You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5819)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Transient Considerations of Flat-Plate Solar CollectorsDocument5 pagesTransient Considerations of Flat-Plate Solar CollectorsmangouarNo ratings yet
- ICPMS Reading MaterialDocument40 pagesICPMS Reading MaterialHimanshiNo ratings yet
- Sharp Is A Pioneer in Photovoltaics Sharp Solar Modules Have Set Standards For Over 50 YearsDocument2 pagesSharp Is A Pioneer in Photovoltaics Sharp Solar Modules Have Set Standards For Over 50 YearshaerulamriNo ratings yet
- Composite Buckling in Ansys ApdlDocument61 pagesComposite Buckling in Ansys ApdlSantosh Mukthenahalli100% (1)
- PVC Bladed Wind TurbineDocument12 pagesPVC Bladed Wind Turbineainer navalNo ratings yet
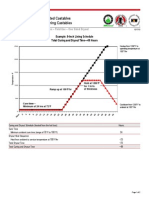
- Anh Schedule 2 Plus Rated CastablesDocument2 pagesAnh Schedule 2 Plus Rated CastablesEfren CandoNo ratings yet
- IEC 62271 - EN - 2003-10-27 - HandoutDocument18 pagesIEC 62271 - EN - 2003-10-27 - HandoutFarhan ShahNo ratings yet
- Kay Maker Tekin 2001Document7 pagesKay Maker Tekin 2001Ineke AuliaNo ratings yet
- ME401 Engine BasicsDocument4 pagesME401 Engine BasicsAdnan Shahariar AnikNo ratings yet
- Asphalt Paper DSRDocument4 pagesAsphalt Paper DSRyazqaNo ratings yet
- Atomic StuctureDocument26 pagesAtomic StucturefatzyNo ratings yet
- Validation Manual Telemac-2d v6p1Document188 pagesValidation Manual Telemac-2d v6p1Milenko TulencicNo ratings yet
- Notes From RCC Pillai MenonDocument71 pagesNotes From RCC Pillai MenonVaibhav SharmaNo ratings yet
- Spectrochemical Trace Analysis FOR Metals and Metalloids: Wilson & Wilson's Comprehensive Analytical ChemistryDocument13 pagesSpectrochemical Trace Analysis FOR Metals and Metalloids: Wilson & Wilson's Comprehensive Analytical ChemistryPedroLHernandezNo ratings yet
- 10 Boundary Layer Drag Lift Physical Model Tutorial SolutionDocument20 pages10 Boundary Layer Drag Lift Physical Model Tutorial SolutionVenkitaraj K PNo ratings yet
- Centrifugal Pump 1 18 1 78Document28 pagesCentrifugal Pump 1 18 1 78yacine35160% (1)
- ST202 - Stochastic ProcessesDocument5 pagesST202 - Stochastic ProcessesRebecca RumseyNo ratings yet
- 07 Flexibility Toolbox VGB Final Web PDFDocument76 pages07 Flexibility Toolbox VGB Final Web PDFAnonymous KzJcjGCJbNo ratings yet
- Manual Software NEPLAN 2Document106 pagesManual Software NEPLAN 2Thomas Reed100% (1)
- Stress Analysis On Rail Wheel ContactDocument6 pagesStress Analysis On Rail Wheel ContactVISHAL KUMARNo ratings yet
- Sec4 6 PDFDocument2 pagesSec4 6 PDFpolistaNo ratings yet
- Learning Activity Sheet On Properties of LightDocument3 pagesLearning Activity Sheet On Properties of LightResttie ĐaguioNo ratings yet
- Departure FunctionDocument6 pagesDeparture FunctionzidinhoNo ratings yet
- Journal of The European Ceramic Society: Vincenzo Buscaglia, Clive A. Randall TDocument15 pagesJournal of The European Ceramic Society: Vincenzo Buscaglia, Clive A. Randall TAryan Singh LatherNo ratings yet
- DSC4821 2022 Assignment 04 Solutions PDFDocument11 pagesDSC4821 2022 Assignment 04 Solutions PDFKeshi AngelNo ratings yet
- Shape Memory AlloyDocument20 pagesShape Memory AlloyChandra Sekhar CNo ratings yet
- Indira College of Engineering and Management: Lesson PlanDocument2 pagesIndira College of Engineering and Management: Lesson PlanHarold WilsonNo ratings yet
- Thesis ListingDocument8 pagesThesis ListingLawrence LingNo ratings yet
- Major and Active Fault Lines Found in The PhilippinesDocument18 pagesMajor and Active Fault Lines Found in The PhilippinesbotchNo ratings yet