You might also like
- FDBMSDocument26 pagesFDBMSsurendraNo ratings yet
- Dbms Lab File - KitDocument70 pagesDbms Lab File - Kitpthepronab57% (7)
- 40572a Microsoft Access Expert 2019 EbookDocument546 pages40572a Microsoft Access Expert 2019 EbookDaniel FloreaNo ratings yet
- DBMS Notes by DinudineshDocument18 pagesDBMS Notes by DinudineshBhargav NaiduNo ratings yet
- Gartner - Adopt Data Virtualization To Improve AgilityDocument16 pagesGartner - Adopt Data Virtualization To Improve AgilityGus Barrera RodriguezNo ratings yet
- BSC CsIt Complete RDBMS NotesDocument86 pagesBSC CsIt Complete RDBMS NotesNilesh GoteNo ratings yet
- Dbms Important QuestionDocument4 pagesDbms Important QuestionpthepronabNo ratings yet
- Concurrency Control DBMSDocument12 pagesConcurrency Control DBMSpthepronabNo ratings yet
- Unit 1 - Database Management Systems - WWW - Rgpvnotes.inDocument21 pagesUnit 1 - Database Management Systems - WWW - Rgpvnotes.inZyter MathuNo ratings yet
- E Notes PDF All UnitsDocument129 pagesE Notes PDF All Unitsshreya sorathiaNo ratings yet
- Ankit Sir All Units DbmsDocument142 pagesAnkit Sir All Units Dbmssageranimesh20100% (1)
- DBMS - QUESTION BANK With Answer TIEDocument56 pagesDBMS - QUESTION BANK With Answer TIESushmith Shettigar100% (3)
- Oracle GoldenGate Heterogeneous MySQL-ORACLEDocument59 pagesOracle GoldenGate Heterogeneous MySQL-ORACLESyed NoumanNo ratings yet
- Unit 1Document11 pagesUnit 1Anand GuptaNo ratings yet
- Unit1 CSEDocument16 pagesUnit1 CSEShagun PandeyNo ratings yet
- Introduction To Database SystemDocument12 pagesIntroduction To Database SystemJulfikar asifNo ratings yet
- Rdbms (Unit 1)Document13 pagesRdbms (Unit 1)hari karanNo ratings yet
- Introduction To Database Management System-NotesDocument46 pagesIntroduction To Database Management System-Notesdurgagarg10051998No ratings yet
- DBDM 16 Marks All 5 UnitsDocument74 pagesDBDM 16 Marks All 5 Unitsathirayan85No ratings yet
- Database Management SystemDocument31 pagesDatabase Management SystemAman SinghNo ratings yet
- Syllabus Data Base Management System: Unit-IDocument64 pagesSyllabus Data Base Management System: Unit-IAnonymous 26fLU3lNo ratings yet
- Introduction To Database Management SystemDocument47 pagesIntroduction To Database Management SystemjisskuruvillaNo ratings yet
- 1 IntroductionDocument87 pages1 IntroductionAnu SreeNo ratings yet
- DBMS Lec 1 + 2Document22 pagesDBMS Lec 1 + 2معتز العجيليNo ratings yet
- 1 - Introductory Concepts of DBMS: Define The Following TermsDocument133 pages1 - Introductory Concepts of DBMS: Define The Following Termsronaldo magarNo ratings yet
- Q Define Database, Data, DBMS, State Purpose of DatabaseDocument20 pagesQ Define Database, Data, DBMS, State Purpose of Databasenaresh sainiNo ratings yet
- Database Management: 1 - Computer ApplicationsDocument7 pagesDatabase Management: 1 - Computer ApplicationsTino AlappatNo ratings yet
- RDBMS Unit1Document15 pagesRDBMS Unit1maniking9346No ratings yet
- Unit-1 Introduction: Define The Following TermsDocument10 pagesUnit-1 Introduction: Define The Following TermsVirat KohliNo ratings yet
- Dbms 16 Marks - All 5 UnitsDocument88 pagesDbms 16 Marks - All 5 Unitssabarish00165% (20)
- DBMS NotesDocument43 pagesDBMS Notesjitendrabudholiya620No ratings yet
- DBMS Class1Document15 pagesDBMS Class1sangeetha sheelaNo ratings yet
- DBMS GTU Study Material E-Notes All-Units 17102019083450AMDocument142 pagesDBMS GTU Study Material E-Notes All-Units 17102019083450AMrambabuNo ratings yet
- Unit - 1 Introduction To Database Management SystemDocument20 pagesUnit - 1 Introduction To Database Management Systemhabib0999No ratings yet
- Unit-01 IntroductionDocument7 pagesUnit-01 IntroductionJINESH VARIANo ratings yet
