You might also like
- Hcia DatacomDocument198 pagesHcia DatacomVLAD100% (4)
- Subsetting Data in RDocument44 pagesSubsetting Data in RGoyobodNo ratings yet
- OOP - Attempt ReviewDocument24 pagesOOP - Attempt Reviewno u lmaoNo ratings yet
- Technical Assessment 2Document7 pagesTechnical Assessment 2nishu100% (1)
- CSI 4107 - Winter 2016 - MidtermDocument10 pagesCSI 4107 - Winter 2016 - MidtermAmin Dhouib0% (1)
- Arid Agriculture University, Rawalpindi: Q.No. Marks ObtainedDocument15 pagesArid Agriculture University, Rawalpindi: Q.No. Marks ObtainedmusabNo ratings yet
- COSC2429 Assessment 2 functionsDocument3 pagesCOSC2429 Assessment 2 functionsroll_wititNo ratings yet
- ANZ Virtual Internship Module Model Answer For Task 1Document9 pagesANZ Virtual Internship Module Model Answer For Task 1Lily WangNo ratings yet
- Test Bank CH 06Document13 pagesTest Bank CH 06RalphNo ratings yet
- Exercises 695 ClasDocument3 pagesExercises 695 Clasbenben08No ratings yet
- CANON Pixma Ip3000 Service ManualDocument24 pagesCANON Pixma Ip3000 Service Manualsollers100% (26)
- Atlassian - LeetCodeDocument2 pagesAtlassian - LeetCodeAnujNo ratings yet
- ML Lab Programs (1-12)Document35 pagesML Lab Programs (1-12)Shyam NaiduNo ratings yet
- Cis262 HMMDocument34 pagesCis262 HMMAndrej IlićNo ratings yet
- Assignment 2 OOPDocument3 pagesAssignment 2 OOPTayyaba Rahmat100% (2)
- CS412 Assignment 2 Ref AnswerDocument7 pagesCS412 Assignment 2 Ref AnswerYavuz Sayan86% (7)
- Time Series BasicsDocument21 pagesTime Series BasicsChopra Shubham100% (1)
- CS217 - Object-Oriented Programming (OOP) Assignment # 1: Carefully Read The Following Instructions!Document2 pagesCS217 - Object-Oriented Programming (OOP) Assignment # 1: Carefully Read The Following Instructions!Ahmed AshrafNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionChichi Jnr100% (1)
- ClassDocument40 pagesClassapi-449920999No ratings yet
- Informatics Practices Class 12 Cbse Notes Data HandlingDocument17 pagesInformatics Practices Class 12 Cbse Notes Data Handlingellastark0% (1)
- Android SQLite DatabaseDocument9 pagesAndroid SQLite DatabaseRaj vamsi Srigakulam100% (1)
- 7 Numerical Methods 3 Newton Raphson and Second OrderDocument19 pages7 Numerical Methods 3 Newton Raphson and Second OrderCarl PNo ratings yet
- CSE Dept Doc on Divide and ConquerDocument21 pagesCSE Dept Doc on Divide and Conquermadhu jhaNo ratings yet
- Graphical and Tabular MethodsDocument53 pagesGraphical and Tabular MethodsmarkeuNo ratings yet
- Dbms End Sem ExamDocument2 pagesDbms End Sem ExamSapna MeenaNo ratings yet
- ANDROID APP ARCHITECTUREDocument8 pagesANDROID APP ARCHITECTURENaga HariniNo ratings yet
- Assignment Ivth SemesterDocument17 pagesAssignment Ivth SemesterRohitNo ratings yet
- CS301 Finalterm Subjective 2013 Solved - 2Document16 pagesCS301 Finalterm Subjective 2013 Solved - 2Network Bull100% (2)
- Bagging, BoostingDocument32 pagesBagging, Boostinglassijassi100% (1)
- Lab Manual # 08: Title: Arrays in C++ One D ArrayDocument18 pagesLab Manual # 08: Title: Arrays in C++ One D ArrayUsama SagharNo ratings yet
- Course File Programming and Problem Solving in CDocument10 pagesCourse File Programming and Problem Solving in Cenggeng7No ratings yet
- Operating System Questions and AnswersDocument6 pagesOperating System Questions and Answersgak2627100% (2)
