You might also like
- Data Analysis With RDocument52 pagesData Analysis With Rraghavsiva89100% (1)
- Pattern Recognition and Artificial Intelligence, Towards an Integration: Proceedings of an International Workshop held in Amsterdam, May 18-20, 1988From EverandPattern Recognition and Artificial Intelligence, Towards an Integration: Proceedings of an International Workshop held in Amsterdam, May 18-20, 1988No ratings yet
- Applied Sciences: When Deep Learning Meets Data Alignment: A Review On Deep Registration Networks (DRNS)Document20 pagesApplied Sciences: When Deep Learning Meets Data Alignment: A Review On Deep Registration Networks (DRNS)SouhailKelNo ratings yet
- Lab Workbook With Solutions-Final PDFDocument109 pagesLab Workbook With Solutions-Final PDFAbhinash Alla100% (5)
- Intelligent Granulation of Machine-Generated Data: June 2013Document7 pagesIntelligent Granulation of Machine-Generated Data: June 2013A ANo ratings yet
- QR Factorization of Tall and Skinny Matrices in A Grid Computing EnvironmentDocument15 pagesQR Factorization of Tall and Skinny Matrices in A Grid Computing EnvironmenthamilearnNo ratings yet
- Chaos Escribano06Document12 pagesChaos Escribano06Artur MinasyanNo ratings yet
- Neural Networks As Radial-Interval Systems Through Learning FunctionDocument3 pagesNeural Networks As Radial-Interval Systems Through Learning FunctionRahul SharmaNo ratings yet
- A Simple Method For Estimating The Fractal Dimension From Digital Images - The Compression DimensionDocument11 pagesA Simple Method For Estimating The Fractal Dimension From Digital Images - The Compression DimensionLuciano ZuninoNo ratings yet
- FOURDATAMODELSINGISDocument70 pagesFOURDATAMODELSINGIS444204056No ratings yet
- FHNW Bachelor ThesisDocument8 pagesFHNW Bachelor Thesisjenniferrobinsonjackson100% (2)
- Applsci 12 09402 v2Document21 pagesApplsci 12 09402 v2Nghiem Quoc AnhNo ratings yet
- Spearman Coefficient For Functions Valencia Lillo Romo 2013 Univcarlosiii WPDocument26 pagesSpearman Coefficient For Functions Valencia Lillo Romo 2013 Univcarlosiii WPJhon MayaNo ratings yet
- Classification of Airborne 3D Point Clouds Regarding Separation of Vegetation in Complex EnvironmentsDocument15 pagesClassification of Airborne 3D Point Clouds Regarding Separation of Vegetation in Complex EnvironmentsGabriel RaamonNo ratings yet
- Signal Processing: Armin Eftekhari, Massoud Babaie-Zadeh, Hamid Abrishami MoghaddamDocument15 pagesSignal Processing: Armin Eftekhari, Massoud Babaie-Zadeh, Hamid Abrishami MoghaddamMohammed BenbrahimNo ratings yet
- dm10 061 AcareDocument12 pagesdm10 061 AcareElida FeifaNo ratings yet
- GUNDAM: A Toolkit For Fast Spatial Correlation Functions in Galaxy SurveysDocument12 pagesGUNDAM: A Toolkit For Fast Spatial Correlation Functions in Galaxy SurveysAkhmad Alfan RahadiNo ratings yet
- Fyp Research PaperDocument4 pagesFyp Research Paperc9r5wdf5100% (1)
- Interactive Computer Graphics: Functional, ProeedurAl, and Device-Level MethodsDocument3 pagesInteractive Computer Graphics: Functional, ProeedurAl, and Device-Level MethodsBenjamin GossweilerNo ratings yet
- Completion: MatrixDocument179 pagesCompletion: MatrixAkhil AkkapelliNo ratings yet
- DSA - Manual22-23 Swarup DevdeDocument44 pagesDSA - Manual22-23 Swarup DevdeSwarup DevdeNo ratings yet
- ITCE 380 Lab Report 7Document7 pagesITCE 380 Lab Report 7Amna AzmatNo ratings yet
- Index Based Top K Uncertain GraphsDocument29 pagesIndex Based Top K Uncertain Graphswillwoods168No ratings yet
- Discovering Patterns With Weak-Wildcard GapsDocument11 pagesDiscovering Patterns With Weak-Wildcard GapsgowripNo ratings yet
- Sdimfeisas PDFDocument20 pagesSdimfeisas PDF游俊彥No ratings yet
- Thesis Gis UtmDocument7 pagesThesis Gis Utmjenniferlandsmannneworleans100% (2)
- High Performance Object-Oriented Scientific Programming in Fortran 90Document8 pagesHigh Performance Object-Oriented Scientific Programming in Fortran 90Malachy EziechinaNo ratings yet
