You might also like
- EXTRACTING RULES FROM NEURAL NETWORKS USING ARTIFICIAL IMMUNE SYSTEMSDocument5 pagesEXTRACTING RULES FROM NEURAL NETWORKS USING ARTIFICIAL IMMUNE SYSTEMSjehadyamNo ratings yet
- Neuro-fuzzy approach classifies infant sleep stagesDocument4 pagesNeuro-fuzzy approach classifies infant sleep stagesvsalaiselvamNo ratings yet
- Segmentation of Medical Image Using Fuzzy Neuro LogicDocument3 pagesSegmentation of Medical Image Using Fuzzy Neuro LogicInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Takagi-Sugeno Fuzzy Control Based On Robust Stability SpecificationsDocument25 pagesTakagi-Sugeno Fuzzy Control Based On Robust Stability SpecificationsMEWAEL MIZANNo ratings yet
- Fu Et Al - 2019 - More Unlabelled Data or Label More DataDocument6 pagesFu Et Al - 2019 - More Unlabelled Data or Label More DataA BCNo ratings yet
- Microarray Gene Expression Ranking With Z Score For Cancer ClassificationDocument5 pagesMicroarray Gene Expression Ranking With Z Score For Cancer ClassificationEditor IJRITCCNo ratings yet
- Simultaneous Differential Diagnoses Basing On MMPI Inventory Norbert Jankowski and Jerzy GomułaDocument5 pagesSimultaneous Differential Diagnoses Basing On MMPI Inventory Norbert Jankowski and Jerzy GomułaUSFMFPNo ratings yet
- 15 Aos1423Document37 pages15 Aos1423sherlockholmes108No ratings yet
- Biostatistics Assignment: Dna Microarray: ANDocument14 pagesBiostatistics Assignment: Dna Microarray: ANAkhil NairNo ratings yet
- M. B. Yobas, J. N. Crook, D P. Ross - Credit Scoring Using Neural and Evolutionary TechniquesDocument15 pagesM. B. Yobas, J. N. Crook, D P. Ross - Credit Scoring Using Neural and Evolutionary Techniqueshenrique_olivNo ratings yet
- Biomedical Data Analysis by Supervised Manifold LearningDocument4 pagesBiomedical Data Analysis by Supervised Manifold LearningCarlos López NoriegaNo ratings yet
- An ANFIS Based Fuzzy Synthesis Judgment For Transformer Fault DiagnosisDocument10 pagesAn ANFIS Based Fuzzy Synthesis Judgment For Transformer Fault DiagnosisDanh Bui CongNo ratings yet
- Applied Artificial Neural Networks: From Associative Memories To Biomedical ApplicationsDocument28 pagesApplied Artificial Neural Networks: From Associative Memories To Biomedical ApplicationsVXNo ratings yet
- Annie StabDocument6 pagesAnnie StabAnshul SharmaNo ratings yet
- Comparison Between KNN and SVM For EMG Signal ClassificationDocument3 pagesComparison Between KNN and SVM For EMG Signal ClassificationEditor IJRITCC100% (1)
- Multilevel Model Analysis Using R: Nicolae-Marius JulaDocument12 pagesMultilevel Model Analysis Using R: Nicolae-Marius JulaAngel Urueta FernandezNo ratings yet
- Helicopter Dynamics-10Document14 pagesHelicopter Dynamics-10KaradiasNo ratings yet
- A Genetic Algorithm for ClassificationDocument6 pagesA Genetic Algorithm for Classificationfran.nanclaresNo ratings yet
- Neural Applied Dynamic Model For Diabetic Patients: AbsfrrrctDocument4 pagesNeural Applied Dynamic Model For Diabetic Patients: AbsfrrrctAnonymous HUY0yRexYfNo ratings yet
- A Morphogenetic Evolutionary System: Phylogenesis of The Poetic CircuitDocument12 pagesA Morphogenetic Evolutionary System: Phylogenesis of The Poetic CircuitrorourkNo ratings yet
- Estrategias de Control - ProcesosDocument9 pagesEstrategias de Control - ProcesosEdgar Maya PerezNo ratings yet
- Applications of Diffusion Maps in Gene Expression Data-Based Cancer Diagnosis AnalysisDocument4 pagesApplications of Diffusion Maps in Gene Expression Data-Based Cancer Diagnosis AnalysisDyah Septi AndryaniNo ratings yet
- We Are Intechopen, The World'S Leading Publisher of Open Access Books Built by Scientists, For ScientistsDocument17 pagesWe Are Intechopen, The World'S Leading Publisher of Open Access Books Built by Scientists, For Scientistsdd sasdsdNo ratings yet
