You might also like
- CH 4 - Project Integration Management - ExamDocument2 pagesCH 4 - Project Integration Management - ExamEng Thiru100% (2)
- PC Powerplay - October 2013 AUDocument108 pagesPC Powerplay - October 2013 AULewis HuynhNo ratings yet
- Roba MulDocument56 pagesRoba MulNishitha NishiNo ratings yet
- Design-Efficient Approximate Multiplication Circuits Through Partial Product PerforationDocument13 pagesDesign-Efficient Approximate Multiplication Circuits Through Partial Product Perforationpsathishkumar1232544No ratings yet
- A Simple Yet Efficient Accuracy-Configurable Adder DesignDocument14 pagesA Simple Yet Efficient Accuracy-Configurable Adder DesignVinay KelurNo ratings yet
- Design and Analysis of Approximate Redundant Binary MultipliersDocument15 pagesDesign and Analysis of Approximate Redundant Binary MultipliersVijay RajNo ratings yet
- A Novel Design and Analysis of 4: 2 Compressors With Reduced Area Delay and PowerDocument15 pagesA Novel Design and Analysis of 4: 2 Compressors With Reduced Area Delay and PowerraghavNo ratings yet
- ConferenceDocument6 pagesConferenceHeaven varghese C S C SNo ratings yet
- Approximate Arithmetic Circuit Design For Error Resilient ApplicationsDocument16 pagesApproximate Arithmetic Circuit Design For Error Resilient ApplicationsAnonymous e4UpOQEPNo ratings yet
- Low Power DSP Using Approximate AddersDocument14 pagesLow Power DSP Using Approximate AddersNMANo ratings yet
- New Metrics For The Reliability of Approximate and Probabilistic AddersDocument12 pagesNew Metrics For The Reliability of Approximate and Probabilistic AddersNick để họcNo ratings yet
- Microprocessors and Microsystems: G. Anusha, P. DeepaDocument7 pagesMicroprocessors and Microsystems: G. Anusha, P. DeepaDarshan BysaniNo ratings yet
- Camus Dac16Document6 pagesCamus Dac16pskumarvlsipdNo ratings yet
- On The Use of Low-Power Devices, Approximate Adders and Near-Threshold Operation For Energy-Efficient MultipliersDocument12 pagesOn The Use of Low-Power Devices, Approximate Adders and Near-Threshold Operation For Energy-Efficient Multipliersprocess dasNo ratings yet
- Design of Roba Multiplier Using Mac UnitDocument15 pagesDesign of Roba Multiplier Using Mac UnitindiraNo ratings yet
- WordlengthresuctionDocument18 pagesWordlengthresuctionswetha sillveriNo ratings yet
- Low Power DSP 1 TechDocument4 pagesLow Power DSP 1 TechtheobrambaNo ratings yet
- PubDat 188476Document15 pagesPubDat 188476Mohamed AlmortadaNo ratings yet
- Design-Efficient Approximate Multiplication Circuits Through Partial Product PerforationDocument13 pagesDesign-Efficient Approximate Multiplication Circuits Through Partial Product PerforationAnju BalaNo ratings yet
- Design of Roba Multiplier For High-Speed Yet Energy-Efficient Digital Signal Processing Using Verilog HDLDocument16 pagesDesign of Roba Multiplier For High-Speed Yet Energy-Efficient Digital Signal Processing Using Verilog HDLNishitha NishiNo ratings yet
- Design and Analysis of Approximate Compressors For MultiplicationDocument11 pagesDesign and Analysis of Approximate Compressors For MultiplicationAnju BalaNo ratings yet
- Block-Based Carry Speculative Approximate Adder For Energy-Efficient ApplicationsDocument5 pagesBlock-Based Carry Speculative Approximate Adder For Energy-Efficient Applicationskrishna sNo ratings yet
- CMOS Op-Amp Sizing Using A Geometric Programming FormulationDocument17 pagesCMOS Op-Amp Sizing Using A Geometric Programming FormulationShubham RaiNo ratings yet
