergence Analysis of the Classical Iterative Schemes It is often thought that the convergence of Jacobi and Gauss-Seidel schemes goes together, i.e., one converges if the other does and that the latter method converges twice as fast.
We dispel this notion by considering the following examples suggested by Ciarlet (1989). Consider, firstly, the set of three simultaneous linear algebraic equations given by x1 + 2x2 2x3 = -2 x1 + x2 + x3 = 6 2x1 + 2x2 + x3 = 9
(68)
It can be shown, using any direct method, that the correct solution is xi = {1,2,3}. The solution obtained using Jacobi and Gauss-Seidel schemes with an initial guess of xi = {0,0,0}is shown in Table 5.1. It can be seen that the Jacobi method converges quickly while the Gauss-Seidel method diverges rapidly. Similar results are obtained for other initial guesses. The convergence behaviour of the SOR scheme is summarized in Table 5.2 where the calculated values are shown for Jacobi with SOR and Gauss-Seidel with SOR for the SOR parameter values of w = 1.25, 1.5, 1.75 and 1.9. We can see that while the Gauss-Seidel method diverges rapidly in all the cases, the Jacobi method converges eventually in all cases although it goes through large negative and/ or positive values before converging in some cases. Also, increasing the value of the relaxation parameter appears to worsen the convergence behaviour. Consider now a second example: 2x1 x2 + x3 = 3 x1 + x2 +x3 = 6 x1 + x2 2x3 = -3
(69)
Again, it can be shown that the correct solution is xi = {1,2,3}. The solution obtained using the Jacobi and Gauss-Seidel schemes for this case is shown in Table 5.3 for an initial guess of xi = {0,0,0}. For this case, the Jacobi scheme diverges but the Gauss-Seidel scheme converges. The Jacobi with SOR is also found to diverge for this example. The Gauss-Seidel scheme with SOR exhibits a more complicated behaviour and the iteration values are summarized in Table 5.4 for relaxation parameter values of 0.75, 1.05, 1.10 and 1.14. The first value, corresponding to under-relaxation, appears to make the convergence faster while for the last value of 1.14, the scheme diverges. Thus, the convergence behaviour of these classical schemes can be more complicated than what appears to be the case. A necessary and sufficient condition (Axelsson, 1994) for convergence for an iterative scheme of the form given by equation (43) xk+1 = Pxk + q k>=0 (43) for non-singular algebriac equations given by equation (7) Ax = b (7) is that the spectral radius of the iteration matrix, P, is less than unity, i.e.,
rho(P) < 1 for convergence The spectral radius of a matrix P is the non-negative number defined by rho(P) = max {|lambdai|}, 1 <=I<=n where lambdai are the eigenvalues of the square matix Pn x n.
