You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- CTI Technical Manual PDFDocument40 pagesCTI Technical Manual PDFYashveer Takoory100% (4)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Pathfinder's Solutions OverviewDocument18 pagesPathfinder's Solutions OverviewbiswasjpNo ratings yet
- WORKBOAT EMERGENCY RESPONSE FLOWCHARTDocument1 pageWORKBOAT EMERGENCY RESPONSE FLOWCHARTKunal SinghNo ratings yet
- ICT101 Lecture 1 IntroductionDocument42 pagesICT101 Lecture 1 IntroductionOguntoye Yusuf100% (2)
- Study United Kingdom PostgraduateDocument2 pagesStudy United Kingdom PostgraduateJohn JohnNo ratings yet
- Vega-Lite View Specification: Documentation OverviewDocument6 pagesVega-Lite View Specification: Documentation OverviewJohn JohnNo ratings yet
- Intermod Product TablesDocument2 pagesIntermod Product TablesJohn JohnNo ratings yet
- Physics GCSE CourseDocument2 pagesPhysics GCSE CourseJohn JohnNo ratings yet
- Stephen HawkingDocument3 pagesStephen HawkingJohn JohnNo ratings yet
- Course GeoDocument4 pagesCourse GeoJohn JohnNo ratings yet
- AbstractDocument1 pageAbstractJohn JohnNo ratings yet
- EquipmentDocument25 pagesEquipmentJohn JohnNo ratings yet
- 3050 Set 01Document19 pages3050 Set 01John JohnNo ratings yet
- RXV630RDSDocument68 pagesRXV630RDSJohn JohnNo ratings yet
- EpsDocument4 pagesEpsJohn JohnNo ratings yet
- Numerical Constants and Electrical PropertiesDocument23 pagesNumerical Constants and Electrical PropertiesJohn JohnNo ratings yet
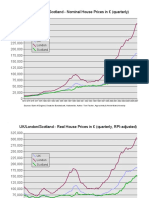
- UK/London/Scotland - Nominal House Prices in (Quarterly)Document5 pagesUK/London/Scotland - Nominal House Prices in (Quarterly)John JohnNo ratings yet
- The Best Way Forward I Can See Is Some Superficial Leadership Figurehead Transition That Leaves The Ba'athist Core in Place, Says Prof. Paul KingstonDocument2 pagesThe Best Way Forward I Can See Is Some Superficial Leadership Figurehead Transition That Leaves The Ba'athist Core in Place, Says Prof. Paul KingstonJohn JohnNo ratings yet
- Car Allowance CalcDocument2 pagesCar Allowance CalcJohn JohnNo ratings yet
- Whats in The News TodayDocument6 pagesWhats in The News TodayJohn JohnNo ratings yet
- Presentation On Antimatter CollisionsDocument2 pagesPresentation On Antimatter CollisionsJohn JohnNo ratings yet
- Fixed vs Variable Lending Rates Over TimeDocument3 pagesFixed vs Variable Lending Rates Over TimeJohn JohnNo ratings yet
- T&Cs To Be Aware ofDocument2 pagesT&Cs To Be Aware ofJohn JohnNo ratings yet
- Analysis F Noise Switched MOSFETDocument7 pagesAnalysis F Noise Switched MOSFETJohn JohnNo ratings yet
- Technical terms in frequency distributionsDocument5 pagesTechnical terms in frequency distributionsRhoseNo ratings yet
- Iec 61439Document3 pagesIec 61439Chithra Babu0% (3)
- DBT416 Amigo ReportDocument32 pagesDBT416 Amigo ReportArjareeNo ratings yet
- Everything You Need to Know About BitcoinDocument24 pagesEverything You Need to Know About BitcoinApuede Ikhianosimhe DanielNo ratings yet
- Software Development ProcessDocument33 pagesSoftware Development ProcessCaseNo ratings yet
- Quickstart Guide of OpenVox GSM Gateway VS-GW1600-20G Connect With 3CX Server PDFDocument6 pagesQuickstart Guide of OpenVox GSM Gateway VS-GW1600-20G Connect With 3CX Server PDFJeandelaSagesse100% (1)
- Deployment StepsDocument3 pagesDeployment StepsAnonymous tLUfHHEONo ratings yet
- Big Data AnalyticsDocument85 pagesBig Data AnalyticsFaiq Ghawash100% (1)
- Consecutive Calculations!: Consecutive Numbers Follow One After Another, E.G. 5, 6, 7Document12 pagesConsecutive Calculations!: Consecutive Numbers Follow One After Another, E.G. 5, 6, 7Nikki Mayor-OngNo ratings yet
- Dell Unity - Additional Procedures-SVC CommandsDocument10 pagesDell Unity - Additional Procedures-SVC CommandsArman ShaikhNo ratings yet
- Makex Brochure MainDocument12 pagesMakex Brochure MainAtharv BalujaNo ratings yet
- Etas Etk-S4.2 Emulator Probe For Infineon Tricore Tc17Xx: User GuideDocument93 pagesEtas Etk-S4.2 Emulator Probe For Infineon Tricore Tc17Xx: User GuideAmine HerbacheNo ratings yet
- Mechanical BIM Engineer ResumeDocument24 pagesMechanical BIM Engineer ResumerameshNo ratings yet
- Social Media Brings Good Than HarmDocument2 pagesSocial Media Brings Good Than HarmSophia Micaella HermosoNo ratings yet
- 962 TRAMONTINA (2)Document2 pages962 TRAMONTINA (2)pramod.yadavNo ratings yet
- Turbo Code Encoder Structure and PerformanceDocument6 pagesTurbo Code Encoder Structure and PerformancematildaNo ratings yet
- Delft3D-Installation - Manual ADocument50 pagesDelft3D-Installation - Manual Aagus suryadiNo ratings yet
- AVS Security Requirements-V1 - 2Document2 pagesAVS Security Requirements-V1 - 2Sigma PigsNo ratings yet
- Presentation On Transistors: Presented byDocument19 pagesPresentation On Transistors: Presented byMonith ElyonNo ratings yet
- Schedule LecturesDocument1 pageSchedule LecturesIsmael LidayNo ratings yet
- Chapter 2 Lexical AnalysisDocument26 pagesChapter 2 Lexical AnalysisElias HirpasaNo ratings yet
- Nems Lock Server InstallationDocument27 pagesNems Lock Server InstallationbathcolNo ratings yet
- Patent Search & Analysis Report (PSAR)Document4 pagesPatent Search & Analysis Report (PSAR)Neel PatelNo ratings yet
- Pierce Theory CommunicationDocument19 pagesPierce Theory CommunicationditurreguiNo ratings yet
- Please Sign DocuSign Tandem Diabetes CareDocument64 pagesPlease Sign DocuSign Tandem Diabetes CareMyah SandovalNo ratings yet
- CV Yaumil FirdausDocument3 pagesCV Yaumil FirdausYaumil FirdausNo ratings yet