- FPGA-Based Multi-Level Approximate Multipliers For High-Performance Error-Resilient ApplicationsDocument17 pagesFPGA-Based Multi-Level Approximate Multipliers For High-Performance Error-Resilient ApplicationspskumarvlsipdNo ratings yet
- Optimized Energy Efficient Resource Management in Cloud Data CenterDocument2 pagesOptimized Energy Efficient Resource Management in Cloud Data CenterHimadri BhattacharjeeNo ratings yet
- A New Vlsi Architecture For Modi EdDocument6 pagesA New Vlsi Architecture For Modi Edsatishcoimbato12No ratings yet
- A Novel Approximate Adder Design Using Error Reduced Carry Prediction and Constant TruncationDocument15 pagesA Novel Approximate Adder Design Using Error Reduced Carry Prediction and Constant Truncationkrishna sNo ratings yet
- Tsai 2021 BHJJDocument9 pagesTsai 2021 BHJJHemanthNo ratings yet
- Wattch: Framework For Architectural-Level Power Analysis and OptimizationsDocument12 pagesWattch: Framework For Architectural-Level Power Analysis and OptimizationsUmekalsoomNo ratings yet
- 1 - 04 - 2019 - Design Methodology To Explore Hybrid Approximate Adders For Energy-Efficient Image and Video Processing AcceleratorsDocument14 pages1 - 04 - 2019 - Design Methodology To Explore Hybrid Approximate Adders For Energy-Efficient Image and Video Processing Acceleratorspraba821No ratings yet
- 079 01ismot BbruDocument8 pages079 01ismot Bbrutabu1099No ratings yet
- Enhancing Speculative Execution With Selective Approximate ComputingDocument29 pagesEnhancing Speculative Execution With Selective Approximate ComputingHinata ShoyoNo ratings yet
- The Design of A Low Power Asynchronous Multiplier: Yijun Liu, Steve FurberDocument6 pagesThe Design of A Low Power Asynchronous Multiplier: Yijun Liu, Steve FurberMishi AggNo ratings yet
- Achieving High Speed CFD Simulations: Optimization, Parallelization, and FPGA Acceleration For The Unstructured DLR TAU CodeDocument20 pagesAchieving High Speed CFD Simulations: Optimization, Parallelization, and FPGA Acceleration For The Unstructured DLR TAU Codesmith1011No ratings yet
- Efficient Design of Majority-Logic-Based Approximate Arithmetic CircuitsDocument13 pagesEfficient Design of Majority-Logic-Based Approximate Arithmetic Circuitspes1ug20ec108No ratings yet
- VlsiDocument32 pagesVlsibalasaravanan0408No ratings yet
- Design of Approximate Radix-4 Booth Multipliers For Error-Tolerant ComputingDocument7 pagesDesign of Approximate Radix-4 Booth Multipliers For Error-Tolerant ComputingBilal KhanNo ratings yet
- GM Vs Id Design FlowDocument5 pagesGM Vs Id Design Flowapi-19755952No ratings yet
- PRJ p388Document6 pagesPRJ p388ahmedmamdouhelnajjarNo ratings yet
- DVR Based ThesisDocument5 pagesDVR Based Thesistinajordanhuntsville100% (1)
- II - Software Design For Low PowerDocument11 pagesII - Software Design For Low Powermonishabe23No ratings yet
- Power and Area Efficient Approximate MultipliersDocument5 pagesPower and Area Efficient Approximate MultipliersHemanthNo ratings yet
- (IJCST-V10I2P11) :sarvottam Dixit, Neerja JainDocument7 pages(IJCST-V10I2P11) :sarvottam Dixit, Neerja JainEighthSenseGroupNo ratings yet
- Optimal Number and Placement of Automated Sectionalizing Switches For Smart Grid Distribution AutomationDocument5 pagesOptimal Number and Placement of Automated Sectionalizing Switches For Smart Grid Distribution AutomationAli HadiNo ratings yet
