You might also like
- Information Theory: 1 Random Variables and Probabilities XDocument8 pagesInformation Theory: 1 Random Variables and Probabilities XShashi SumanNo ratings yet
- Lecture 7: Convergence and Limit TheoremsDocument23 pagesLecture 7: Convergence and Limit TheoremsNurfitri AnbarsantiNo ratings yet
- Random VariablesDocument44 pagesRandom VariablesOtAkU 101No ratings yet
- Assign 5 1Document2 pagesAssign 5 1chataniket04No ratings yet
- CH 4-Exponentialandcentrallimit UploadedDocument10 pagesCH 4-Exponentialandcentrallimit UploadedAlexis MasonNo ratings yet
- Central Limit Theorem: Scott SheffieldDocument17 pagesCentral Limit Theorem: Scott SheffieldzahiruddinNo ratings yet
- Discrete Distributions: Bernoulli Random VariableDocument27 pagesDiscrete Distributions: Bernoulli Random VariableThapelo SebolaiNo ratings yet
- Tutorial 9 QNDocument2 pagesTutorial 9 QNanon_5970959290% (1)
- Chap3 PDFDocument33 pagesChap3 PDFJeanneth Tatiana GuamanNo ratings yet
- Exercises - Probability - C6Document1 pageExercises - Probability - C6ahmed.mozammel.samiNo ratings yet
- CH (3) Part 2Document38 pagesCH (3) Part 2digiy40095No ratings yet
- Lec05 RegressionasymptoticsDocument34 pagesLec05 RegressionasymptoticsAmbie MchereNo ratings yet
- All TutorialsDocument246 pagesAll TutorialsAngad SinghNo ratings yet
- 2.3 Expectation of Random VariablesDocument3 pages2.3 Expectation of Random VariablesThales mathNo ratings yet
- Binomial DistributionDocument15 pagesBinomial Distribution20-CMB-01 Mudasir ShabirNo ratings yet
- Probability S2010Document2 pagesProbability S2010acebagginsNo ratings yet
- Unit 2 Ma 202Document13 pagesUnit 2 Ma 202shubham raj laxmiNo ratings yet
- Introduction To Random Variables: Godfried ToussaintDocument19 pagesIntroduction To Random Variables: Godfried ToussaintchilledkarthikNo ratings yet
- MIT6 436JF08 Rec10Document5 pagesMIT6 436JF08 Rec10jarod_kyleNo ratings yet
- Random Variables: - Definition of Random VariableDocument29 pagesRandom Variables: - Definition of Random Variabletomk2220No ratings yet
- R300 Solution Guide 2018MDocument8 pagesR300 Solution Guide 2018MMarco BrolliNo ratings yet
- ECS315 2014 Postmidterm U1 PDFDocument89 pagesECS315 2014 Postmidterm U1 PDFArima AckermanNo ratings yet
- Unit-14 IGNOU STATISTICSDocument13 pagesUnit-14 IGNOU STATISTICSCarbidemanNo ratings yet
- Types of Random VariablesDocument9 pagesTypes of Random VariablesPutri Rania AzzahraNo ratings yet
- Monte Carlo Integration: Discrete ProbabilityDocument15 pagesMonte Carlo Integration: Discrete ProbabilityLionel LimNo ratings yet
- Lesson4 MAT284 PDFDocument36 pagesLesson4 MAT284 PDFMayankJain100% (1)
- Class 4Document9 pagesClass 4Smruti RanjanNo ratings yet
- Chapter 3Document47 pagesChapter 3Eva ChungNo ratings yet
- PS VDocument3 pagesPS VAmazing cricket shocksNo ratings yet
- Lecture 4 - Fall 2023Document29 pagesLecture 4 - Fall 2023tarunya724No ratings yet
- M. ThompsonDocument12 pagesM. Thompsonnsobrenome73No ratings yet
- Binomial Random Variables and Repeated Trials: Scott SheffieldDocument61 pagesBinomial Random Variables and Repeated Trials: Scott SheffieldEd ZNo ratings yet
- Stat 110 Strategic Practice 4, Fall 2011Document16 pagesStat 110 Strategic Practice 4, Fall 2011nxp HeNo ratings yet
- ProbdDocument49 pagesProbdapi-3756871No ratings yet
- Linear Al Alys Is 2022Document41 pagesLinear Al Alys Is 2022Angelo OppioNo ratings yet
- ISI MStat 05Document4 pagesISI MStat 05api-26401608No ratings yet
- Random Variables and Probability DistributionsDocument45 pagesRandom Variables and Probability DistributionsChidvi ReddyNo ratings yet
- HW7 Probability 1Document1 pageHW7 Probability 1nothardNo ratings yet
- Continuous RvsDocument34 pagesContinuous RvsArchiev KumarNo ratings yet
- Lesson3 ProbdistnsDocument52 pagesLesson3 ProbdistnsJohn Lloyd PabroaNo ratings yet
