You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- CT3041 UK Hoofdstuk 7 PDFDocument24 pagesCT3041 UK Hoofdstuk 7 PDFEmily DiazNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- 111 Math Midterm PDFDocument59 pages111 Math Midterm PDFalamin018No ratings yet
- HW6 ResultsDocument9 pagesHW6 Resultsalamin018No ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Reducing Greenhouse Gas Emissions Through Strategic Management of Highway Pavement RoughnessDocument11 pagesReducing Greenhouse Gas Emissions Through Strategic Management of Highway Pavement Roughnessalamin018No ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Homework7 SolutionsDocument2 pagesHomework7 Solutionsalamin018No ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Weather Wax Bertsimas Solutions ManualDocument20 pagesWeather Wax Bertsimas Solutions Manualchencont0% (8)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Air PollutionDocument12 pagesAir Pollutionalamin018No ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Project 1 - Academic Schedule-GoalsDocument3 pagesProject 1 - Academic Schedule-Goalsalamin018No ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
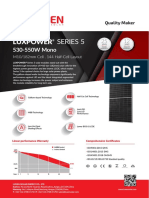
- LUXEN SERIES 5 182 144cells 530-550w MONOFACIALDocument2 pagesLUXEN SERIES 5 182 144cells 530-550w MONOFACIALOscar DuduNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- UM - HX204 - EN User ManualDocument32 pagesUM - HX204 - EN User Manuals7631040No ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Basics of Electric Heat Trace TechnologyDocument8 pagesThe Basics of Electric Heat Trace Technologyvladimir rosas ayalaNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Anchor Lliberty Mpa ManDocument8 pagesAnchor Lliberty Mpa ManIgnacio Barriga NúñezNo ratings yet
- 12 MarksDocument23 pages12 Markslakshmigsr6610No ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- RLC-circuits With Cobra4 Xpert-Link: (Item No.: P2440664)Document14 pagesRLC-circuits With Cobra4 Xpert-Link: (Item No.: P2440664)fatjonmusli2016100% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Service Manual - Amnc09gdba2, Amnc12gdba2Document6 pagesService Manual - Amnc09gdba2, Amnc12gdba2U Kyaw San OoNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Mechanics of Solids by Crandall, Dahl, Lardner, 2nd ChapterDocument118 pagesMechanics of Solids by Crandall, Dahl, Lardner, 2nd Chapterpurijatin100% (2)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- 049 Hadoop Commands Reference Guide.Document3 pages049 Hadoop Commands Reference Guide.vaasu1No ratings yet
- Information Data and ProcessingDocument10 pagesInformation Data and ProcessingarshdeepsinghdhingraNo ratings yet
- Test For CarbohydratesDocument15 pagesTest For CarbohydratesKevin SangNo ratings yet
- Random Sampling - QuizizzDocument7 pagesRandom Sampling - Quizizzmacjoven101No ratings yet
- 12 One Way Ribbed Slab-SlightDocument18 pages12 One Way Ribbed Slab-Slightريام الموسوي100% (1)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Celonis Configuration Store Setup Guide 1.6Document11 pagesCelonis Configuration Store Setup Guide 1.6Venugopal JujhavarappuNo ratings yet
- The Sacred Number Forty-NineDocument12 pagesThe Sacred Number Forty-NinePatrick Mulcahy100% (6)
- Horizontal Vessel Support: Vertical Saddle ReactionsDocument12 pagesHorizontal Vessel Support: Vertical Saddle ReactionsSanket BhaleraoNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- EVADTS - 6-1 - 04 June 2009Document232 pagesEVADTS - 6-1 - 04 June 2009Carlos TejedaNo ratings yet
- Example 6 1 Rectangular Water Tank DesignDocument7 pagesExample 6 1 Rectangular Water Tank DesignMesfin Derbew88% (104)
- 3681 113533 1 SM - , mutasiCVKaroseriLaksanaDocument14 pages3681 113533 1 SM - , mutasiCVKaroseriLaksanataufiq hidayatNo ratings yet
- SWT 2 3 101 Brochure.Document8 pagesSWT 2 3 101 Brochure.Uhrin ImreNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Design Constraint ReportDocument11 pagesDesign Constraint ReportCam MillerNo ratings yet
- Lecture 4 Maps Data Entry Part 1Document80 pagesLecture 4 Maps Data Entry Part 1arifNo ratings yet
- Ic Assignment 2Document1 pageIc Assignment 2Nilven GastardoNo ratings yet
- Weld Map & NDE Extent of Pressure VesselDocument32 pagesWeld Map & NDE Extent of Pressure VesselMahesh Kumar100% (2)
- Explaining OPERCOM® Methodology in CommissioningDocument5 pagesExplaining OPERCOM® Methodology in Commissioningiman2222100% (2)
- EAPA Paper - Asphalt Pavements On Bridge Decks - 2013Document33 pagesEAPA Paper - Asphalt Pavements On Bridge Decks - 2013prdojeeNo ratings yet
- Ing. Ccallo Cusi, Ruben German - Analisis Estructural 2Document63 pagesIng. Ccallo Cusi, Ruben German - Analisis Estructural 2educacion universitarioNo ratings yet
- Reading A Film - Problem of Denotation in Fiction FilmDocument0 pagesReading A Film - Problem of Denotation in Fiction FilmragatasuryaNo ratings yet
- INA131 Burr-BrownCorporationDocument10 pagesINA131 Burr-BrownCorporationMartha H.TNo ratings yet
- Geomechanics & ERDDocument18 pagesGeomechanics & ERDRene Torres HinojosaNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)