- KING SAUD UNIVERSITY DATABASE DESIGN TUTORIALDocument2 pagesKING SAUD UNIVERSITY DATABASE DESIGN TUTORIALSOMEONENo ratings yet
- DS&CA Lab ManualDocument49 pagesDS&CA Lab Manuallakshmi.sNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Lab Assignment, MCAP 1211, 2019Document3 pagesLab Assignment, MCAP 1211, 2019santanu dharaNo ratings yet
- Assignment - Machine LearningDocument3 pagesAssignment - Machine LearningLe GNo ratings yet
- IP - Pandas 1 & 2 (Worksheet) Class 12Document16 pagesIP - Pandas 1 & 2 (Worksheet) Class 12WhiteNo ratings yet
- 55 Final Paper PDFDocument8 pages55 Final Paper PDFDatta KumarNo ratings yet
- Exp 3 - 6 (A)Document10 pagesExp 3 - 6 (A)Mr MovieNo ratings yet
- Doubly Linked List - Attempt ReviewDocument22 pagesDoubly Linked List - Attempt ReviewJo ChNo ratings yet
- Practice Questions For Quizzes and Midterms - SolutionDocument38 pagesPractice Questions For Quizzes and Midterms - SolutionBrandon KimNo ratings yet
- Greenhouse Monitoring and Control System Based On Wireless Sensor NetworkDocument4 pagesGreenhouse Monitoring and Control System Based On Wireless Sensor NetworkFolkes LaumalNo ratings yet
- Python Data Exploratory CommandsDocument9 pagesPython Data Exploratory CommandsJaya ShankarNo ratings yet
- Online Auction Java Servlet Database ExperimentDocument7 pagesOnline Auction Java Servlet Database ExperimentSaikat DasNo ratings yet
- Daa Lab Manual Kcs553 2022-23Document89 pagesDaa Lab Manual Kcs553 2022-232030195No ratings yet
- Exercise08 SolutionDocument10 pagesExercise08 SolutionCharles ColinNo ratings yet
- Machine Learning Lab Assignment Using Weka Name:: Submitted ToDocument15 pagesMachine Learning Lab Assignment Using Weka Name:: Submitted ToZobahaa HorunkuNo ratings yet
- Java program to generate payslip using inheritanceDocument18 pagesJava program to generate payslip using inheritanceKarthi KarthickNo ratings yet
- ADBMS Parallel and Distributed DatabasesDocument98 pagesADBMS Parallel and Distributed DatabasesTulipNo ratings yet
- C Program To Implement Evaluation of Postfix Expression Using StackDocument2 pagesC Program To Implement Evaluation of Postfix Expression Using StackSaiyasodharan0% (1)
- DS Lab Manual-1Document63 pagesDS Lab Manual-1Amogh SkNo ratings yet
- Computer Concepts and C ProgrammingDocument2 pagesComputer Concepts and C ProgrammingAnser Pasha50% (2)
- SQL Database Programming GuideDocument143 pagesSQL Database Programming GuideSandesh Gupta100% (1)
- Assignment 4 QuestionsDocument5 pagesAssignment 4 QuestionsLavanya_123No ratings yet
- Experiment No 1: 1. Study of Arm Evaluation SystemDocument30 pagesExperiment No 1: 1. Study of Arm Evaluation SystemAshok KumarNo ratings yet
- Daa Question BankDocument13 pagesDaa Question BankKumar ManishNo ratings yet
- Machine Learning Lab ManualDocument30 pagesMachine Learning Lab ManualPriyanka VermaNo ratings yet
- AIML Lab ManualDocument31 pagesAIML Lab ManualEshwar EK67% (3)
- Pattern RecognitionDocument26 pagesPattern RecognitionAryan AttriNo ratings yet
- DNN ALL Practical 28Document34 pagesDNN ALL Practical 284073Himanshu PatleNo ratings yet
- Srishyla Educational Trust Bheemasamudra. Machine Learning Laboratory VII SemesterDocument35 pagesSrishyla Educational Trust Bheemasamudra. Machine Learning Laboratory VII Semestersuharika suharikaNo ratings yet
- Lab 9 GraphDocument9 pagesLab 9 GraphThanh NhànNo ratings yet
