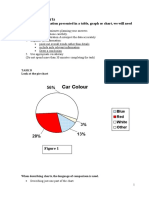
You might also like
- 3.data Summarizing and Presentation PDFDocument34 pages3.data Summarizing and Presentation PDFIoana CroitoriuNo ratings yet
- Cheat Sheet: Tableau-DesktopDocument1 pageCheat Sheet: Tableau-DesktopNitish YadavNo ratings yet
- Application Letter DepedDocument2 pagesApplication Letter DepedHow doyoudoNo ratings yet
- Learn Excel ChartsDocument202 pagesLearn Excel ChartseBooks DPF DownloadNo ratings yet
- LESSON PLAN IN MATHEMATICS IV JemDocument8 pagesLESSON PLAN IN MATHEMATICS IV JemMargie PajaronNo ratings yet
- Normal DistributionDocument43 pagesNormal Distributionkrystel basaNo ratings yet
- Advantages and Disadvantages PicturesDocument3 pagesAdvantages and Disadvantages Picturesapi-29821558555% (11)
- HUMSS - Disciplines and Ideas in The Applied Social Sciences CG - 1Document7 pagesHUMSS - Disciplines and Ideas in The Applied Social Sciences CG - 1Owen Radaza Pirante100% (3)
- Unit4 - DataAnalytics and IoT PDFDocument40 pagesUnit4 - DataAnalytics and IoT PDFrashmiNo ratings yet
- IELTS Bar Chart Sample Essay - IELTS AdvantageDocument7 pagesIELTS Bar Chart Sample Essay - IELTS Advantagedownload meNo ratings yet
- 2023 P2 OCT Math Checkpoint - AnswersDocument10 pages2023 P2 OCT Math Checkpoint - Answersrromar197567% (3)
- SHS Understanding Culture, Society and Politics CGDocument8 pagesSHS Understanding Culture, Society and Politics CGLloyl Yosores Montero65% (23)
- C1S1 Statistics PacketDocument24 pagesC1S1 Statistics PacketPrathyusha KorrapatiNo ratings yet
- Comparing Information (+ writing tasks) - khoa Quản trịDocument4 pagesComparing Information (+ writing tasks) - khoa Quản trịlien nguyenNo ratings yet
- cn4212 1Document35 pagescn4212 1upk civilNo ratings yet
- Summarizing Data: Qualitative Data Quantitative DataDocument19 pagesSummarizing Data: Qualitative Data Quantitative DatacindyNo ratings yet
- Business Statistics For Contemporary Decision Making Canadian 2nd Edition Black Test BankDocument37 pagesBusiness Statistics For Contemporary Decision Making Canadian 2nd Edition Black Test Bankdanielmillerxaernfjmcg100% (13)
- Robability and TatisticsDocument31 pagesRobability and TatisticsVan TranNo ratings yet
- Lecture # 2: Analytical Methods of Data RepresentationDocument27 pagesLecture # 2: Analytical Methods of Data Representationmuhammad aifNo ratings yet
- Business Report MLDocument29 pagesBusiness Report MLVindhya Mounika PatnaikNo ratings yet
- SOB 1040 Lecture 2 - Data Organisation and Descriptive StatisticsDocument113 pagesSOB 1040 Lecture 2 - Data Organisation and Descriptive StatisticsCaroline KapilaNo ratings yet
- Organizing and Graphing DataDocument83 pagesOrganizing and Graphing DataSoNotNo ratings yet
- Descriptive Statistics: Frequency Distributions, Graphs and Data SummarizationDocument47 pagesDescriptive Statistics: Frequency Distributions, Graphs and Data SummarizationAbdu Abdoulaye100% (1)
- Introduction to Error Analysis and PropagationDocument13 pagesIntroduction to Error Analysis and PropagationMaduamaka IhejiamatuNo ratings yet
- IntroductionDocument37 pagesIntroductionzinmarNo ratings yet
- Describing and Interpreting Data: VariableDocument9 pagesDescribing and Interpreting Data: VariableMaruthi MaddipatlaNo ratings yet
