You might also like
- Computer NetworksDocument25 pagesComputer Networksanjali srivastavaNo ratings yet
- Possible Algorithms of 2NF and 3NF For DBNorma - A Tool For Relational Database NormalizationDocument7 pagesPossible Algorithms of 2NF and 3NF For DBNorma - A Tool For Relational Database NormalizationIDESNo ratings yet
- Assignment No:-2: Object Oriented Analysis & DesignDocument15 pagesAssignment No:-2: Object Oriented Analysis & DesignAnkur SinghNo ratings yet
- Data Redundancy Risk To Data Integrity Data Isolation Difficult Access To Data Unsatisfactory Security Measure Concurrent AccessDocument80 pagesData Redundancy Risk To Data Integrity Data Isolation Difficult Access To Data Unsatisfactory Security Measure Concurrent Accessjack430No ratings yet
- Query Optimization and Execution Plan Generation in Object-Oriented Data Management SystemsDocument51 pagesQuery Optimization and Execution Plan Generation in Object-Oriented Data Management SystemsBangun WijayantoNo ratings yet
- NLP For Automated Conceptual Data Modeling: Suraj A. Jogdand, Mr. Pramod B. MaliDocument8 pagesNLP For Automated Conceptual Data Modeling: Suraj A. Jogdand, Mr. Pramod B. MaliIOSRjournalNo ratings yet
- Data Structures and Algorithms (Csc-221) : Instructor: Engr. Naveera SamiDocument28 pagesData Structures and Algorithms (Csc-221) : Instructor: Engr. Naveera SamiMuhammad BilalNo ratings yet
- Word Processor Data STRDocument29 pagesWord Processor Data STRArpit TyagiNo ratings yet
- Chapter 2. Database ConceptsDocument29 pagesChapter 2. Database ConceptsMikaellacalubayan DelmoNo ratings yet
- 03 Text EditorDocument91 pages03 Text EditorglobalhodmechNo ratings yet
- What Is Data StructureDocument2 pagesWhat Is Data StructureTila D-ShaNo ratings yet
- Summer Training ReportDocument7 pagesSummer Training Reportali3800No ratings yet
- Chapter 3Document28 pagesChapter 3Gemechis GurmesaNo ratings yet
- Oraculum, A System For Complex Linguistic Queries: (S.ljubo - S.nemec - S.pilat - S.reschke - S.stuchl) @ufal - Mff.cuni - CZDocument8 pagesOraculum, A System For Complex Linguistic Queries: (S.ljubo - S.nemec - S.pilat - S.reschke - S.stuchl) @ufal - Mff.cuni - CZMario GuzmanNo ratings yet
- Chain IndexingDocument15 pagesChain IndexingMadhu YadavNo ratings yet
- Ans Key CIA 2 Set 1Document9 pagesAns Key CIA 2 Set 1kyahogatera45No ratings yet
- CH 11Document12 pagesCH 11Ramesh KumarNo ratings yet
- Journal of Asian Scientific Research 2 (11) :773-781Document9 pagesJournal of Asian Scientific Research 2 (11) :773-781HASHIM MALHINo ratings yet
- Data ModelDocument5 pagesData ModelSyed MoizuddinNo ratings yet
- Infosys Technical Interview QuestionsDocument11 pagesInfosys Technical Interview QuestionsRajeev SinghNo ratings yet
- Unit 1: How Many Levels Are There in Architecture of DBMSDocument11 pagesUnit 1: How Many Levels Are There in Architecture of DBMSSonu KumarNo ratings yet
- TCS QuestionsDocument5 pagesTCS QuestionsFann KannNo ratings yet
- An Object-Oriented Finite-Element Program For Electromagnetic Field ComputationDocument4 pagesAn Object-Oriented Finite-Element Program For Electromagnetic Field ComputationPranav LadkatNo ratings yet
- Solutio 1Document32 pagesSolutio 1Savi PatilNo ratings yet
- The Nested Relational Data Model Is Not A Good IdeaDocument10 pagesThe Nested Relational Data Model Is Not A Good IdeaArun arunNo ratings yet
- 432 - Kishankumar Goud - SEDocument31 pages432 - Kishankumar Goud - SEKajal GoudNo ratings yet
- Anurag: Ajay Himanshu Mayank PrabhatDocument32 pagesAnurag: Ajay Himanshu Mayank PrabhatPrabhat SinghNo ratings yet
- 18CST41 - DBMS Cat 1 Answer KeyDocument12 pages18CST41 - DBMS Cat 1 Answer Key20CSR064 Natchattira T SNo ratings yet
