You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Book TurmericDocument14 pagesBook Turmericarvind3041990100% (2)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Pilapil v. CADocument2 pagesPilapil v. CAIris Gallardo100% (2)
- Introduction To Astronomical PhotometryDocument452 pagesIntroduction To Astronomical PhotometrySergio Alejandro Fuentealba ZuñigaNo ratings yet
- UXBenchmarking 101Document42 pagesUXBenchmarking 101Rodrigo BucketbranchNo ratings yet
- Name: Nur Hashikin Binti Ramly (2019170773) Course Code: Udm713 - Decision Making Methods and Analysis Assignment Title: Need Gap AnalysisDocument2 pagesName: Nur Hashikin Binti Ramly (2019170773) Course Code: Udm713 - Decision Making Methods and Analysis Assignment Title: Need Gap AnalysisAhmad HafizNo ratings yet
- Emma The Easter BunnyDocument9 pagesEmma The Easter BunnymagdaNo ratings yet
- Internal Rules of Procedure Sangguniang BarangayDocument37 pagesInternal Rules of Procedure Sangguniang Barangayhearty sianenNo ratings yet
- Newspaper OrganisationDocument20 pagesNewspaper OrganisationKcite91100% (5)
- Iii. The Impact of Information Technology: Successful Communication - Key Points To RememberDocument7 pagesIii. The Impact of Information Technology: Successful Communication - Key Points To Remembermariami bubuNo ratings yet
- Commercial Private Equity Announces A Three-Level Loan Program and Customized Financing Options, Helping Clients Close Commercial Real Estate Purchases in A Few DaysDocument4 pagesCommercial Private Equity Announces A Three-Level Loan Program and Customized Financing Options, Helping Clients Close Commercial Real Estate Purchases in A Few DaysPR.comNo ratings yet
- New Kanban System DesignDocument4 pagesNew Kanban System DesignJebin GeorgeNo ratings yet
- Brahm Dutt v. UoiDocument3 pagesBrahm Dutt v. Uoiswati mohapatraNo ratings yet
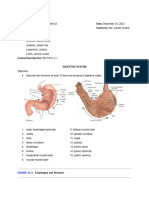
- Digestive System LabsheetDocument4 pagesDigestive System LabsheetKATHLEEN MAE HERMONo ratings yet
- 1 Piling LaranganDocument3 pages1 Piling LaranganHannie Jane Salazar HerreraNo ratings yet
- Damodaram Sanjivayya National Law University VisakhapatnamDocument6 pagesDamodaram Sanjivayya National Law University VisakhapatnamSuvedhya ReddyNo ratings yet
- AI in HealthDocument105 pagesAI in HealthxenoachNo ratings yet
- Cabot - Conductive Carbon Black For Use in Acrylic and Epoxy CoatingsDocument2 pagesCabot - Conductive Carbon Black For Use in Acrylic and Epoxy CoatingsLin Niu0% (1)
- Phylogenetic Tree: GlossaryDocument7 pagesPhylogenetic Tree: GlossarySab ka bada FanNo ratings yet
- Georgia Jean Weckler 070217Document223 pagesGeorgia Jean Weckler 070217api-290747380No ratings yet
- Prof. Monzer KahfDocument15 pagesProf. Monzer KahfAbdulNo ratings yet
- Circular No 02 2014 TA DA 010115 PDFDocument10 pagesCircular No 02 2014 TA DA 010115 PDFsachin sonawane100% (1)
- English 10-Dll-Week 3Document5 pagesEnglish 10-Dll-Week 3Alyssa Grace Dela TorreNo ratings yet
- Result 1st Entry Test Held On 22-08-2021Document476 pagesResult 1st Entry Test Held On 22-08-2021AsifRiazNo ratings yet
- Fix Problems in Windows SearchDocument2 pagesFix Problems in Windows SearchSabah SalihNo ratings yet
- Chemical BondingDocument7 pagesChemical BondingSanaa SamkoNo ratings yet
- German Lesson 1Document7 pagesGerman Lesson 1itsme_ayuuNo ratings yet
- Java Magazine JanuaryFebruary 2013Document93 pagesJava Magazine JanuaryFebruary 2013rubensaNo ratings yet
- Tesmec Catalogue TmeDocument208 pagesTesmec Catalogue TmeDidier solanoNo ratings yet
- Assignment File - Group PresentationDocument13 pagesAssignment File - Group PresentationSAI NARASIMHULUNo ratings yet
- Financial Performance Report General Tyres and Rubber Company-FinalDocument29 pagesFinancial Performance Report General Tyres and Rubber Company-FinalKabeer QureshiNo ratings yet