- DBMS Notes - All UnitsDocument77 pagesDBMS Notes - All UnitsvibhavariNo ratings yet
- Unit 1Document21 pagesUnit 123mca006No ratings yet
- Networking IntroductionDocument29 pagesNetworking IntroductionParomita BiswasNo ratings yet
- Chapter 1 Introduction To DatabasesDocument53 pagesChapter 1 Introduction To Databasescharlesochen247No ratings yet
- S. K. Mishra: Lecturer (Information Technology), Institute of Management Sciences, University of Lucknow, LucknowDocument15 pagesS. K. Mishra: Lecturer (Information Technology), Institute of Management Sciences, University of Lucknow, Lucknowshalini20aprNo ratings yet
- UNIT-1 - Chapter 1: What Is A Database?Document13 pagesUNIT-1 - Chapter 1: What Is A Database?sri krishna sai kotaNo ratings yet
- Module - 1Document9 pagesModule - 1Yash Pathak YpNo ratings yet
- Intro To DBMSDocument22 pagesIntro To DBMSapi-27570914100% (1)
- RDBMS Unit IDocument40 pagesRDBMS Unit IrogithaNo ratings yet
- Rdbms Unit IDocument38 pagesRdbms Unit IrogithaNo ratings yet
- Unit 1Document26 pagesUnit 1skmatankiNo ratings yet
- CS6302 Notes PDFDocument126 pagesCS6302 Notes PDFrewop sriNo ratings yet
- Chapter 1 Introduction To DBMS PDFDocument6 pagesChapter 1 Introduction To DBMS PDFVidhyaNo ratings yet
- Dbms 2013 DemoDocument90 pagesDbms 2013 DemoVivek VishwakarmaNo ratings yet
- Module 1Document23 pagesModule 1SHABNAM SNo ratings yet
- CS502 DBMS Notes Unit 1Document19 pagesCS502 DBMS Notes Unit 1Yadu PatidarNo ratings yet
- Dbms 1&2Document15 pagesDbms 1&2aswinsai615No ratings yet
- Relational Database Management System : Co/Cm/If 3GDocument209 pagesRelational Database Management System : Co/Cm/If 3GHET JOSHINo ratings yet
- Relational Database Management System NoDocument209 pagesRelational Database Management System NoHemant ThawaniNo ratings yet
- Data Base Management SystemDocument30 pagesData Base Management SystemHrithick BhowmickNo ratings yet
- DBMS Unit 1Document58 pagesDBMS Unit 1MeeraNo ratings yet
- 1 8 Database and Data ModellingDocument6 pages1 8 Database and Data ModellingnelisappawandiwaNo ratings yet
- Unit-I Notes DBMSDocument34 pagesUnit-I Notes DBMSYugi YuguNo ratings yet
- Introduction To Database and Its EnvironmentDocument70 pagesIntroduction To Database and Its Environmentvivianchepngetich21No ratings yet
- Complete Dbms NotesDocument138 pagesComplete Dbms NotesSanjeev KumarNo ratings yet
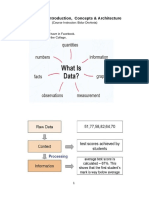
- Database: Introduction, Concepts & ArchitectureDocument32 pagesDatabase: Introduction, Concepts & ArchitectureKapil PokhrelNo ratings yet
- DBMS Part - B Q&a PDFDocument88 pagesDBMS Part - B Q&a PDFSatthiraj SatthiNo ratings yet
- Introduction To Database ConceptsDocument64 pagesIntroduction To Database ConceptsFauzil 'AzimNo ratings yet
- THE SQL LANGUAGE: Master Database Management and Unlock the Power of Data (2024 Beginner's Guide)From EverandTHE SQL LANGUAGE: Master Database Management and Unlock the Power of Data (2024 Beginner's Guide)No ratings yet
- Assignment 2 DbmsDocument2 pagesAssignment 2 DbmspthepronabNo ratings yet
- Rcs 501 2018 19Document2 pagesRcs 501 2018 19pthepronabNo ratings yet
- Course FileDocument6 pagesCourse FilepthepronabNo ratings yet
- Data Abstraction and Data IndependenceDocument1 pageData Abstraction and Data IndependencepthepronabNo ratings yet
- RCS-501-Database Management Systems: Course ObjectivesDocument1 pageRCS-501-Database Management Systems: Course ObjectivespthepronabNo ratings yet
- DBMS Architecture 2-Level, 3-Level: Two Tier Architecture: Client-ServerDocument1 pageDBMS Architecture 2-Level, 3-Level: Two Tier Architecture: Client-ServerpthepronabNo ratings yet
- ACID Properties: AtomicityDocument2 pagesACID Properties: AtomicitypthepronabNo ratings yet
- LexprogsDocument9 pagesLexprogspthepronabNo ratings yet