- Orm PDFDocument30 pagesOrm PDFAsad AliNo ratings yet
- Dbms (r20) Unit - 3 (Part - 1)Document17 pagesDbms (r20) Unit - 3 (Part - 1)MOHANKRISHNACHAITANYA KNo ratings yet
- DBMS (R20) Unit - 3Document67 pagesDBMS (R20) Unit - 3RONGALI CHANDININo ratings yet
- Grammatical Approach To Problem SolvingDocument6 pagesGrammatical Approach To Problem SolvingAnirudh AgarwallaNo ratings yet
- Analyzing Relationships ClassesDocument7 pagesAnalyzing Relationships ClassesAndrej ArbanasNo ratings yet
- A Three Stage Hybrid Parser For Hindi: Sanjay Chatterji, Arnab Dhar, Sudeshna Sarkar, Anupam BasuDocument8 pagesA Three Stage Hybrid Parser For Hindi: Sanjay Chatterji, Arnab Dhar, Sudeshna Sarkar, Anupam Basumusic2850No ratings yet
- Natural Language Processing Parsing Techniques:: Unit IVDocument24 pagesNatural Language Processing Parsing Techniques:: Unit IVThumbiko Mkandawire100% (1)
- Software Architecture and Design Documentation TemplateDocument7 pagesSoftware Architecture and Design Documentation TemplategirumNo ratings yet
- Null 1Document6 pagesNull 1ajaydanish012No ratings yet
- What Is Data StructureDocument20 pagesWhat Is Data StructuregauravujjawalNo ratings yet
- Answers To Review QuestionsDocument46 pagesAnswers To Review QuestionsKimverlie Abastar0% (1)
- Modeling Componnet Level Design (2) - STUDENTDocument25 pagesModeling Componnet Level Design (2) - STUDENTBuncy MaddalaNo ratings yet
- Briefly Explain The Characteristics of Reference-Type Variables That Are Supported in The C# Programming LanguageDocument7 pagesBriefly Explain The Characteristics of Reference-Type Variables That Are Supported in The C# Programming LanguagemaanicapriconNo ratings yet
- DATABASE Answers To Review QuestionsDocument46 pagesDATABASE Answers To Review QuestionsAmirah Husna Abu0% (1)
- Third Year Sixth Semester CS6660 Compiler Design Two Mark With AnswerDocument11 pagesThird Year Sixth Semester CS6660 Compiler Design Two Mark With AnswerPRIYA RAJI100% (1)
- Decompiling CODASYL DML Into Relational QueriesDocument23 pagesDecompiling CODASYL DML Into Relational QueriesSpod SpoddyNo ratings yet
- AssignmentdatabaseDocument54 pagesAssignmentdatabaseer testNo ratings yet
- Automatic Text Summarization Using: Hybrid Fuzzy GA-GPDocument7 pagesAutomatic Text Summarization Using: Hybrid Fuzzy GA-GPSona AgarwalNo ratings yet
- Access Path Selection in A Relational Dbms - SelingerDocument12 pagesAccess Path Selection in A Relational Dbms - SelingerPanos KoukiosNo ratings yet
- ADBMS Chapter OneDocument21 pagesADBMS Chapter OneNaomi AmareNo ratings yet
- Intreview QuestionsDocument19 pagesIntreview Questionsuttkarsh singhNo ratings yet
- MC0073-System Programming-Fall-10Document12 pagesMC0073-System Programming-Fall-10Sayantan InduNo ratings yet
- Management SystemDocument37 pagesManagement SystemJonbert AndamNo ratings yet
- Explanetion For OOAD DiagramsDocument7 pagesExplanetion For OOAD Diagramsmsccs2nd2024No ratings yet
- Object-Oriented Programming With Class Dictionaries: Karl J. Lieberherr, Northeastern University April 27, 2004Document33 pagesObject-Oriented Programming With Class Dictionaries: Karl J. Lieberherr, Northeastern University April 27, 2004sathiyanitNo ratings yet
- Answers To Review QuestionsDocument46 pagesAnswers To Review QuestionsSreejith KarunakaranpillaiNo ratings yet
- An Object-Oriented Type and Effect System: Aivar Annamaa December 14th, 2011Document11 pagesAn Object-Oriented Type and Effect System: Aivar Annamaa December 14th, 2011aivarannamaaNo ratings yet
- Case Studies in GOF Structural Patterns: Case Studies in Software Architecture & Design, #3From EverandCase Studies in GOF Structural Patterns: Case Studies in Software Architecture & Design, #3No ratings yet
