You might also like
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Oracle Web ADIDocument37 pagesOracle Web ADIKavithap PalaniNo ratings yet
- Programming Java NC III CGDocument32 pagesProgramming Java NC III CGHersey Badulis Hernandez100% (2)
- INSTITUTIONAL ASSESSMENT TOOLS (AutoRecovered)Document25 pagesINSTITUTIONAL ASSESSMENT TOOLS (AutoRecovered)billy100% (2)
- INSTITUTIONAL ASSESSMENT TOOLS (AutoRecovered)Document25 pagesINSTITUTIONAL ASSESSMENT TOOLS (AutoRecovered)billy100% (2)
- Software Development Techniques 07 March 2019 Examination PaperDocument7 pagesSoftware Development Techniques 07 March 2019 Examination PaperAsifHossain100% (1)
- Crafting The Literature ReviewDocument21 pagesCrafting The Literature Reviewbilly100% (1)
- 2-INTRODUCTION TO PDC - MOTIVATION - KEY CONCEPTS-03-Dec-2019Material - I - 03-Dec-2019 - Module - 1 PDFDocument63 pages2-INTRODUCTION TO PDC - MOTIVATION - KEY CONCEPTS-03-Dec-2019Material - I - 03-Dec-2019 - Module - 1 PDFANTHONY NIKHIL REDDYNo ratings yet
- Introduction To Parallel ComputingDocument34 pagesIntroduction To Parallel ComputingJOna Lyne0% (1)
- Digital Electronics, Computer Architecture and Microprocessor Design PrinciplesFrom EverandDigital Electronics, Computer Architecture and Microprocessor Design PrinciplesNo ratings yet
- High Performance ComputingDocument164 pagesHigh Performance Computingtpabbas100% (2)
- Parallel Processing Assignment 1Document14 pagesParallel Processing Assignment 1RobelNo ratings yet
- Cloud Computing All Unit NotesDocument210 pagesCloud Computing All Unit NotesK Maneesh100% (1)
- Parallel Computing An IntroductionDocument40 pagesParallel Computing An Introductioncleopatra2121No ratings yet
- Lecture Week - 1 Introduction 1 - SP-24Document51 pagesLecture Week - 1 Introduction 1 - SP-24imhafeezniaziNo ratings yet
- UNIT 1 FinalDocument36 pagesUNIT 1 FinalSivakumar SathasivamNo ratings yet
- UNIT I - Cloud ComputingDocument58 pagesUNIT I - Cloud Computing103 Swaran KrishNo ratings yet
- Module 1 HPCDocument32 pagesModule 1 HPCJoona JohnNo ratings yet
- Foundations of Sequential and Parallel Programming: Raising A New Generation of LeadersDocument34 pagesFoundations of Sequential and Parallel Programming: Raising A New Generation of Leadersekechi berniveNo ratings yet
- 17 Manjula Shanbhog Research Letter Aug 2011Document5 pages17 Manjula Shanbhog Research Letter Aug 2011cluxNo ratings yet
- Grid Computing A New DefinitionDocument4 pagesGrid Computing A New DefinitionChetan NagarNo ratings yet
- UNIT I - Cloud ComputingDocument57 pagesUNIT I - Cloud ComputingSHERWIN JOE 30No ratings yet
- ch06 PDFDocument10 pagesch06 PDFUtsab RautNo ratings yet
- ch06 PDFDocument10 pagesch06 PDFUtsab RautNo ratings yet
- Research Paper Computer Architecture PDFDocument8 pagesResearch Paper Computer Architecture PDFcammtpw6100% (1)
- Grid Architecture and Its Relation Through Various DistributedDocument27 pagesGrid Architecture and Its Relation Through Various DistributedrohitNo ratings yet
- Evolution of Cloud Computing and Enabling TechnoloDocument17 pagesEvolution of Cloud Computing and Enabling TechnoloNithin jNo ratings yet
