You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- 2 Two Period ModelDocument10 pages2 Two Period ModelSandrine MattheyNo ratings yet
- Aerodynamic Optimization of Missile ExternalDocument103 pagesAerodynamic Optimization of Missile ExternalDinh Le100% (1)
- HHT Alpha MethodDocument22 pagesHHT Alpha MethodSasi Sudhahar ChinnasamyNo ratings yet
- Engineering Optimization, 2nd Ed, Wiley (2006), 0471558141Document681 pagesEngineering Optimization, 2nd Ed, Wiley (2006), 0471558141Shivani Gupta100% (1)
- Sheet With AnswersDocument87 pagesSheet With Answersshivam pradhanNo ratings yet
- New Text DocumentDocument19 pagesNew Text Documentshivam pradhanNo ratings yet
- Ensomerge MSAT Exam Set 01Document6 pagesEnsomerge MSAT Exam Set 01shivam pradhanNo ratings yet
- Homework #3: MDPS, Q-Learning, &: PomdpsDocument18 pagesHomework #3: MDPS, Q-Learning, &: Pomdpsshivam pradhanNo ratings yet
- Swine Flu en IN PDFDocument2 pagesSwine Flu en IN PDFshivam pradhanNo ratings yet
- Torrent Downloaded From Bt-Scene - CCDocument1 pageTorrent Downloaded From Bt-Scene - CCshivam pradhan100% (1)
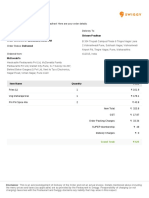
- Shivam Pradhan: Thanks For Choosing Swiggy, Shivam Pradhan! Here Are Your Order Details: Delivery ToDocument1 pageShivam Pradhan: Thanks For Choosing Swiggy, Shivam Pradhan! Here Are Your Order Details: Delivery Toshivam pradhanNo ratings yet
- Namaste KichenDocument1 pageNamaste Kichenshivam pradhanNo ratings yet
- Advanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, MadrasDocument24 pagesAdvanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, MadrasSharmila ShettyNo ratings yet
- MT105a Commentary 2019 PDFDocument23 pagesMT105a Commentary 2019 PDFNghia Tuan NghiaNo ratings yet
- 0 - Introduction PDFDocument3 pages0 - Introduction PDFDan EnzerNo ratings yet
- Dommel Tinney OpfDocument11 pagesDommel Tinney OpffpttmmNo ratings yet
- Dynamic Optimization Using Lagrangian and Hamiltonian MethodsDocument38 pagesDynamic Optimization Using Lagrangian and Hamiltonian MethodsjrodascNo ratings yet
- Hysys Rto RefguideDocument154 pagesHysys Rto RefguideMohanad Magdy SaidNo ratings yet
- Practice Problems: Paul DawkinsDocument77 pagesPractice Problems: Paul DawkinsMonica PonnamNo ratings yet
- Nonlinear Programming 3rd Edition Theoretical Solutions ManualDocument26 pagesNonlinear Programming 3rd Edition Theoretical Solutions ManualJigo CasteloNo ratings yet
- Nptel CN MathsDocument32 pagesNptel CN MathsAnurag SharmaNo ratings yet
- Schonemann Trace Derivatives PresentationDocument82 pagesSchonemann Trace Derivatives PresentationGiagkinis GiannisNo ratings yet
- Three Strategies To Derive A Dual ProblemDocument8 pagesThree Strategies To Derive A Dual ProblemRyota TomiokaNo ratings yet
- Opf Ieee PDFDocument17 pagesOpf Ieee PDFMayank GoyalNo ratings yet
- This Study Resource Was: Final ExaminationDocument7 pagesThis Study Resource Was: Final ExaminationPuwa CalvinNo ratings yet
- Power System Analysis: Economic DispatchDocument39 pagesPower System Analysis: Economic DispatchMukesh SharmaNo ratings yet
- Neural Networks in A Softcomputing FrameworkDocument67 pagesNeural Networks in A Softcomputing FrameworkEmilio GarcíaNo ratings yet
- Quantitative Methods in Economics IIDocument8 pagesQuantitative Methods in Economics IIJoshi2014No ratings yet
- Ds 5Document21 pagesDs 5Saransh ShivhareNo ratings yet
- Stress Testing Correlation Matrix A Maximum Empirical Likelihood ApproachDocument8 pagesStress Testing Correlation Matrix A Maximum Empirical Likelihood ApproachGiuliano de Queiroz FerreiraNo ratings yet
- 4.0 Preliminaries of Hydro-Thermal Scheduling (HTS)Document30 pages4.0 Preliminaries of Hydro-Thermal Scheduling (HTS)prabhatNo ratings yet
- Optimal Truss Design Including Plastic Collapse ConstraintsDocument8 pagesOptimal Truss Design Including Plastic Collapse Constraintscasoj29No ratings yet
- Chapter 07Document20 pagesChapter 07richaNo ratings yet
- COMP 4211 - Machine LearningDocument19 pagesCOMP 4211 - Machine LearningLinh TaNo ratings yet
- 2010 Lecture 005 PDFDocument43 pages2010 Lecture 005 PDFeouahiauNo ratings yet
- VP LectureNotes 2010Document26 pagesVP LectureNotes 2010nickthegreek142857No ratings yet