- Magic Data: Part 1 - Harnessing the Power of Algorithms and StructuresFrom EverandMagic Data: Part 1 - Harnessing the Power of Algorithms and StructuresNo ratings yet
- An Efficient User Privacy and Protecting Location Content in Location Based ServiceDocument4 pagesAn Efficient User Privacy and Protecting Location Content in Location Based ServiceInternational Journal of Research in Science & TechnologyNo ratings yet
- Performance Evaluation of Computationally Efficient Energy Detection Based Spectrum Sensing For Cognitive Radio NetworksDocument6 pagesPerformance Evaluation of Computationally Efficient Energy Detection Based Spectrum Sensing For Cognitive Radio NetworksInternational Journal of Research in Science & TechnologyNo ratings yet
- DTC Scheme For A Four-Switch Inverter-Fed PMBLDC Motor Emulating The Six-Switch Inverter OperationDocument6 pagesDTC Scheme For A Four-Switch Inverter-Fed PMBLDC Motor Emulating The Six-Switch Inverter OperationInternational Journal of Research in Science & TechnologyNo ratings yet
- Internet of Things - OverviewDocument5 pagesInternet of Things - OverviewInternational Journal of Research in Science & TechnologyNo ratings yet
- Support Vector Machine For Wind Speed PredictionDocument7 pagesSupport Vector Machine For Wind Speed PredictionInternational Journal of Research in Science & TechnologyNo ratings yet
- A Novel Approach For Interference Suppression Using A Improved LMS Based Adaptive Beam Forming AlgorithmDocument10 pagesA Novel Approach For Interference Suppression Using A Improved LMS Based Adaptive Beam Forming AlgorithmInternational Journal of Research in Science & TechnologyNo ratings yet
- Integration of Unified Power Quality Controller With DGDocument6 pagesIntegration of Unified Power Quality Controller With DGInternational Journal of Research in Science & TechnologyNo ratings yet
- A Particle Swarm Optimization For Optimal Reactive Power DispatchDocument9 pagesA Particle Swarm Optimization For Optimal Reactive Power DispatchInternational Journal of Research in Science & TechnologyNo ratings yet
- Reduction of Frequency Offset Using Joint Clock For OFDM Based Cellular Systems Over Generalized Fading ChannelsDocument7 pagesReduction of Frequency Offset Using Joint Clock For OFDM Based Cellular Systems Over Generalized Fading ChannelsInternational Journal of Research in Science & TechnologyNo ratings yet
- Neutron Stars - Unique Compact Objects of Their OwnDocument5 pagesNeutron Stars - Unique Compact Objects of Their OwnInternational Journal of Research in Science & TechnologyNo ratings yet
- Improving The Signal Quality of Multistream Data Transmission in 4G ServicesDocument4 pagesImproving The Signal Quality of Multistream Data Transmission in 4G ServicesInternational Journal of Research in Science & TechnologyNo ratings yet
- Line Integration of Bidirectional Inverter With Buck Boost For MicrogridDocument4 pagesLine Integration of Bidirectional Inverter With Buck Boost For MicrogridInternational Journal of Research in Science & TechnologyNo ratings yet
- Analysis of Voltage and Current Variations in Hybrid Power SystemDocument6 pagesAnalysis of Voltage and Current Variations in Hybrid Power SystemInternational Journal of Research in Science & TechnologyNo ratings yet
- IJRST02A Study On The Local Property of Indexed Summability of A Factored Fourier Series0304Document6 pagesIJRST02A Study On The Local Property of Indexed Summability of A Factored Fourier Series0304International Journal of Research in Science & TechnologyNo ratings yet