(70) (71)
For the system of equations in the first example (equation 68), the iteration matix for the Jacobi method is given by Pjacobi1 = (72)
The three eigenvalues of this matrix are la1, la2 and la3 and the spectral radius is therefore rho(Pjaboi1) = |la3| = < 1 (73)
showing that condition given by (71) is satisfied. Similarly, for the Gauss-Seidel scheme for the same example, the iteration matrix is given by PGS1 = (74)
the eigenvalues of which are la1, la2 and la3. The spectral radius for this matrix is therefore |la3| = la3 >1. Hence the Gauss-Seidel scheme diverged. The iteration matrix and the corresponding spectral radius for the other cases in examples 1 and 2 are listed in Table 5.5. It can be seen that, in all the cases, the condition that the spectral radius of the corresponding iteration matrix be less than unity is satisfied. Defining the error, e, in the solution of equation (44) as e = x~ - x (75) where x~ is the exact solution of (7), the error propagation from iteration to iteration can be written as ek+1 = Pek (76) Thus, at the end of m recursive applications, we have em = Pm e0 (77) where e0 is in the initial error vector. If the spectral radius of P < 1, then em->0 as m -> inf leading to a converged solution. The rate at which the error decreases is governed, for large m, by the largest eigenvalue of P, i.e., by its spectral radius. Thus, the average convergence factor (per step for m steps) depends on the spectral radius; the smaller the spectral radius, the larger the convergence factor and the faster the rate of convergence. The asymptotic rate of convergence is proportional to ln[rho(P)], i.e., asmptotically as n -> inf, the error decreases by a factor of e every 1/(-ln [rhoP]) number of iterations, or by one order (factor of ten) for every
2.3/(-ln[rhoP]) number of iterations. Consider the simple case of the Laplace equation in the square [0,a] x [0,a] in the x- and y-direction. If this square is divided into a uniform mesh of M x M subrectangles, then for a five-point Jacobi scheme, the eigenvalues of the iteration matrix are given by (see, for example, Hirsch, 1988) lambdaJac = 1- (sin2(lpi/2M) + sin^2(mpi/2M)]=1/2[cos(lpi/M)+cos(mpi/M)] (78)
where l and m correspond to the grid indices in the x- and y-directions, respectively, and take values from 1 to (M-1). The spectral radius of the Jacobi iteration matrix is given by the highest eigenvalue, that is, for l = m = 1 in equation (78) and is therefore rho(PJ) = cos (pi/M) (79)
For large M, the spectral radius of the Jacobi iteration matrix can be approximated as rho(PJ) 1- pi^2/2M^2 (80)
The asymptotic convergence rate for the Jacobi scheme for the Laplace equation with Dirichlet boundary conditions is (2M^2/pi^2) or 0.466N iterations to reduce the error by one order where N is the number of equations (Mx M) being solved simultaneously. Each equation of the Jacobi iteration requires 5 arithmetic operations, and thus the total number of arithmetic operations required to reduce error by four orders of magnitude for the Jacobi scheme is 9N^2. This compares favourably with an 1/3N3 variation for the Gaussian elimination scheme discussed earlier for large values of N. For the Gauss-Seidel method, it can be shown that the corresponding eigenvalues of the amplification matrix are equal to the square of the eigenvalues of the Jacobi method; thus, lambdaGS = 1/4[cos(lpi/M)+cos(mpi/M)]^2 (81)
Hence the spectral radius of the iteration matrix for the Gauss-Seidel method for the Laplace equation is given by rho(PGS) = cos^2 (pi/M) which can be approximated for large M as rho(PGS) 1- pi^2/M^2 (83) (82)
Thus, the Gauss-Seidel method converges twice as fast as the Jacobi method for this problem. For example, the total number of arithmetic operations required to reduce the error by four orders of magnitude will be 4.5N2. The above results of the relative convergence of the Jacobi and Gauss-Seidel methods for the Laplace (and Poisson) equation can be generalized to the case where the coefficient matrix A is symmetric and positive definite. It can be shown (Hirsch, 1988) that for such matrices, the SOR method would converge provided the overrelaxation factor satisfied the relation 0 < w < 2/ [1+ rho(P) ] (84)