- Bacterial Chemotaxis Optimization AlgorithmDocument5 pagesBacterial Chemotaxis Optimization AlgorithmMohammad saheemNo ratings yet
- Lecture On C - ChartDocument20 pagesLecture On C - Chart191329No ratings yet
- Heart Murmur Detection and Clinical Outcome Prediction Using Multilayer Perceptron ClassifierDocument4 pagesHeart Murmur Detection and Clinical Outcome Prediction Using Multilayer Perceptron ClassifierDalana PasinduNo ratings yet
- Effective Predictor of Human Mast Cell Tryptase Inhibitors: Sorin Avram, Stefana Avram, Cristina DeheleanDocument4 pagesEffective Predictor of Human Mast Cell Tryptase Inhibitors: Sorin Avram, Stefana Avram, Cristina DeheleanAnonymous p52JDZOdNo ratings yet
- Journal of Multivariate Analysis: H. Romdhani, L. Lakhal-Chaieb, L.-P. RivestDocument16 pagesJournal of Multivariate Analysis: H. Romdhani, L. Lakhal-Chaieb, L.-P. RivestAbdul Azies KurniawanNo ratings yet
- Comparison of MLDocument8 pagesComparison of MLjahanzebNo ratings yet
- Inteligencia ArtificialDocument15 pagesInteligencia ArtificialSebastian Vallejo RangelNo ratings yet
- Fuzzy Supervisory PI Controller Using Hierarchical Genetic AlgorithmsDocument6 pagesFuzzy Supervisory PI Controller Using Hierarchical Genetic AlgorithmsSahasra KalyanNo ratings yet
- Microarray FullDocument56 pagesMicroarray FullSyed MasudNo ratings yet
- Project O: Breast Cancer Gene Analysis Using R: Sheena Scroggins, Susan Mcgowan, John CarasDocument25 pagesProject O: Breast Cancer Gene Analysis Using R: Sheena Scroggins, Susan Mcgowan, John Carassheena_scroggin3619No ratings yet
- Introduccion UPDocument16 pagesIntroduccion UPOscar SanchezNo ratings yet
- Germinal Center Optimization Applied to Neural Inverse Optimal ControlDocument16 pagesGerminal Center Optimization Applied to Neural Inverse Optimal ControlOscar SanchezNo ratings yet
- Tuning Fuzzy Logic Controllers by Genetic Algorithms : F. Herrera, M. Lozano, and J. L. VerdegayDocument17 pagesTuning Fuzzy Logic Controllers by Genetic Algorithms : F. Herrera, M. Lozano, and J. L. VerdegayAhmed BadawyNo ratings yet
- Diagnosing Acute Appendicitis With Very Simple RulesDocument14 pagesDiagnosing Acute Appendicitis With Very Simple Rulescarlitoscom18No ratings yet
- PLS-DA for hyperspectral data classificationDocument21 pagesPLS-DA for hyperspectral data classificationJoseNo ratings yet
- An Excellent Mortality Prediction Model Based On Support Vector MachineDocument4 pagesAn Excellent Mortality Prediction Model Based On Support Vector MachineJose Andres Cartuche ValverdeNo ratings yet
- Adaptive Control For A Class of Non-Affine Nonlinear Systems Via Neural NetworksDocument37 pagesAdaptive Control For A Class of Non-Affine Nonlinear Systems Via Neural Networkskj185No ratings yet
- Neural Network Weight Selection Using Genetic AlgorithmsDocument17 pagesNeural Network Weight Selection Using Genetic AlgorithmsChevalier De BalibariNo ratings yet
- Neural Networks in Medical DiagnosisDocument12 pagesNeural Networks in Medical DiagnosisSamantha RoopNo ratings yet
- Sample Size and Power Calculations Using The Noncentral T-DistributionDocument12 pagesSample Size and Power Calculations Using The Noncentral T-Distributionwulandari_rNo ratings yet
- Tuning Fuzzy Logic GA PDFDocument17 pagesTuning Fuzzy Logic GA PDFPham ThuanNo ratings yet
- 8 I January 2020Document9 pages8 I January 2020Shazia147No ratings yet
- Detect Key Genes in Classification of Microarray DataDocument13 pagesDetect Key Genes in Classification of Microarray DataLeo trinhNo ratings yet
- Existence Uniqueness and Synchronization of A Fractional Tum - 2023 - Results IDocument9 pagesExistence Uniqueness and Synchronization of A Fractional Tum - 2023 - Results Ironaldquezada038No ratings yet