- Booth Algo and IEEE 754 CodeDocument7 pagesBooth Algo and IEEE 754 CodeSurjya Kanta prustyNo ratings yet
- Electronic Controllers For Ventilated Refrigeration Units With Electronic Expansion Valve ManagementDocument43 pagesElectronic Controllers For Ventilated Refrigeration Units With Electronic Expansion Valve ManagementEng . Moiead SlemanNo ratings yet
- IP Issues & CyberspaceDocument13 pagesIP Issues & Cyberspace1234tempoNo ratings yet
- How To Mention Promotion On ResumeDocument9 pagesHow To Mention Promotion On Resumeafiwftfbu100% (2)
- Unit 1 PythonDocument38 pagesUnit 1 PythonTrushankNo ratings yet
- Smart City Billing System For Homes Through IotDocument7 pagesSmart City Billing System For Homes Through IotMuhammad AwaisNo ratings yet
- Arcgis Desktop Associate: Exam Information GuideDocument7 pagesArcgis Desktop Associate: Exam Information GuideNELLIE FERNANDEZNo ratings yet
- LogDocument25 pagesLogIntan TaniaNo ratings yet
- Calculus+1+ +limits+ +worksheet+5+ +Limits+Involving+Trig+FunctionsDocument20 pagesCalculus+1+ +limits+ +worksheet+5+ +Limits+Involving+Trig+FunctionsImad H. HalasahNo ratings yet
- Creating A Logical Standby DatabaseDocument5 pagesCreating A Logical Standby DatabaseRajesh BejjenkiNo ratings yet
- M1120 Calculus (IV) LectureDocument11 pagesM1120 Calculus (IV) LectureAuzzie MovinNo ratings yet
- 20221438A AI70 Instruction ManualDocument148 pages20221438A AI70 Instruction ManualCristina Franco100% (1)
- R Datasheet Fi8170Document2 pagesR Datasheet Fi8170comunicacionecuacopiaNo ratings yet
- Artificial Intelligence Engineer BrochureDocument16 pagesArtificial Intelligence Engineer BrochureMadyNo ratings yet
- Varian 240MS InstallationDocument18 pagesVarian 240MS InstallationAndrés SauvêtreNo ratings yet
- Cracking Core Java Interviews Sample PDFDocument51 pagesCracking Core Java Interviews Sample PDFAmit MitraNo ratings yet
- Ex 3-1 Indirect Questions - LVL 5 Ozuna FloresDocument12 pagesEx 3-1 Indirect Questions - LVL 5 Ozuna FloresAbigailNo ratings yet
- Information and Communication Technology: Pearson Edexcel International GCSEDocument24 pagesInformation and Communication Technology: Pearson Edexcel International GCSEEric TTLNo ratings yet
- EZ MAX User Guide PDFDocument72 pagesEZ MAX User Guide PDFJuan UrdanetaNo ratings yet
- SOC Presentation Denver IIADocument28 pagesSOC Presentation Denver IIA44abcNo ratings yet
- Ten Project Proposals in Artificial Intelligence: January 2008Document35 pagesTen Project Proposals in Artificial Intelligence: January 2008Manas MallickNo ratings yet
- Manual Sony MHC-GRX8Document52 pagesManual Sony MHC-GRX8Leandro CaetanoNo ratings yet
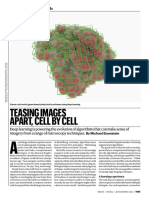
- Teasing Images Apart, Cell by CellDocument3 pagesTeasing Images Apart, Cell by Cellbiomarinium76No ratings yet
- CSS - 05-Module 5.1 - Network DesignDocument5 pagesCSS - 05-Module 5.1 - Network DesignElixa HernandezNo ratings yet
- Howtoearnbitcoinandmining Blogspot ComDocument3 pagesHowtoearnbitcoinandmining Blogspot ComSmall ExperimentsNo ratings yet
- Itns Year 1 T3-Module Dip-01001 Network 11 Introduction To Networks (Version 7.00) - Modules 11 - 13 Ip Addressing Answer All QuestionsDocument25 pagesItns Year 1 T3-Module Dip-01001 Network 11 Introduction To Networks (Version 7.00) - Modules 11 - 13 Ip Addressing Answer All Questionskwasi williamsNo ratings yet