- Publi 2020 IJNME Ghanem Soize Mehrez Aitharaju PreprintDocument22 pagesPubli 2020 IJNME Ghanem Soize Mehrez Aitharaju PreprintTathagato BoseNo ratings yet
- Typeset Proof-FAIR Data Model For Chemical Substances. Developme (2022-12-27 18 - 24 - 46) - NK - GT - v2Document23 pagesTypeset Proof-FAIR Data Model For Chemical Substances. Developme (2022-12-27 18 - 24 - 46) - NK - GT - v2jeliazkova.ninaNo ratings yet
- Spatial DB Part-4Document28 pagesSpatial DB Part-4Avudaiappan SNo ratings yet
- Board of Studies: Master of Science (Computer Science)Document31 pagesBoard of Studies: Master of Science (Computer Science)Gi WiveNo ratings yet
- Interpolation As A Tool For The Modelling of ThreeDocument7 pagesInterpolation As A Tool For The Modelling of Threeshahab rahimiNo ratings yet
- Functional StatisticsDocument150 pagesFunctional StatisticsmonicabNo ratings yet
- Introdataviz PreprintDocument59 pagesIntrodataviz PreprintJorgeNo ratings yet
- Information Sciences: Chunyao Song, Tingjian Ge, Yao Ge, Haowen Zhang, Xiaojie YuanDocument24 pagesInformation Sciences: Chunyao Song, Tingjian Ge, Yao Ge, Haowen Zhang, Xiaojie YuanSudhir M RNo ratings yet
- Geofd: An R Package For Function-Valued Geostatistical PredictionDocument23 pagesGeofd: An R Package For Function-Valued Geostatistical PredictionClaudia GarciaNo ratings yet
- 8444-Article Text-25112-1-10-20171211Document20 pages8444-Article Text-25112-1-10-20171211Yoakim MoraNo ratings yet
- Uncertain Canonical Correlation Analysis For Multi-View FeatureDocument11 pagesUncertain Canonical Correlation Analysis For Multi-View Featurehind90No ratings yet
- GraphSigProc Part I v18 NowFnTDocument49 pagesGraphSigProc Part I v18 NowFnTljubisa4840No ratings yet
- Bases de DatosDocument15 pagesBases de DatosIvan HSNo ratings yet
- C1 Support IJNME43Document25 pagesC1 Support IJNME43Daniel ClaudiuNo ratings yet
- A Hierarchical Approach To The A Posteriori Error Estimation of Isogeometric Kirchhoff Plates and Kirchhoff-Love ShellsDocument20 pagesA Hierarchical Approach To The A Posteriori Error Estimation of Isogeometric Kirchhoff Plates and Kirchhoff-Love ShellsJorge Luis Garcia ZuñigaNo ratings yet
- Data Stream Clustering: A Survey: ACM Computing Surveys March 2014Document39 pagesData Stream Clustering: A Survey: ACM Computing Surveys March 2014Daniel LNo ratings yet
- MCADocument11 pagesMCAAlphones DamonNo ratings yet
- An Optical Communication's Perspective On Machine Learning and Its ApplicationsDocument24 pagesAn Optical Communication's Perspective On Machine Learning and Its ApplicationsHassan RizwanNo ratings yet
- Bachelor Thesis Haw HamburgDocument7 pagesBachelor Thesis Haw HamburgPayForSomeoneToWriteYourPaperUK100% (2)
- Splay Method of Model Acquisition AssessmentDocument3 pagesSplay Method of Model Acquisition AssessmentEditor IJTSRDNo ratings yet
- Sensors: Real-Time Pattern-Recognition of GPR Images With YOLO v3 Implemented by TensorflowDocument18 pagesSensors: Real-Time Pattern-Recognition of GPR Images With YOLO v3 Implemented by TensorflowMiftNo ratings yet
- Texture Images Analysis Using Fractal Extracted AttributesDocument16 pagesTexture Images Analysis Using Fractal Extracted AttributesjasimNo ratings yet
- Int Statistical Rev - 2013 - H Rdle - Bootstrap Methods For Time SeriesDocument25 pagesInt Statistical Rev - 2013 - H Rdle - Bootstrap Methods For Time SeriesTitin AgustinaNo ratings yet
- And Information Science, University of Granada, Spain Received 22 January 2004 RevisedDocument15 pagesAnd Information Science, University of Granada, Spain Received 22 January 2004 RevisedXis' ArshavinNo ratings yet
- Multivariable Functional Interpolation and Adaptive NetworksDocument35 pagesMultivariable Functional Interpolation and Adaptive NetworksBruno FarinaNo ratings yet
