You might also like
- Dam Project ReportDocument35 pagesDam Project ReportMuhammad SardaarNo ratings yet
- Advance DatabaseDocument14 pagesAdvance DatabaseInformation TechnologyNo ratings yet
- DBA Interview Questions With Answers Part1Document134 pagesDBA Interview Questions With Answers Part1RajeshRajNo ratings yet
- DBA Interview Questions With Answers Part1Document134 pagesDBA Interview Questions With Answers Part1RajeshRaj100% (1)
- DBA Interview Questions With AnswersDocument104 pagesDBA Interview Questions With AnswersBirendra Padhi67% (3)
- DBA Interview Common Alert Log ErrorsDocument118 pagesDBA Interview Common Alert Log ErrorsAnil DevNo ratings yet
- Troubleshooting - Using LOGDUMPDocument6 pagesTroubleshooting - Using LOGDUMPsuresh463765No ratings yet
- Top 10 SQL Server DBA Daily Checks v2 - 1 - by - SQLNetHubDocument5 pagesTop 10 SQL Server DBA Daily Checks v2 - 1 - by - SQLNetHubLaddu BujjiNo ratings yet
- Step by Step Golden GateDocument27 pagesStep by Step Golden GatebillNo ratings yet
- DBA Interview Questions With Answers Part8Document13 pagesDBA Interview Questions With Answers Part8anu224149No ratings yet
- Database tuning tips and tricks for SQL ServerDocument4 pagesDatabase tuning tips and tricks for SQL ServerAshok kumarNo ratings yet
- Oracle DBA Interview PERFORMANCE TUNING Question-1Document7 pagesOracle DBA Interview PERFORMANCE TUNING Question-1RahumassNo ratings yet
- Oracle ASM StuffDocument6 pagesOracle ASM Stuffdbareddy100% (1)
- How To Recreate The Control File On 10gR2 RAC With ASM and Data GuardDocument11 pagesHow To Recreate The Control File On 10gR2 RAC With ASM and Data GuardBhupinder SinghNo ratings yet
- BCQuestionDocument12 pagesBCQuestionRamesh NatarajanNo ratings yet
- Oe InterviewDocument51 pagesOe InterviewnareshNo ratings yet
- Best Practise For EbsDocument30 pagesBest Practise For EbshemalrohaNo ratings yet
- Security Real-Time Data Auditing With Extended Oracle Change Data CaptureDocument6 pagesSecurity Real-Time Data Auditing With Extended Oracle Change Data CapturelbrittobaNo ratings yet
- ORACLE DBA Activity ChecklistDocument23 pagesORACLE DBA Activity ChecklistVimlendu Kumar71% (17)
- Performance Tunning StepsDocument11 pagesPerformance Tunning StepsVinu3012No ratings yet
- AWR INTERPRETATIONDocument17 pagesAWR INTERPRETATIONPraveen KumarNo ratings yet
- Tracing Bind Variables and Waits 20000507Document5 pagesTracing Bind Variables and Waits 20000507José Laurindo ChiappaNo ratings yet
- 9i RAC: Cloning To A Single Instance: Shankar GovindanDocument12 pages9i RAC: Cloning To A Single Instance: Shankar GovindanPedro Tablas SanchezNo ratings yet
- View SAP Directories AL11Document8 pagesView SAP Directories AL11Charan ReddyNo ratings yet
- PR Oracle TraceDocument4 pagesPR Oracle TraceRavi ChandarNo ratings yet
- SP01 - Spool Request Screen - Check For Spool That Are in Request For Over An HourDocument21 pagesSP01 - Spool Request Screen - Check For Spool That Are in Request For Over An HourdeepakNo ratings yet
- New Updated Oracle 10g DBA interview questions and answers on database administration conceptsDocument42 pagesNew Updated Oracle 10g DBA interview questions and answers on database administration conceptsPrema LingamNo ratings yet
- Oracle 10g Dataguard Best Practice and Setup StepsDocument6 pagesOracle 10g Dataguard Best Practice and Setup Stepsborra venkateshNo ratings yet
- Resize Standby Datafile If Disk Runs Out of Space On Standby SiteDocument8 pagesResize Standby Datafile If Disk Runs Out of Space On Standby SitePraveenNo ratings yet
- Starting The ServerDocument5 pagesStarting The ServerAkif KhanNo ratings yet