- S. Narayanamoorthy, H.A. Moghaddam, Z. Liu, T. Park, N.S. Kim, InIEEE Transactions On VeryLarge Scale Integration (VLSI) Systems23 (6), 1180 (2015)Document5 pagesS. Narayanamoorthy, H.A. Moghaddam, Z. Liu, T. Park, N.S. Kim, InIEEE Transactions On VeryLarge Scale Integration (VLSI) Systems23 (6), 1180 (2015)VipinNo ratings yet
- Major PPT Batch - 13Document28 pagesMajor PPT Batch - 13Vasanth PerniNo ratings yet
- 1 s2.0 S143484112100385X MainDocument12 pages1 s2.0 S143484112100385X MainShylu SamNo ratings yet
- A Gradient-Based Approach For Power System Design Using Electromagnetic Transient SimulationDocument5 pagesA Gradient-Based Approach For Power System Design Using Electromagnetic Transient SimulationBarron JhaNo ratings yet
- A Green Energy-Efficient Scheduling Algorithm Using The DVFS Technique For Cloud DatacentersDocument7 pagesA Green Energy-Efficient Scheduling Algorithm Using The DVFS Technique For Cloud DatacentersDenner Stevens100% (1)
- Ilsche2019 Article PowerMeasurementTechniquesForEDocument8 pagesIlsche2019 Article PowerMeasurementTechniquesForESajid KhanNo ratings yet
- Optimal Frequency 1-S2.0-S2210537916301755-Am - s0Document24 pagesOptimal Frequency 1-S2.0-S2210537916301755-Am - s0ausiasllorencNo ratings yet
- Ee Computer Application: EecompDocument36 pagesEe Computer Application: EecompJas PayaNo ratings yet
- Low Power CAD: Trends and ChallengesDocument24 pagesLow Power CAD: Trends and Challengesjubincb2No ratings yet
- Dmatm: Dual Modified Adaptive Technique Based MultiplierDocument6 pagesDmatm: Dual Modified Adaptive Technique Based MultiplierTJPRC PublicationsNo ratings yet
- Vlsi95 Power SurveyDocument6 pagesVlsi95 Power Surveyjubincb2No ratings yet
- Approximate Hybrid High Radix Encoding For Energy-Efficient Inexact MultipliersDocument10 pagesApproximate Hybrid High Radix Encoding For Energy-Efficient Inexact MultipliersraghavNo ratings yet
- Modeling Simulation Technology Research For Distribution Network PlanningDocument6 pagesModeling Simulation Technology Research For Distribution Network Planningrasim_m1146No ratings yet
- Design of High Performance Dynamically Truncated A-1Document7 pagesDesign of High Performance Dynamically Truncated A-1Mca SaiNo ratings yet
- Power Management Techniques For Wireless Sensor Networks: A ReviewDocument5 pagesPower Management Techniques For Wireless Sensor Networks: A ReviewLakshmi KNo ratings yet
- A2 IntroDocument28 pagesA2 IntroPranesh 06No ratings yet
- An Energy-Efficient Reconfigurable Public-Key Cryptography ProcessorDocument13 pagesAn Energy-Efficient Reconfigurable Public-Key Cryptography ProcessorseanNo ratings yet
- Design and Test Strategies for 2D/3D Integration for NoC-based Multicore ArchitecturesFrom EverandDesign and Test Strategies for 2D/3D Integration for NoC-based Multicore ArchitecturesNo ratings yet
- Spintronics ML Accelerator PDFDocument40 pagesSpintronics ML Accelerator PDFউদয় কামালNo ratings yet
- Image Captioning Using CNN & LSTM: Digital Signal Processing Laboratory (EEE - 316)Document24 pagesImage Captioning Using CNN & LSTM: Digital Signal Processing Laboratory (EEE - 316)উদয় কামালNo ratings yet
- Dataset For Uav PDFDocument9 pagesDataset For Uav PDFউদয় কামালNo ratings yet
- Aynal Sir Biomed Book Scanned PDFDocument124 pagesAynal Sir Biomed Book Scanned PDFউদয় কামালNo ratings yet
- Adaptive Signal Processing Bernard Widrow, Peter N. StearnsDocument14 pagesAdaptive Signal Processing Bernard Widrow, Peter N. Stearnsউদয় কামালNo ratings yet