- Probability and Statistics for EngineersDocument24 pagesProbability and Statistics for EngineersRaphael Patrick GileraNo ratings yet
- Module 2 Descriptive Statistics Tabular and Graphical PresentationsDocument23 pagesModule 2 Descriptive Statistics Tabular and Graphical PresentationsSophia Angela GarciaNo ratings yet
- Ed242 Lec2a Review DataDocument21 pagesEd242 Lec2a Review DataErikaNo ratings yet
- Chapter 3Document23 pagesChapter 3MomedNo ratings yet
- Dwnload Full Business Statistics For Contemporary Decision Making Canadian 2nd Edition Black Test Bank PDFDocument36 pagesDwnload Full Business Statistics For Contemporary Decision Making Canadian 2nd Edition Black Test Bank PDFmarchellemckethanuk100% (10)
- Lesson 12 - Trees - 2Document14 pagesLesson 12 - Trees - 2Udeshika WanninayakeNo ratings yet
- Graphing - DistributionsDocument25 pagesGraphing - Distributionslemuel sardualNo ratings yet
- Central Tendency MeasuresDocument8 pagesCentral Tendency MeasuresAmer HussainNo ratings yet
- Pitanje 14 PDFDocument48 pagesPitanje 14 PDFAnonymous kpTRbAGeeNo ratings yet
- De La Salle University - Dasmariñas: Mathematics and Statistics DepartmentDocument6 pagesDe La Salle University - Dasmariñas: Mathematics and Statistics DepartmentAxl Arboleda ValiolaNo ratings yet
- Chap 2 Introduction To StatisticsDocument46 pagesChap 2 Introduction To StatisticsAnanthanarayananNo ratings yet
- Biology AtpDocument14 pagesBiology Atpniveditharnair23No ratings yet
- Presentation of DataDocument30 pagesPresentation of DataShahzaib SalmanNo ratings yet
- Lecture-2,3 - Chapter 2 - Organizing and Graphing DataDocument46 pagesLecture-2,3 - Chapter 2 - Organizing and Graphing DataZafar Ibn Kader 2013819030No ratings yet
- Randomized Block DesignDocument8 pagesRandomized Block DesignDhona أزلف AquilaniNo ratings yet
- Error in AdjustmentDocument7 pagesError in AdjustmentOasica NawziNo ratings yet
- BA 1.3 - Descriptive StatisticsDocument70 pagesBA 1.3 - Descriptive StatisticsScarfaceXXXNo ratings yet
- Data Handling Notes and ExercisesDocument16 pagesData Handling Notes and ExercisesRNo ratings yet
- PHY Lab IntroductionDocument30 pagesPHY Lab IntroductionkrittametsupmunNo ratings yet
- L7-093 Understand Dens enDocument11 pagesL7-093 Understand Dens enGoran RadjenovicNo ratings yet
- Goal:: Problem Set #1 10 Points DUE DATE: Saturday Following End of Module 2: Check D2L For Actual Due DateDocument3 pagesGoal:: Problem Set #1 10 Points DUE DATE: Saturday Following End of Module 2: Check D2L For Actual Due DateChaitanya SinglaNo ratings yet
- Problem Set #1 descriptive statsDocument3 pagesProblem Set #1 descriptive statsChaitanya SinglaNo ratings yet
- Goal:: Problem Set #1 10 Points DUE DATE: Saturday Following End of Module 2: Check D2L For Actual Due DateDocument3 pagesGoal:: Problem Set #1 10 Points DUE DATE: Saturday Following End of Module 2: Check D2L For Actual Due DateChaitanya SinglaNo ratings yet
- Business Statistics For Contemporary Decision Making 8th Edition Black Solutions ManualDocument14 pagesBusiness Statistics For Contemporary Decision Making 8th Edition Black Solutions ManualKevinSandovalitre100% (51)