- Robust Decision TreesDocument6 pagesRobust Decision TreesjrodascNo ratings yet
- Midsem I 31 03 2023Document12 pagesMidsem I 31 03 2023MUSHTAQ AHAMEDNo ratings yet
- Quantum AlgorithmsDocument17 pagesQuantum AlgorithmsAlexNo ratings yet
- Fusion of Distributions For Radar Clutter ModelingDocument9 pagesFusion of Distributions For Radar Clutter Modelingxcekax_net1666No ratings yet
- R18 B.TECH CSE II Year Syllabus PDFDocument33 pagesR18 B.TECH CSE II Year Syllabus PDFHemima RachelNo ratings yet
- Master of Science in Big Data Science ModulesDocument4 pagesMaster of Science in Big Data Science Modulesneer dingerNo ratings yet
- Thesis Gis PDFDocument7 pagesThesis Gis PDFdwsmjsqy100% (1)
- Quick Search: Σκριπ 07/05/1904 Section Section Section SectionDocument1 pageQuick Search: Σκριπ 07/05/1904 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 22/05/1904 Section Section Section SectionDocument1 pageQuick Search: Σκριπ 22/05/1904 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Maios Zesti SkoniDocument1 pageMaios Zesti SkoniPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 16/03/1905 Section Section Section SectionDocument2 pagesQuick Search: Σκριπ 16/03/1905 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Onomasia Odwn 1905Document1 pageOnomasia Odwn 1905Panagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 12/02/1905 Section Section Section SectionDocument2 pagesQuick Search: Σκριπ 12/02/1905 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 18/01/1905 Section Section Section Section Section SectionDocument1 pageQuick Search: Σκριπ 18/01/1905 Section Section Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Minimum Arc of MovementDocument1 pageMinimum Arc of Movementindian democracyNo ratings yet
- Quick Search: SectionDocument2 pagesQuick Search: SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 31/12/1904 Section Section Section Section Section SectionDocument1 pageQuick Search: Σκριπ 31/12/1904 Section Section Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Breathing Control: Pistol@tenrings - Co.ukDocument1 pageBreathing Control: Pistol@tenrings - Co.ukmanfromgladNo ratings yet
- Quick Search: Σκριπ 17/01/1905 Section Section Section Section Section SectionDocument1 pageQuick Search: Σκριπ 17/01/1905 Section Section Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- 195 251 59 97 Viewer BnlViewer View Index HTML Lang El Panel PP Issue E52 - 123 Page 1Document1 page195 251 59 97 Viewer BnlViewer View Index HTML Lang El Panel PP Issue E52 - 123 Page 1Panagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 11/02/1905 Section Section Section SectionDocument2 pagesQuick Search: Σκριπ 11/02/1905 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 07/02/1905 Section Section Section SectionDocument2 pagesQuick Search: Σκριπ 07/02/1905 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- FINAL Report Recreational Boating Formatted REVISED 241115Document146 pagesFINAL Report Recreational Boating Formatted REVISED 241115Panagiotis KarathymiosNo ratings yet
- Apagwges 1904Document1 pageApagwges 1904Panagiotis KarathymiosNo ratings yet
- Staff Working Paper No. 865: Making Text Count: Economic Forecasting Using Newspaper TextDocument49 pagesStaff Working Paper No. 865: Making Text Count: Economic Forecasting Using Newspaper TextPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 02/08/1904 Section Section Section SectionDocument1 pageQuick Search: Σκριπ 02/08/1904 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- ExampleDocument14 pagesExampleKai WikeleyNo ratings yet
- Follow Through: Pistol: o o o o oDocument1 pageFollow Through: Pistol: o o o o oPanagiotis KarathymiosNo ratings yet
- Applied Artificial Intelligence: GroupDocument7 pagesApplied Artificial Intelligence: GroupPanagiotis KarathymiosNo ratings yet
- Bayes Slides1Document146 pagesBayes Slides1Panagiotis KarathymiosNo ratings yet