- Term Paper Cse 211Document20 pagesTerm Paper Cse 211Nancy GoyalNo ratings yet
- Parallel and Distributed SystemsDocument63 pagesParallel and Distributed SystemsSrinivas NaiduNo ratings yet
- 1 of 1 PDFDocument7 pages1 of 1 PDFpatasutoshNo ratings yet
- WSNOPSYS Article 159 Final 159Document6 pagesWSNOPSYS Article 159 Final 159Usman TariqNo ratings yet
- Serial and Parallel First 3 LectureDocument17 pagesSerial and Parallel First 3 LectureAsif KhanNo ratings yet
- PDC Lecture No. 1Document21 pagesPDC Lecture No. 1Kashif MehmoodNo ratings yet
- HPC NotesDocument24 pagesHPC NotesShadowOPNo ratings yet
- Parallel Processing Assignment 1Document14 pagesParallel Processing Assignment 1RobelNo ratings yet
- UNIT I - Cloud ComputingDocument57 pagesUNIT I - Cloud Computing19CS038 HARIPRASADRNo ratings yet
- UNIT1Document57 pagesUNIT1sureshkumar aNo ratings yet
- Operating Systems For Wireless Sensor Networks: An OverviewDocument6 pagesOperating Systems For Wireless Sensor Networks: An OverviewUbiquitous Computing and Communication JournalNo ratings yet
- Rubio Campillo2018Document3 pagesRubio Campillo2018AimanNo ratings yet
- Computer03 SofteninghwDocument7 pagesComputer03 SofteninghwKoshal SanghaiNo ratings yet
- Parallel Processing: Types of ParallelismDocument7 pagesParallel Processing: Types of ParallelismRupesh MishraNo ratings yet
- Cloud Computing As An Evolution of Distributed ComputingDocument6 pagesCloud Computing As An Evolution of Distributed ComputingVIVA-TECH IJRINo ratings yet
- Seminar Presented By: Sehar Sultan M.SC (CS) 4 Semester UAFDocument33 pagesSeminar Presented By: Sehar Sultan M.SC (CS) 4 Semester UAFSahar SultanNo ratings yet
- 02 - Lecture #2Document29 pages02 - Lecture #2Fatma mansourNo ratings yet
- Csc4306 Net-Centric ComputingDocument5 pagesCsc4306 Net-Centric ComputingAli musa baffa100% (1)
- LLNL Introduction To Parallel ComputingDocument39 pagesLLNL Introduction To Parallel ComputingLogeswari GovindarajuNo ratings yet
- Editorial: Embedded Systems-New Challenges and Future DirectionsDocument3 pagesEditorial: Embedded Systems-New Challenges and Future DirectionsناصرھرەNo ratings yet
- 3-Flynn's Taxonomy - Multi-Core Processors - Shared Vs Distributed Memory-15!12!2022Document147 pages3-Flynn's Taxonomy - Multi-Core Processors - Shared Vs Distributed Memory-15!12!2022Pranav HiremathNo ratings yet
- Grid Computing: Vinayaka VDocument26 pagesGrid Computing: Vinayaka Vvinayakav658575No ratings yet
- Types of Parallel ComputingDocument11 pagesTypes of Parallel Computingprakashvivek990No ratings yet
- Application of Real Time Operating System in The Internet of ThingsDocument6 pagesApplication of Real Time Operating System in The Internet of Thingspatelhiren3385No ratings yet
- Grid Computing As Virtual Supercomputing: Paper Presented byDocument6 pagesGrid Computing As Virtual Supercomputing: Paper Presented bysunny_deshmukh_3No ratings yet
- Lecture 2 (Parallelism)Document7 pagesLecture 2 (Parallelism)hussiandavid26No ratings yet
