You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Python IntroductionDocument405 pagesPython IntroductionchhacklNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Kollo T 2005 Advanced Multivariate Statistics With Matrices Livro Estatistica Matriz Estatistica MultivariadaDocument502 pagesKollo T 2005 Advanced Multivariate Statistics With Matrices Livro Estatistica Matriz Estatistica MultivariadaAntonio Alfim Malanchini RibeiroNo ratings yet
- Python For Multivariate AnalysisDocument47 pagesPython For Multivariate AnalysisEmmanuelDasiNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Math 362, Problem Set 6Document4 pagesMath 362, Problem Set 6Bruno Soares de CastroNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- O Mle PDFDocument16 pagesO Mle PDFdavidNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- MLEDocument3 pagesMLEPoornima PamulapatiNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Python For Multivariate AnalysisDocument47 pagesPython For Multivariate AnalysisEmmanuelDasiNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Python For Multivariate AnalysisDocument47 pagesPython For Multivariate AnalysisEmmanuelDasiNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Theory Short 09Document101 pagesTheory Short 09Rheza MpNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Ebook Aprenda Os Verbos Irregulares de Uma Vez Por TodasDocument5 pagesEbook Aprenda Os Verbos Irregulares de Uma Vez Por TodasJoel Sulino SimaoNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Python For Multivariate AnalysisDocument47 pagesPython For Multivariate AnalysisEmmanuelDasiNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- AICBICDocument4 pagesAICBICBruno Soares de CastroNo ratings yet
- Multivariate Statistical DistributionsDocument12 pagesMultivariate Statistical DistributionsBruno Soares de CastroNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Little Book of R For Multivariate AnalysisDocument51 pagesLittle Book of R For Multivariate AnalysissactyrNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- PythonScientific Simple PDFDocument335 pagesPythonScientific Simple PDFBruno Soares de Castro100% (2)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Newton Raphson MethodDocument61 pagesThe Newton Raphson MethodAlexander DavidNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- SequencesDocument7 pagesSequencesSilentSparrow98No ratings yet
- Cost FunctionDocument17 pagesCost Functionjuanka82No ratings yet
- Submodular Set Function - WikipediaDocument5 pagesSubmodular Set Function - WikipedianmahsevNo ratings yet
- Eml 5060 - Syllabus Fall 2016Document2 pagesEml 5060 - Syllabus Fall 2016Apratim DasguptaNo ratings yet
- Pure Mathematics Preview Unit 2 - Test 1Document2 pagesPure Mathematics Preview Unit 2 - Test 1kkkkllllNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- New Methods and Applications in Multiple Attribute Decision Making (MADM)Document236 pagesNew Methods and Applications in Multiple Attribute Decision Making (MADM)Kumar palNo ratings yet
- Relation &functionDocument24 pagesRelation &functionAbhishekNo ratings yet
- Algebra: Exercise 1ADocument10 pagesAlgebra: Exercise 1ANigel Itai ZembeNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- CE 215: Structural Analysis and Design I (Pre Req. CE 213) : 4.00 Credit, 4 Hrs/weekDocument4 pagesCE 215: Structural Analysis and Design I (Pre Req. CE 213) : 4.00 Credit, 4 Hrs/weekimam hossainNo ratings yet
- Deductive Reasoning Vs Inductive ReasoningDocument2 pagesDeductive Reasoning Vs Inductive ReasoningAc MIgzNo ratings yet
- Basic Calculus 3rd Quarter Learning Module No.1 Lesson 1 11Document29 pagesBasic Calculus 3rd Quarter Learning Module No.1 Lesson 1 11Mui BautistaNo ratings yet
- Assumptions in Regression Model PDFDocument12 pagesAssumptions in Regression Model PDFtestttNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
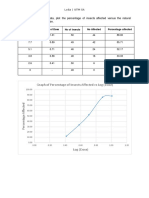
- Graph of Percentage of Insects Affected Vs Log (Dose)Document3 pagesGraph of Percentage of Insects Affected Vs Log (Dose)LydiaRHNo ratings yet
- A Simultaneous Optimization Approach For Off Line Blending and Scheduling of Oil Refinery Operations PDFDocument21 pagesA Simultaneous Optimization Approach For Off Line Blending and Scheduling of Oil Refinery Operations PDFHussaini HamisuNo ratings yet
- Incorporating Limited RationalityDocument17 pagesIncorporating Limited RationalityYago RamalhoNo ratings yet
- Who Chromatography DraftDocument35 pagesWho Chromatography Drafthassaan haiderNo ratings yet
- CH 1 Relations and Functions Multiple Choice Questions With Answers PDFDocument3 pagesCH 1 Relations and Functions Multiple Choice Questions With Answers PDFAnindya100% (4)
- Rudin Osher FatemiDocument10 pagesRudin Osher FatemiSrikant Kamesh IyerNo ratings yet
- Introduction To Classical Test TheoryDocument32 pagesIntroduction To Classical Test TheoryNicoleNo ratings yet
- Hanbook of Numerical Calculations in Engineering-CorectDocument204 pagesHanbook of Numerical Calculations in Engineering-Corectinlov100% (1)
- COMSATS University Islamabad (Sahiwal Campus) : Lab ManualDocument30 pagesCOMSATS University Islamabad (Sahiwal Campus) : Lab ManualMirza Riyasat Ali100% (1)
- Signals and SystemsDocument22 pagesSignals and Systemsvnrao61No ratings yet
- Convex It y 2015Document437 pagesConvex It y 2015sdssd sds0% (1)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Multivariable Calculus ShimamotoDocument326 pagesMultivariable Calculus ShimamotoHelloNo ratings yet
- Jadual Spesifikasi Ujian Matematik TambahanDocument2 pagesJadual Spesifikasi Ujian Matematik Tambahanrofi100% (1)
- HW4 Sol MATH0420 PDFDocument3 pagesHW4 Sol MATH0420 PDFBùi Quang MinhNo ratings yet
- Two Marks FEADocument43 pagesTwo Marks FEAM Vinoth kumarNo ratings yet
- Introduction To Chemical Engneering: Prepared by Fariza/05092016/Fkk/UitmDocument32 pagesIntroduction To Chemical Engneering: Prepared by Fariza/05092016/Fkk/UitmStudent KeekNo ratings yet
- Question: Davison Construction Company Is Building A Luxury Lakefront Home in The Finger Lakes Region of Ne..Document4 pagesQuestion: Davison Construction Company Is Building A Luxury Lakefront Home in The Finger Lakes Region of Ne..Quratulain Shafique Qureshi0% (1)