- Statistical Science: Volume 33, Number 2 May 2018Document35 pagesStatistical Science: Volume 33, Number 2 May 2018Panagiotis KarathymiosNo ratings yet
- Keogh Et Al 2018 BiometricsDocument12 pagesKeogh Et Al 2018 BiometricsPanagiotis KarathymiosNo ratings yet
- Missing ValuesDocument16 pagesMissing ValuesPanagiotis KarathymiosNo ratings yet
- Bayes Notes1Document75 pagesBayes Notes1Alecia SuarezNo ratings yet
- Bayes Notes1Document148 pagesBayes Notes1Panagiotis Karathymios100% (1)
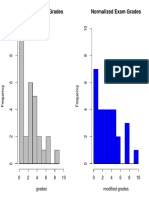
- Original Exam Grades Normalized Exam GradesDocument1 pageOriginal Exam Grades Normalized Exam GradesPanagiotis KarathymiosNo ratings yet
- LogDocument7 pagesLogplaastore1No ratings yet
- Simone's ResumeDocument4 pagesSimone's ResumeMorrisa AlexanderNo ratings yet
- Models of Communication (Linear & Shanon Weaver)Document14 pagesModels of Communication (Linear & Shanon Weaver)Anshul BhadouriaNo ratings yet
- Samsung NP530U3Document81 pagesSamsung NP530U3danielradu27100% (1)
- Ib 0600562 EngfDocument25 pagesIb 0600562 EngfGod Damn Fu cking DegenerateNo ratings yet
- Assembly - Arrays - TutorialspointDocument2 pagesAssembly - Arrays - TutorialspointMordi MustafaNo ratings yet
- Online Ticket Reservation SystemDocument20 pagesOnline Ticket Reservation SystemRaj Umakantham80% (5)
- G1000 NXi Reference GuideDocument182 pagesG1000 NXi Reference GuideCassiano CapellassiNo ratings yet
- Ejoam TemplateDocument22 pagesEjoam TemplateJack FisherNo ratings yet
- File Do An ThuDocument11 pagesFile Do An Thusanbay phanthietNo ratings yet
- Prabh CV PDFDocument7 pagesPrabh CV PDFKeshav Kumar100% (1)
- Snake 101Document13 pagesSnake 101cryptobengsgNo ratings yet
- Emtech Q1 Las Week 4Document4 pagesEmtech Q1 Las Week 4rosellerNo ratings yet
- Template Customer - Journey - Maps - 99281Document12 pagesTemplate Customer - Journey - Maps - 99281lawyerNo ratings yet
- HCL Technical MCQ - 239 QuestionsDocument66 pagesHCL Technical MCQ - 239 QuestionsAbdul MusavvirNo ratings yet
- MODEL 1230: Ac Induction Motor ControllerDocument4 pagesMODEL 1230: Ac Induction Motor ControllerJorge MorenoNo ratings yet
- Examen, 03 ED, 2020A - ECUACIONES DIFERENCIALES (2020A), Spring 2020 - WebAssign PDFDocument4 pagesExamen, 03 ED, 2020A - ECUACIONES DIFERENCIALES (2020A), Spring 2020 - WebAssign PDFMarcos ArtolaNo ratings yet
- Telugu IME ReadmeDocument5 pagesTelugu IME Readmesravannkumar2626ramNo ratings yet
- DSP PDFDocument2 pagesDSP PDFSibiviswa RajendranNo ratings yet
- Rodrigues Frade - DPP-Webinar) - (DIGIT) - (v2.02)Document31 pagesRodrigues Frade - DPP-Webinar) - (DIGIT) - (v2.02)xinyang sunNo ratings yet
- 8086 Masm ManualDocument25 pages8086 Masm Manualsri_baba0988% (8)
- Critical Review BIM Project ManagementDocument15 pagesCritical Review BIM Project ManagementMelkamu DemewezNo ratings yet
- 4 Ways To Recover A Dead Hard Disk - WikiHowDocument7 pages4 Ways To Recover A Dead Hard Disk - WikiHow1051988No ratings yet
- DBMSBSIT3A&CS3Document6 pagesDBMSBSIT3A&CS3armie valenciaNo ratings yet
- Guidelines For Filling Up The ChecklistDocument42 pagesGuidelines For Filling Up The ChecklistSunil UndarNo ratings yet
- Gcse Science Homework OnlineDocument4 pagesGcse Science Homework Onlinevxrtevhjf100% (1)
- Blogs Sap Com 2023 01 16 Collected Information About Reclaim Shrink DefragmentatDocument9 pagesBlogs Sap Com 2023 01 16 Collected Information About Reclaim Shrink DefragmentatPrasad BoddapatiNo ratings yet
- Linux Foundation Certified Sysadmin (LFCS)Document9 pagesLinux Foundation Certified Sysadmin (LFCS)Sema AbayNo ratings yet
- Microsoft AZ-500 Exam Practice Set - 04 - Results Attempt 1: Return To ReviewDocument51 pagesMicrosoft AZ-500 Exam Practice Set - 04 - Results Attempt 1: Return To ReviewDigambar S TatkareNo ratings yet
- SoftwareDesignSpecification TemplateDocument7 pagesSoftwareDesignSpecification Templategiaphuc2004hgNo ratings yet