where rho (P) is the spectral radius of the iteration matrix of the pure Jacobi or Gauss-Seidel method (i.e., without overrelaxation). The convergence rate for these methods will depend strongly on the overreelaxation factor and is greatly improved near the optimal relaxation factor, wopt, which corresponds to the minimum spectral radius of the iteration matrix. For the Jacobi method with SOR, the eigenvalues of the iteration matrix are related by lambda(PJSOR) = (1-w) + wlambda(PJ) (85)
where lambda(PJ) are the eigenvalues of the pure Jacobi iteration matrix. The optimum value of the overrelaxation parameter, w, for the JSOR method is given by wopt,JSOR = 2/[2-(lambdamin + lambdamax) (86)
where lambdamin and lambdamax are the minimum and the maximum values of the iteration matrix corresponding to the pure Jacobi method. For the specific case of the Laplace equation with Dirichlet boundary conditions, the minimum and maximum eigenvalues are given by lambdamax = -lambdamin = cos (pi/M) and the optimal relaxation occurs for w = 1 corresponding to the Jacobi method without SOR itself! For the point Gauss-Seidel method with SOR, the eigenvalues of the corresponding iteration matrix are related by lambdaGSSOR = 1-w + w* lambda(Pjac) * lambdaGSSOR^0.5 (87)
The optimal relaxation factor, when A is symmetric and positive definite, is given by
wopt, GSSOR = 2/[1-{1-rho^2(Pjaco)}^0.5] The spectral radius for the optimal relaxation factor is given by rho(GSSOR) = wopt 1
(88)
(89)
For the case of the Laplace equation with Dirichlet conditions, the spectral radius of the Jacobi iteration matrix is cos (pi/M) and hence wopt for the GSSOR method is given by wopt = 2/[1+ sin(pi/M)] 2(1-pi/M) Hence the spectral radius at optimum relaxation is given by rho(GSSOR) = 2(1-pi/M) 1 = 1- pi/M (90)
Comparing this with the corresponding expression (equation (83)) without SOR, we find that, for large M and in the asymptotic limit, the number of iterations required to reduce error by an order of magnitude varies as N^0.5 and that the total number of arithmetic operations required to reduce error by a decade varies as N^1.5, compared to N^2 variation for the pure GS method. This represents a considerably enhanced convergence rate for large values of N. It is interesting to note from equations (79), (82) and (90) that as the number of subdivisions (M) increases, the spectral radius approaches closer to unity and the convergence rate therefore decreases. Thus, for diffusion-dominated flows, convergence would be slower on finer grids and a larger number of iterations would be required to reduce the error by a given factor. The above discussion is applicable in the asymptotic limit of large number of iterations and for large number of subdivisions (large M). In the initial stages of computation, the residual reduction may typically follow one of the two idealized curves shown in Figure [Link] (Fig. 12.1.3 of Hirsch) depending on the spectrum of eigenvalues present in the iteration matrix and their damping characteristics. A residual history of the type of curve a may be expected if the iterative scheme damps rapidly the high frequency errors but damps poorly the low frequency errors. A response of the type of curve b may be obtained if the low frequency errors are damped rapidly. A detailed discussion of this eigenvalue analysis of an iterative method is presented in Hirsch (1988). Such detailed analysis of the properties of iterative schemes is possible for symmetric matrices. For unsymmetric matrices, the convergence behaviour is more complicated and a non-monotone convergence may be expected, and the interested reader is referred to Axelsson (1994) for more details.
The above results on the conditions for convergence and the rate of convergence expressed in terms of the spectral radius of the iteration matrix are not very useful in practice because of the large size of matrices involved, typically of the order of 104 x 104 or more. The evaluation of the eigenvalues and the spectral radius for such cases may not be practically feasible. The following more restrictive condition, but one which is readily implementable, is often used as a guide for the convergence behaviour of iterative schemes: A sufficient condition for covergence of an iterative scheme is that the matrix A (in equation 7) is irreducible and must have general diagonal dominance, i.e., |aii| >= sum I=/j (|aij|) for all I |aii| > sum I=/ j (|aij|) for at least on ei
