You might also like
- Mark Vie Controller: Standard Block LibraryDocument287 pagesMark Vie Controller: Standard Block LibraryImad BouchaourNo ratings yet
- Kilobyte Magazine 2019-2Document42 pagesKilobyte Magazine 2019-2Charles Uchôa100% (2)
- Seismic Manual Using ETABSDocument27 pagesSeismic Manual Using ETABSKiranNo ratings yet
- Lavaan Multilevel Zurich2017Document162 pagesLavaan Multilevel Zurich2017henk-912871100% (1)
- DL Full MergedDocument454 pagesDL Full MergedMann chhikaraNo ratings yet
- En1992 ManualDocument80 pagesEn1992 ManualLuana PamelaNo ratings yet
- Large Scale Deep LearningDocument170 pagesLarge Scale Deep Learningpavancreative81No ratings yet
- DTMF GenDocument22 pagesDTMF GenMohammad R AssafNo ratings yet
- Time Series Prediction With Recurrent Neural NetworksDocument7 pagesTime Series Prediction With Recurrent Neural Networksghoshayan1003No ratings yet
- Multilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksFrom EverandMultilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksNo ratings yet
- Introduction To Artificial Neural NetworkDocument42 pagesIntroduction To Artificial Neural NetworkRezaBachtiar100% (1)
- AI - Physics Informed Neural Network by ARNAB HALDERDocument15 pagesAI - Physics Informed Neural Network by ARNAB HALDERARNAB HALDERNo ratings yet
- Applications of Intelligent Hybrid Systems in MatlabDocument13 pagesApplications of Intelligent Hybrid Systems in MatlabayeniNo ratings yet
- 6COM1044 Deep Learning 1Document49 pages6COM1044 Deep Learning 1Amir Mohamed Nabil Saleh ElghameryNo ratings yet
- 6.2 Gradient BasedLearningDocument56 pages6.2 Gradient BasedLearningCharuNo ratings yet
- Management Decision-Making Based On Fuzzy Neural NetworkDocument3 pagesManagement Decision-Making Based On Fuzzy Neural NetworkMario Alcides CaloNo ratings yet
- Chapter 9 - ANNsDocument25 pagesChapter 9 - ANNsd4rx5wsrw5No ratings yet
- What Is Neural Network Technology?Document17 pagesWhat Is Neural Network Technology?Mészáros BalázsNo ratings yet
- Pseudo Label FinalDocument6 pagesPseudo Label FinaljustinthecoachNo ratings yet
- Chapter 9: Supervised Learning Neural NetworksDocument20 pagesChapter 9: Supervised Learning Neural NetworksCharles UchôaNo ratings yet
- Unit 03 - Neural Networks - MDDocument24 pagesUnit 03 - Neural Networks - MDMega Silvia HasugianNo ratings yet
- UE20EC352-Machine Learning & Applications Unit 3 - Non Parametric Supervised LearningDocument117 pagesUE20EC352-Machine Learning & Applications Unit 3 - Non Parametric Supervised LearningSai Satya Krishna PathuriNo ratings yet
- So Far : Lecture 1: Review of Classical & Modern Control Lecture 2: MATLAB LectureDocument12 pagesSo Far : Lecture 1: Review of Classical & Modern Control Lecture 2: MATLAB LectureShivan BiradarNo ratings yet
- Machine Learning: Lecture 4: Artificial Neural Networks (Based On Chapter 4 of Mitchell T.., Machine Learning, 1997)Document14 pagesMachine Learning: Lecture 4: Artificial Neural Networks (Based On Chapter 4 of Mitchell T.., Machine Learning, 1997)harutyunNo ratings yet
- CS536: Machine Learning Artificial Neural NetworksDocument32 pagesCS536: Machine Learning Artificial Neural NetworksAnand SNo ratings yet
- Mod 2.1,2.2Document24 pagesMod 2.1,2.2Christeena AntonyNo ratings yet
- Unit X - Final Review - 1 Per PageDocument30 pagesUnit X - Final Review - 1 Per PageKase1No ratings yet
- Machine Learning: Lecture 4: Artificial Neural Networks (Based On Chapter 4 of Mitchell T.., Machine Learning, 1997)Document14 pagesMachine Learning: Lecture 4: Artificial Neural Networks (Based On Chapter 4 of Mitchell T.., Machine Learning, 1997)dollsicecreamNo ratings yet
- Noriega - Ponce Et Al - 2004 - Redes Neuronales para Control AutosontonizableDocument4 pagesNoriega - Ponce Et Al - 2004 - Redes Neuronales para Control AutosontonizableJesus Cano MoralesNo ratings yet
