0% found this document useful (0 votes)
661 views30 pagesARM CPU Architecture
ARM CPU Architecture
Uploaded by
Tuyen DinhCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
661 views30 pagesARM CPU Architecture
ARM CPU Architecture
Uploaded by
Tuyen DinhCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
- Introduction: Introduces the ARMv8-A CPU architecture overview, setting the stage for subsequent technical details.
- Speaker Introduction: Presents the speaker's background, experience, and role in the ARM company, establishing credibility.
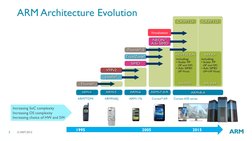
- ARM Architecture Evolution: Describes the historical development of ARM architecture leading to the ARMv8 series.
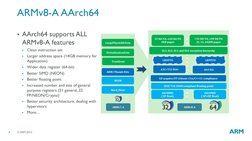
- ARMv8-A AArch64 Features: Details the main features of the ARMv8-A AArch64 including instruction set and performance enhancements.
- What's New in ARMv8-A: Highlights new execution states in ARMv8-A, differentiating between AArch32 and AArch64.
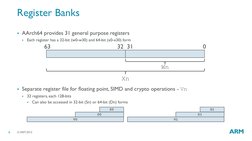
- Register Banks: Explains the structure and function of register files used in ARMv8-A architecture.
- Procedure Call Standard: Defines the rules for using registers in creating function calls in ARM architecture.
- A64 Instruction Set Overview: An overview of the new A64 instruction set, detailing fixed length and similar instructions to previous ARM versions.
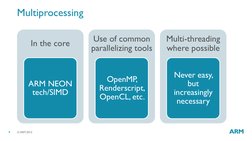
- Multiprocessing: Describes techniques and tools used to enable multiprocessing in ARMv8-A CPUs.
- ARM Cortex-A57 MPCore: Provides a diagram of the ARM Cortex-A57 memory and processing architecture.
- Cluster of Cores: Explains the cluster configuration in ARM SMP systems.
- Multicluster Systems: Details system integration of multiple clusters to enhance processing capability.
- Power Efficiency: Examines the power efficiency strategies implemented in different ARM Cortex models.
- Global Task Scheduling: Introduction to ARM's Global Task Scheduling strategy using big.LITTLE architecture.
- big.LITTLE Development: Explores development strategies and considerations when employing ARM's big.LITTLE architecture.
- Takeaways: Summarizes the ARM big.LITTLE technology advantages, focusing on performance and efficiency.
- NEON - SIMD Data Processing: Discusses the functioning of the NEON SIMD data processing engine as an ARM technology feature.
- Vectors: Provides explanation on the structure and access methods for vectors in SIMD operations.
- Vectorizing Examples: Provides practical examples of code vectorization in ARMv8-A for optimization.
- ARM Technical Training: Promotes ARM's training and development resources available for technical skill enhancement.
- Closure: Concludes the presentation with acknowledgments and copyright notice.