- IJRST02A Study On The Local Property of Indexed Summability of A Factored Fourier Series0304Document6 pagesIJRST02A Study On The Local Property of Indexed Summability of A Factored Fourier Series0304International Journal of Research in Science & TechnologyNo ratings yet
- Neutron Stars - Unique Compact Objects of Their OwnDocument5 pagesNeutron Stars - Unique Compact Objects of Their OwnInternational Journal of Research in Science & TechnologyNo ratings yet
- Detection of DNA Damage Using Comet Assay Image AnalysisDocument5 pagesDetection of DNA Damage Using Comet Assay Image AnalysisInternational Journal of Research in Science & TechnologyNo ratings yet
- Review of Low Voltage Ride Through Methods in PMSGDocument4 pagesReview of Low Voltage Ride Through Methods in PMSGInternational Journal of Research in Science & TechnologyNo ratings yet
- Implementation of Windowing Technique For Minimizing The Side Lobes in Antenna Array DesignDocument5 pagesImplementation of Windowing Technique For Minimizing The Side Lobes in Antenna Array DesignInternational Journal of Research in Science & TechnologyNo ratings yet
- Reactive Power Compensation in Distribution Network With Slide Mode MPPT Control For PV SystemDocument5 pagesReactive Power Compensation in Distribution Network With Slide Mode MPPT Control For PV SystemInternational Journal of Research in Science & TechnologyNo ratings yet
- A Compact Remote Switching With Efficient Monitoring For AC PlantsDocument4 pagesA Compact Remote Switching With Efficient Monitoring For AC PlantsInternational Journal of Research in Science & TechnologyNo ratings yet
- Review of Step Down Converter With Efficient ZVS OperationDocument4 pagesReview of Step Down Converter With Efficient ZVS OperationInternational Journal of Research in Science & TechnologyNo ratings yet
- Power Quality Improvement by UPQC Based On Voltage Source ConvertersDocument6 pagesPower Quality Improvement by UPQC Based On Voltage Source ConvertersInternational Journal of Research in Science & TechnologyNo ratings yet
- Experimental Investigation On Hybrid Steel Fiber Reinforced Concrete Beam - Column Joints Under Cyclic LoadingDocument6 pagesExperimental Investigation On Hybrid Steel Fiber Reinforced Concrete Beam - Column Joints Under Cyclic LoadingInternational Journal of Research in Science & TechnologyNo ratings yet
- Performance Evaluation and Cost Analysis of Selected Shielded Manual Metal Arc Welding (SMMAW) Steel ElectrodesDocument6 pagesPerformance Evaluation and Cost Analysis of Selected Shielded Manual Metal Arc Welding (SMMAW) Steel ElectrodesInternational Journal of Research in Science & TechnologyNo ratings yet
- Experimental Studies On Retrofitting of RCC Beams Using GFRPDocument8 pagesExperimental Studies On Retrofitting of RCC Beams Using GFRPInternational Journal of Research in Science & TechnologyNo ratings yet
- A Study of SEPIC Converter Based Fuzzy Logic Controller For Hybrid SystemDocument7 pagesA Study of SEPIC Converter Based Fuzzy Logic Controller For Hybrid SystemInternational Journal of Research in Science & TechnologyNo ratings yet
- Review of Reduction of Leakage Current in Cascaded Multilevel InverterDocument4 pagesReview of Reduction of Leakage Current in Cascaded Multilevel InverterInternational Journal of Research in Science & Technology0% (1)
- Dynamic Stability of SMIB System With Fuzzy Logic Based Power System StabilizerDocument6 pagesDynamic Stability of SMIB System With Fuzzy Logic Based Power System StabilizerInternational Journal of Research in Science & TechnologyNo ratings yet
- Integration of Litho-Units Derived From Satellite DataDocument5 pagesIntegration of Litho-Units Derived From Satellite DataInternational Journal of Research in Science & TechnologyNo ratings yet