- Continuous DistributionDocument16 pagesContinuous DistributionShahariar KabirNo ratings yet
- Lec 03Document45 pagesLec 03John MaoNo ratings yet
- STAT0009 Introductory NotesDocument4 pagesSTAT0009 Introductory NotesMusa AsadNo ratings yet
- Unit V Probability DistributionsDocument52 pagesUnit V Probability DistributionsabcdNo ratings yet
- Probability Theory Lecture Notes PDFDocument25 pagesProbability Theory Lecture Notes PDF너굴No ratings yet
- LinearAlalysis2024 (More Complete Version)Document43 pagesLinearAlalysis2024 (More Complete Version)Pak Kin LauNo ratings yet
- Lecture Two (2)Document13 pagesLecture Two (2)Costantine Andrew Jr.No ratings yet
- Probability, Statistics and Reliability: (Module 2)Document16 pagesProbability, Statistics and Reliability: (Module 2)Anshika MishraNo ratings yet
- Singular Homology: 1 Introduction: Singular Simplices and ChainsDocument5 pagesSingular Homology: 1 Introduction: Singular Simplices and ChainsArindam BandyopadhyayNo ratings yet
- 2 Discrete Random Variables: 2.1 Probability Mass FunctionDocument12 pages2 Discrete Random Variables: 2.1 Probability Mass FunctionAdry GenialdiNo ratings yet
- AI Tut Sheet 1Document9 pagesAI Tut Sheet 1Sudesh KansraNo ratings yet
- Probability Distributions FinalDocument23 pagesProbability Distributions FinalTushar Gautam100% (1)
- Dis - Struc - ITEC 205 - L9Document23 pagesDis - Struc - ITEC 205 - L9percival fernandezNo ratings yet
- Topic 6: Convergence and Limit Theorems: ES150 - Harvard SEAS 1Document6 pagesTopic 6: Convergence and Limit Theorems: ES150 - Harvard SEAS 1RadhikanairNo ratings yet
- 10.0 Lesson Plan: Answer Questions Robust Estimators Maximum Likelihood EstimatorsDocument15 pages10.0 Lesson Plan: Answer Questions Robust Estimators Maximum Likelihood EstimatorsKhushboo GambhirNo ratings yet
- Foss Lecture4Document12 pagesFoss Lecture4Jarsen21No ratings yet
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- File 0097 PDFDocument1 pageFile 0097 PDFEd ZNo ratings yet
- File 0099 PDFDocument1 pageFile 0099 PDFEd ZNo ratings yet
- File 0094 PDFDocument1 pageFile 0094 PDFEd ZNo ratings yet
- File 0077 PDFDocument1 pageFile 0077 PDFEd ZNo ratings yet
- File 0096 PDFDocument1 pageFile 0096 PDFEd ZNo ratings yet
- File 0081 PDFDocument1 pageFile 0081 PDFEd ZNo ratings yet
- 4.2 Cross-Country Evidence On Trade Policies, Trade Volumes, Productivity, and GrowthDocument1 page4.2 Cross-Country Evidence On Trade Policies, Trade Volumes, Productivity, and GrowthEd ZNo ratings yet
- File 0091 PDFDocument1 pageFile 0091 PDFEd ZNo ratings yet
- File 0095 PDFDocument1 pageFile 0095 PDFEd ZNo ratings yet
- File 0098 PDFDocument1 pageFile 0098 PDFEd ZNo ratings yet
- File 0079 PDFDocument1 pageFile 0079 PDFEd ZNo ratings yet
- File 0092 PDFDocument1 pageFile 0092 PDFEd ZNo ratings yet
- File 0100 PDFDocument1 pageFile 0100 PDFEd ZNo ratings yet
- File 0078 PDFDocument1 pageFile 0078 PDFEd ZNo ratings yet
- File 0088 PDFDocument1 pageFile 0088 PDFEd ZNo ratings yet
- Ann Harrison and Andrés Rodríguez-ClareDocument1 pageAnn Harrison and Andrés Rodríguez-ClareEd ZNo ratings yet
- File 0087 PDFDocument1 pageFile 0087 PDFEd ZNo ratings yet
- File 0090 PDFDocument1 pageFile 0090 PDFEd ZNo ratings yet
- File 0083 PDFDocument1 pageFile 0083 PDFEd ZNo ratings yet
- File 0073 PDFDocument1 pageFile 0073 PDFEd ZNo ratings yet
- File 0067 PDFDocument1 pageFile 0067 PDFEd ZNo ratings yet
- File 0061 PDFDocument1 pageFile 0061 PDFEd ZNo ratings yet
- File 0076 PDFDocument1 pageFile 0076 PDFEd ZNo ratings yet
- File 0069 PDFDocument1 pageFile 0069 PDFEd ZNo ratings yet
- File 0063 PDFDocument1 pageFile 0063 PDFEd ZNo ratings yet
- File 0075 PDFDocument1 pageFile 0075 PDFEd ZNo ratings yet
- File 0070 PDFDocument1 pageFile 0070 PDFEd ZNo ratings yet
- File 0068 PDFDocument1 pageFile 0068 PDFEd ZNo ratings yet