- Chi-Square Test of IndependenceDocument15 pagesChi-Square Test of IndependenceMat3xNo ratings yet
- Segmentation of Stock Trading Customers According To Potential ValueDocument7 pagesSegmentation of Stock Trading Customers According To Potential ValueAnonymous RrGVQjNo ratings yet
- A Model Reference Control Structure Using A Fuzzy Neural NetworkDocument22 pagesA Model Reference Control Structure Using A Fuzzy Neural NetworkMitchell Angel Gomez OrtegaNo ratings yet
- Evolving Neural Network Using Real Coded Genetic Algorithm (GA) For Multispectral Image ClassificationDocument13 pagesEvolving Neural Network Using Real Coded Genetic Algorithm (GA) For Multispectral Image Classificationjkl316No ratings yet
- Modeling Cellular Signaling Systems: An Abstraction-Refinement ApproachDocument5 pagesModeling Cellular Signaling Systems: An Abstraction-Refinement ApproachdhermitNo ratings yet
- Matlab Analysis of Eeg Signals For Diagnosis of Epileptic Seizures by Ashwani Singh 117BM0731 Under The Guidance of Prof. Bibhukalyan Prasad NayakDocument29 pagesMatlab Analysis of Eeg Signals For Diagnosis of Epileptic Seizures by Ashwani Singh 117BM0731 Under The Guidance of Prof. Bibhukalyan Prasad NayakAshwani SinghNo ratings yet
- Avalanchas Neuronales BeggsDocument11 pagesAvalanchas Neuronales BeggsSatwant Kaur AssefNo ratings yet
- Multidimensional Data AnalysisDocument24 pagesMultidimensional Data AnalysisNovia WidyaNo ratings yet
- Performance Analysis of Machine Learning Algorithms For Thyroid DiseaseDocument13 pagesPerformance Analysis of Machine Learning Algorithms For Thyroid DiseaseRihab BEN LAMINENo ratings yet
- Optimal Control Applied To ImmunotherapyDocument13 pagesOptimal Control Applied To ImmunotherapyahmatogreNo ratings yet
- MostDocument31 pagesMostannafrolova16.18No ratings yet
- Genetic Optimization Techniques for Sizing and Management of Modern Power SystemsFrom EverandGenetic Optimization Techniques for Sizing and Management of Modern Power SystemsNo ratings yet
- Slide 2Document43 pagesSlide 2erumNo ratings yet
- SWP SlideDocument22 pagesSWP SlideerumNo ratings yet
- FM Slide 1Document20 pagesFM Slide 1erumNo ratings yet
- SlidesDocument45 pagesSlideserumNo ratings yet
- FM Slide2Document15 pagesFM Slide2erumNo ratings yet
- Ti-Nspirecas Guide Part1 en PDFDocument160 pagesTi-Nspirecas Guide Part1 en PDFerumNo ratings yet
- AdaDocument25 pagesAdaabhishekmurthyNo ratings yet
- Ti Nspire CX CasDocument64 pagesTi Nspire CX Casols3d100% (1)
- Research PaperDocument6 pagesResearch PapererumNo ratings yet
- Software Engineering Process in Web Application DevelopmentDocument5 pagesSoftware Engineering Process in Web Application DevelopmentInternational Organization of Scientific Research (IOSR)No ratings yet
- Software Engineering Process in Web Application DevelopmentDocument5 pagesSoftware Engineering Process in Web Application DevelopmentInternational Organization of Scientific Research (IOSR)No ratings yet
- Ti-Nspirecas Ref GuideDocument196 pagesTi-Nspirecas Ref GuideKunal KapurNo ratings yet
- Diagnosis Blood Test For Liver Disease Using Fuzzy LogicDocument33 pagesDiagnosis Blood Test For Liver Disease Using Fuzzy LogicerumNo ratings yet
- The introduction of Uber services: An institutional analysis of market entry timingDocument44 pagesThe introduction of Uber services: An institutional analysis of market entry timingam791130No ratings yet
- On The Analysis and Improvement of Hearing Aid Devices: Diogo Rafael Amado AlmeidaDocument4 pagesOn The Analysis and Improvement of Hearing Aid Devices: Diogo Rafael Amado AlmeidaerumNo ratings yet
- The PersonalityDocument7 pagesThe PersonalityMeris dawatiNo ratings yet