(91)
Both these conditions, namely, irreducibility and diagonal dominance, require some clarification.. A reducible matrix does not require the simultaneous solution of all the equations; simultaneous solution of a reduced set of equations is possible. When this is not the case, the matrix A is said to be irreducible. Diagonal dominance of a matrix refers to the condition that |aii| > sum j=/I |aij| for all I (94)
A matrix which satisfies equation (94) is said to be strictly diagonally dominant. A matrix which satisfied the diagonal dominance condition for at least one row and satisfies the others with an equality sign, is said to be generally diagonally dominant. A matrix satisfying the irreducibility and the general diagonance condition is called irreducibly diagonally dominant matrix. It can be shown that (Ciarlet, 1989) that under such conditions, the spectral radius of the iteration matrices corresponding to the Jacobi and Gauss-Seidel methos is less than unity and that they converge for all initial vectors, x0. Also, the SOR method would converge for 0 < w < 2. Let us summarize the results that we have obtained in this section. For the basic iterative methods, namely, the Jacobi method and the Gauss-Seidel method, the number of airthmetic operations required to reduce the residual by k orders of magnitude varies as ~kN^2 where N is the number of equations being solved simultaneously. For the optimal SOR method, the number of arithmetic operations may vary as ~kN^1.5, constituting a significant improvement for large N. However, the convergence rate decreases rather sharply for non-optimal (especially suboptimal) values of the relaxation factor and, in a practical implementation of the iterative scheme, a search for an optimal value of w should be incorporated for large N while taking account of the disparity of variation of the residual in the initial stages of the computation
(Figure [Link]). The above results, which are valid for diffusion-dominated flows, compare very favourably with the best general purpose direct method for the solution of the same equation, namely, the Gaussian elimination method, which takes 1/3N^3 number of arithmetic operations for the solution (to machine accuracy). The basic iterative methods are much simpler, easier to program, require less storage and take advantage of the structure of the matrix. However, these advantages are gained at the cost of a significant curtailment of applicability. While the Gaussian elimination method (with pivoting) would work for any non-singular matrix, the basic iterative methods are limited to diagonally dominant matrices. Also, they compare significantly less favourably with the best general purpose direct method for a diagonally domaninat tridiagonal matrix, namely, the Thomas algorithm, for which the number of operations varies as ~ N. While SOR remains an effective means of enhancing the convergence rate of the basic methods, its efficacy is reduced for non-optimal values and may not work at all in some cases, as shown in Table 5.x (GS with w= 1.14). A number of methods and strategies have been developed to arrive at improving the convergence behaviour of the iterative methods. Some of these are discussed below. 5.3 Advanced Iterative Methods A number of iterative methods have been devised to improve the convergence behaviour of the basic iterative schemes. These take the form of (i) improving the sensitivity of the SOR method to the choice of w, e.g., Chebyshev iterative methods; (ii) taking advantage of the efficient Thomas algorithm for tridiagonal matrices, e.g., ADI methods; (iii) providing a betterconditioned splitting of the matrix A into M and N, e.g., strongly implicit methods; and (iv) taking advantage of the error smoothening properties of some iterative methods, e.g., multigrid methods.
You might also like
- Vdoc - Pub Generalized Vectorization Cross Products and Matrix CalculusNo ratings yetVdoc - Pub Generalized Vectorization Cross Products and Matrix Calculus279 pages