- DBMS Architecture 2-Level, 3-Level: Two Tier Architecture: Client-ServerDocument2 pagesDBMS Architecture 2-Level, 3-Level: Two Tier Architecture: Client-ServerpthepronabNo ratings yet
- Synchronous and Asynchronous TransmissionDocument3 pagesSynchronous and Asynchronous Transmissionpthepronab0% (1)
- 4 Sol RelAlgDocument4 pages4 Sol RelAlgpthepronabNo ratings yet
- Turban Dss9e Tif Ch03Document12 pagesTurban Dss9e Tif Ch03Ahmed HamdyNo ratings yet
- Database Programming With SQL 4-1: Case and Character Manipulation Practice ActivitiesDocument3 pagesDatabase Programming With SQL 4-1: Case and Character Manipulation Practice ActivitiesFlorin CatalinNo ratings yet
- MAA - Creating Single Instance Physical Standby For A RAC Primary - 12cDocument18 pagesMAA - Creating Single Instance Physical Standby For A RAC Primary - 12cSamNo ratings yet
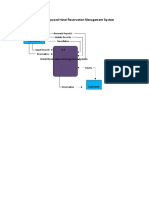
- Context Diagram of Proposed Hotel Reservation Management SystemDocument8 pagesContext Diagram of Proposed Hotel Reservation Management SystemJoffrey Montalla67% (3)
- Bhaskar ReddyDocument7 pagesBhaskar Reddyabreddy2003No ratings yet
- Visual Basic Part 4 Studocu PDFDocument42 pagesVisual Basic Part 4 Studocu PDFManoj BENo ratings yet
- Lab 6: Views and SQL FunctionsDocument24 pagesLab 6: Views and SQL FunctionsZeenat SiddiqNo ratings yet
- Implementing IoT Concepts With PythonDocument6 pagesImplementing IoT Concepts With PythonGostudy LifeNo ratings yet
- Data Connection and Manipulation of Archaeological Database Created in Visual EnvironmentDocument9 pagesData Connection and Manipulation of Archaeological Database Created in Visual EnvironmentCarmen PodemNo ratings yet
- Data WarehousingDocument7 pagesData WarehousingSajakul SornNo ratings yet
- JLAN Server Installation GuideDocument49 pagesJLAN Server Installation GuideCodiusNo ratings yet
- IT223 Advance Database System Course Pack Module 4Document21 pagesIT223 Advance Database System Course Pack Module 4Clarissa SottoNo ratings yet
- Big Data Analytics: By: Syed Nawaz Pasha at SR Univeristy Professional Elective-5 B.Tech Iv-Ii SemDocument31 pagesBig Data Analytics: By: Syed Nawaz Pasha at SR Univeristy Professional Elective-5 B.Tech Iv-Ii SemShushanth munna100% (1)
- Cim QuestionsDocument3 pagesCim QuestionsHimanshu MishraNo ratings yet
- Ms SQL CommandDocument19 pagesMs SQL Commandjoneil dulaNo ratings yet
- Dbms (Cse201) Theory Notes: Primary KeyDocument18 pagesDbms (Cse201) Theory Notes: Primary KeyAakash JainNo ratings yet
- Pyspark MCQDocument3 pagesPyspark MCQEren LeviNo ratings yet
- Dbms NotesDocument2 pagesDbms NotesAyushman SinghNo ratings yet
- 1.1 Ims/VsDocument45 pages1.1 Ims/VsbhaskarNo ratings yet
- What Is A Database Management System (Or DBMS) ?: SoftwareDocument2 pagesWhat Is A Database Management System (Or DBMS) ?: SoftwareMerad HassanNo ratings yet
- Best Practices For Oracle On HPUX: Sandy Gruver Senior Technical Consultant HP/Oracle Advanced Technology CenterDocument108 pagesBest Practices For Oracle On HPUX: Sandy Gruver Senior Technical Consultant HP/Oracle Advanced Technology CenterEricSaubignacNo ratings yet
- Introduction To DBMSDocument37 pagesIntroduction To DBMSKIRUTHIKA KNo ratings yet
- Build Reports For Finance and Operations AppsDocument2 pagesBuild Reports For Finance and Operations AppsJackNo ratings yet
- User Manual: R&S Contest Advanced User ProceduresDocument103 pagesUser Manual: R&S Contest Advanced User ProceduresAshish GuptaNo ratings yet
- Computer Practical Class 12 by - ManishDocument40 pagesComputer Practical Class 12 by - Manishgamingmsop5No ratings yet
- Actional 8.2.1 Release NotesDocument14 pagesActional 8.2.1 Release NotesMarcio ConceicaoNo ratings yet
- CHANNELSTOTHEFUTUREDocument7 pagesCHANNELSTOTHEFUTUREClaudia StylesNo ratings yet