- HRS 9 Software License Installation GuideDocument31 pagesHRS 9 Software License Installation GuideAdhiawa Alif Archiafinno0% (1)
- Sap User Group For Railways (Sugrail) Congress: Hosted by Ns (Nederlandse Spoorwegen - Dutch Railways)Document8 pagesSap User Group For Railways (Sugrail) Congress: Hosted by Ns (Nederlandse Spoorwegen - Dutch Railways)jfdiago4703No ratings yet
- ASPA Schedule 1-6Document19 pagesASPA Schedule 1-6nikki.mad8149100% (1)
- Instalacija Mrežnog Operativnog SistemaDocument10 pagesInstalacija Mrežnog Operativnog SistemaAmir KaracicNo ratings yet
- Backgrounder Airbus Commercial Aircraft A380 Facts and Figures enDocument4 pagesBackgrounder Airbus Commercial Aircraft A380 Facts and Figures enFernando NCNo ratings yet
- Group6 (Flipkart)Document4 pagesGroup6 (Flipkart)Atul SinghNo ratings yet
- CVTDocument18 pagesCVTRon Farm100% (1)
- 2012 - DVB-T and DVB-T2 Performance in Fixed Terrestrial TV ChannelsDocument5 pages2012 - DVB-T and DVB-T2 Performance in Fixed Terrestrial TV ChannelsLương Xuân DẫnNo ratings yet
- Assignment 2nd - 566 - Computer ApplicationDocument36 pagesAssignment 2nd - 566 - Computer ApplicationM Hammad ManzoorNo ratings yet
- EEB417 68kDocument82 pagesEEB417 68kfosterNo ratings yet
- Benchmarking Templates For Digital Marketing Smart InsightsDocument15 pagesBenchmarking Templates For Digital Marketing Smart InsightsGabby EnllancheNo ratings yet
- Cencon Atm Security Lock Installation InstructionsDocument24 pagesCencon Atm Security Lock Installation InstructionsbiggusxNo ratings yet
- EMP Lecture 1Document19 pagesEMP Lecture 1Alauddin KhanNo ratings yet
- MG Transformers and Packaged Substations TX5299.V2Document20 pagesMG Transformers and Packaged Substations TX5299.V2engnajeeb75No ratings yet
- Daftar PustakaDocument8 pagesDaftar PustakaResti Nurmala DewiNo ratings yet
- Reducing Welding Defects in Turnaround Projects Lean Six SigmaDocument15 pagesReducing Welding Defects in Turnaround Projects Lean Six SigmaLuis Eduardo Arellano100% (3)
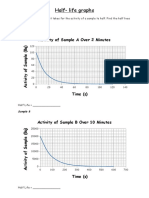
- Half Life Graphs WorksheetDocument2 pagesHalf Life Graphs WorksheetafdsgafgNo ratings yet
- How To Select An ActuatorDocument12 pagesHow To Select An Actuatorforevertay2000100% (2)
- 6100 Series PDFDocument2 pages6100 Series PDFSayed Younis SadaatNo ratings yet
- Art of DelegationDocument19 pagesArt of DelegationDilip DhageNo ratings yet
- Proceedings IUFRO 3.06 NorwayDocument128 pagesProceedings IUFRO 3.06 NorwayBqdcc6No ratings yet
- 1 (MVA) 23 / 13.2 (KV) Transformador: Los AngelesDocument1 page1 (MVA) 23 / 13.2 (KV) Transformador: Los AngelesHans Cabrera MankowskiNo ratings yet
- Stream Cipher - Wikipedia, The Free EncyclopediaDocument5 pagesStream Cipher - Wikipedia, The Free EncyclopediaKiran GunasegaranNo ratings yet
- Berkeley Vertical Multi Stage Pumps Catalog 08 02Document24 pagesBerkeley Vertical Multi Stage Pumps Catalog 08 02Gayan ChathurangaNo ratings yet
- TV Antenna PDFDocument4 pagesTV Antenna PDFDom BolNo ratings yet
- Drones TeamTBD FullDocument43 pagesDrones TeamTBD FullAkshat JaniNo ratings yet
- 12fuegen Prog eDocument7 pages12fuegen Prog eMário PereiraNo ratings yet
- GX630 GX690: Owner'S Manual Manuel de L'Utilisateur Manual Del PropietarioDocument45 pagesGX630 GX690: Owner'S Manual Manuel de L'Utilisateur Manual Del PropietarioOsman ElmaradnyNo ratings yet