You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- API Dev GuideDocument94 pagesAPI Dev GuideMel CooperNo ratings yet
- Principles of Information Security Chapter 1Document58 pagesPrinciples of Information Security Chapter 1Brian100% (1)
- AIT 614 Summer 08 Final Exam - CompleatedDocument5 pagesAIT 614 Summer 08 Final Exam - Compleatedjocansino4496No ratings yet
- CMD Command Tips for LAN HackingDocument7 pagesCMD Command Tips for LAN HackingChasiful AnwarNo ratings yet
- RFC 1560Document9 pagesRFC 1560NickyNETNo ratings yet
- RFC 1559Document71 pagesRFC 1559NickyNETNo ratings yet
- RFC 1553Document25 pagesRFC 1553NickyNETNo ratings yet
- RFC 1550Document8 pagesRFC 1550NickyNETNo ratings yet
- RFC 1556Document5 pagesRFC 1556NickyNETNo ratings yet
- RFC 1548Document55 pagesRFC 1548NickyNETNo ratings yet
- RFC 1555Document7 pagesRFC 1555NickyNETNo ratings yet
- RFC 1557Document11 pagesRFC 1557NickyNETNo ratings yet
- RFC 1558Document5 pagesRFC 1558NickyNETNo ratings yet
- RFC 1554Document8 pagesRFC 1554NickyNETNo ratings yet
- RFC 1551Document24 pagesRFC 1551NickyNETNo ratings yet
- RFC 1552Document18 pagesRFC 1552NickyNETNo ratings yet
- RFC 1547Document23 pagesRFC 1547NickyNETNo ratings yet
- RFC 1549Document20 pagesRFC 1549NickyNETNo ratings yet
- RFC 1544Document5 pagesRFC 1544NickyNETNo ratings yet
- RFC 1546Document11 pagesRFC 1546NickyNETNo ratings yet
- RFC 1543Document18 pagesRFC 1543NickyNETNo ratings yet
- RFC 1545Document7 pagesRFC 1545NickyNETNo ratings yet
- RFC 1542Document25 pagesRFC 1542NickyNETNo ratings yet
- Network Working Group Request For Comments: 1541 Obsoletes: 1531 CategoryDocument39 pagesNetwork Working Group Request For Comments: 1541 Obsoletes: 1531 CategorystrideworldNo ratings yet
- RFC 1537Document11 pagesRFC 1537NickyNETNo ratings yet
- RFC 1540Document36 pagesRFC 1540NickyNETNo ratings yet
- RFC 1533Document32 pagesRFC 1533NickyNETNo ratings yet
- RFC 1539Document24 pagesRFC 1539NickyNETNo ratings yet
- RFC 1536Document14 pagesRFC 1536NickyNETNo ratings yet
- RFC 1531Document39 pagesRFC 1531Shiva prasadNo ratings yet
- RFC 1538Document12 pagesRFC 1538NickyNETNo ratings yet
- RFC 1535Document7 pagesRFC 1535NickyNETNo ratings yet
- RFC 1534Document6 pagesRFC 1534NickyNETNo ratings yet
- RFC 1532Document24 pagesRFC 1532NickyNETNo ratings yet
- Garmin Fleet Management Dev GuideDocument58 pagesGarmin Fleet Management Dev GuideAnonymous 23CEh9jUNo ratings yet
- AOS-CX VSF Best PracticesDocument14 pagesAOS-CX VSF Best PracticesstillNo ratings yet
- Database Management Systems (DBMS) OverviewDocument17 pagesDatabase Management Systems (DBMS) OverviewPraveen KumarNo ratings yet
- Print Basic Text in PythonDocument113 pagesPrint Basic Text in PythonAnkur SinghNo ratings yet
- Virtual Axis Monitoring MotionDocument4 pagesVirtual Axis Monitoring MotionbhageshlNo ratings yet
- Modifying Data in TablesDocument35 pagesModifying Data in TablesLuis Gonzalez AlarconNo ratings yet
- Understanding Computer ArchitectureDocument55 pagesUnderstanding Computer ArchitectureWei-Lun HuangNo ratings yet
- Reporting Issues With VB 6Document4 pagesReporting Issues With VB 6vinycioNo ratings yet
- OpenMP API Specification 5.0Document666 pagesOpenMP API Specification 5.0Marius BlueEyesNo ratings yet
- Theory of Computation Guidelines and Practical List - TutorialsDuniyaDocument2 pagesTheory of Computation Guidelines and Practical List - TutorialsDuniyaPapaNo ratings yet
- SAP Business One For HANA On The AWS Cloud PDFDocument35 pagesSAP Business One For HANA On The AWS Cloud PDFMiguelNo ratings yet
- File HandlingDocument5 pagesFile HandlingMisha JinsNo ratings yet
- Using Poka-Yoke Techniques For Early Defect DetectionDocument22 pagesUsing Poka-Yoke Techniques For Early Defect DetectionAngela CastilloNo ratings yet
- Microsoft Azure Infographic 2014 PDFDocument1 pageMicrosoft Azure Infographic 2014 PDFkiranNo ratings yet
- Yexcel Upload IN ABAPDocument2 pagesYexcel Upload IN ABAPSomnathChoudhuryNo ratings yet
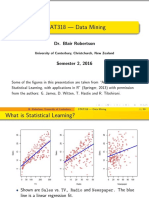
- STAT318 - Data Mining: Dr. Blair RobertsonDocument39 pagesSTAT318 - Data Mining: Dr. Blair RobertsonCesilyNo ratings yet
- Data Structures and Algorithms: (CS210/ESO207/ESO211)Document12 pagesData Structures and Algorithms: (CS210/ESO207/ESO211)Moazzam HussainNo ratings yet
- A Note On Goldberg and Rao Algorithm For The Maximum Flow ProblemDocument9 pagesA Note On Goldberg and Rao Algorithm For The Maximum Flow ProblemthangmleNo ratings yet
- 642 902Document169 pages642 902MD.JAVEDNo ratings yet
- Index 1. Two. Three. April. MayDocument18 pagesIndex 1. Two. Three. April. MayMabu DbaNo ratings yet
- Csit127 SeminarDocument12 pagesCsit127 SeminarZahra HossainiNo ratings yet
- PCI Express BasicsDocument34 pagesPCI Express Basicsteo2005100% (1)
- ADP Updating Methods (Text Only)Document2 pagesADP Updating Methods (Text Only)Keittikun PhairinNo ratings yet
- Advanced Dimensional ModelingDocument19 pagesAdvanced Dimensional ModelingjerinconNo ratings yet
- Esp32 Datasheet enDocument43 pagesEsp32 Datasheet enRenato HernandezNo ratings yet
- Fifo RTL CodeDocument5 pagesFifo RTL CodePranav ToorNo ratings yet