- Module - 5 - ECE3047 - Machine LearningDocument52 pagesModule - 5 - ECE3047 - Machine LearningUtkarsh MauryaNo ratings yet
- Artificial Neural Networks - : IntroductionDocument19 pagesArtificial Neural Networks - : IntroductionJOYNo ratings yet
- Fuzzy Methods in Expert Systems For Configuration and Control (Models, Implementations and Experiences)Document3 pagesFuzzy Methods in Expert Systems For Configuration and Control (Models, Implementations and Experiences)Ariel AlvarezNo ratings yet
- Soft Computing and Optimization AlgorithmsDocument27 pagesSoft Computing and Optimization AlgorithmsAndrew GarfieldNo ratings yet
- Artificial Neural NetworksDocument50 pagesArtificial Neural NetworksRiyujamalNo ratings yet
- Learning: Book: Artificial Intelligence, A Modern Approach (Russell & Norvig)Document22 pagesLearning: Book: Artificial Intelligence, A Modern Approach (Russell & Norvig)Mustefa MohammedNo ratings yet
- Perceptron LearningDocument19 pagesPerceptron LearningWorkagegn TatekNo ratings yet
- 8 ClusteringDocument53 pages8 ClusteringNgọc LợiNo ratings yet
- P9 Conditional Neural ProcessesDocument10 pagesP9 Conditional Neural ProcessesSau L.No ratings yet
- Support Vector Machines (SVMS) : Lirong Tan, Ph.D. StudentDocument38 pagesSupport Vector Machines (SVMS) : Lirong Tan, Ph.D. Studentgheorghe garduNo ratings yet
- Introduction To Artificial Neural NetworksDocument70 pagesIntroduction To Artificial Neural Networksmadhu shree mNo ratings yet
- Bark08 Ghahramani Samlbb 01Document26 pagesBark08 Ghahramani Samlbb 01Shifath NafisNo ratings yet
- FuzzyDocument38 pagesFuzzytidjani86No ratings yet
- Team 22Document5 pagesTeam 22api-422839082No ratings yet
- 03 Single Neuron Traning - 2Document21 pages03 Single Neuron Traning - 2حيدر الجوهرNo ratings yet
- Welcome To The Kernel-ClassDocument11 pagesWelcome To The Kernel-ClassSNo ratings yet
- ECE5550-Notes04 - KopyaDocument50 pagesECE5550-Notes04 - KopyaZeynep Vildan IşıkNo ratings yet
- Deep Learning Using Rectified Linear Units (ReLU)Document7 pagesDeep Learning Using Rectified Linear Units (ReLU)dejanira dejaNo ratings yet
- DOS - ReportDocument25 pagesDOS - ReportSagar SimhaNo ratings yet
- Duda Solutions PDFDocument77 pagesDuda Solutions PDFR Gowri PrasadNo ratings yet
- Test 1 Week 5Document3 pagesTest 1 Week 5Cristian CabelloNo ratings yet
- Lec1 PerceptronPocket RecapDocument61 pagesLec1 PerceptronPocket Recaptejsharma815No ratings yet
- 4.2 AnnDocument26 pages4.2 AnnMatrix BotNo ratings yet
- Evolving Neural Network Using Real Coded Genetic Algorithm (GA) For Multispectral Image ClassificationDocument13 pagesEvolving Neural Network Using Real Coded Genetic Algorithm (GA) For Multispectral Image Classificationjkl316No ratings yet
- UNIT-8 Cluster AnalysisDocument91 pagesUNIT-8 Cluster Analysisvenki yerramallliNo ratings yet
- Identification and Dahlin'S Control For Nonlinear Discrete Time Output Feedback SystemsDocument9 pagesIdentification and Dahlin'S Control For Nonlinear Discrete Time Output Feedback SystemsNguyễn Thành TrungNo ratings yet
- 06 NeuralNetworksIIDocument41 pages06 NeuralNetworksIIBenNo ratings yet
- Algorithm: September 23, 2010 Neural Networks Lecture 6: Perceptron Learning 1Document12 pagesAlgorithm: September 23, 2010 Neural Networks Lecture 6: Perceptron Learning 1Obulesh ANo ratings yet
- Introduction To ANNsDocument31 pagesIntroduction To ANNsanjoomNo ratings yet
- A Probabilistic Theory of Deep Learning: Unit 2Document17 pagesA Probabilistic Theory of Deep Learning: Unit 2HarshitNo ratings yet
- 3 b41658c776 Artificial Intelligence Unit 1Document81 pages3 b41658c776 Artificial Intelligence Unit 1Vishesh negiNo ratings yet
- Deep Learning TrainingDocument9 pagesDeep Learning Training18r91a1255No ratings yet
- Artificial Neural Networks: System That Can Acquire, Store, and Utilize Experiential KnowledgeDocument43 pagesArtificial Neural Networks: System That Can Acquire, Store, and Utilize Experiential KnowledgeUtkarsh AgarwalNo ratings yet