- Children Literature Evaluation Form I Aint Gonna Paint No MoreDocument4 pagesChildren Literature Evaluation Form I Aint Gonna Paint No Moreapi-548506674No ratings yet
- Test Bank For Organizations Behavior Structure Processes 14th Edition James GibsonDocument36 pagesTest Bank For Organizations Behavior Structure Processes 14th Edition James Gibsonfurrygrindlett3t1bt100% (37)
- Tikkun Kisay HaShemDocument47 pagesTikkun Kisay HaShemYochananMauritzHummasti100% (1)
- UNIABROAD PitchdeckDocument21 pagesUNIABROAD PitchdeckVikas MurulidharaNo ratings yet
- Case Presentation On Management of Depressive Disorders-1Document40 pagesCase Presentation On Management of Depressive Disorders-1Fatima MuhammadNo ratings yet
- Visibility of NursesDocument17 pagesVisibility of NursesLuke ShantiNo ratings yet
- Tahmina Ferdousy Jhumu: HND Btec Unit 15 Psychology For Health and Social CareDocument29 pagesTahmina Ferdousy Jhumu: HND Btec Unit 15 Psychology For Health and Social CareNabi BoxNo ratings yet
- Research Propsal v1.2Document3 pagesResearch Propsal v1.2john7904No ratings yet
- Final Exam Tle Grade 8Document4 pagesFinal Exam Tle Grade 8John leo Claus67% (3)
- SAP Group Reporting 1909Document28 pagesSAP Group Reporting 1909SUDIPTADATTARAY86% (7)
- Expt Lipid - Influence of Bile in The Action of LipaseDocument3 pagesExpt Lipid - Influence of Bile in The Action of LipaseAngela CaguitlaNo ratings yet
- Reading Comprehension Pre TestDocument7 pagesReading Comprehension Pre TestMimimiyuhNo ratings yet
- Om06 JulyaugDocument44 pagesOm06 JulyaugengineeringyusufNo ratings yet
- LinuxSocials RoadmapDocument12 pagesLinuxSocials RoadmapShrutiNo ratings yet
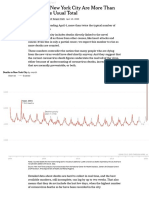
- Deaths in New York City Are More Than Double The Usual TotalDocument3 pagesDeaths in New York City Are More Than Double The Usual TotalRamón RuizNo ratings yet
- Pke - End Sleeves - Cembre (1) - AKBAR TRADING EST - SAUDI ARABIADocument2 pagesPke - End Sleeves - Cembre (1) - AKBAR TRADING EST - SAUDI ARABIAGIBUNo ratings yet
- Dokumen - Tips Dm3220-Servicemanual PDFDocument62 pagesDokumen - Tips Dm3220-Servicemanual PDFwalidsayed1No ratings yet
- Armenotech PCIDSS AOCDocument13 pagesArmenotech PCIDSS AOCHakob ArakelyanNo ratings yet
- Boot Time Memory ManagementDocument22 pagesBoot Time Memory Managementblack jamNo ratings yet
- Chapter 2 The Development of Evolutionary TheoryDocument5 pagesChapter 2 The Development of Evolutionary TheoryjohnNo ratings yet
- Lecture - 1 - UNDERGROUND MINE DESIGNDocument59 pagesLecture - 1 - UNDERGROUND MINE DESIGNRahat fahimNo ratings yet
- Chemistry For Engineers - Week 4 and 5 - Chemical BondDocument162 pagesChemistry For Engineers - Week 4 and 5 - Chemical BondHồng NhungNo ratings yet
- Dunhill The Old WindmillDocument2 pagesDunhill The Old WindmillMaría Hernández MiraveteNo ratings yet
- Portal 2 PresDocument15 pagesPortal 2 Presapi-666608332No ratings yet
- Impacts of Extracurricular Activities On The Academic Performance of Student AthletesDocument3 pagesImpacts of Extracurricular Activities On The Academic Performance of Student AthletesKarlo VillanuevaNo ratings yet
- Alup Allegro 37 AC IE3 400V 4-13bar 50Hz Metric Technical Data ENDocument2 pagesAlup Allegro 37 AC IE3 400V 4-13bar 50Hz Metric Technical Data ENBosznay ZoltánNo ratings yet
- Tata Steel LTD.: Elements Unit Min Max RemarksDocument2 pagesTata Steel LTD.: Elements Unit Min Max RemarksPavan KumarNo ratings yet
- Kuka Interbus InterfaceDocument11 pagesKuka Interbus InterfaceAnonymous Zh6p3ENo ratings yet
- MikroC PRO For DsPIC30Document9 pagesMikroC PRO For DsPIC30ivcal20No ratings yet
- Ath9k and Ath9k - HTC DebuggingDocument4 pagesAth9k and Ath9k - HTC DebuggingHam Radio HSMMNo ratings yet