- Tabular Presentation of DataDocument33 pagesTabular Presentation of DataCZARINA JANE ACHUMBRE PACTURANNo ratings yet
- Excel 101Document34 pagesExcel 101Tardoo OrhunduNo ratings yet
- Chap 2 NotesDocument5 pagesChap 2 NotesKaustubh SaksenaNo ratings yet
- Chapter 2 PDFDocument63 pagesChapter 2 PDFSilent ScreamNo ratings yet
- STAT101 Lecture 1Document55 pagesSTAT101 Lecture 1Mpho TsheoleNo ratings yet
- Understanding Frequency DistributionsDocument10 pagesUnderstanding Frequency DistributionsYaziz HasanNo ratings yet
- PS 1 Resubmit FinalDocument16 pagesPS 1 Resubmit FinalAshley PlemmonsNo ratings yet
- "Probability and Statistics (For Engineering) 235 M: Summer Session 2019/2020Document45 pages"Probability and Statistics (For Engineering) 235 M: Summer Session 2019/2020Maram BatayhaNo ratings yet
- Statistics and Probability in EngineeringDocument24 pagesStatistics and Probability in EngineeringasadNo ratings yet
- Charts and GraphsDocument7 pagesCharts and GraphsIrene JavierNo ratings yet
- Udacity Statistics NotesDocument37 pagesUdacity Statistics NotesEm PieNo ratings yet
- GEE 5 Chapter 3 Part 1 NotesDocument18 pagesGEE 5 Chapter 3 Part 1 NotesMadelyn B. LagueNo ratings yet
- Algebra1section9 3Document9 pagesAlgebra1section9 3api-358505269No ratings yet
- Workbook of Simplified Statistics and ProbabilityDocument154 pagesWorkbook of Simplified Statistics and ProbabilityHermawan LesmanaNo ratings yet
- Module 3Document11 pagesModule 3Sayan MajumderNo ratings yet
- Risk Management Principles and Key Risk CategoriesDocument3 pagesRisk Management Principles and Key Risk CategoriesJoe AndrewsNo ratings yet
- Notes Chapter2Document24 pagesNotes Chapter2sundari_muraliNo ratings yet
- R - Lecture #2Document21 pagesR - Lecture #2Nabanita GhoshNo ratings yet
- MM Lab Chi SquareDocument8 pagesMM Lab Chi SquareNixoniaNo ratings yet
- T.O With Application For TransferDocument4 pagesT.O With Application For TransferHow doyoudoNo ratings yet
- Parallel TestDocument4 pagesParallel TestHow doyoudoNo ratings yet
- Personal Data SheetDocument8 pagesPersonal Data SheetHow doyoudoNo ratings yet
- Activity No 2 MayeDocument4 pagesActivity No 2 MayeHow doyoudoNo ratings yet
- Parallel TestDocument4 pagesParallel TestHow doyoudoNo ratings yet
- Revised Personal Data Sheet FormDocument8 pagesRevised Personal Data Sheet FormHow doyoudoNo ratings yet
- Personal Data SheetDocument8 pagesPersonal Data SheetHow doyoudoNo ratings yet
- Omnibus Adrian FinalDocument1 pageOmnibus Adrian FinalHow doyoudoNo ratings yet
- Cert of Passing AdrianDocument1 pageCert of Passing AdrianHow doyoudoNo ratings yet
- Cert of Passing AdrianDocument1 pageCert of Passing AdrianHow doyoudoNo ratings yet
- Vanjo ResumeDocument1 pageVanjo ResumeHow doyoudoNo ratings yet
- Department of EducationDocument1 pageDepartment of EducationHow doyoudoNo ratings yet
- Answer KeyDocument1 pageAnswer KeyAlemor AlviorNo ratings yet
- Filipino dessert Ginataang Halo-haloDocument2 pagesFilipino dessert Ginataang Halo-haloHow doyoudoNo ratings yet
- Pork SinigangDocument2 pagesPork SinigangHow doyoudoNo ratings yet
- Chapter 1Document30 pagesChapter 1How doyoudoNo ratings yet
- Professional Education - Part 4Document5 pagesProfessional Education - Part 4How doyoudoNo ratings yet