- Introduction To ML Partial 2 PDFDocument54 pagesIntroduction To ML Partial 2 PDFLesocrateNo ratings yet
- An Introduction To Neural Networks: Instituto Tecgraf PUC-Rio Nome: Fernanda Duarte Orientador: Marcelo GattassDocument45 pagesAn Introduction To Neural Networks: Instituto Tecgraf PUC-Rio Nome: Fernanda Duarte Orientador: Marcelo GattassGiGa GFNo ratings yet
- Perceptrons: Fundamentals and Applications for The Neural Building BlockFrom EverandPerceptrons: Fundamentals and Applications for The Neural Building BlockNo ratings yet
- MPDF 6.0 DemoDocument34 pagesMPDF 6.0 DemoCharles UchôaNo ratings yet
- Chapter 9: Supervised Learning Neural NetworksDocument20 pagesChapter 9: Supervised Learning Neural NetworksCharles UchôaNo ratings yet
- Learning From Reinforcement: - Introduction (10.1) - Failure Is The Surest Path To Success (10.2)Document12 pagesLearning From Reinforcement: - Introduction (10.1) - Failure Is The Surest Path To Success (10.2)Charles UchôaNo ratings yet
- To Finance: by George BlazenkoDocument45 pagesTo Finance: by George BlazenkoMoktar Tall ManNo ratings yet
- 1974 - Impedance Functions For A Rigid Foundation On A Layered MediumDocument14 pages1974 - Impedance Functions For A Rigid Foundation On A Layered MediumdisotiriNo ratings yet
- Forces On DislocationsDocument24 pagesForces On DislocationsArthur DingNo ratings yet
- Newton's LawDocument1 pageNewton's LawMastyNo ratings yet
- COMP4610 Notes Set 1Document12 pagesCOMP4610 Notes Set 1G MNo ratings yet
- Gen Physics 1 Wk3Document10 pagesGen Physics 1 Wk3Hannah Bianca RegullanoNo ratings yet
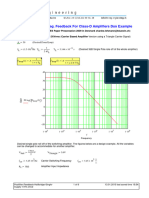
- Mathcad - Postfilter-Feedback-Halfbridge-Single-Supply-170VDocument6 pagesMathcad - Postfilter-Feedback-Halfbridge-Single-Supply-170Vfarid.mmdNo ratings yet
- Statistics Chapter 10 ProjectDocument3 pagesStatistics Chapter 10 Projectapi-590585243No ratings yet
- Delta Function and Heaviside FunctionDocument5 pagesDelta Function and Heaviside FunctionRajat AroraNo ratings yet
- 8.3-Area of CirclesDocument21 pages8.3-Area of CirclesBrett EdgerleNo ratings yet
- Frequencydistributionworksheet 15 RevisedDocument4 pagesFrequencydistributionworksheet 15 RevisedJA HmiNo ratings yet
- 1.2 Auxilia Ry (Concen Ntric) Circle e MethodDocument2 pages1.2 Auxilia Ry (Concen Ntric) Circle e MethodTayani T KumwendaNo ratings yet
- DKB Lecture28 PDFDocument15 pagesDKB Lecture28 PDFSoma Rani MandalNo ratings yet
- 2010 Canadian Computing Competition: Junior Division: SponsorDocument10 pages2010 Canadian Computing Competition: Junior Division: SponsorCSP EDUNo ratings yet
- 1.1 Integers: Math and Science DivisionDocument23 pages1.1 Integers: Math and Science DivisionBobby BannerjeeNo ratings yet
- Compsa - ReviewerDocument5 pagesCompsa - ReviewerCARMONA, Monique Angel DapitanNo ratings yet
- De Thi Ioe Tieng Anh Lop 5 Vong 1 Den 35 7191Document10 pagesDe Thi Ioe Tieng Anh Lop 5 Vong 1 Den 35 7191Nguyễn Thu HuyềnNo ratings yet
- PVT Calculation On Ptetroleum Fluids PDFDocument7 pagesPVT Calculation On Ptetroleum Fluids PDFalejandro fragosoNo ratings yet
- Sullivan-A System of Architectural Ornament-TranscriptDocument4 pagesSullivan-A System of Architectural Ornament-TranscriptLee ChinghangNo ratings yet
- A Technique of Deep Learning For The Classification of ImagesDocument7 pagesA Technique of Deep Learning For The Classification of ImagesSania AshirNo ratings yet
- TN TRB Aeeo SyllabusDocument3 pagesTN TRB Aeeo SyllabusvijayenglishliteratureNo ratings yet
- EEE248 CNG232 Lab2 3 Spring2012Document10 pagesEEE248 CNG232 Lab2 3 Spring2012Aziz Nihat GürsoyNo ratings yet
- 1 - Deflection Diagrams and The Elastic Curve PDFDocument36 pages1 - Deflection Diagrams and The Elastic Curve PDFjaamartinezNo ratings yet
- Y4 Autumn WhiteRoseDocument155 pagesY4 Autumn WhiteRoseSofia Maria QuinnNo ratings yet