- Strategic ManagementDocument7 pagesStrategic ManagementSarah ShehataNo ratings yet
- PROBLEM 7 - CDDocument4 pagesPROBLEM 7 - CDRavidya ShripatNo ratings yet
- Government of India Sponsored Study on Small Industries Potential in Sultanpur DistrictDocument186 pagesGovernment of India Sponsored Study on Small Industries Potential in Sultanpur DistrictNisar Ahmed Ansari100% (1)
- Materiality of Cultural ConstructionDocument3 pagesMateriality of Cultural ConstructionPaul YeboahNo ratings yet
- Digital Banking in Vietnam: A Guide To MarketDocument20 pagesDigital Banking in Vietnam: A Guide To MarketTrang PhamNo ratings yet
- CRT 48-35L PS EuDocument35 pagesCRT 48-35L PS Eujose alvaradoNo ratings yet
- Otimizar Windows 8Document2 pagesOtimizar Windows 8ClaudioManfioNo ratings yet
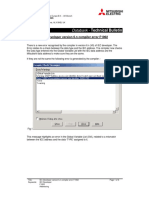
- IEC Developer version 6.n compiler error F1002Document6 pagesIEC Developer version 6.n compiler error F1002AnddyNo ratings yet
- 10.6 Heat Conduction Through Composite WallsDocument35 pages10.6 Heat Conduction Through Composite WallsEngr Muhammad AqibNo ratings yet
- Check List Valve PDFDocument2 pagesCheck List Valve PDFikan100% (1)
- Cegep Linear Algebra ProblemsDocument92 pagesCegep Linear Algebra Problemsham.karimNo ratings yet
- Work Text INGE09: Understanding The SelfDocument24 pagesWork Text INGE09: Understanding The SelfFrancis Dave MabborangNo ratings yet
- Simha Lagna: First House Ruled by The Planet Sun (LEO) : The 1st House Known As The Ascendant orDocument3 pagesSimha Lagna: First House Ruled by The Planet Sun (LEO) : The 1st House Known As The Ascendant orRahulshah1984No ratings yet
- Presentation 5 1Document76 pagesPresentation 5 1Anshul SinghNo ratings yet
- Next Generation Mobile Network PosterDocument1 pageNext Generation Mobile Network PosterTarik Kazaz100% (2)
- PTE - Template - Essay All TypesDocument8 pagesPTE - Template - Essay All TypeskajalNo ratings yet
- Occupational Health and Safety ProceduresDocument20 pagesOccupational Health and Safety ProceduresPRINCESS VILLANo ratings yet
- Registration Confirmation: 315VC18331 Aug 24 2009 7:47PM Devashish Chourasiya 24/05/1989 Mechanical RanchiDocument2 pagesRegistration Confirmation: 315VC18331 Aug 24 2009 7:47PM Devashish Chourasiya 24/05/1989 Mechanical Ranchicalculatorfc101No ratings yet
- .Design and Development of Motorized Multipurpose MachineDocument3 pages.Design and Development of Motorized Multipurpose MachineANKITA MORENo ratings yet
- EagleBurgmann BT-ARP ENDocument4 pagesEagleBurgmann BT-ARP ENMarin PintarićNo ratings yet
- Duobias M 200 TM Section02 Performance SpecificationDocument12 pagesDuobias M 200 TM Section02 Performance SpecificationtonytomsonNo ratings yet
- Latihan Soal ADS Bab 14-16Document1 pageLatihan Soal ADS Bab 14-16nadea06_20679973No ratings yet
- Quick Guide in The Preparation of Purchase Request (PR), Purchase Order (PO) and Other Related DocumentsDocument26 pagesQuick Guide in The Preparation of Purchase Request (PR), Purchase Order (PO) and Other Related DocumentsMiguel VasquezNo ratings yet
- D 4 Development of Beam Equations: M X V XDocument1 pageD 4 Development of Beam Equations: M X V XAHMED SHAKERNo ratings yet
- Worksheet Mendel's LawsDocument3 pagesWorksheet Mendel's LawsAkito NikamuraNo ratings yet
- A Guide For School LeadersDocument28 pagesA Guide For School LeadersIsam Al HassanNo ratings yet
- A Minimal Core Calculus For Java and GJDocument15 pagesA Minimal Core Calculus For Java and GJpostscriptNo ratings yet
- Galvanic CorrosionDocument5 pagesGalvanic Corrosionsatheez3251No ratings yet
- The Future of Power Systems: Challenges, Trends, and Upcoming ParadigmsDocument16 pagesThe Future of Power Systems: Challenges, Trends, and Upcoming ParadigmsAndres ZuñigaNo ratings yet