- Sapinterview QuesDocument5 pagesSapinterview Quessatya1207No ratings yet
- SQL Structured Query LanguageDocument7 pagesSQL Structured Query Languagemanojprabhakar_mNo ratings yet
- Configure Dataguard 11gr2 Physical Standby Part Ii1Document13 pagesConfigure Dataguard 11gr2 Physical Standby Part Ii1gurwinder_saini2003No ratings yet
- DB12c Tuning New Features Alex Zaballa PDFDocument82 pagesDB12c Tuning New Features Alex Zaballa PDFGanesh KaralkarNo ratings yet
- Data Stage ETL QuestionDocument11 pagesData Stage ETL Questionrameshgrb2000No ratings yet
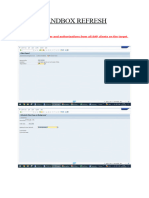
- Sandbox RefreshDocument24 pagesSandbox Refreshsravanthimanoj2013No ratings yet
- Restore / Clone of A Database With A Different Name On The Same ServerDocument34 pagesRestore / Clone of A Database With A Different Name On The Same ServeraasishNo ratings yet
- Technical White Paper Oracle9I Logminer™Document22 pagesTechnical White Paper Oracle9I Logminer™elcaso34No ratings yet
- Daily Check ListDocument40 pagesDaily Check ListVamshi Krishna DaravathNo ratings yet
- Daily Check List SummaryDocument40 pagesDaily Check List SummaryVamshi Krishna DaravathNo ratings yet
- QuestionaireDocument106 pagesQuestionairevenkatsainath06No ratings yet
- DBA ScriptsDocument25 pagesDBA Scriptschavandilip100% (2)
- UntitledDocument39 pagesUntitledJoe RodriguezNo ratings yet
- Generating SQL Trace FilesDocument24 pagesGenerating SQL Trace FilesramaniqbalNo ratings yet
- DBA Genesis - Oracle DBA ScriptsDocument35 pagesDBA Genesis - Oracle DBA ScriptsKamaldeep Nainwal60% (5)
- Diagnosis For DB HungDocument5 pagesDiagnosis For DB Hungnu04330No ratings yet
- How To Add or Extend Datafiles in Sap System Based On Oracle Database ?Document22 pagesHow To Add or Extend Datafiles in Sap System Based On Oracle Database ?Abdul27No ratings yet
- Chapter 1 TransactionDocument28 pagesChapter 1 TransactionKumkumo Kussia KossaNo ratings yet
- Daily WorkDocument68 pagesDaily Workapi-3819698No ratings yet
- Database Refresh ProcedureDocument55 pagesDatabase Refresh Proceduredebojoti100% (1)
- MVS JCL Utilities Quick Reference, Third EditionFrom EverandMVS JCL Utilities Quick Reference, Third EditionRating: 5 out of 5 stars5/5 (1)
- Monitoring Informix Dynamic Server For Higher PerformanceDocument14 pagesMonitoring Informix Dynamic Server For Higher PerformanceAhmed Yamil Chadid EstradaNo ratings yet
- Common Issues in DatastageDocument12 pagesCommon Issues in Datastagesunipulicherla100% (1)
- Starting Database Administration: Oracle DBAFrom EverandStarting Database Administration: Oracle DBARating: 3 out of 5 stars3/5 (2)
- CCNA Day1Document199 pagesCCNA Day1stars7771No ratings yet
- MPL Assignmnts QuesitionsDocument1 pageMPL Assignmnts QuesitionsMuhammad Khubaib0% (1)
- Design Document: Garment Sale and Stitching MasterDocument29 pagesDesign Document: Garment Sale and Stitching MasterMuhammad KhubaibNo ratings yet
- Design Document: Effective Beauty and Health RemediesDocument19 pagesDesign Document: Effective Beauty and Health RemediesMuhammad KhubaibNo ratings yet
- Cloth ManagementDocument29 pagesCloth ManagementMuhammad KhubaibNo ratings yet
- Design Document: Garment Sale and Stitching MasterDocument29 pagesDesign Document: Garment Sale and Stitching MasterMuhammad KhubaibNo ratings yet
- Design Document: Garment Sale and Stitching MasterDocument29 pagesDesign Document: Garment Sale and Stitching MasterMuhammad KhubaibNo ratings yet
- World's Largest Science, Technology & Medicine Open Access Book PublisherDocument19 pagesWorld's Largest Science, Technology & Medicine Open Access Book PublisherMuhammad KhubaibNo ratings yet