- File 0072 PDFDocument1 pageFile 0072 PDFEd ZNo ratings yet
- File 0065 PDFDocument1 pageFile 0065 PDFEd ZNo ratings yet
- Annual Product Quality ReviewDocument3 pagesAnnual Product Quality ReviewPharmacist100% (1)
- 02 Template For Collection and Analysis of Road Accident Data-160119Document14 pages02 Template For Collection and Analysis of Road Accident Data-160119B Darshan G CV026No ratings yet
- Lab 1 Experimental ErrorsDocument7 pagesLab 1 Experimental ErrorsAaron Gruenert100% (1)
- 4.6 Validation of The PASAT in ArgentinaDocument6 pages4.6 Validation of The PASAT in ArgentinaEvelyn RoldanNo ratings yet
- Project Scheduling - Probabilistic PERTDocument23 pagesProject Scheduling - Probabilistic PERTSanjana GaneshNo ratings yet
- Basic Control RulesDocument39 pagesBasic Control RulesMary Joy GaloloNo ratings yet
- Supply Chain Management Assignment #2: Case: Sport ObermeyerDocument4 pagesSupply Chain Management Assignment #2: Case: Sport ObermeyerSHREYASI SAHANo ratings yet
- SQM Notes Unit IIDocument25 pagesSQM Notes Unit IIannamyemNo ratings yet
- Data Analysis and Graphs RubricDocument3 pagesData Analysis and Graphs RubricbbmsscienceNo ratings yet
- Empirical RuleDocument25 pagesEmpirical RuleJash Antoneth TimbangNo ratings yet
- Let's Be Rational: J Ac06 Vog07Document12 pagesLet's Be Rational: J Ac06 Vog07dheeraj8rNo ratings yet
- 01 FM&I Chap 7 Part 2 Stock MKTDocument89 pages01 FM&I Chap 7 Part 2 Stock MKTHoàng Lan AnhNo ratings yet
- Stat QP 2017Document31 pagesStat QP 2017AnithaNo ratings yet
- Chapter 3 Numerical Descriptive MeasuresDocument65 pagesChapter 3 Numerical Descriptive MeasuresKhouloud bn16No ratings yet
- Normal Approximation To The BinomialDocument3 pagesNormal Approximation To The BinomialGwen Bess N. CacanindinNo ratings yet
- N Mean (x) yn Sn std. Deviation σ: Year Maximum flood discharge (m3/sec)Document4 pagesN Mean (x) yn Sn std. Deviation σ: Year Maximum flood discharge (m3/sec)SUDHIR GAYAKENo ratings yet
- Financial Risk ManagementDocument21 pagesFinancial Risk ManagementLianne Esco100% (4)
- Assignment02 Sec17 No Submission-1Document2 pagesAssignment02 Sec17 No Submission-1Rokibul HasanNo ratings yet
- Effect of Pile Yarn Type On Absorbency, Stiffness, and Abrasion Resistance of Bamboo/Cotton and Cotton Terry Towels Filiz SekerdenDocument7 pagesEffect of Pile Yarn Type On Absorbency, Stiffness, and Abrasion Resistance of Bamboo/Cotton and Cotton Terry Towels Filiz SekerdenSubramani PichandiNo ratings yet
- RTEP222Document68 pagesRTEP222Bernard OwusuNo ratings yet
- Business Statistics in Practice 8th Edition Bowerman Solutions Manual 1Document26 pagesBusiness Statistics in Practice 8th Edition Bowerman Solutions Manual 1raymond100% (40)
- Building A Climate For Innovation Through Transformational Leadership and Organizational CultureDocument15 pagesBuilding A Climate For Innovation Through Transformational Leadership and Organizational Cultureiflash3dNo ratings yet
- Assignment 2 (2024)Document3 pagesAssignment 2 (2024)younes.louafiiizNo ratings yet
- Test Bank For Investment Analysis and Portfolio Management 11th by ReillyDocument15 pagesTest Bank For Investment Analysis and Portfolio Management 11th by Reillydieurobertp6cufvNo ratings yet
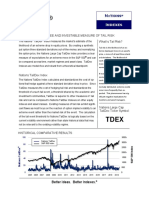
- Nations TailDex Tail Risk IndexesDocument2 pagesNations TailDex Tail Risk IndexesEmanuele QuagliaNo ratings yet
- LAS4 - STATS - 2nd SemDocument8 pagesLAS4 - STATS - 2nd SemLala dela Cruz - FetizananNo ratings yet
- State Practice ACI 317Document8 pagesState Practice ACI 317josebolis50% (2)
- Small Craft Weigth PredictionDocument12 pagesSmall Craft Weigth PredictionFederico Babich100% (1)
- Performance Level ResultsDocument2 pagesPerformance Level ResultsSarrah May S. MendivelNo ratings yet
- Engineering Data SolutionsDocument8 pagesEngineering Data Solutionsppp2010No ratings yet