- Grid and Cloud Full NotesDocument80 pagesGrid and Cloud Full NotesVive Kowsal YanissNo ratings yet
- Study and Applications of Cluster Grid and Cloud Computing: Umesh Chandra JaiswalDocument6 pagesStudy and Applications of Cluster Grid and Cloud Computing: Umesh Chandra JaiswalIJERDNo ratings yet
- Achieving High Performance ComputingDocument58 pagesAchieving High Performance ComputingIshamNo ratings yet
- CSE 423 Virtualization and Cloud Computinglecture0Document16 pagesCSE 423 Virtualization and Cloud Computinglecture0Shahad ShahulNo ratings yet
- It CC1 LN R18Document75 pagesIt CC1 LN R18Sàñdèép SûññyNo ratings yet
- CS6703 - Rejin NotesDocument80 pagesCS6703 - Rejin NotesCSE DEPARTMENTNo ratings yet
- Unit I GCCDocument6 pagesUnit I GCCGobi NathanNo ratings yet
- Advanced Computer ArchitectureDocument28 pagesAdvanced Computer ArchitectureSameer KhudeNo ratings yet
- Advance Computing Technology (170704)Document106 pagesAdvance Computing Technology (170704)Satryo PramahardiNo ratings yet
- TopologyiesDocument18 pagesTopologyieslahiruaioitNo ratings yet
- Rohini 74684926776Document24 pagesRohini 74684926776gynoceNo ratings yet
- PDC 1Document41 pagesPDC 1Engr Mir MuhammadNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument47 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- Aca NotesDocument148 pagesAca NotesHanisha BavanaNo ratings yet
- The Elements of DesignDocument23 pagesThe Elements of DesignbillyNo ratings yet
- Sample Java Program Accessing A DatabaseDocument28 pagesSample Java Program Accessing A DatabasebillyNo ratings yet
- Lesson Database FinalDocument28 pagesLesson Database FinalbillyNo ratings yet
- Digital ArtsM4Document20 pagesDigital ArtsM4billyNo ratings yet
- Data Structure M1Document3 pagesData Structure M1billyNo ratings yet
- Needed For NetworkingDocument1 pageNeeded For NetworkingbillyNo ratings yet
- lESSON IT FINALDocument11 pageslESSON IT FINALbillyNo ratings yet
- Student Remediation PlanDocument3 pagesStudent Remediation PlanbillyNo ratings yet
- Exceptions: Error-HandlingDocument13 pagesExceptions: Error-HandlingbillyNo ratings yet
- Q3M1Equations and Formulas in ExcelDocument12 pagesQ3M1Equations and Formulas in ExcelbillyNo ratings yet
- Resumepresentation 160102023142Document30 pagesResumepresentation 160102023142s_87045489No ratings yet
- Lesson COMPROGFINALDocument10 pagesLesson COMPROGFINALbillyNo ratings yet
- Teacher Remediation PlanDocument1 pageTeacher Remediation PlanbillyNo ratings yet
- Enrollment FlowDocument1 pageEnrollment FlowbillyNo ratings yet
- Learning Module: Environment and Market in Computer Systems ServicingDocument43 pagesLearning Module: Environment and Market in Computer Systems ServicingbillyNo ratings yet
- Ict Modules OverviewDocument40 pagesIct Modules OverviewKittybabyMaladyNo ratings yet
- CertificateDocument1 pageCertificatebillyNo ratings yet
- Example of FantasyDocument3 pagesExample of FantasybillyNo ratings yet
- Mobile ComputingDocument43 pagesMobile ComputingbillyNo ratings yet
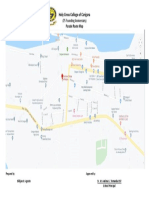
- Holy Cross College of Carigara Route MApDocument1 pageHoly Cross College of Carigara Route MApbillyNo ratings yet