- World's Largest Science, Technology & Medicine Open Access Book PublisherDocument23 pagesWorld's Largest Science, Technology & Medicine Open Access Book PublisherMuhammad KhubaibNo ratings yet
- World's Largest Science, Technology & Medicine Open Access Book PublisherDocument25 pagesWorld's Largest Science, Technology & Medicine Open Access Book PublisherDeepaNo ratings yet
- Cyber Security Strategy enDocument58 pagesCyber Security Strategy enArief PrihantoroNo ratings yet
- Server Administration & MaintenanceDocument8 pagesServer Administration & Maintenancemrvoodoo67No ratings yet
- HP eIUMDocument250 pagesHP eIUMFerFaustoNo ratings yet
- QlikView Server Reference Manual PDFDocument120 pagesQlikView Server Reference Manual PDFDENILSONFNNo ratings yet
- Drive Test InvestigationDocument28 pagesDrive Test InvestigationRatha Sroy100% (2)
- FAQ 013736 01 Syngistix For AA ICP Enhanced Security Software PDFDocument4 pagesFAQ 013736 01 Syngistix For AA ICP Enhanced Security Software PDFOuanzar KadaNo ratings yet
- Fdi - Maitaining Redo Log FilesDocument5 pagesFdi - Maitaining Redo Log FileslonodovoNo ratings yet
- B DSM Guide PDFDocument230 pagesB DSM Guide PDFmohamed saadNo ratings yet
- Resolve NetBackup Status 249 error by adjusting timeout thresholdDocument2 pagesResolve NetBackup Status 249 error by adjusting timeout thresholdsubhrajitm47No ratings yet
- TeamForge5.2 System Administrator GuideDocument82 pagesTeamForge5.2 System Administrator GuideLeandro ArgeNo ratings yet
- ReadmeDocument9 pagesReadmeZaenalAbidinNo ratings yet
- NSE5 FAZ-6.2 48Qs 9 - 22Document15 pagesNSE5 FAZ-6.2 48Qs 9 - 22Roberto Enriquez Delgadillo100% (1)
- 21 11 VPC Si Sys AdminDocument582 pages21 11 VPC Si Sys Admindubeyalok.rmNo ratings yet
- Troubleshooting GuideDocument708 pagesTroubleshooting GuideanonNo ratings yet
- AdadminsrvctlDocument40 pagesAdadminsrvctlTsdfsd YfgdfgNo ratings yet
- DataPower ServicePlanning Implementation BestPracticesDocument160 pagesDataPower ServicePlanning Implementation BestPracticesDaniel Bharathy DinakaranNo ratings yet
- ReweDocument2 pagesRewekiran869No ratings yet
- Ibm Datapower Gateway V7.6 Solution Implementation Sample TestDocument4 pagesIbm Datapower Gateway V7.6 Solution Implementation Sample TestAnudeep PolamarasettyNo ratings yet
- Bioadmin Revision Notes: © 2008 by Suprema IncDocument12 pagesBioadmin Revision Notes: © 2008 by Suprema IncleninNo ratings yet
- Sybase 12 Install InstructionsDocument29 pagesSybase 12 Install InstructionsJohn ThorntonNo ratings yet
- 2.1-2.9 Batch RobustnessDocument32 pages2.1-2.9 Batch RobustnessElson Tan100% (1)
- Manipulating Oracle Files With UTLDocument10 pagesManipulating Oracle Files With UTLSandeep KavuriNo ratings yet
- QCATDocument6 pagesQCATSunil Joseph Chunkapura75% (4)
- LogMan II. Reefer Container Monitoring. Users Manual. Transportation SolutionsDocument25 pagesLogMan II. Reefer Container Monitoring. Users Manual. Transportation SolutionsPedro BancayanNo ratings yet
- Dataguatd IssuesDocument2 pagesDataguatd Issuesshaikali1980No ratings yet
- All SAP Security TCodesDocument4 pagesAll SAP Security TCodessmadhu324No ratings yet
- Status Code 42Document3 pagesStatus Code 42NavneetMishraNo ratings yet
- RTMT CucmDocument204 pagesRTMT Cucmyusufali2011No ratings yet
- Tems Investigation - Drive TestDocument17 pagesTems Investigation - Drive TestfarhadfzmNo ratings yet
- EDRMedeso Bolt Toolkit V192.12Document38 pagesEDRMedeso Bolt Toolkit V192.12Joshua KarthikNo ratings yet
- SAP BASIS Quick Troubleshooting Guide 2013Document86 pagesSAP BASIS Quick Troubleshooting Guide 2013manikandanNo ratings yet