- Chapter 3Document31 pagesChapter 3How doyoudoNo ratings yet
- Chapter 4: Describing The Relationship Between Two VariablesDocument27 pagesChapter 4: Describing The Relationship Between Two VariablesHow doyoudoNo ratings yet
- DepEd Order No. 3 Series 2016Document32 pagesDepEd Order No. 3 Series 2016Trevor Selwyn100% (1)
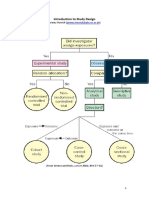
- CEBM Study Design April 20131 PDFDocument4 pagesCEBM Study Design April 20131 PDFThalia KarampasiNo ratings yet
- 2 GEN ED 1999 Teachers Always Remind Us That Time Is GoldDocument11 pages2 GEN ED 1999 Teachers Always Remind Us That Time Is GoldLeih Anne Quezon AnonuevoNo ratings yet
- Hoofdstuk 2.2Document18 pagesHoofdstuk 2.2anoniemf8No ratings yet
- Topic 10 - Descriptive Statistics NotesDocument62 pagesTopic 10 - Descriptive Statistics NotesDahlia RamirezNo ratings yet
- Charts and GraphsDocument7 pagesCharts and GraphsIrene JavierNo ratings yet
- Pareto 80:20 RuleDocument24 pagesPareto 80:20 RuleMuhammad Saleem BuluNo ratings yet
- LS-3-Math And-Prob Sol SkillsDocument11 pagesLS-3-Math And-Prob Sol SkillsJuvilla BatrinaNo ratings yet
- Instructional MediaDocument8 pagesInstructional MediaKurnia Ika P0% (1)
- Statistics PresentationDocument21 pagesStatistics PresentationkaylaNo ratings yet
- Types of Graphs ExplainedDocument26 pagesTypes of Graphs ExplainedKlaribelle VillaceranNo ratings yet
- Stacked Bar Graph StataDocument30 pagesStacked Bar Graph Stataallison100% (1)
- Inquiries, Investigation, and Immersion Quarter 4: Module 3Document3 pagesInquiries, Investigation, and Immersion Quarter 4: Module 3Sheena CadagNo ratings yet
- Awesome Charts Documentation: Table of ContentDocument22 pagesAwesome Charts Documentation: Table of ContentSTANLEY DROID MONIES KeYlsoNo ratings yet
- Sample Theory & Que. - UGC NET GP-1 Data Interpretation (UNIT-7)Document23 pagesSample Theory & Que. - UGC NET GP-1 Data Interpretation (UNIT-7)Harsh Vardhan Singh Hvs100% (1)
- M&M MathDocument9 pagesM&M Mathapi-283989564No ratings yet
- Research Unit 5 BbaDocument17 pagesResearch Unit 5 Bbayash soniNo ratings yet
- Topic 5 Communicating Visually Through Graphics: Fia 1383: Business CommunicationDocument35 pagesTopic 5 Communicating Visually Through Graphics: Fia 1383: Business CommunicationroomNo ratings yet
- INTRO TO REPORT WRITINGDocument16 pagesINTRO TO REPORT WRITINGlinhNo ratings yet
- EFAPP Q2 M 78-And-9Document42 pagesEFAPP Q2 M 78-And-9Michael Joshua Lesiguez0% (1)
- File 2 Chapter 1 Data Representation Techniques PDFDocument32 pagesFile 2 Chapter 1 Data Representation Techniques PDFPraise Nehumambi100% (1)
- 3 Graphical Methods For Describing DataDocument46 pages3 Graphical Methods For Describing DataIT GAMINGNo ratings yet
- Tabular and Graphical Presentation Using Excel: 2.1 Summarizing Categorical DataDocument15 pagesTabular and Graphical Presentation Using Excel: 2.1 Summarizing Categorical DataAnna TaylorNo ratings yet
- Graphic Organizers FinalDocument45 pagesGraphic Organizers FinalPhilip Anthony Marcos Cabato0% (1)
- QTM StatisticsDocument17 pagesQTM StatisticsBasit MominNo ratings yet
- SBA Statistics Graduation RatesDocument14 pagesSBA Statistics Graduation RatesMalikiNo ratings yet