- Session Plan Core - Install and Configure Computer SystemsDocument4 pagesSession Plan Core - Install and Configure Computer SystemsNeri Erin67% (3)
- LAC Action PlanDocument4 pagesLAC Action PlanEr Ma100% (3)
- Forms Program Registration 2018Document25 pagesForms Program Registration 2018Tahani Awar GurarNo ratings yet
- Story of My LifeDocument2 pagesStory of My LifebillyNo ratings yet
- Source CodeDocument20 pagesSource CodeLacorte Jr MeranoNo ratings yet
- Clustering Partition HierachyDocument58 pagesClustering Partition HierachyKathy KgNo ratings yet
- Experiment No 2: Name: Pallavi Bharti Roll No: 18141112Document4 pagesExperiment No 2: Name: Pallavi Bharti Roll No: 18141112Pallavi BhartiNo ratings yet
- Important LinksDocument3 pagesImportant LinksAbdelkareem EmaraNo ratings yet
- Wipro Elite NLTH Coding Placement QuestionsDocument16 pagesWipro Elite NLTH Coding Placement QuestionsShivamNo ratings yet
- BCA 2021 SyllabusDocument57 pagesBCA 2021 SyllabusKhaja HussainNo ratings yet
- DSA RecursionDocument21 pagesDSA RecursionRiyaz ShresthaNo ratings yet
- Db2 RedbookDocument350 pagesDb2 RedbookOm ShivaniNo ratings yet
- Tax Calculation Using Switch Case in JavaDocument4 pagesTax Calculation Using Switch Case in Javaprofessorrdsharma0% (1)
- Week 11b ViewsDocument26 pagesWeek 11b ViewsKenanNo ratings yet
- HP Vertica 7.1.x CPP SDK APIDocument379 pagesHP Vertica 7.1.x CPP SDK APIRahul VishwakarmaNo ratings yet
- Appendix D: Introduction To FlowchartingDocument10 pagesAppendix D: Introduction To FlowchartingMai K MohamedNo ratings yet
- MDIAPPDocument4 pagesMDIAPPSorin BelousNo ratings yet
- Parametric LPDocument13 pagesParametric LPSou TibonNo ratings yet
- DPRNTDocument4 pagesDPRNTalecandro_90No ratings yet
- Relational Databases and BeyondDocument12 pagesRelational Databases and BeyondaNo ratings yet
- Programming in C For BCA BIT BEDocument0 pagesProgramming in C For BCA BIT BEwww.bhawesh.com.npNo ratings yet
- Home Asgn3 Bee 13cdDocument1 pageHome Asgn3 Bee 13cdMuhammad Hassan JavedNo ratings yet
- Appendix H: Authors: John Hennessy & David PattersonDocument7 pagesAppendix H: Authors: John Hennessy & David Pattersona.shyamNo ratings yet
- Chapter 6: Arrays: SolutionsDocument40 pagesChapter 6: Arrays: SolutionsEric Martin100% (1)
- TinyMush 3.1p6 Source Code Syntax ColoredDocument1,492 pagesTinyMush 3.1p6 Source Code Syntax ColoredSeekerOfThingsNo ratings yet
- 2015 Coc Level 3 DBADocument5 pages2015 Coc Level 3 DBAkayisle karshanbo100% (3)
- Chapter 10: Arrays: Programming With Microsoft Visual BasicDocument47 pagesChapter 10: Arrays: Programming With Microsoft Visual BasicNarnishNo ratings yet
- Strings AssignmentDocument3 pagesStrings AssignmentDAKSH SACHDEVNo ratings yet
- Software Design: CPE 223LDocument146 pagesSoftware Design: CPE 223Ljapheth louie m. gofredoNo ratings yet
- Monad (3) .PsDocument10 pagesMonad (3) .PsPrajwal KhatiwadaNo ratings yet
- TechLang BrochureDocument12 pagesTechLang BrochureAkhilTCNo ratings yet
- Misrac2012 DatasheetDocument25 pagesMisrac2012 DatasheetsdfklaghNo ratings yet