- Aeroelastic Divergence Methods in MSC.NastranNo ratings yetAeroelastic Divergence Methods in MSC.Nastran7 pages
- Dynamics of Particles and Rigid Bodies Anil Rao Kindle & PDF FormatsNo ratings yetDynamics of Particles and Rigid Bodies Anil Rao Kindle & PDF Formats503 pages
- Linear Algebra For Computational Engineering0% (1)Linear Algebra For Computational Engineering21 pages
- Householder's Method For Approximating Eigenvalues: Azhi Sabir Mohammed & Rebwar Mohammed WSWNo ratings yetHouseholder's Method For Approximating Eigenvalues: Azhi Sabir Mohammed & Rebwar Mohammed WSW69 pages
- Primitive Roots and Discrete LogarithmsNo ratings yetPrimitive Roots and Discrete Logarithms16 pages
- Matrix Algebra: Operations and InversesNo ratings yetMatrix Algebra: Operations and Inverses89 pages
- Math 6610 - Analysis of Numerical Methods INo ratings yetMath 6610 - Analysis of Numerical Methods I103 pages
- Fourier Series of Even and Odd FunctionsNo ratings yetFourier Series of Even and Odd Functions5 pages
- Quaternion Equations and Quaternion Polynomial MatricesNo ratings yetQuaternion Equations and Quaternion Polynomial Matrices130 pages
- 5 L L EC533: Digital Signal Processing: DFT and FFTNo ratings yet5 L L EC533: Digital Signal Processing: DFT and FFT20 pages
- Dilations of Irreversible Evolutions in Algebraic Quantum Theory100% (2)Dilations of Irreversible Evolutions in Algebraic Quantum Theory81 pages
- Understanding Complex Numbers and OperationsNo ratings yetUnderstanding Complex Numbers and Operations42 pages
- Understanding Eigenvalues and Eigenvectors100% (1)Understanding Eigenvalues and Eigenvectors10 pages
- Math 2331 - Linear Algebra: 1.9 The Matrix of A Linear TransformationNo ratings yetMath 2331 - Linear Algebra: 1.9 The Matrix of A Linear Transformation9 pages
- CS229 Autumn 2012 Problem Set 1 SolutionsNo ratings yetCS229 Autumn 2012 Problem Set 1 Solutions16 pages
- B-Spline Surface Fitting by Iterative Geometric Interpolation Approximation AlgorithmsNo ratings yetB-Spline Surface Fitting by Iterative Geometric Interpolation Approximation Algorithms12 pages
- Wilkinson-Reinsch1971 Book HandbookForAutomaticComputatioNo ratings yetWilkinson-Reinsch1971 Book HandbookForAutomaticComputatio450 pages
- Periodic Solutions of Differential EquationsNo ratings yetPeriodic Solutions of Differential Equations8 pages
- Finite Difference & Volume Methods for DiffusionNo ratings yetFinite Difference & Volume Methods for Diffusion25 pages
- 2D Elliptic PDE Finite Difference MethodsNo ratings yet2D Elliptic PDE Finite Difference Methods18 pages
- Poisson Equation Solver Comparison in Matlab and OctaveNo ratings yetPoisson Equation Solver Comparison in Matlab and Octave18 pages
- MIT Numerical Fluid Mechanics Problem SetNo ratings yetMIT Numerical Fluid Mechanics Problem Set5 pages
- Discretization Methods ("Numerical Heat Transfer and Fluid Flow" by Suhas V. Patankar)No ratings yetDiscretization Methods ("Numerical Heat Transfer and Fluid Flow" by Suhas V. Patankar)4 pages
- TEQIP Teaching Assistantship RecommendationsNo ratings yetTEQIP Teaching Assistantship Recommendations1 page
- Body Donation An Act of Love Supporting Anatomy EducationNo ratings yetBody Donation An Act of Love Supporting Anatomy Education7 pages
- Intro to Information & Communication TechNo ratings yetIntro to Information & Communication Tech6 pages
- Universal Design For Learning (UDL) in Teaching 21st Century LiteratureNo ratings yetUniversal Design For Learning (UDL) in Teaching 21st Century Literature8 pages
- GSC400 Series: Automatic Gen-Set Controller Manual100% (1)GSC400 Series: Automatic Gen-Set Controller Manual105 pages
- Class 150 & 300 Ball Valve SpecificationsNo ratings yetClass 150 & 300 Ball Valve Specifications1 page
- JPM Guide To The Markets Europe 1704580390aNo ratings yetJPM Guide To The Markets Europe 1704580390a98 pages
- Science and Design of Engineering Materials 2nd Edition-1 PDF96% (24)Science and Design of Engineering Materials 2nd Edition-1 PDF844 pages
- Environment and Competitiveness RedefinedNo ratings yetEnvironment and Competitiveness Redefined23 pages
- Challenges and Opportunities in Ethiopia's Manufacturing Sector100% (1)Challenges and Opportunities in Ethiopia's Manufacturing Sector7 pages