You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- The Mathematics of (Hacking) PasswordsDocument11 pagesThe Mathematics of (Hacking) PasswordsFederico CarusoNo ratings yet
- Region: Africa Asia Europe Middle East Oceania The AmericasDocument1 pageRegion: Africa Asia Europe Middle East Oceania The AmericasFederico CarusoNo ratings yet
- DAT101x Lab 3 - Statistical AnalysisDocument19 pagesDAT101x Lab 3 - Statistical AnalysisFederico CarusoNo ratings yet
- Graphics Course 0125Document73 pagesGraphics Course 0125Federico CarusoNo ratings yet
- Torturing Excel Into Doing Statistics: Preparing Your SpreadsheetDocument10 pagesTorturing Excel Into Doing Statistics: Preparing Your SpreadsheetFederico CarusoNo ratings yet
- 2007 War Detal HasDocument37 pages2007 War Detal HasFederico CarusoNo ratings yet
- Good Morning Heartache PDFDocument1 pageGood Morning Heartache PDFFederico CarusoNo ratings yet
- Brown, Ray-Bass Method-Bass Clarinet CutDocument90 pagesBrown, Ray-Bass Method-Bass Clarinet CutFederico Caruso67% (3)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Quantitative Aids To Decision MakingDocument130 pagesQuantitative Aids To Decision MakingbalakscribdNo ratings yet
- Exercise For Practice - Quantitative DataDocument4 pagesExercise For Practice - Quantitative DatarohanNo ratings yet
- Practical Statistics For Nursing Using Spss 1St Edition Knapp Solutions Manual Full Chapter PDFDocument67 pagesPractical Statistics For Nursing Using Spss 1St Edition Knapp Solutions Manual Full Chapter PDFAdrianLynchpdci100% (7)
- Module 5: Data Presentation: Learning Outcome: Create Appropriate Tabular and Graphical Displays Using RDocument24 pagesModule 5: Data Presentation: Learning Outcome: Create Appropriate Tabular and Graphical Displays Using RABAGAEL CACHONo ratings yet
- Unit 03 - 04Document27 pagesUnit 03 - 04Nigussie WenNo ratings yet
- Oracle StatisticsDocument26 pagesOracle Statisticsசரவணன் தயாளன்No ratings yet
- 2013 CH 1 Up 9 Probability NoteDocument104 pages2013 CH 1 Up 9 Probability NoteZemenu mandefroNo ratings yet
- Chapter 6 - Process Capability AnalysisDocument21 pagesChapter 6 - Process Capability AnalysisKaya Eralp AsanNo ratings yet
- UntitledDocument72 pagesUntitledDixon XuNo ratings yet
- Chapter 7Document12 pagesChapter 7MARY JOY NAVARRANo ratings yet
- XAT-2017 Explanatory Answers: Part-A Section-IDocument25 pagesXAT-2017 Explanatory Answers: Part-A Section-IAnjaliNo ratings yet
- Applying Quality Standards CSS-NCIIDocument42 pagesApplying Quality Standards CSS-NCIIJasmine100% (1)
- Frequency Distribution in StatisticsDocument5 pagesFrequency Distribution in Statisticsmichelle argenio100% (1)
- Car Price Prediction Using Machine Learning: SRM Institute of Science & Technology Faculty of Engineering & TechnologyDocument21 pagesCar Price Prediction Using Machine Learning: SRM Institute of Science & Technology Faculty of Engineering & Technologysandra antony100% (2)
- Past ManualDocument169 pagesPast ManualRizkiNo ratings yet
- AgainstAllOdds StudentGuide Unit07Document21 pagesAgainstAllOdds StudentGuide Unit07Piyush Vaishwaner0% (1)
- AllCheatSheets Stata v15 PDFDocument6 pagesAllCheatSheets Stata v15 PDFKarenVásquezNo ratings yet
- StatsDocument11 pagesStatsAkirha SoNo ratings yet
- HW 4Document3 pagesHW 4nilyuNo ratings yet
- Session 5-6 - The Passport Nightmare Business Process Analysis in Public Service PDFDocument6 pagesSession 5-6 - The Passport Nightmare Business Process Analysis in Public Service PDFDivya GiriNo ratings yet
- Chapter 20 Modul DSSDocument20 pagesChapter 20 Modul DSSVici Syahril ChairaniNo ratings yet
- 2ND PERIODICALS.Y.2019-2020.odtDocument18 pages2ND PERIODICALS.Y.2019-2020.odtVincent ParungaoNo ratings yet
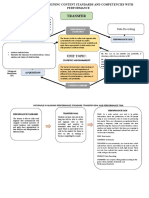
- Transfer: Technique A: Aligning Content Standards and Competencies With PerformanceDocument8 pagesTransfer: Technique A: Aligning Content Standards and Competencies With PerformanceMiguel StraussNo ratings yet
- Statistics Diagrams and GraphsDocument14 pagesStatistics Diagrams and GraphsRaja kamal ChNo ratings yet
- Class-Xi ECONOMICS (030) ANNUAL EXAM (2020-21) : General InstructionsDocument8 pagesClass-Xi ECONOMICS (030) ANNUAL EXAM (2020-21) : General Instructionsadarsh krishnaNo ratings yet
- Spss ExercisesDocument5 pagesSpss Exercisesabcxyz7799No ratings yet
- Zometric Qtools Features ListDocument1 pageZometric Qtools Features ListRakesh JangraNo ratings yet
- 1003 0720 Modelación y Simulación 2 - Libro Averill M Law - Simulation Modeling and Analysis - Solutions of Select ExercisesDocument285 pages1003 0720 Modelación y Simulación 2 - Libro Averill M Law - Simulation Modeling and Analysis - Solutions of Select ExercisesSaul ObandoNo ratings yet
- Community Health Nursing Concept II - HandoutsDocument25 pagesCommunity Health Nursing Concept II - HandoutsDherick Rosas100% (1)
- Stats and Proba 240878Document130 pagesStats and Proba 240878bahru demekeNo ratings yet